- 前面章节介绍的机器学习方式,包括监督学习和无监督学习等,都是针对一个给定的任务,准备一定规模的训练数据,并且要求这些训练数据和真实数据分布一致,然后设定一个目标函数或优化方法,在训练数据上学习一个模型
- 不同的任务的模型往往需要从零开始训练,每个任务都需要准备大量的训练数据
But,在实际应用中,往往无法满足上述要求:
- 可能训练任务和目标任务的数据分布不一致
- 可能训练数据过少
- … …
此外,我们还需要一个模型可以快速地适应新的任务,因此需要 模型独立的学习方式

假设有 M 个不同的模型  ,其平均期望错误为
,其平均期望错误为 
集成策略:
- 直接平均(投票)
- 集成模型

- F(x) 的期望错误 R(F) :

- 即,集成模型的期望错误大于等于所有模型平均期望错误的
 ,小于等于所有模型的平均期望错误
,小于等于所有模型的平均期望错误 - 为了得到更好的集成效果,要求每个模型之间具备一定的差异性(差异性尽可能大)
- 增加模型差异性的方法:
- Bagging 类方法:通过随即构造训练样本、随机选择特征等方法来提高每个基模型的独立性
- Bagging:通过不同模型的训练集的独立性来提高不同模型之间的独立性
- 在原始训练集上进行有放回的随机采样,得到 M 个比较小的训练集并训练 M 个模型,然后通过投票的方法进行模型集成
- 随机森林:在 Bagging 的基础上再引入了随机特征,进一步提高每个基模型之间的独立性
- Bagging:通过不同模型的训练集的独立性来提高不同模型之间的独立性
- Boosting 类方法:按一定的顺序先后训练不同的基模型,每个模型都针对前序模型的错误进行专门训练。根据前序模型的结果,调整训练样本的权重,从而增加不同基模型之间的差异性
- 只要基模型的准确率比随机猜测高,就可以通过集成方法来显著的提高集成模型的准确率
- 代表性方法:AdaBoost
- Bagging 类方法:通过随即构造训练样本、随机选择特征等方法来提高每个基模型的独立性
- 集成模型
- 加权平均
10.1.1 AdaBoost 算法
Boosting 类方法:
- 目标是学习一个加性模型:

- 弱分类器 / 基分类器
 :
: 为其权重
为其权重 - 强分类器

- 关键:如何训练每个弱分类器 及其权重 ,使得每个若分类的差异性尽可能大,以提高集成效果
AdaBoost 算法:一种迭代式的训练算法,通过改变数据分布来提高弱分类器的差异
- 改变数据分布的方法:每一轮训练中(训练第 m+1 个分类器时),增加已有 m 个弱分类器分错样本的权重,减少分对样本的权重,从而得到一个新的数据分布,使得第 m+1 个弱分类器更关注于已有弱分类器分错的样本

10.2 半监督学习 SSL
半监督学习 Semi-supervised Learning:利用少量标注数据和大量无标注数据进行学习的方式

10.2.1 自训练
自训练(Self-Training / Self-Teaching)/ 自举法(Bootstrapping):
- 首先使用标注数据训练一个模型
- 用该模型预测无标注样本的标签
- 将预测置信度比较高的样本及其预测的伪标签加入数据集
- 用新的数据集(原标注数据集+筛选的伪标签数据集)重新训练新的模型
- 不断重复以上过程…

自训练的缺点:
- 无法保证每次加入训练集的样本的伪标签是正确的,如果选择样本的伪标签是错误的,反而会损害模型的预测能力。
自训练最关键的步骤:如何设置挑选样本的标准,避免错误伪标签的负面影响
伪标签:
Pseudo-Label : The Simple and Efficient Semi-Supervised Learning Method for Deep Neural Networks
伪标签 Pseudo Labeling
10.2.2 协同训练
视角 View:eg. 网页包含两种视角:文字内容、只想其他网页的链接,这两种视角都可以用来判断一个网页的类别
协同训练 Co-Training,是自训练方法的一种改进,通过两个基于不同视角(view) 的分类器来互相促进
对一个样本  ,
, 和
和  分别表示两种不同视角
分别表示两种不同视角  和
和  的特征
的特征
协同训练的假设:
- 条件独立性:给定样本标签 y 时,两种特征条件独立

- 协同算法要求两种视角条件独立,如果两种视角完全一样,就退化成了自训练算法
- 充足和冗余性:当数据充分时,每种视角的特征都足以单独训练出一个正确的分类器
即,
协同训练的训练过程:
- 首先使用标注数据,根据不同视角分别训练两个模型

- 在无标注数据集上进行预测,各自选取预测置信度比较高的样本及其伪标签加入训练集
- 用新的训练集重新驯良两个不同视角的模型
- 不断重复以上过程…

10.3 多任务学习
共享知识:两个比较相关的任务之间存在一定的共享知识,对两个任务都有所帮助
- 共享知识可以是:表示(特征)、模型参数 or 学习算法等
- 目前主流的多任务学习主要关注表示层面的共享
多任务学习 Multi-task Learning,指同时学习多个相关任务,让这些任务在学习过程中共享知识,利用多个任务之间的相关性来改进模型在每个任务上的性能和泛化能力
- 多任务学习可以看作一种归纳迁移学习,即通过利用包含在相关任务中的信息作为归纳偏置,来提高泛化能力
多任务学习的主要挑战:设计多任务之间的共享机制
共享机制:神经网络提供了一种很方便的信息共享方式,可以很容易地进行多任务学习
四种常见的共享模式:
| 共享模式 | 含义 |
|---|---|
| 硬共享模式 | - 让不同任务的神经网络模型共同使用一些共享模块(一般是低层)来提取一些通用特征 - 然后针对每个不同的任务设置一些私有模块(一般是高层)来提取一些任务特定的特征 |
| 软共享模式 | - 不显式地设置共享模块,但每个任务都可以从其他任务中“窃取”一些信息来提高自己的能力 - 窃取的方式:直接复制使用其他任务的隐状态、使用注意力机制来主动选取有用信息等 |
| 层次共享模式 | 如果同时学习的多个任务有级别高低之分,则: - 让低级任务在低层输出(抽取一些低级的局部特征) - 让高级任务在高层输出(抽取一些高级的抽象语义特征) |
| 共享-私有模式 | 将共享模块和任务特定的(私有)模块的责任分开: - 共享模块捕捉一些跨任务的共享特征 - 私有模块只捕捉和特定任务相关的特征 |
最终表示由共享特征和私有特征共同构成 |
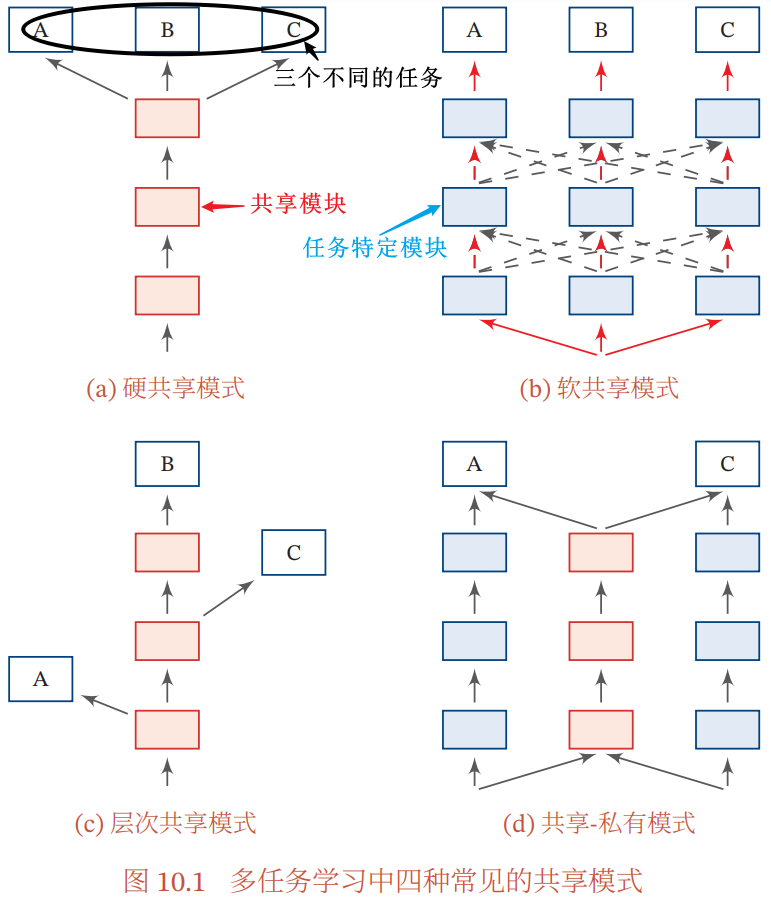
多任务学习中,每个任务都有自己单独的训练集:第 m 个任务的训练集 
多任务学习的联合函数:
- 即所有 M 个任务损失函数的线性加权
- 第 m 个任务的权重
 :权重可以根据不同任务的重要程度来赋值,也可以根据任务的难易程度来赋值;通常情况下,所有任务设置相同的权重,即
:权重可以根据不同任务的重要程度来赋值,也可以根据任务的难易程度来赋值;通常情况下,所有任务设置相同的权重,即 
多任务学习的流程:
- 联合训练阶段:每次迭代时,随机挑选一个任务,从这个任务中随机选择一些训练样本,计算梯度并更新参数

- 单任务精调阶段:基于多任务学习得到的参数,分别在每个单独任务上进行精调(Fine-Tuning)
多任务学习能获得比单任务学习更好的泛化能力的原因:
- 多任务学习在多个任务的数据集上进行训练,比单任务学习的训练集更大。由于多个任务之间有一定的相关性,因此多任务学习相当于一种隐式的数据增强,可以提高模型的泛化能力
- 多任务学习中的共享模块需要兼顾所有任务,在一定程度上避免了模型过拟合到单个任务的训练集,可以看作一种正则化
- 一个好的表示通常需要适用于多个不同任务,因此多任务学习的机制使得它会比单任务学习获得更好的表示
- 在多任务学习中,每个任务都可以选择性利用其他任务中学习到的隐藏特征,从而提高自身的能力
10.4 迁移学习
迁移学习:将相关任务(具有大量训练数据,虽然分布与目标任务不同)的训练数据中的可泛化知识迁移到目标任务上
- 迁移学习是指两个不同领域的知识的迁移过程,利用源领域
 中学到的知识来帮助目标领域
中学到的知识来帮助目标领域  上的学习任务,源领域的训练样本数量一般远大于目标领域
上的学习任务,源领域的训练样本数量一般远大于目标领域
| 机器学习任务相关概念 | 定义 |
|---|---|
| 样本空间 | |
| 输入空间 | |
| 输出空间 | |
| 概率密度函数 / 分布 | |
| 领域 Domain | 一个样本空间及其分布 - 输入空间、输出空间、概率分布中有一个不同,就认为是不同的领域 |
| 机器学习任务 | 在一个领域 D 上的条件概率  的建模问题 的建模问题 |
迁移学习的两种类型:归纳迁移学习、转导迁移学习
| 概念 | 定义 |
|---|---|
| 归纳学习 | 希望在训练数据集上学习到使得期望风险(即真实数据分布上的错误率)最小的模型 - 一般机器学习都是归纳学习 |
| 转导学习 | 学习一种在给定测试集上错误率最小的模型,在训练阶段可以利用测试集的信息 |
| 归纳迁移学习 | 在源领域和任务上学习出一般的规律,然后将这个规律迁移到目标领域和任务上 |
| 转导迁移学习 | 从样本到样本的迁移,直接利用源领域和目标领域的样本进行迁移学习 |
10.4.1 归纳迁移学习
归纳迁移学习 Inductive Transfer Learning:要求源领域和目标领域是相关的,并且源领域 有大量的训练样本(可以是有标注/无标注)
| 输入空间 | 源领域和目标领域有相同的输入空间  |
|---|---|
| 输出空间 | 输出空间可以相同也可以不同 |
| 任务 / 概率分布 | 源任务和目标任务一般不同 ,即 |
归纳迁移学习有效的原因:源领域的训练数据规模非常大,这些预训练模型通常有比较好的泛化性,其学习到的表示通常也适用于目标任务
不同的迁移学习任务:
| 源领域只有大量无标签数据时 | 源任务可以转换为无监督学习任务,eg. 自编码、密度估计任务。 通过这些无监督学习任务学习一种可迁移的表示,然后再将这种表示迁移到目标学习任务 |
|---|---|
| 源领域有大量的标注数据时 | 可以直接将源领域上训练的模型迁移到目标领域上。 eg. 计算机视觉领域,有基于大规模图像数据集 ImageNet 预训练的图像分类模型 VGG、ResNet 等,可以将这些预训练模型迁移到目标任务 |
两种迁移方式:
- 基于特征的方式:将预训练模型的输出或者中间隐藏层的输出作为特征直接加入到目标任务的学习模型中
- 目标任务的学习模型可以是一般的浅层分类器(eg. 支持向量机)或一个新的神经网络模型
- 精调(Fine-Tuning)的方式:在目标任务上复用预训练模型的部分组件,并对其参数进行精调
将预训练模型迁移到目标任务上通常比从零开始学习的方式好:
- 初始模型性能一般比随机初始化的模型好
- 训练时模型的学习速度比从零开始学习要快,收敛性更好
- 模型的最终性能更好,具有更好的泛化性
归纳迁移学习和多任务学习的区别:
- 多任务学习是同时学习多个不同任务,而归纳迁移学习通常分为两个阶段:源任务上的学习阶段、目标任务上的迁移学习阶段
- 多任务学习是希望提高所有任务的性能,而归纳迁移学习是单向的知识迁移,希望提高模型在目标任务上的性能
10.4.2 转导迁移学习
转导迁移学习 Transductive Transfer Learning:是一种从样本到样本的迁移,直接利用源领域和目标领域的样本进行迁移学习
- 通常假设源领域有大量的标注数据,而目标领域没有(或只有少量)的标注数据,但有大量的无标注数据
- 目标领域的数据在训练阶段是可见的
领域适应 Domain Adaptation:转导迁移学习的一个常见子问题,一般假设:
| 样本空间 | 源领域和目标领域有相同的样本空间 |
|---|---|
| 数据分布 | 数据分布不同 |
造成数据分布( )不一致的三种情况:
)不一致的三种情况:
| 协变量偏移 (大多数领域适应问题主要关注协变量偏移) |
- 源领域和目标领域的输入边际分布不同 - 但后验分布相同 ,即学习任务相同 |
|---|---|
| 概念偏移 | - 源领域和目标领域的输入边际分布相同 - 但后验分布相同 ,即学习任务不同 |
| 先验偏移 | - 源领域和目标领域的输出标签 y 的先验分布不同 - 但条件分布相同 |
目标领域必须提供一定数量的标注样本 |

10.5 终身学习
终身学习 / 持续学习:根据历史任务中学到的经验和知识来帮助学习不断出现的新任务,并且这些经验和知识是持续累积的,不会因为新的任务而忘记旧的知识
- 终身学习与归纳迁移学习的区别:
- 归纳迁移学习的目标是优化目标任务的性能,而不关心知识的累积
- 终身学习的目标是持续的学习和知识累积
- 终身学习和多任务学习的区别:
- 多任务学习是在使用所有任务的数据进行联合学习,并不是持续累积地一个一个学习
- 终身学习并不是在所有任务上同时学习
终身学习的关键问题:避免灾难性遗忘
- 即,按照一定顺序学习多个任务时,在学习新任务的同时不会忘记之前学会的历史任务
- 也就是说,在学习第 m+1 个任务
 时,找到一组不影响任务
时,找到一组不影响任务  而又能使得任务 最优的参数
而又能使得任务 最优的参数
解决灾难性遗忘的方法:弹性权重巩固
10.6 元学习
元学习 Meta-Learning:也称学习的学习,是动态调整学习方式的能力,即根据不同任务来动态地选择合适的模型或动态地调整超参数
元学习的目的:从已有任务中学习一种学习方法或知识,可以加速新任务的学习

10.6.1 基于优化器的元学习
基于优化器的元学习:自动学习一种更新参数的规则,即通过另一个神经网络(eg. RNN、LSTM)来建模梯度下降的过程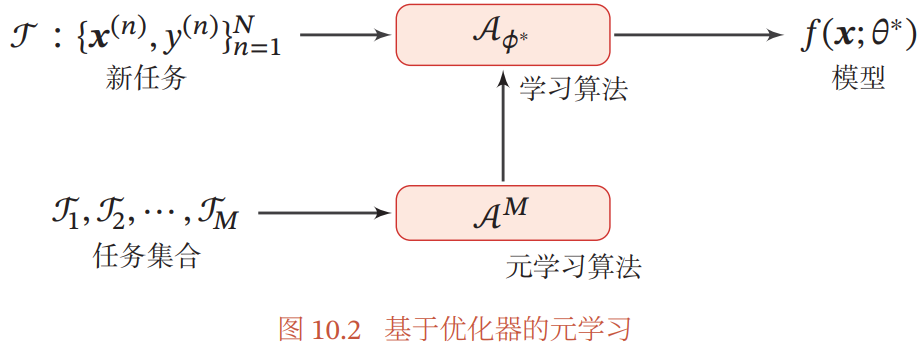
元学习过程:目标是找到一个适用于多个不同任务的优化器
- 优化器
 :用于预测第 t 步时更新参数的差值
:用于预测第 t 步时更新参数的差值 
- 第 t 步的更新规则:
 ,
, 是优化器的参数
是优化器的参数
10.6.2 模型无关的元学习 MAML
模型无关的元学习 MAML:一个简单的模型无关、任务无关的元学习算法
MAML 的目标:快速学习的能力,即在任务空间的所有任务上学习一种通用的表示(模型),然后学习一个参数  使得其经过一个梯度迭代(或少量迭代)就可以在新任务上达到最好的性能,并且避免在新任务上的过拟合
使得其经过一个梯度迭代(或少量迭代)就可以在新任务上达到最好的性能,并且避免在新任务上的过拟合
10.7 总结和深入阅读
本章主要介绍了一些和模型无关的学习方式:
- 集成学习:通过汇总多个模型来提高预测准确率
- 代表模型:
- 随机森林
- AdaBoost
- 在训练神经网络时经常采用的丢弃法 Dropout 在一定程度上也是一个模型集成
- 代表模型:
- 半监督学习 SSL:高效地利用少量标注数据和大量无标注数据来训练分类器
- 多任务学习:利用多个相关任务共享知识来提高模型泛化性
- 迁移学习:将一个领域上训练的模型迁移到新的领域,使得新模型不用从零开始学习
- 迁移学习中要避免将领域相关的特征迁移到新的领域
- 主要研究问题:领域适应 Domain Adaptation
- 终身学习:持续学习,不断累积在先前任务中学到的知识,并在未来新的任务中利用这些知识,同时避免对先前学会的历史任务的灾难性遗忘
- 元学习:在多个不同任务上学习一种可泛化的的快速学习能力
习题
参考:
习题 10-1 根据Jensen不等式以及公式 (10.6),证明公式(10.9)中的 ℛ(𝑓) ≥ ℛ(𝐹)
习题 10-2 集成学习是否可以避免过拟合?
可以。集成学习通过组合多个模型,可以减少泛化误差,起到了正则化的作用,所以可以避免过拟合。
习题 10-3 分析自训练和EM算法(11.2.2.1 节)之间的联系
- 自训练算法和EM算法都属于半监督学习算法,需要有一些有标注数据训练模型
- 两者都属于迭代优化策略
习题 10-4 根据最大后验估计来推导公式(10.50)

若有收获,就点个赞吧
0 人点赞
