卷积神经网络:是一种具有局部连接、权重共享等特性的深层前馈神经网络。
上一章介绍的全连接前馈神经网络,用于处理图像时有两个问题:
- 参数太多:导致整个神经网络的训练效率非常低,也很容易出现过拟合
- 局部不变形特征:全连接前馈网络很难提取局部不变性特征(eg. 对图像进行尺度缩放、平移、旋转等不影响语义信息的操作),一般需要进行数据增强来提高性能
因而,出现了卷积神经网络,并在计算机视觉领域得到广泛应用
目前的卷积神经网络一般是由卷积层、汇聚层(池化层)、全连接层交叉堆叠而成的前馈神经网络
卷积神经网络有三个结构上的特性:
- 局部连接
- 权重共享
- 汇聚(池化)
这些特性使得卷积神经网络具有一定程度上的平移、缩放和旋转不变性;
和(全连接)前馈神经网络相比,卷积神经网络的参数更少
5.1 卷积/褶积
5.1.1 卷积的定义
- 一维卷积:常用于信号处理中,用于计算信号的延迟累积
- 在时刻 t 收到的信号
 为当前时刻产生的信息和以前时刻延迟信息的叠加
为当前时刻产生的信息和以前时刻延迟信息的叠加
 称为滤波器(filter)或卷积核,滤波器长度为 K,x 为信号序列
称为滤波器(filter)或卷积核,滤波器长度为 K,x 为信号序列
- 一维卷积的定义:
 ,
, 表示卷积运算
表示卷积运算 - 不同的滤波器提取不同的特征:
- 在时刻 t 收到的信号

- 二维卷积:常用于二维的图像处理
- 二维卷积的定义:
 ,X 为输入信息,W 为滤波器
,X 为输入信息,W 为滤波器 - 注意:卷积实际上分为两步:(参考:如何通俗易懂地解释卷积?)
- ① 将卷积核翻转 180°:即上下翻转+左右翻转
- ② 滑动叠加
- 二维卷积的定义:
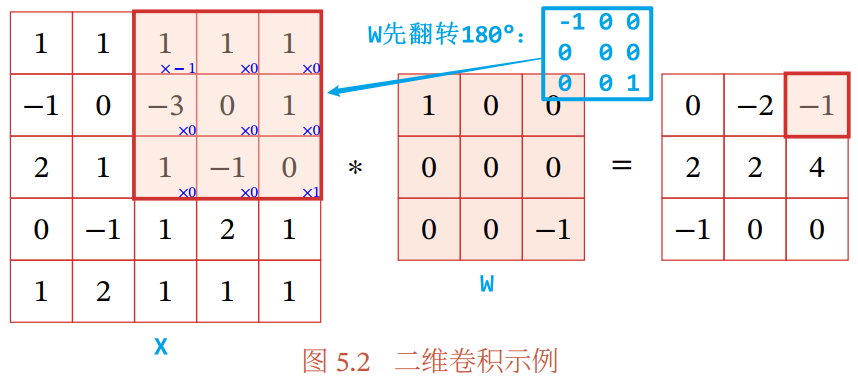
- 二维卷积常用于图像的特征提取,图像通过卷积得到的结果称为特征映射

5.1.2 互相关
互相关:也称不翻转卷积,与卷积的区别仅仅在于互相关的卷积核不进行翻转
定义: ,
, 代表互相关运算
代表互相关运算
卷积核是否进行翻转和其特征抽取能力无关,也就是说,卷积和互相关在能力上是等价的,也因此常用互相关代替卷积运算。
事实上,现在的“卷积”一般就指“互相关”,即不翻转卷积,用 表示,而不是用 表示的真正的卷积
5.1.3 卷积的变种
- 步长:卷积核在滑动时的间隔
- 零填充:在输入向量两端进行补零
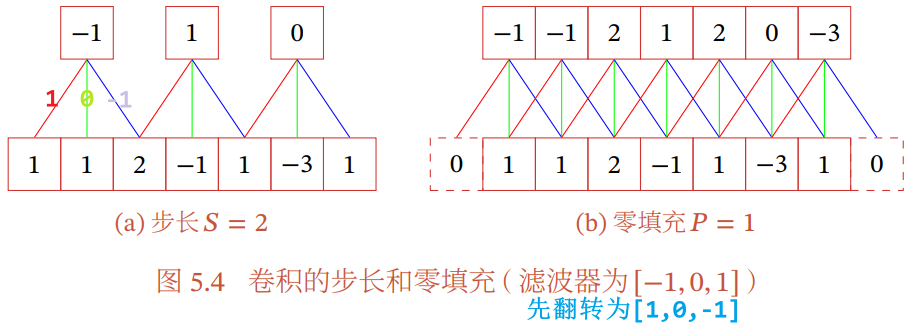
对于一维卷积,假设卷积层的输入神经元个数为 M,卷积大小为 K,步长为 S,在输入两端各填补 P 个 0,那么该卷积层的神经元数量为:
常用的卷积:
- 窄卷积:步长 S=1,两端不补零 P=0,卷积后输出长度为 M-K+1
- 宽卷积:步长 S=1,两端补零 P=K-1,卷积后输出长度为 M+K-1
- 等宽卷积:步长 S=1,两端补零 P=(K-1)/2,卷积后输出长度为 M
- 目前的文献中,卷积一般默认为等宽卷积
5.1.4 卷积的数学性质
交换性
- 翻转卷积具有交换性:

- 宽卷积具有交换性:
 ,
, 代表宽卷积
代表宽卷积
- 翻转卷积具有交换性:
导数(
 ,
, 为一个标量函数)
为一个标量函数)


5.2 卷积神经网络
5.2.1 用卷积来代替全连接
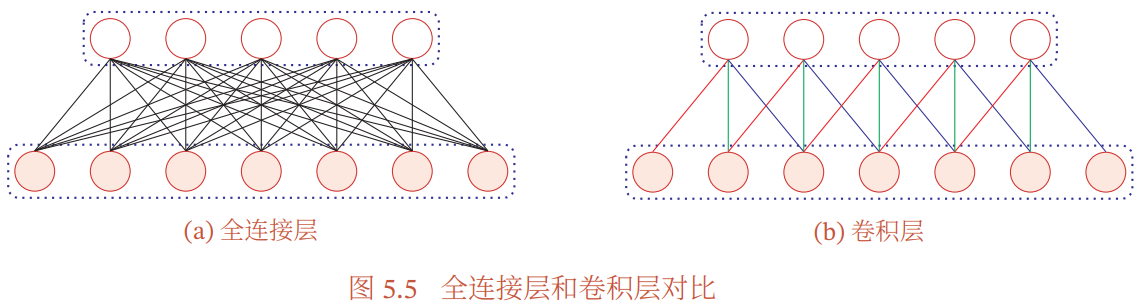
卷积层有两个很重要的性质:
- 局部连接:
- 卷积层(第 l 层)中的每个神经元都只和下一层(第 l-1 层)中某个局部窗口内的神经元相连,构成一个局部连接网络
- 卷积层和下一层之间的连接数大大减少,由原来(全连接)的
 个连接变为
个连接变为 个连接,K 为卷积核大小
个连接,K 为卷积核大小
- 权重共享:
- 作为参数的卷积核
 对于 第 l 层的所有神经元都是相同的
对于 第 l 层的所有神经元都是相同的 - 权重共享可以理解为:一个卷积核只捕捉输入数据中的一种特定的局部特征
- 如果要提取多种特征,就需要使用不同的卷积核
- 作为参数的卷积核
得益于以上两个性质,卷积层共有 K+1 个参数,包括 K 维的权重 和 1 维的偏置  ,参数个数与神经元数量无关(当然卷积层的神经元个数不是任意的,遵循上面提到的公式)
,参数个数与神经元数量无关(当然卷积层的神经元个数不是任意的,遵循上面提到的公式)
5.2.2 卷积层
卷积层的作用:提取一个局部区域的特征,不同的卷积核相当于不同的特征提取器
特征映射:一幅图像(或其他特征映射)经过卷积提取得到的特征,每个特征映射可以作为一类抽取的图像特征
- 图像的深度(通道数)就是特征映射的数量
- 一个卷积层有 P 个三维的卷积核(卷积核深度=输入图像深度),输出图像的通道数(特征映射的数量)就为 P
卷积层的结构:
- 输入特征映射组:
 ,每个切片矩阵
,每个切片矩阵  为一个输入特征映射,D 代表输入图像的通道数/图像深度/特征映射的数量
为一个输入特征映射,D 代表输入图像的通道数/图像深度/特征映射的数量 - 输出特征映射组:
 ,每个切片矩阵
,每个切片矩阵  为一个输出特征映射,P 代表输出图像的通道数/图像深度/特征映射的数量
为一个输出特征映射,P 代表输出图像的通道数/图像深度/特征映射的数量 - 卷积核:
 ,是四维张量,每个切片矩阵
,是四维张量,每个切片矩阵  为一个三维卷积核,P 代表三维卷积核的个数,等于输出图像的通道数;D 代表三维卷积核的深度,等于输入图像的通道数
为一个三维卷积核,P 代表三维卷积核的个数,等于输出图像的通道数;D 代表三维卷积核的深度,等于输入图像的通道数
- 输入特征映射组:
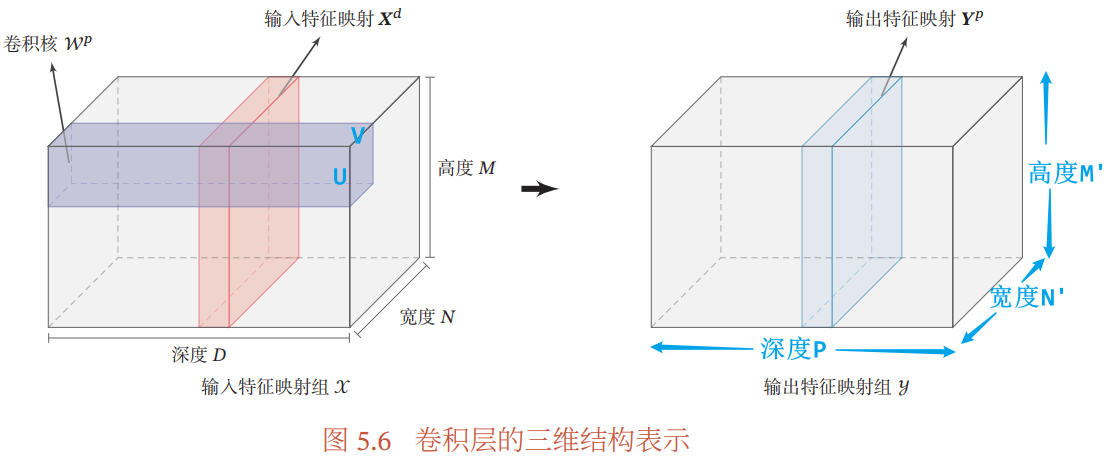
- 计算输出特征映射
 :
:- 卷积层净输入
 ,即每个三维卷积核
,即每个三维卷积核  需要一个偏置
需要一个偏置 
- 输出特征映射
 ,
, 为非线性激活函数,一般用 ReLU 函数
为非线性激活函数,一般用 ReLU 函数
- 卷积层净输入
- 对应的一个卷积层共需要
 个参数
个参数
5.2.3 汇聚层/池化层
- 汇聚层/池化层(Pooling Layer),也称子采样层
汇聚层的作用:
- 进行特征选择,降低特征数量,从而减少参数数量
- 卷积层可以显著减少网络中连接的数量,但得到的输出特征映射组中的神经元数量并没有显著减少,如果后面接一个分类器,则分类器的输入维数依然很高,很容易导致过拟合。因此,可以在卷积层后加上一个汇聚层,从而降低特征维数,避免过拟合 (注:增加卷积步长也可以降低特征维数)
- 汇聚层不但可以有效地减少神经元的数量,还可以使得网络对一些小的局部形态改变保持不变性,并拥有更大的感受野
汇聚/池化(Pooling):指对每个区域进行下采样得到一个值,作为这个区域的概括
- 常用的汇聚函数:
- 最大汇聚/最大池化:即选择这个区域内所有神经元的最大活性值作为这个区域的表示
- 平均汇聚/平均池化:取区域内所有神经元活性值的平均值

- 早期的卷积网络会在汇聚层使用非线性激活函数,但目前主流的卷积网络中,汇聚层仅包含下采样操作,不包含非线性激活函数
- 典型的汇聚层:将每个特征映射划分为 2×2 大小的不重叠区域,然后使用最大汇聚的方式进行下采样
- 过大的采样区域会急剧减少神经元的数量,但也会造成过多的信息损失
5.2.4 卷积网络的整体结构
- 卷积块:一个卷积块为连续 M 个卷积层和 b 个汇聚层,M 通常设置为 2~5,b 为 0~1
- 一个卷积网络由 N 个卷积块和 K 个全连接层组成
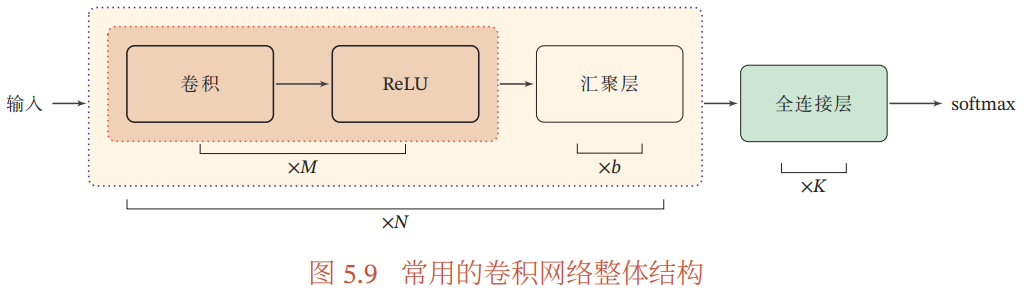
- 目前,卷积网络的整体结构趋向于使用更小的卷积核(eg. 1×1,3×3)以及更深的结构(eg. 层数>50)
- 由于卷积的操作性越来越灵活(eg. 增大步长也可以减少特征维数),汇聚层的作用也越来越少,目前的主流网络中汇聚层的比例正在降低,趋向于全卷积网络
5.3 参数学习
- 误差反向传播法进行参数学习
卷积神经网络包含卷积层和汇聚层,但参数为卷积核以及偏置,因此只需要计算卷积层中参数的梯度


- 即,每层参数的梯度依赖于其所在层的误差项
 ,z 是净输入
,z 是净输入
5.4 几种典型的卷积神经网络
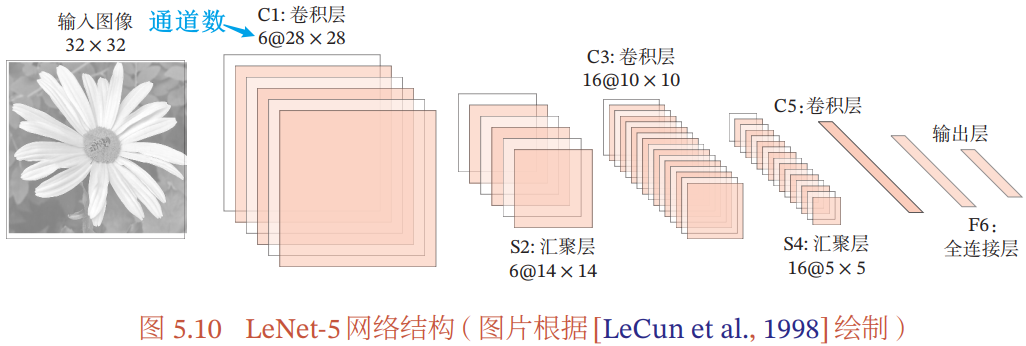
5.4.1 LeNet-5
5.4.2 AlexNet

5.4.3 Inception 网络
- Inception 模块:一个卷积层包含多个不同大小的卷积操作(eg. 同时使用 1×1、3×3、5×5 等不同大小的卷积核),并将得到的特征映射在深度上拼接(堆叠)起来作为输出特征映射
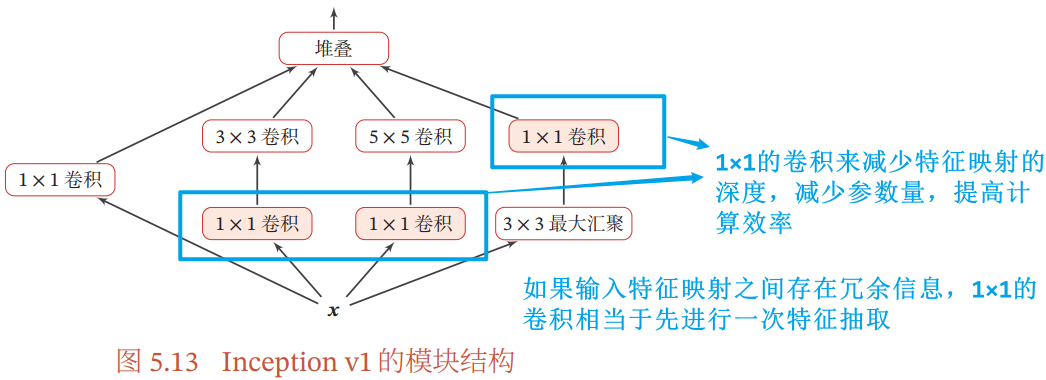
- Inception v1 即 GooLeNet:由 9 个Inception v1 模块和 5 个汇聚层(池化层)以及其他一些卷积层和全连接层构成,总共 22 层网络。为了解决梯度消失问题,GoogLeNet 在网络中间层引入两个辅助分类器来加强监督信息

- Inception v3:用多层的小卷积核来替换大的卷积核,以减少计算量和参数量,并保持感受野不变,具体包括:
- 使用两层 3×3 的卷积来代替 v1 中的 5×5 的卷积
- 使用连续的 K×1 和 1×K 来替换 K×K 的卷积
- 此外,还引入了标签平滑以及批量归一化等优化方法进行训练
5.4.4 残差网络 ResNet
残差连接:残差网络通过给非线性的卷积层增加直连边(即残差连接)的方式来提高信息的传播效率
原理:
- 深度网络中,我们期望用一个非线性单元(可以为一层或多层的卷积层)
 去逼近一个目标函数
去逼近一个目标函数 
- 目标函数 可以拆分为两部分:

- 由通用近似定理,一个由神经网络构成的非线性单元有足够的能力来近似逼近原始目标函数或残差函数
- 但实际上,残差函数更容易学习,因此可以将原来的优化问题转化为:
- 让非线性单元 去近似残差函数
 ,并用
,并用  去逼近
去逼近
残差单元:由多个级联的(等宽)卷积层和一个跨层的直连边组成,再经过 ReLU 激活后得到输出
残差网络:就是由多个残差单元串联起来构成的一个非常深的网络
5.5 其他卷积方式
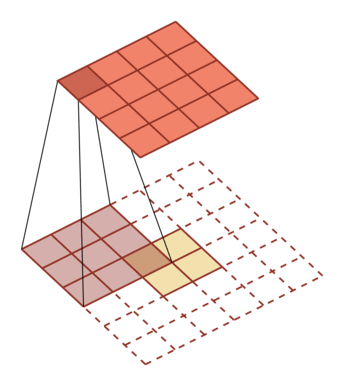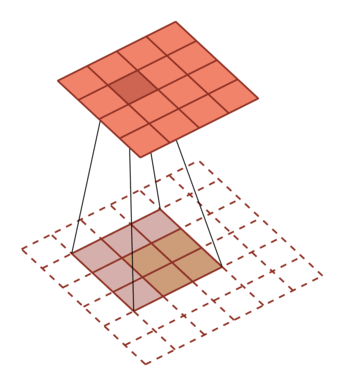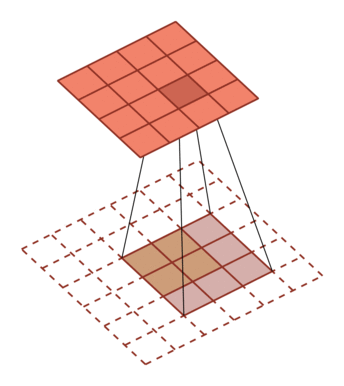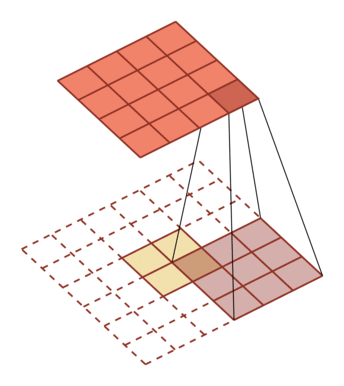
5.5.1 转置卷积
(注:以下的维应该指的是一维向量的维数,or 二维向量的边长,eg. 3维是 3×3 矩阵)
- 卷积:一般是实现从高维特征到低维特征的转化
- 转置卷积/反卷积:将低维特征映射到高维特征的卷积
在卷积网络中,卷积层的前向计算和反向传播也是一种转置关系
规律:对一个 M 维的向量 z (M×M)和大小为 K 的卷积核(K×K),如果希望通过卷积操作来映射到更高维的向量,只需要对向量 z 进行两端补零 P=K-1,然后进行卷积,可以得到 M+K-1 维的向量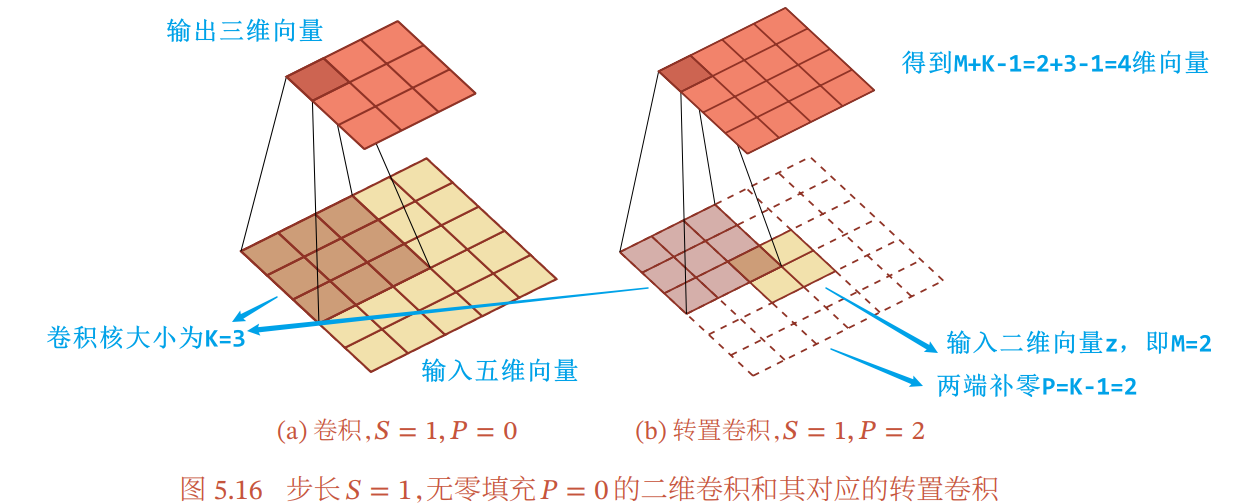
动图如下:
| 卷积,输入向量大小M=5,卷积核大小K=3,零填充P=0,步长S=1 | 转置卷积,输入向量大小M=2,卷积核大小K=3,零填充P=2,步长S=1 |
|---|---|
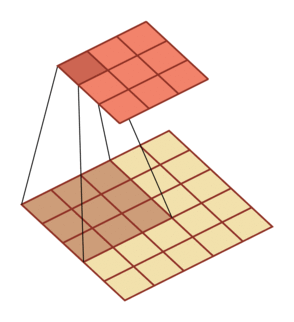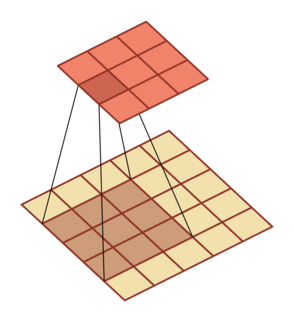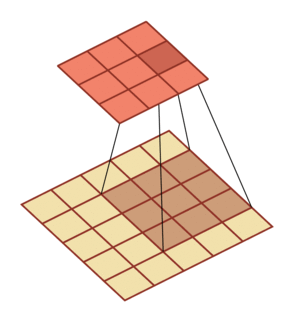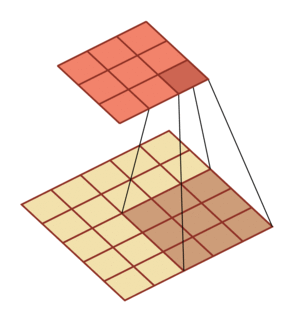 |
 |
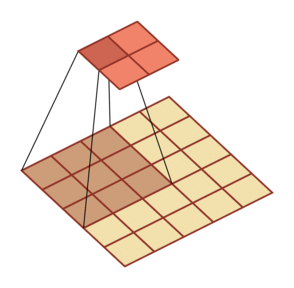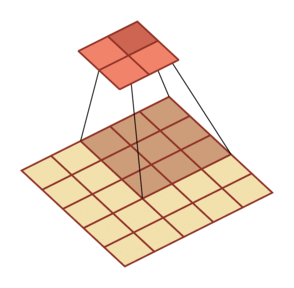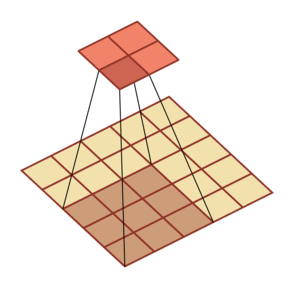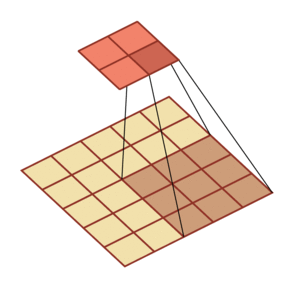
微步卷积
- 下采样:增加卷积操作的步长 S>1 来实现对输入特征的下采样,大幅降低特征维数
上采样:减少卷积操作的步长 S<1 来实现对输入特征的上采样,大幅提高特征维数
微步卷积:即步长 S<1 的转置卷积。可以通过在输入特征之间插入 0 来间接地使步长变小
- 如果卷积操作的步长为 S>1,希望其对应的转置卷积的步长为
 ,需要在输入特征之间插入 S-1 个 0 来使得其移动的速度变慢
,需要在输入特征之间插入 S-1 个 0 来使得其移动的速度变慢
- 如果卷积操作的步长为 S>1,希望其对应的转置卷积的步长为
规律:对一个 M 维的向量 z (M×M)和大小为 K 的卷积核(K×K),通过对向量 z 进行两端补零 P=K-1,并且在每两个向量元素之间插入 D 个0,然后进行步长为 1 的卷积,可以得到  维的向量
维的向量
| 卷积,输入向量大小M=5,卷积核大小K=3,零填充P=0,步长S=2 | 转置卷积,输入向量大小M=2,卷积核大小K=3,零填充P=2,插入零D=1,步长S=1 |
|---|---|
 |
 |
5.5.2 空洞卷积
卷积层增加输出单元的感受野的三种方式:
- 增加卷积核的大小
- 增加层数,eg. 两层 3×3 的卷积可以近似一层 5×5 的卷积的效果
- 在卷积之前进行汇聚(池化)操作
但,前两种方法会增加参数数量,第三种方法会丢失一些信息
空洞卷积/膨胀卷积:不增加参数数量,同时增加输出单元感受野的一种方法。
- 通过给卷积核插入“空洞”来变相的增加其大小(区别:上面的微步卷积是在输入特征之间插入0)
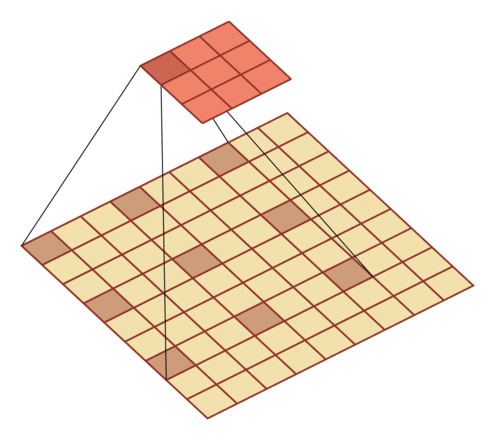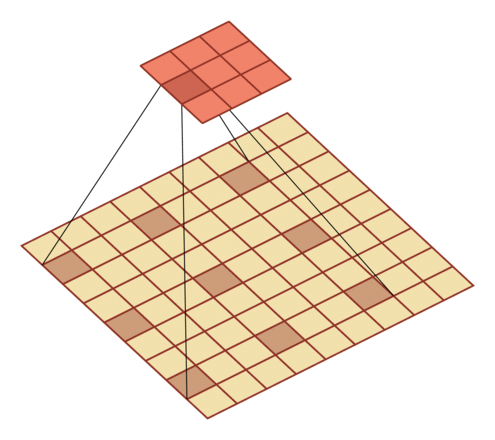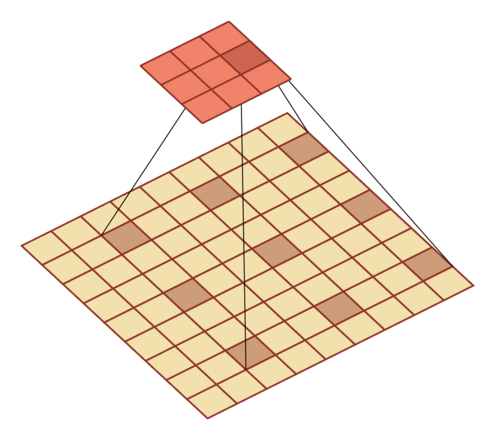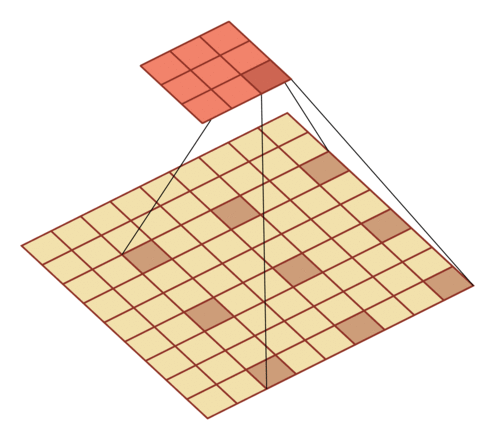
- 膨胀率 D:在卷积核每两个元素之间插入 D-1 个空洞,得到新卷积核大小
 | 输入向量大小M=7,卷积核大小K=3,零填充P=0,步长S=1,膨胀率 D=2 | 输入向量大小M=9,卷积核大小K=3,零填充P=0,步长S=1,膨胀率 D=3 |
| —- | —- |
|
| 输入向量大小M=7,卷积核大小K=3,零填充P=0,步长S=1,膨胀率 D=2 | 输入向量大小M=9,卷积核大小K=3,零填充P=0,步长S=1,膨胀率 D=3 |
| —- | —- |
| 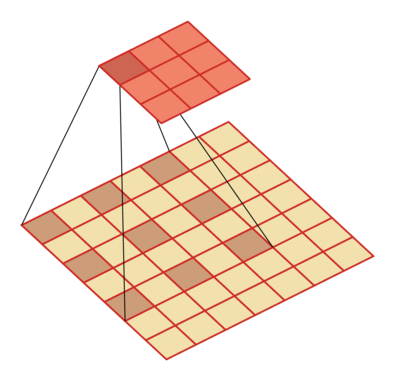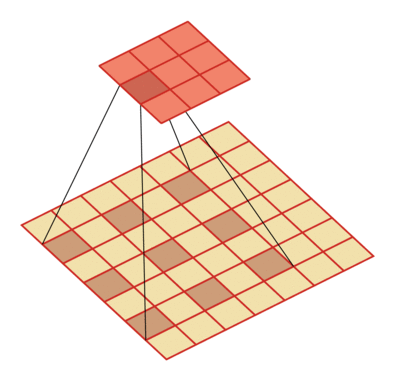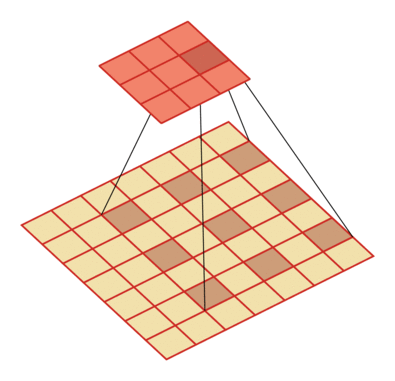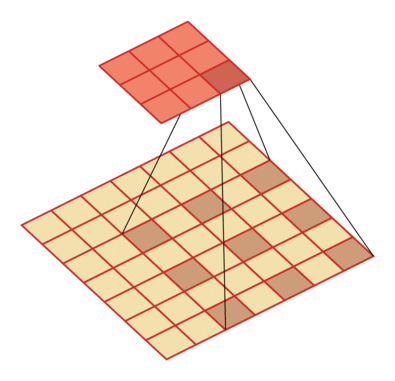 |
|  |
|
5.6 总结和深入阅读
- 目前,卷积神经网络已经成为计算机视觉领域的主流模型
- 通过引入跨层的直连边(残差连接),可以训练上百层乃至上千层的卷积网络
- 随着网络层数的增加,卷积层越来越多地使用 1×1 和 3×3 大小的小卷积核,也出现了一些不规则的卷积操作,eg. 空洞卷积、可变性卷积等
- 网络结构也逐渐趋向于全卷积网络,减少汇聚层(池化层)和全连接层的作用
习题(解答) 参考
习题 5-1 1)证明公式 (5.6)
可以近似为离散信号序列 𝑥(𝑡) 关于 𝑡 的二阶微分; 2)对于二维卷积, 设计一种滤波器来近似实现对二维输入信号的二阶微分.
1) 
2) 对于二位输入信号,由公式 5.6,可得:


- 所以,二维的二阶微分为:

- 所以,可以设计滤波器:
 ,也称为 Laplace算子
,也称为 Laplace算子
习题 5-2 证明宽卷积具有交换性, 即公式(5.13)
习题 5-3 分析卷积神经网络中用1 × 1的卷积核的作用
1×1的卷积核在实际应用中类似于一根截面积为1个像素的正方形管道,用来贯穿整个输入特征。每个1×1的卷积核都试图提取基于相同像素位置的特征的融合表达。可以实现特征升维和降维的目的。并且增加了网络的非线性,提高拟合能力。
习题 5-4 对于一个输入为100 × 100 × 256的特征映射组, 使用3 × 3的卷积核, 输出为100 × 100 × 256的特征映射组的卷积层, 求其时间和空间复杂度. 如果引入一个1 × 1卷积核, 先得到100 × 100 × 64的特征映射, 再进行3 × 3的卷积, 得到100 × 100 × 256的特征映射组, 求其时间和空间复杂度
3×3的卷积核:
- 每一个卷积核移动100×100次,每次移动需计算256(深度)×3×3个乘积,一共有256个卷积核,所以时间复杂度:100×100×256×3×3×256=5898240000
- 空间复杂度:100×100×256=2560000
1×1的卷积核:
- 时间复杂度:100×100×256×1×1×64+100×100×64×3×3×256=1638400000
- 空间复杂度:100×100×64+100×100×256=3200000
习题 5-5 对于一个二维卷积, 输入为3 × 3, 卷积核大小为2 × 2, 试将卷积操作重写为仿射变换的形式 参见公式 5.45
(对应于输入x为5 × 5,卷积核大小为3 × 3)

习题 5-6 计算函数
和函数
的梯度.
习题 5-7 忽略激活函数, 分析卷积网络中卷积层的前向计算和反向传播( 公式(5.39)
) 是一种转置关系
习题 5-8 在空洞卷积中, 当卷积核大小为𝐾, 膨胀率为𝐷时, 如何设置零填充𝑃 的值以使得卷积为等宽卷积.
对于空洞卷积,
等宽卷积:

若有收获,就点个赞吧
0 人点赞
