视频:李宏毅 Sequence-to-sequence Learning 1:00 开始的部分
RNN(Recurrent Neural Network)
- 输入:向量序列

- 输出:向量序列

- basic function f:

- 输入:前一时刻的隐状态
 和 当前时刻 RNN 的输入
和 当前时刻 RNN 的输入 
- 输出:当前时刻的隐状态
 和 当前时刻 RNN 的输出
和 当前时刻 RNN 的输出 
- RNN 不同时刻反复使用同一个 basic function
- 因此不论输入/输出序列有多长,参数数量都是固定的
- 输入:前一时刻的隐状态

Deep RNN
每一层分别使用一个 basic function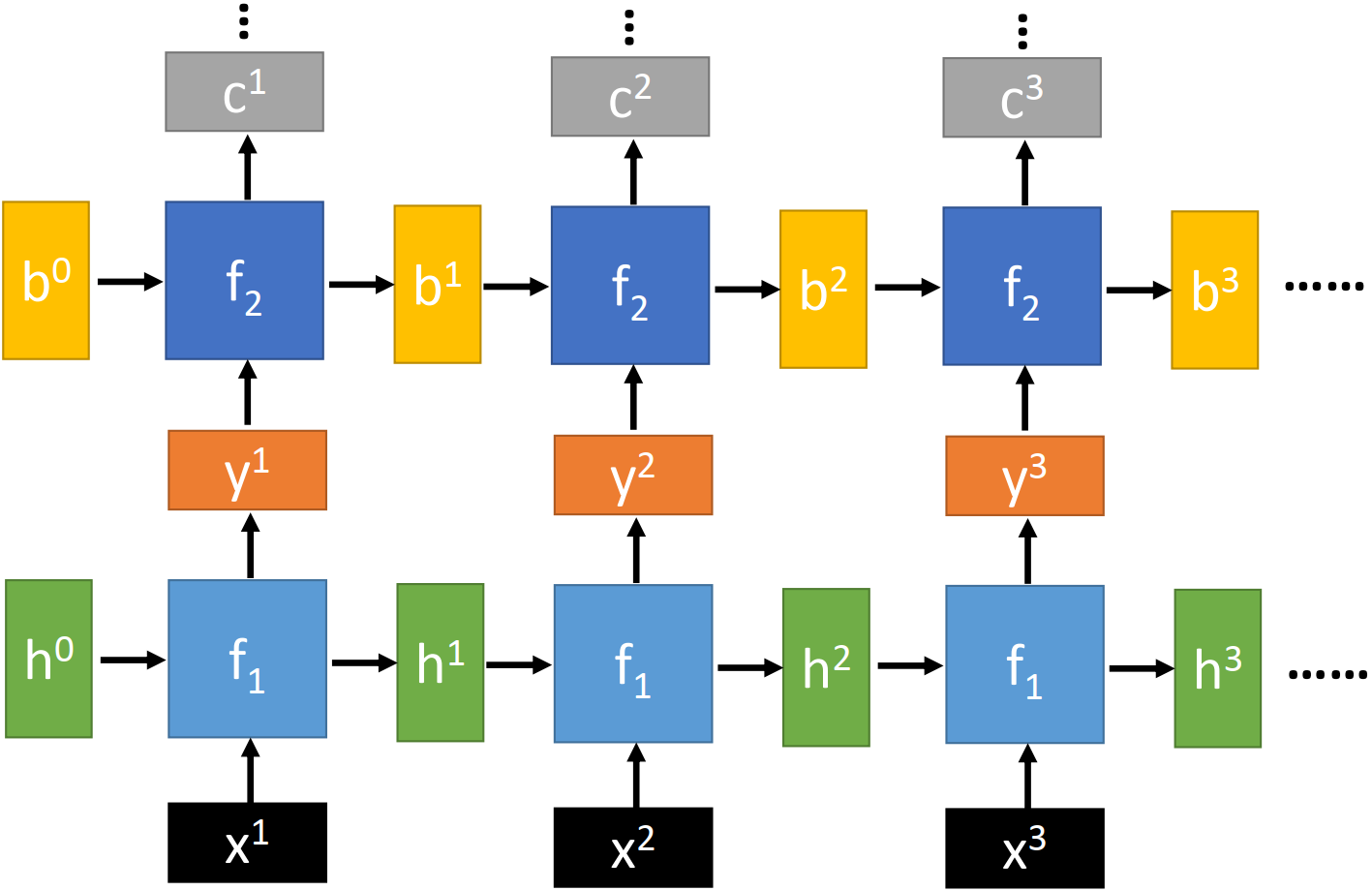
双向 RNN
 按正序
按正序  依次读入输入向量序列
依次读入输入向量序列 按逆序
按逆序  依次读入输入向量序列
依次读入输入向量序列 读入
读入  和
和  的输出,输出向量序列
的输出,输出向量序列 
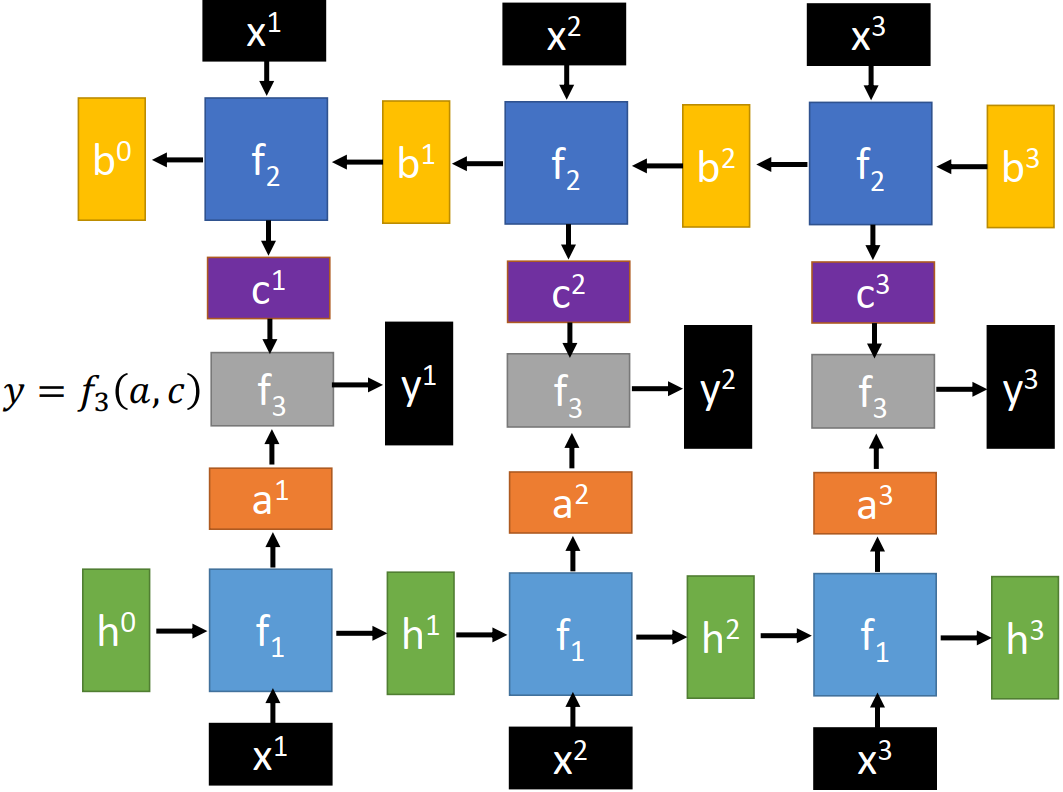
RNN 的 basic function f
Naive RNN
RNN 的 basic function f 最简单的设计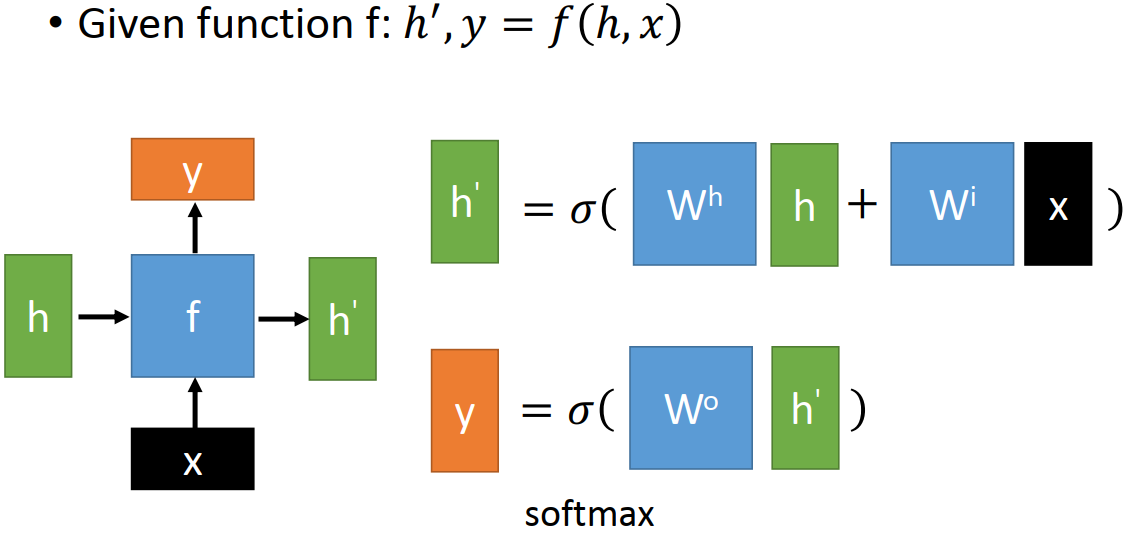
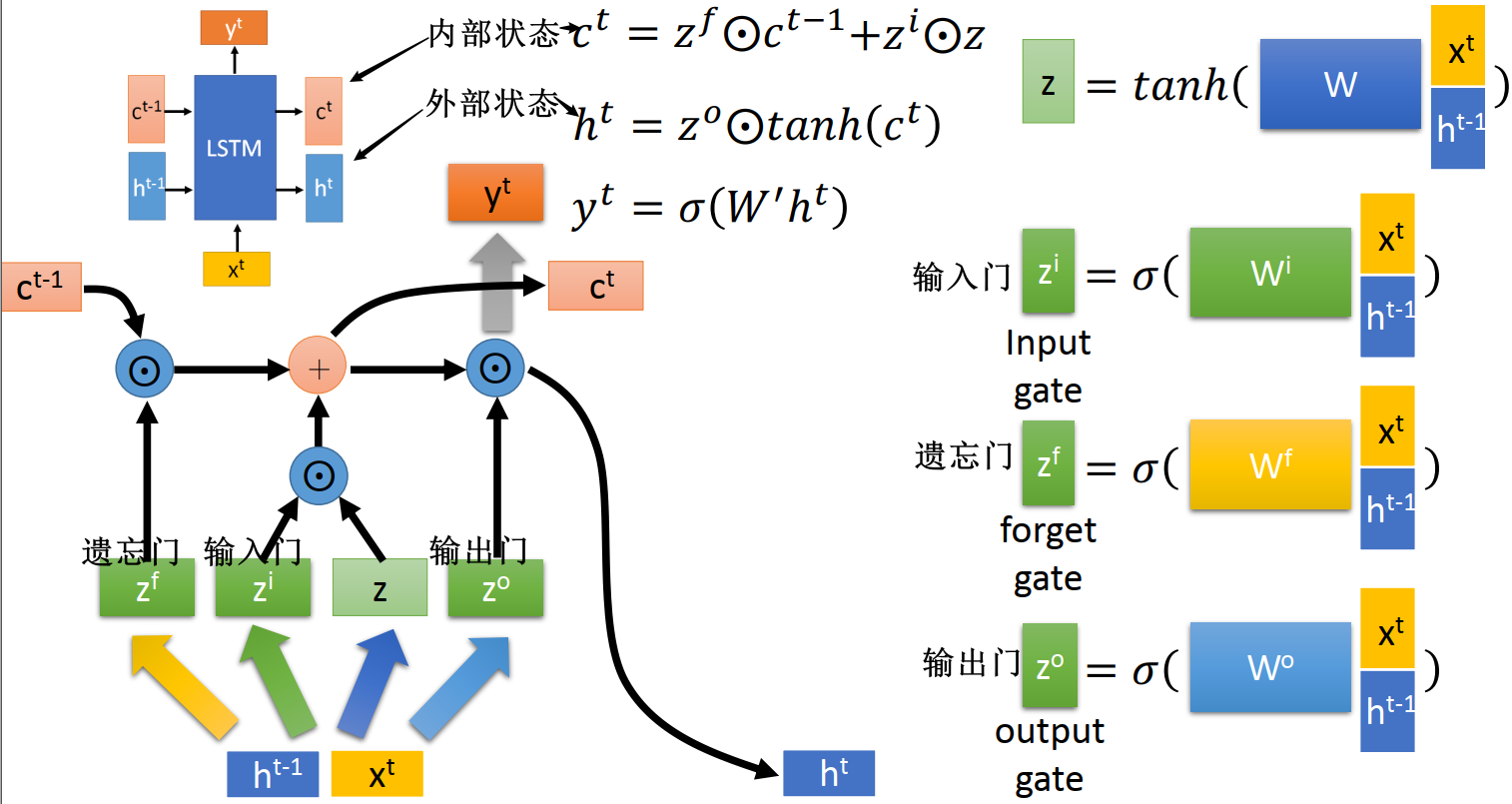
LSTM 长短期记忆网络
详见 LSTM
实际上 LSTM 才是 basic function 最常见的设计,现在一般说用 RNN 用的就是 LSTM
LSTM 将 RNN 的隐状态  拆分为两个状态:
拆分为两个状态:
- 内部状态
 :改变比较缓慢的 memory,
:改变比较缓慢的 memory, 和
和  很像,可以记住长时间的资讯
很像,可以记住长时间的资讯 - 外部状态
 :改变比较快,
:改变比较快, 和
和  差异很大
差异很大
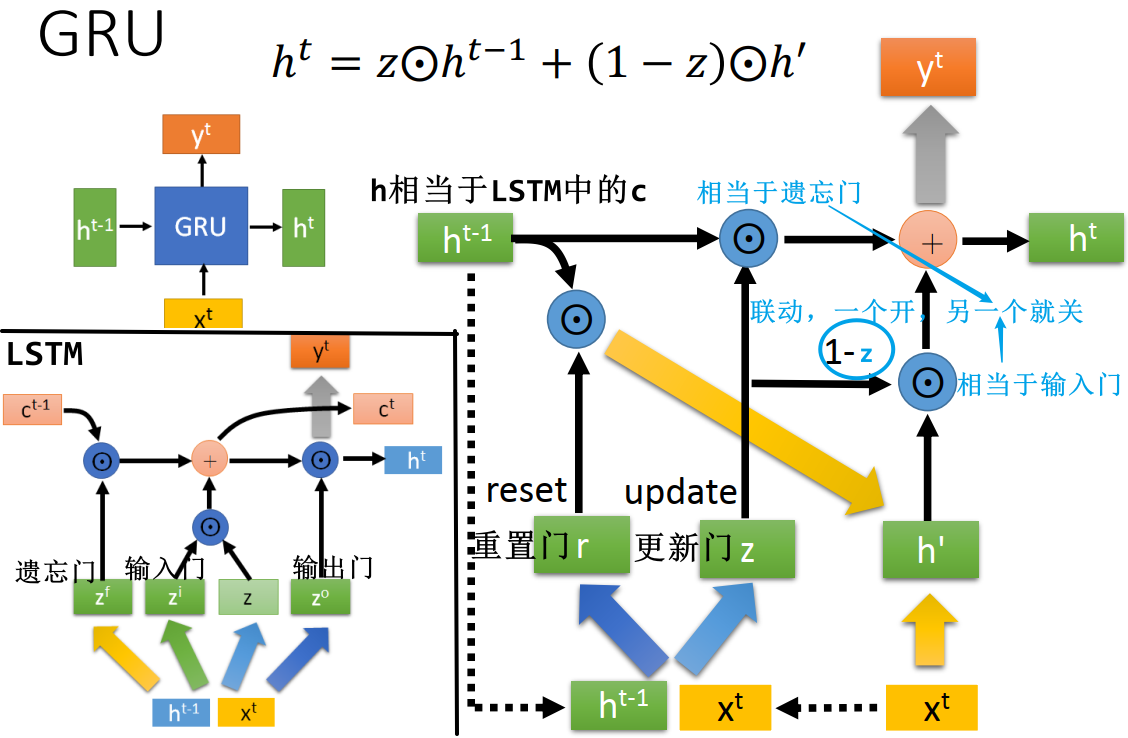
GRU 门控循环单元网络
详见 GRU
GRU 是另一种常用的 RNN basic function
- GRU 相当于 LSTM 中的遗忘门和输入门联动,一个开,另一个就关
- GRU 参数量比 LSTM 少,能减少过拟合的可能性
- 下图中每个粗箭头代表乘上一个 linear transform W,不同颜色的粗箭头代表不同的 W
- 可见不算求
 用到的 linear transform,LSTM 共需要 4 个,而 GRU 需要 3 个
用到的 linear transform,LSTM 共需要 4 个,而 GRU 需要 3 个

若有收获,就点个赞吧
0 人点赞
