李宏毅【机器学习2021】课程主页: MACHINE LEARNING 2021 SPRING
1、生成 Generation
视频链接:【機器學習2021】生成式對抗網路 (Generative Adversarial Network, GAN) (一) – 基本概念介紹
生成:
- 一般对于一个神经网络,输入一个 x,输出一个固定的 y
- 而生成器不同,增加了一个从某个分布采样的随机向量 z 作为输入,输出的 y 不再是固定的,而是变为一个复杂的分布
1.1 生成器 Generator
- 输入:(关于两个输入如何处理,可以将两个向量直接拼接起来 or 相加 or 其他办法)
- x:在条件式 GAN 中 x 是条件,在非条件式 GAN 中输入没有 x,只有 z
- z:随机向量 z 是从某个简单分布采样得到的,不固定,每次都不一样
- 分布必须足够简单,即我们需要知道这个分布的公式,才可以从这个分布中采样
- 输出:
- y:由于输入的 z 的不同,每次输出的 y 也不同,因此输出不再是固定的,而是一个复杂的分布

1.1.1 为什么需要输出是分布?
问题:输入一个 x,输出一个固定的 y 不好吗?为什么有时候需要输出 y 是一个分布呢?
eg. 视频下一帧预测:
- 输入是之前的一些帧,输出下一帧
- 如下图所示,对于同样的前面几帧画面 x,数据集中可能同时存在往左走、往右走的标签,即数据集包含 (x, turn left),(x, turn right) 这两种同输入但不同标签的训练数据
- 那么,网络就可能学习到错误的结果,输出图像中既向左走,又向右走,于是小精灵分裂了

- 因此,一种处理以上问题的方法就是:让机器的输出不再是单一的固定输出,而是有几率的,即让输出变成一个分布
什么时候需要输出是一个分布?→ 即什么时候需要一个生成模型?
- 当同一个输入可以有多种可能的输出,且这些不同的输出都是对的(也就是这个任务需要一点创造力)
- eg. 绘画、聊天机器人

1.2 GAN(Generative Adversarial Network)
各种各样的GAN:the GAN zoo - GitHub
GAN 生成对抗网络:(以动漫人脸生成为例)
- 生成器 Generator:
- 输入:注意,一般的 GAN 是无条件生成,因此生成器的输入只有 z,没有条件 x
- z:从一个正态分布(normal distribution)中采样出来的向量,通常是一个低维向量(维度自己决定)
- 输出:
- y:通常是高维向量,比如图片就是高维向量(eg. 64×64×3),服从某个复杂分布
- 输入:注意,一般的 GAN 是无条件生成,因此生成器的输入只有 z,没有条件 x

- 鉴别器 Discriminator:
- 输入:图像
- 输出:数值 scalar,数值越大说明鉴别为真,数值小说明鉴别为假

1.2.1 GAN 的训练过程
- 初始化生成器 G 和鉴别器 D 的参数
- 在每个训练迭代中:
- 步骤 1:固定生成器 G,只训练更新鉴别器 D 的参数
- 将数据集中采样的真实图像打上标签 1,将生成器 G 生成的图像打上标签 0,作为训练数据训练鉴别器 D,让鉴别器 D 学会给真实图像打高分,给生成图像打低分,即学会鉴别真实图像和生成图像
- 步骤 1:固定生成器 G,只训练更新鉴别器 D 的参数

- 步骤 2:固定鉴别器 D,只训练更新生成器 G 的参数
- 生成器 G 的训练目标是让它生成的图像骗过鉴别器 D,即让鉴别器 D 输出的值越大越好
- 可以将生成器 G 和鉴别器 D 看作一个大网络(整体),生成器的输出就相当于这个大网络的某个隐藏层输出

总体训练过程如下所示:
1.2.2 进阶: Style GAN
Style GAN 论文:A Style-Based Generator Architecture for Generative Adversarial Networks Style GAN v2 论文:Analyzing and Improving the Image Quality of StyleGAN 博文:Making Anime Faces With StyleGAN
1.2.3 进阶:Progressive GAN
论文:Progressive Growing of GANs for Improved Quality, Stability, and Variation
使用 GAN 能产生没见过的人脸,还能把输入向量做内插(interpolation),观察生成图像的连续变化
假设两个输入  ,会生成两张人脸图像
,会生成两张人脸图像  ,把两个输入向量
,把两个输入向量  做内插,得到一组输入向量,通过 GAN 的生成器,就得到一组从
做内插,得到一组输入向量,通过 GAN 的生成器,就得到一组从  逐渐过渡到
逐渐过渡到  的生成图像
的生成图像
2、GAN 的理论介绍 & 训练技巧——WGAN
视频链接:【機器學習2021】生成式對抗網路 (Generative Adversarial Network, GAN) (二) – 理論介紹與WGAN
2.1 GAN 的训练目标
口语化的训练目标:将从正态分布中采样出来的向量输入到生成器,输出是复杂的分布  ,希望
,希望  和真实数据的分布
和真实数据的分布  越接近越好
越接近越好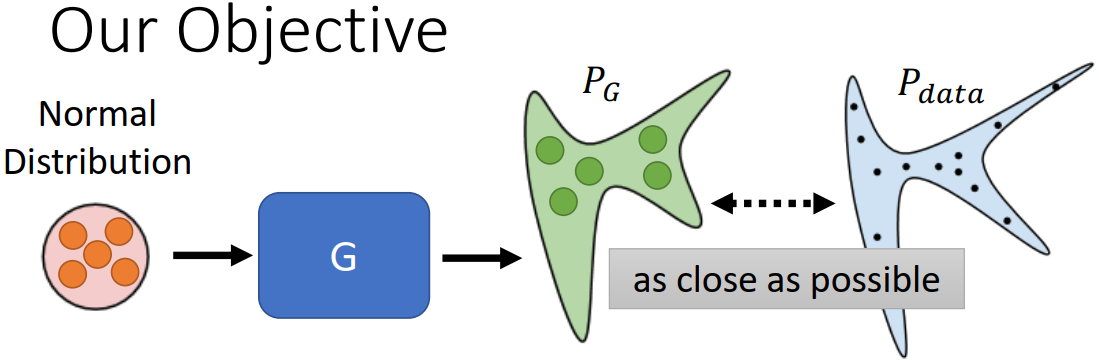
公式化的训练目标:
- 散度(Divergence):
 ,是两个分布
,是两个分布  和
和  之间的散度(距离)
之间的散度(距离)
问题:在连续分布上算不出散度
- 解决:对于 GAN,虽然不知道
 和
和  实际上完整的表达式,但只要能采样,就能估测出散度
实际上完整的表达式,但只要能采样,就能估测出散度- 靠的就是鉴别器

2.2 鉴别器的训练目标——JS 散度
鉴别器的训练目标:
- Objective Function(目标函数) for D:

- 总体上我们希望
 越大越好,那么就希望从
越大越好,那么就希望从  里采样出来的 y 对应的
里采样出来的 y 对应的  越大越好,希望从
越大越好,希望从  里采样出来的 y 对应的
里采样出来的 y 对应的  越小越好
越小越好 - 之所以将目标函数写成这个形式,是为了和二元分类扯上关系,实际上也可以是别的形式
- 上面这个形式的
 实际上就是交叉熵×负号,最大化
实际上就是交叉熵×负号,最大化  实际上就相当于最小化交叉熵,就等于在训练一个分类器。这个鉴别器就可以当作是分类器
实际上就相当于最小化交叉熵,就等于在训练一个分类器。这个鉴别器就可以当作是分类器 - 以上这个目标函数的最大值
 和 JS divergence(JS 散度) 有关
和 JS divergence(JS 散度) 有关- 如果
 和
和  很像,距离小,分类器就很难鉴别,就没有办法让目标函数的值很大,也就是小的 divergence 就对应到小的目标函数的最大值
很像,距离小,分类器就很难鉴别,就没有办法让目标函数的值很大,也就是小的 divergence 就对应到小的目标函数的最大值 
- 要 maximize 的东西称为 objective function(目标函数)
- 要 minimize 的东西称为 loss function(损失函数)
- 如果
- 总体上我们希望

因此,就可以用  代替 JS 散度
代替 JS 散度 
∴ GAN 的训练目标就变成:
同理,只要改变上面鉴别器的目标函数的形式,就可以使用各式各样的散度。参考论文:f-GAN: Training Generative Neural Samplers using Variational Divergence Minimization,详细介绍了怎么样设计目标函数来得到不同的散度
2.3 GAN 的训练技巧
2.3.1 JS 散度的问题
上面介绍了 GAN 的训练目标是要最小化 JS 散度,但 JS 散度实际上并不适合 GAN
在多数情形下, 和
和  几乎不重叠(or 重叠的部分往往非常小),两个原因:
几乎不重叠(or 重叠的部分往往非常小),两个原因:
- 数据本身的特性:两个分布
 和
和  的数据都是图像,图像是高维空间一个低维的 manifold。高维空间中随便采样一个点一般都不是图像,只有非常小的范围采样出来的是图像。以生成二次元人物头像为例,二次元人物头像的分布在高维空间中非常狭窄,可能就是二维空间的一条线。二维空间的两条线,除非刚好重合,否则相交范围几乎可以忽略
的数据都是图像,图像是高维空间一个低维的 manifold。高维空间中随便采样一个点一般都不是图像,只有非常小的范围采样出来的是图像。以生成二次元人物头像为例,二次元人物头像的分布在高维空间中非常狭窄,可能就是二维空间的一条线。二维空间的两条线,除非刚好重合,否则相交范围几乎可以忽略 - 采样带来的问题:即使
 和
和  有很大的重合范围,但我们只是通过采样来了解这两个分布,如果采样的点不够多,对鉴别器(分类器)来说,仍然可以轻松地画一条线区分开,也就以为这两个分布没有重叠
有很大的重合范围,但我们只是通过采样来了解这两个分布,如果采样的点不够多,对鉴别器(分类器)来说,仍然可以轻松地画一条线区分开,也就以为这两个分布没有重叠

JS 散度的问题:如果两个分布没有重叠,JS 散度的值总为 log2
- 如下图所示,不管两个分布的距离远近,只要两个分布不重叠,那么 JS 散度总为 2;除非两个分布有重叠,值才不为 log2
- 换一种角度,如果两个分布没有重叠,二分类器(鉴别器)总能取得 100% 的分类准确率(入上图所示,分类器总能用一条线将两个分布采样出来的点区分开)
- 因此,在过去,准确率(或损失值)对 GAN 的训练是没有意义的,没法通过损失值的变化来了解训练结果的好坏,只能人眼观察图像

2.3.2 改进:Wasserstein distance
既然是 JS 散度的问题导致 GAN 训练困难,那么可以换一个衡量两个分布相似程度的方式,即换一个散度 divergence —— Wasserstein distance
Wasserstein distance(Wasserstein 距离,也称 Earth-Mover 距离,即推土机距离,简称 EM 距离)
- 对于两个分布,将其中一个分布 P 想象成一堆土,另一个分布 P 想象成要把土堆放的目的地,用推土机将 P 这边的土堆拖到 Q 所移动的平均距离,就是 Wasserstein distance

但是,对于更复杂的分布,要算 Wasserstein distance 有点困难:假设你开推土机,想把下图的 P 重新塑造成接近 Q 的形状,有无穷多种移动方法(moving plans),而不同的方法算出来的平均距离就不一样。
Wasserstein distance 更准确的定义:看哪一种移动方法可以得到最小的平均距离,这个最小的平均距离就是 Wasserstein distance
Wasserstein distance 的好处:即使两个分布没有重叠,但只要两个分布的距离更近,Wasserstein distance(即平均距离)自然就更小。因此,使用 Wasserstein distance,每次训练只要稍微将  往
往  挪近一点,Wasserstein distance 就能变得更小,这样就有办法逐步训练,使得两个分布越来越接近
挪近一点,Wasserstein distance 就能变得更小,这样就有办法逐步训练,使得两个分布越来越接近
- 而之前的 JS 散度,两个没有重叠得分布离得近一点远一点 JS 散度值都为 log2,除非一步训练就将两个分布 aligne 到一起了,JS 散度值才会有变化,但这很困难

2.3.4 WGAN
上面介绍了 Wasserstein distance,那么如何估测  和
和  之间的 Wasserstein distance?
之间的 Wasserstein distance?
2.2 节曾讲过:只要改变鉴别器的目标函数的形式,就可以使用各种各样得散度
对于 Wasserstein distance,目标函数的最大值  的表达式:
的表达式:
- 希望从
 里采样出来的 y 对应的
里采样出来的 y 对应的  越大越好,希望从
越大越好,希望从  里采样出来的 y 对应的
里采样出来的 y 对应的  越小越好
越小越好 - 解以上这个优化问题解出来的值就是 Wasserstein distance
- 上述公式除了 max 这个限制外,还有一个限制就是鉴别器 D 必须是一个 1-Lipschitz 的函数(一个足够平滑的函数)
- 如果没有这个限制,鉴别器的训练就不会收敛,如下图所示,只要两个分布无重叠,从
 里采样出来的 y 对应的
里采样出来的 y 对应的  就会趋向正无穷,而从
就会趋向正无穷,而从  里采样出来的 y 对应的
里采样出来的 y 对应的  就会趋向负无穷,整个结果就是无限大,没法收敛
就会趋向负无穷,整个结果就是无限大,没法收敛 - 而加入这个限制,要求 D 的函数必须平滑,就没法出现上述趋向正无穷、负无穷的情况,否则就会很尖锐而不平滑,不符合限制
- 如果没有这个限制,鉴别器的训练就不会收敛,如下图所示,只要两个分布无重叠,从

如何实现  的限制?
的限制?
- 原始的 WGAN,是强制参数 w 的取值在 c 和 -c 之间。参数更新后,如果 w>c,就让 w=c;如果 w<-c,就让 w=-c。但这种做法比较粗糙,并不一定真的能做到 1-Lipschitz,只是让鉴别器 D 的 function 变得比较平滑
- 改进的 WGAN:使用梯度惩罚机制,在两个分布中分别采样一个点,两点之间连线,再连线上再采样一个点,要求这个点的梯度接近 1

- 真正做到 1-Lipschitz 的效果最好的方法:Spectral Normalization(SNGAN) → Keep gradient norm smaller than 1 everywhere
2.3.5 其它训练技巧
即使有了 WGAN,实际上 GAN 依然很难训练
GAN 本质上困难的地方:生成器和鉴别器两者必须始终保持棋逢对手,互相砥砺才能互相进步。
- 只要其中一者发生什么问题,停止训练,另外一者也会跟着停止训练,跟着变差
- 但训练网络时我们没法保证 loss 能一直下降,没法保证两者始终不出问题

更多训练技巧:
- Tips from Soumith
- Tips in DCGAN: Guideline for network architecture design for image generation
- Improved techniques for training GANs
- Tips from BigGAN
实际上,训练 GAN 最难的是用 GAN 来生成一段文字(序列)
- 难点:无法做到用梯度下降训练生成器(eg. Transformer 的 Decoder),来让鉴别器输出的分数越大越好
- 原因:梯度就是某一个参数有变化时对目标造成的影响大小。现在假设改变了 Decoder 的参数(小变化),因为变化很小,输出时取 max 并不受影响,因此输出结果仍是一模一样的,那么鉴别器输出的分数也没变化,因此根本没法做梯度下降
- 想法:遇到不能用梯度下降训练的问题,就当作强化学习的问题硬做一下就结束了
- 问题:强化学习和 GAN 都是以难训练著称的,加在一起根本训练不起来
- 因此,很长的时间里,没有人可以用正常方法来训练一个生成器产生一段文字
- 通常需要做预训练,然后对生成器进行微调
- ScarchGAN:谷歌通过爆搜超参数和使用一大堆的 tips,ScarchGAN 可以直接从随机初始化的参数开始从零训练生成器,让生成器产生文字
GAN 的完整课程:李宏毅 GAN 2018 完整课程
3、条件式生成 Conditional Generation
视频链接:李宏毅【機器學習2021】生成式對抗網路 (Generative Adversarial Network, GAN) (三) – 条件式生成
前面讲的生成器的输入都只是随机的分布,这不见得非常有用,现在想要进一步可以操控生成器的输出,给生成器一个条件(condition)x,让生成器根据条件 x 和随机分布 z 来产生输出 y 
用途:eg. 文字描述生成人脸图片,需要有标注数据,做监督训练
- x 就是一段文字,其输入到生成器有多种方法,eg. :
- 方法一:将 x 通过 RNN 读进去,生成一个向量,再输入到生成器
- 方法二:将 x 输入到 Transformer Encoder,把 Encoder 的输出向量通通平均起来,输入到生成器
- 每次生成器生成的图像都不一样,这取决于输入的随机分布 z,但通通是满足 x 的描述的(eg. 红眼睛)
3.1 Conditional GAN
Conditional GAN 的训练一般需要有标注的成对数据。
生成器:
- 输入:
- 条件 x:在这个例子中是一段文字描述
- 随机分布中采样的 z:

鉴别器:
- 输入:
- 图像 y:鉴别器需判定 y 是真实图像还是生成的图像
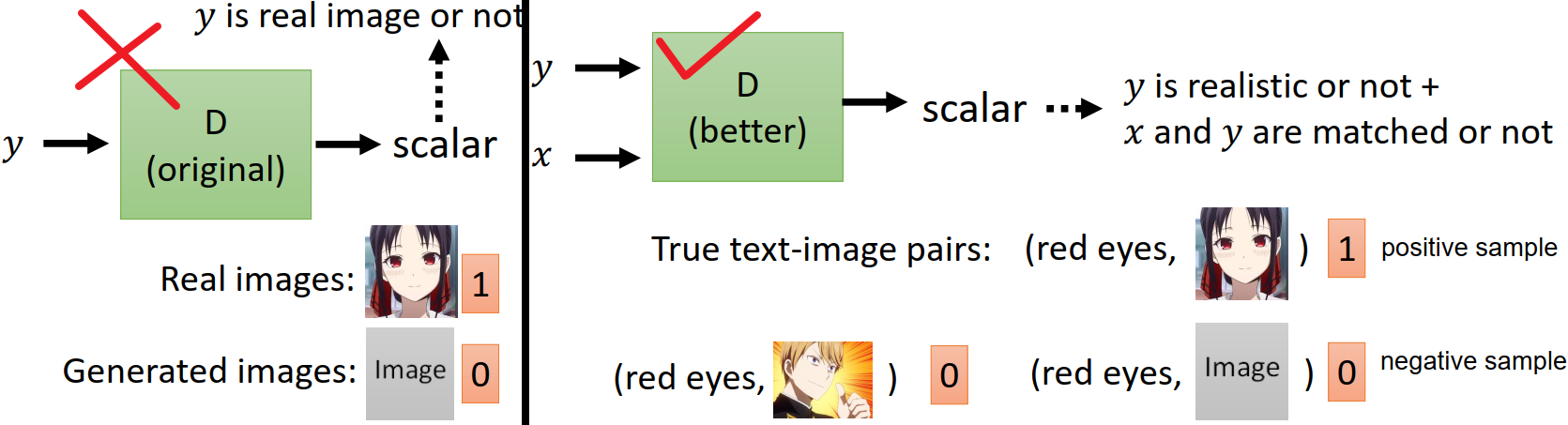
- 条件 x:如果只是让鉴别器判定图像 y 是否为真是图像,可能会造成生成器的输出忽视输入条件的情况,即生成一张能骗过鉴别器的接近真实的图像,但和输入的条件没有关系。因此还需要让鉴别器鉴别图像 y 是否符合条件 x
- 训练鉴别器的三种成对的数据对:
- positive sample:真实图像,输入的条件
- negative sample:合成的假的图像,输入的条件
- 合成的效果接近真实图像但和条件的文字描述配不上的图片,输入的条件
- 光是 positive sample 和 negative sample 来训练鉴别器得到的鉴别器性能往往不够好,还需要加上这种不好的状况:即已经产生好的图片但和输入的文字叙述配不上的情况
3.2 其它应用
Conditional GAN 除了上面描述的看一段文字描述来生成图片,还有很多应用,eg.
- Image Translation(pix2pix),即看一张图片,生成一张图片:eg. 输入房屋设计图,输出房子图片;or 输入黑白图片,输出着色的图片; or 输入白天图片,输出夜晚图片;输入有雾的图片,输出去雾的图片等
- 如果用监督学习的方法训练一个图片生成图片的生成器,通常得不到好的结果。因为同样的输入有不同的输出可能,生成器学到的就是把不同的可能平均起来,结果就得到一个模糊的图片
- 因此需要 GAN 来训练,即加一个判别器,输入是一张图片和一个 condition。但单纯用 GAN 的话,其产生出来的图片虽然比较真实,但是有个小问题,由于 GAN 的想象力过于丰富,会产生一些输入没有的东西
- GAN 和 监督学习同时使用,能得到最好的效果。也就是生成器在训练时有两个训练目标:
- 训练目标 1:生成的图片要能骗过鉴别器
- 训练目标 2:生成的图片和 ground truth 的图片越像越好

4、Cycle GAN —— 无监督学习
视频链接:李宏毅【機器學習2021】生成式對抗網路 (Generative Adversarial Network, GAN) (四) – Cycle GAN
4.1 使用非成对数据学习 Learning from unpaired data
实际上,我们在做深度学习时可能遇到没有成对数据(无标注数据)的情况,也就是说,我们有一堆 X 域的数据和一堆 Y 域的数据,但它们不是成对的,因此我们无法利用这些数据做监督学习。
那如何使用 unpaired data 来训练?
- 方法一:半监督学习 Semi-supervised learning
- 伪标签 pseudo labeling:本课程的作业 3
- back translation:本课程的作业 5
但半监督学习实际上仍需要部分有标注的成对数据来训练一个模型
- 方法二:无监督学习 Unsupervised learning
- eg. 图像风格转换,输入是真人头像照片,希望输出是对应的动漫头像图片,我们可以获取大量 domain X 的图像(真人头像照片)和 domain Y 的图像(动漫头像图片),但是是 unpaired data。即使要获取少量的成对数据成本也很高,因为这不是简单的数据标注,需要专门找画师将真人头像画成动漫。因此,无法做半监督学习,只能做无监督学习
- GAN 实现无监督学习:Cycle GAN

4.2 Cycle GAN
参考:语音转换 - Cycle GAN 论文:Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks 不同团队几乎同时发表的文章,模型命名不同,但实际就是 Cycle GAN:
原始的 GAN 包含一个生成器  和一个鉴别器
和一个鉴别器  ,生成器的训练目标是让生成的图像能骗过鉴别器
,生成器的训练目标是让生成的图像能骗过鉴别器  ,鉴别器
,鉴别器  的训练目标则是能分别出生成器
的训练目标则是能分别出生成器  生成的图像和真实的 Domain Y 的图像(对抗训练)。
生成的图像和真实的 Domain Y 的图像(对抗训练)。
但如果直接将原始的 GAN 直接用于真人照片转漫画的图像风格转换任务,会导致一个问题:生成器  可能无视输入的图像,而只是随意输出一张和输入无关的漫画图片,期望这张输出的图片能骗过,鉴别器
可能无视输入的图像,而只是随意输出一张和输入无关的漫画图片,期望这张输出的图片能骗过,鉴别器  。
。
- eg. 输入李宏毅的照片,输出一张女孩子的漫画图像,这也能骗过鉴别器,但不符合要求
因此,Cycle GAN 的结构如下图所示,新增了一个将漫画图像转会真人头像的的生成器  ,希望其转回的真人头像图片和输入的照片越接近越好。
,希望其转回的真人头像图片和输入的照片越接近越好。
∴ Cycle GAN 的生成器包含两个训练目标:
- 训练目标 1:希望生成器
 生成的图像能骗过鉴别器
生成的图像能骗过鉴别器 
- 训练目标 2:希望生成器
 生成的图像再通过生成器
生成的图像再通过生成器  还原生成的图像和输入的图像越像越好,即 Cycle consistency 循环一致性
还原生成的图像和输入的图像越像越好,即 Cycle consistency 循环一致性

Cycle GAN 通过加入新的生成器  和训练目标 2 来强迫生成器
和训练目标 2 来强迫生成器  生成的动漫图像至少和输入的图像有一些关系。但如何保证这个关系就是我们想要的关系呢?机器有没有可能学到很奇怪的转换,比如输入一个戴眼镜的人,生成器
生成的动漫图像至少和输入的图像有一些关系。但如何保证这个关系就是我们想要的关系呢?机器有没有可能学到很奇怪的转换,比如输入一个戴眼镜的人,生成器  看到眼镜,就生成抹掉眼镜但有一颗痣的图像,然后生成器
看到眼镜,就生成抹掉眼镜但有一颗痣的图像,然后生成器  看到痣就还原为眼镜?这样仍可以满足循环一致性(训练目标 2),因此实际上这有可能发生,但目前没有很好的解法。但是,实际上,使用 Cycle GAN 的时候,这种情况没那么容易发生,生成器
看到痣就还原为眼镜?这样仍可以满足循环一致性(训练目标 2),因此实际上这有可能发生,但目前没有很好的解法。但是,实际上,使用 Cycle GAN 的时候,这种情况没那么容易发生,生成器  的输入输出往往真的看起来就非常像。甚至在实作中不用 Cycle GAN,就用一般的 GAN,即去掉生成器
的输入输出往往真的看起来就非常像。甚至在实作中不用 Cycle GAN,就用一般的 GAN,即去掉生成器  ,这种图像风格转换的任务往往也做得起来。因为在实作时,我们会发现网络其实非常懒惰,它输入一张图片,往往默认就是输出很像的东西,而不想做太复杂的转换。因此实作中这往往不是很大的问题,但在理论上,即使你加上了循环一致性,似乎也没法保证生成器输入和输出的图片一定要很像,这是实作和理论的差异
,这种图像风格转换的任务往往也做得起来。因为在实作时,我们会发现网络其实非常懒惰,它输入一张图片,往往默认就是输出很像的东西,而不想做太复杂的转换。因此实作中这往往不是很大的问题,但在理论上,即使你加上了循环一致性,似乎也没法保证生成器输入和输出的图片一定要很像,这是实作和理论的差异
4.3 双向 Cycle GAN
Cycle GAN 可以是双向的,可以同时做另外一个方向的训练
4.4 进阶:Star GAN
参考:语音转换 - Star GAN 论文:StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation
5、生成器性能评估
视频链接:【機器學習2021】生成式對抗網路 (Generative Adversarial Network, GAN) (三) – 生成器效能評估
生成图像质量(Quality)的评估:
- 很长一段时间都没有很好的评估方法,只能靠人眼看(不客观也不稳定)
- 针对特定任务,有办法设计一些方法来自动评估
- eg. 评估标准:跑一个动画人物人脸侦测系统,例如输入 1000 张生成的图像,被检测出 900 张人脸,那么就比只检测出 300 张人脸的好
- 评估方法:使用一个图像分类器,输入一张生成的图像,输出各类别的概率分布越集中,代表生成的图片很可能就越好

问题:如果仅使用上述的图像分类器来评估,可能会被两种问题骗过去:
- Mode Collapse(模式坍塌):生成的图像来来去去就类似的几张,缺乏多样性。也就是生成器可能发现了鉴别器的一个盲点,当生成器学会生成这样的图片之后,就永远都可以骗过鉴别器
- 没法彻底解决。一种做法是训练时保存训练点,将发生模式坍塌之前的模型拿出来用
- Mode Dropping:表面看起来多样性也足够,但实际上生成的图像的分布只是相当于真实图像分布的一部分
- 比模式坍塌更难被侦测到

生成图像多样性(Diversity)的评估:
- 也使用一个图像分类器,输入一堆生成的图像,输出的平均分布如果非常集中,就代表多样性不够;输出的平均分布如果非常平坦,则代表多样性也许是足够的
- 问题:图像质量和多样性的评估有点互斥,分布集中代表图像质量高,但分布平坦才代表图像多样性好。不过两者评估范围不一样,质量评估是只看一张图片,多样性评估看的是一堆图片

生成器的性能评估指标:
- IS (Inception Score):生成的图像质量高,多样性好,IS 分数就高
- 问题:例如动漫人物头像生成任务,即使生成的图像发色、瞳色等不同,有多样性,但对于机器来说,觉得都是人脸,多样性不高,IS 的分数就低
- FID (Frerchet Inception Distance):分数越小越好
- 可以同时使用 FID 和 动画人物人脸侦测系统 两个指标

评估问题:
- 即使评估指标很高,但可能遇到一个问题,就是生成的图像可能就直接 copy 的训练图像,或只是做了简单的翻转


若有收获,就点个赞吧
0 人点赞
