序列概率模型:
- 一个文本序列的概率大小可以用来评估它符合自然语言规则的程度
- 给定一个序列样本
 ,其概率是 T 个词的联合概率
,其概率是 T 个词的联合概率 
- 和一般的概率模型类似,序列概率模型有两个基本问题:
- 学习问题(概率密度估计):给定一组序列数据,估计这些数据背后的概率分布
- 生成问题(样本生产):从已知的序列分布中生成新的序列样本
- 序列数据一般可以通过概率图模型来建模序列中不同变量之间的依赖关系
15.1 序列概率模型
序列数据有两个特点:
- 样本是变长的
- 样本空间非常大
对于一个长度为 T 的序列,其样本空间为  ,因此很难用已知的概率模型来直接建模整个序列的概率
,因此很难用已知的概率模型来直接建模整个序列的概率
序列概率:
- 因此,序列数据的概率密度估计问题可以转换为单变量的条件概率估计问题,即给定
 时
时  的条件概率
的条件概率 
自回归生成模型:
- 给定一个包含 N 个序列数据的数据集
 ,序列数据模型需要学习一个模型
,序列数据模型需要学习一个模型  来最大化整个数据集的对数似然函数
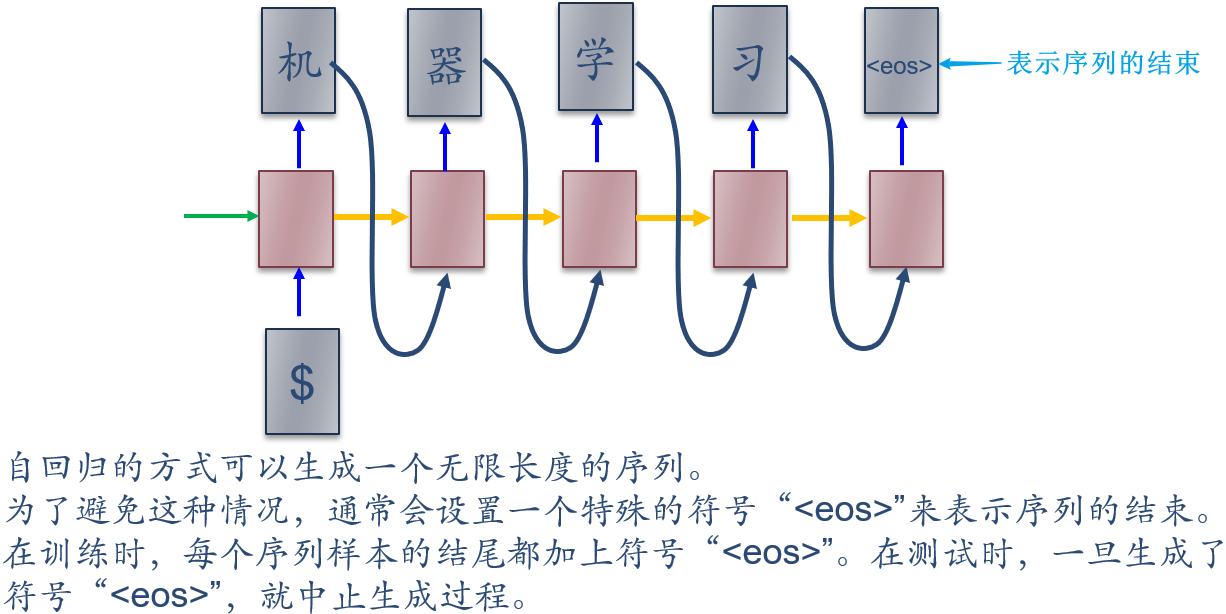
来最大化整个数据集的对数似然函数 在这种序列模型中,每一步都需要将前面的输出作为当前步的输入,是一种自回归的方式
15.1.1 序列生成
自回归生成模型:
一旦通过最大似然估计训练了模型
 ,就可以通过时间顺序来生成一个完整的序列样本
,就可以通过时间顺序来生成一个完整的序列样本- 区分:非自回归生成模型则同时生成所有词

生成最可能序列:
- 当使用自回归模型生成一个最可能的序列时,生成过程是一种从左到右的贪婪式搜索过程,在每一步都生成最可能的词,即

- 这种贪婪式的搜索方式是次优的,生成的序列
 并不保证是全局最优的,即
并不保证是全局最优的,即 
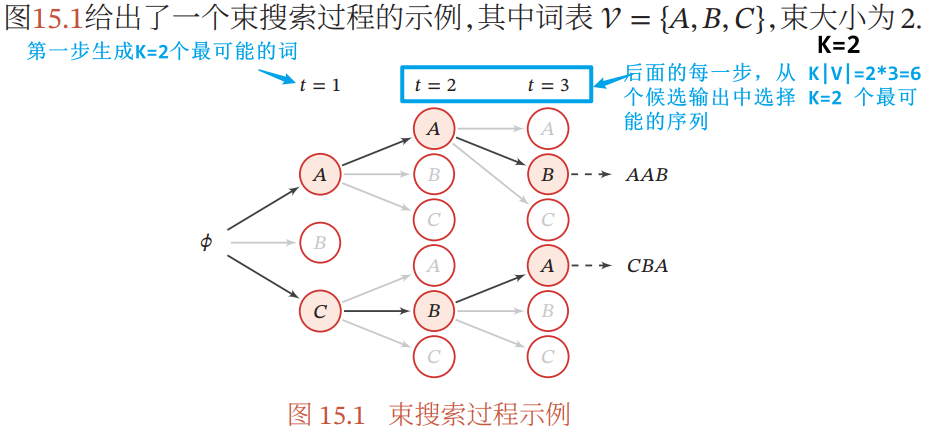
束搜索:一种常用的减少搜索错误的启发方法
- 在每一步中,生成 K 个最可能的前缀序列(K 为束大小)
- 束搜索通过调整束大小 K 来平衡计算复杂度和搜索质量之间的优先级
- 数的大小 K 越大,束搜索的复杂度越高,但越有可能生成最有序列
15.2 N 元统计模型(N-Gram)
N 元模型(N-Gram Model):假设每个词  只依赖于其前面的 N-1 个词(N 阶马尔可夫性质),即
只依赖于其前面的 N-1 个词(N 阶马尔可夫性质),即

- N 元模型的条件概率可以通过最大似然函数得到,即
- N 元模型的主要问题:数据稀疏问题
- 由于训练样本不足而导致密度估计不准确。在 N 元模型中,当一个 N 元组合在训练数据集中不存在时,包含这个组合的句子的概率为 0
- 解决方法:
- 增加训练数据集的规模:但自然语言中大部分词都是低频词,很难通过增加数据集来避免数据稀疏问题
- 平滑技术 Smoothing:即给一些没有出现的词组合赋予一定先验概率。基本思想:增加低频词的频率,降低高频词的频率
- 加法平滑:

- 当 δ=1 时,称为 加 1 平滑
- Good-Turing 平滑
- Kneser-Ney 平滑
- 加法平滑:

15.3 深度序列模型
深度序列模型:利用神经网络模型来估计条件概率 
- 神经网络

- 输入:历史信息

- 输出:词表
 中的每个词
中的每个词  出现的概率
出现的概率
- 输入:历史信息

15.3.1 模型结构
15.3.1.1 嵌入层
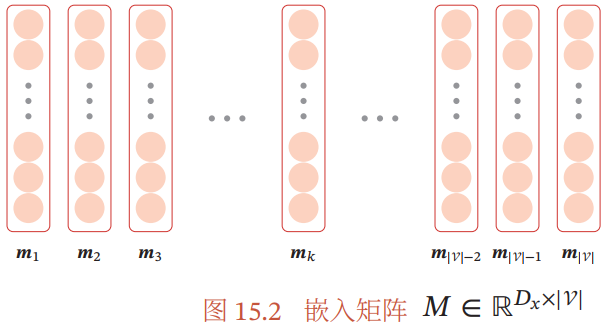
嵌入层:将输入的历史信息  (一般为符号序列)转换为神经网络模型能处理的向量形式
(一般为符号序列)转换为神经网络模型能处理的向量形式 
词  (词表中索引为 k)对应的 one-hot 向量表示为
(词表中索引为 k)对应的 one-hot 向量表示为 
- 嵌入矩阵
 ,其中第 k 列向量为
,其中第 k 列向量为 
 是第 k 维为 1,其余为 0 的
是第 k 维为 1,其余为 0 的  维向量
维向量
15.3.1.2 特征层
特征层:用于从输入序列  中提取特征,输出为一个可以表示历史信息的向量
中提取特征,输出为一个可以表示历史信息的向量 
特征层可以用不同类型的神经网络来实现:
- 简单平均:

- 即历史信息的向量
 为前面 t-1 个词的加权平均
为前面 t-1 个词的加权平均 - 权重可以与位置 i 及其表示
 有关,或直接设为
有关,或直接设为  ,也可以通过注意力机制动态计算
,也可以通过注意力机制动态计算
- 即历史信息的向量
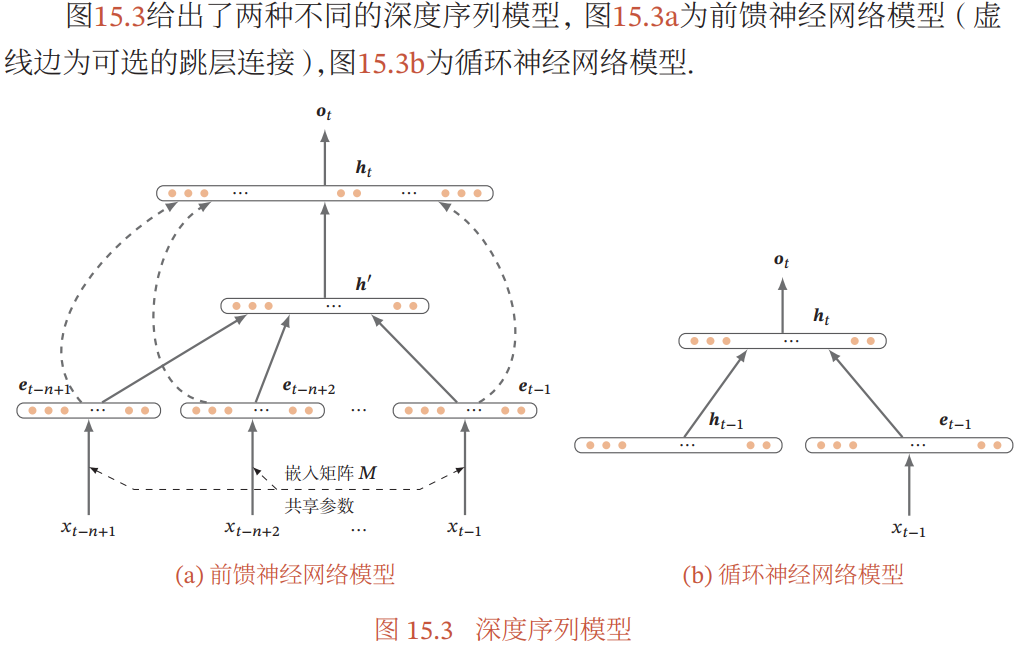
- 前馈神经网络:
- 前馈神经网络要求输入大小固定,因此假设历史信息只包含前面 N-1 个词(类似 N-Gram):

- 输出

- 前馈神经网络要求输入大小固定,因此假设历史信息只包含前面 N-1 个词(类似 N-Gram):
- 循环神经网络:
- 循环神经网络可以接受变长的输入序列,依次接受输入
 ,得到时刻 t 的隐藏状态
,得到时刻 t 的隐藏状态 
- 循环神经网络可以接受变长的输入序列,依次接受输入
15.3.1.3 输出层
输出层:接受历史信息的向量表示  ,输出为词表中每个词的后验概率,输出大小为
,输出为词表中每个词的后验概率,输出大小为 
- 一般使用 softmax 分类器:

15.3.2 参数学习
给定一个训练序列 
深度序列模型的训练目标:找到一组参数  使得对数似然函数最大
使得对数似然函数最大

网络参数一般通过梯度上升法学习:
15.4 评价方法
15.4.1 困惑度
给定一个测试文本集合(有 N 个独立同分布的序列),一个好的序列生成模型  应该使得测试集合中句子的联合概率尽可能高
应该使得测试集合中句子的联合概率尽可能高
- 整个测试集的联合概率

困惑度:可以衡量模型分布和经验分布之间的契合程度。困惑度越低,则两个分布越接近
- 模型
 的困惑度
的困惑度 
 为测试数据集中序列的总长度
为测试数据集中序列的总长度
- 困惑度为每个词条件概率
 的几何平均数的倒数
的几何平均数的倒数 -
15.4.2 BLEU 算法
BLEU 算法:是衡量模型生成序列和参考序列之间的 N 元词组重合度的算法
BLEU 算法计算的是 N 元组合的精度
 ,即生成序列中的 N 元组合有多少比例在参考序列中出现,而不关心召回率
,即生成序列中的 N 元组合有多少比例在参考序列中出现,而不关心召回率- 精度

 是 N 元组合 w 在生成序列 x 中出现的次数
是 N 元组合 w 在生成序列 x 中出现的次数 是 N 元组合 w 在参考序列
是 N 元组合 w 在参考序列  中出现的次数
中出现的次数
- BLEU 算法计算不同长度的 N 元组合的精度,并进行几何加权平均得到:

- N’ 是最长 N 元组合的长度
 是不同 N 元组合的权重
是不同 N 元组合的权重- 长度惩罚因子
 ,
, 为生成序列 x 的长度,
为生成序列 x 的长度, 为参考序列的最短长度
为参考序列的最短长度- 因为精度只衡量生成序列中的 N 元组合是否在参考序列中出现,生成序列越短,其精度会越高,因此引入长度惩罚因子,若生成序列的长度短于参考序列,则进行惩罚
- BLEU 算法的值([0,1])越大,表明生成的质量越好
15.4.3 ROUGE 算法
ROUGE 算法:计算的是召回率,即参考序列中的 N 元组合有多少比例在生成序列中出现

15.5 序列生成模型中的学习问题
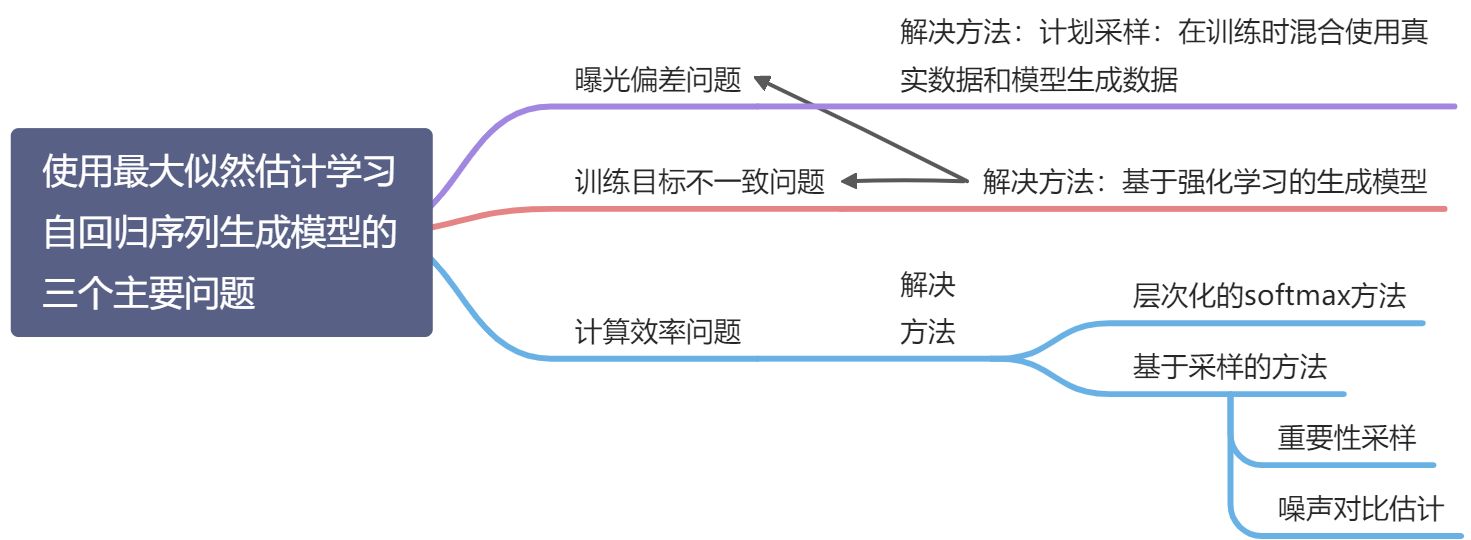
15.5.1 曝光偏差问题
- 教师强制:
- 在自回归生成模型中,第 t 步的输入为模型生成的前缀序列
 ,来自于模型分布
,来自于模型分布 
- 在训练时,使用的前缀序列是训练集中的真实数据
 ,来自于真实的数据分布
,来自于真实的数据分布 
- 在自回归生成模型中,第 t 步的输入为模型生成的前缀序列
- 协变量偏移问题:
- 教师强制的学习方式,模型分布和真实分布并不严格一致,因此存在协变量便宜问题
- 曝光偏差问题:
- 一旦在预测前缀
 的过程中存在错误,会导致错误传播,后续生成的序列也会偏离真实分布
的过程中存在错误,会导致错误传播,后续生成的序列也会偏离真实分布 - 解决办法:计划采样
- 在训练时混合使用真实数据和模型生成的数据
 :使用真实数据的概率(
:使用真实数据的概率( 为使用生成数据的概率)
为使用生成数据的概率)- 计划采样:在训练初期赋予
 较大的值,随着训练次数的增加逐步减小
较大的值,随着训练次数的增加逐步减小  的值
的值- 线性衰减:

- 指数衰减:

- 逆 Sigmoid 衰减:

- 线性衰减:
- 计划采样的缺点:过度纠正。即在每一步中不管输入如何选择,目标输出依然来自于真实数据,这可能使得模型预测一些不正确的序列。eg. 真实序列为“吃饭”,若在第一步生成时使用模型预测的词是“喝”,模型就会强制记住“喝饭”这个不正确的序列
- 一旦在预测前缀
15.5.2 训练目标不一致问题
训练目标不一致问题:训练目标和评价方法不一致
- 序列生成模型的好坏通常采用和任务相关的指标(eg. BLEU、ROUGE)来进行评估
- 训练时通常使用最然似然估计来优化模型
解决方法:基于强化学习的序列生成
- 将自回归序列生成看作一种马尔可夫决策过程,并使用强化学习的方法来进行训练
- 基于强化学习的序列生成模型不但可以解决训练和评价目标不一致问题,也可以有效地解决曝光偏差问题
15.5.3 计算效率问题
计算效率问题:序列生成模型的输出层为词表中所有词的条件概率,需要 softmax 归一化,当词表比较大时,计算效率比较低:
 (
( 为前缀序列)
为前缀序列)- 配分函数
 :需要对词表中所有词 v 计算
:需要对词表中所有词 v 计算  并求和,当词表比较大时,计算开销非常大
并求和,当词表比较大时,计算开销非常大
加快训练速度的方法:
- 基于层次化的 softmax 方法:改变了模型结构,在训练和测试时都可以加快计算速度
基于采样的方法:不改变模型的结构,只是近似计算参数梯度,在训练时可以显著提高模型的训练速度,但在测试阶段依然需要计算配分函数
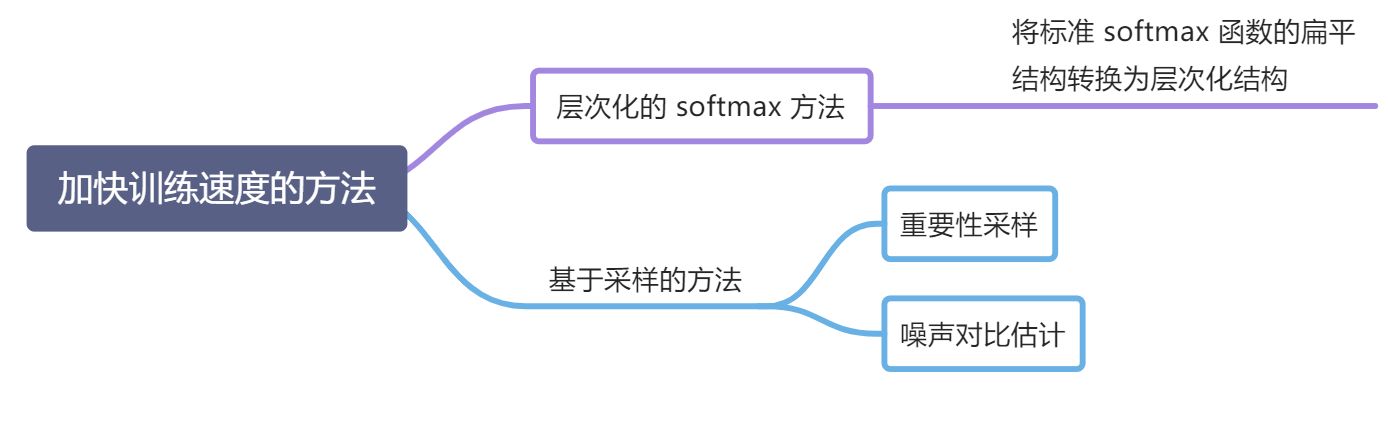
15.5.3.1 层次化 Softmax
两层树结构组织词表:将词表中的词分为 K 组,并且每个词只能属于一个组,则每组大小为

词 w (设属于
 组)的概率:
组)的概率:
- 即将一个词的概率分解为两个概率的乘积,计算 softmax 时分别只需要计算
 和 K 次求和,从而大大提高 softmax 函数的计算速度
和 K 次求和,从而大大提高 softmax 函数的计算速度
- 即将一个词的概率分解为两个概率的乘积,计算 softmax 时分别只需要计算
- 一般对于词表大小
 ,将词平均分到
,将词平均分到  个分组中,每组
个分组中,每组  个词,将 softmax 计算加速到
个词,将 softmax 计算加速到  倍
倍
更深层的树结构组织词表:进一步降低 softmax 函数的计算复杂度
- 若使用平衡二叉树进行分组,则条件概率估计可以转换为
 个二分类问题,这时原始预测模型中的 softmax 函数可以使用 Logistic 函数代替,计算效率可以加速
个二分类问题,这时原始预测模型中的 softmax 函数可以使用 Logistic 函数代替,计算效率可以加速  倍
倍
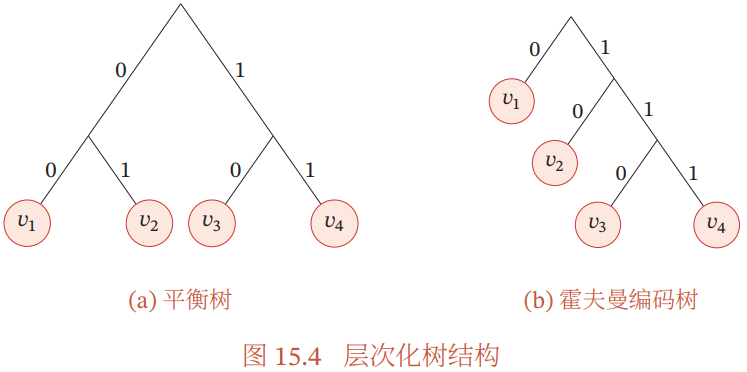
将词按树结构组织的几种方式:
- 利用人工整理的词汇层结构,eg. is-a 关系:动物 - 狗
- 使用霍夫曼编码

15.5.3.2 重要性采样
基于采样的方法:即通过采样来近似计算训练时的梯度,以提高计算效率
15.5.3.4 噪声对比估计 NCE
噪声对比估计 NCE:也是一种近似估计梯度的方法。将密度估计问题转换为二分类问题,从而降低计算复杂度
- 需建模的真实分布
 ,模型分布
,模型分布  ,噪声分布
,噪声分布 
- 判别函数 D:噪声对比估计是通过调整模型
 使得判别函数很容易分辨出样本 x 来自真实分布还是噪声分布,可以看作一个二分类问题
使得判别函数很容易分辨出样本 x 来自真实分布还是噪声分布,可以看作一个二分类问题 - 噪声对比估计的损失函数

噪声对比估计 VS 生成对抗网络:
- 思想类似:噪声对比估计相当于用判别式的准则
 来训练一个生成式模型
来训练一个生成式模型  ,使得判别函数 D 很容易分辨出样本来自哪个分布
,使得判别函数 D 很容易分辨出样本来自哪个分布 - 不同点:噪声对比估计中的判别函数 D 是通过贝叶斯公式计算得到,而生成对抗网络的判别函数 D 是一个需要学习的神经网络
噪声分布  的选取也十分关键,取一元模型的分布是一个好选择
的选取也十分关键,取一元模型的分布是一个好选择
15.6 序列到序列模型 Seq2Seq Model
序列到序列 Sequence to Sequence:是一种有条件的序列生成问题(Conditional Sequence Generation),给定一个序列  ,生成另一个序列
,生成另一个序列  ,输入和输出序列的长度可以不同
,输入和输出序列的长度可以不同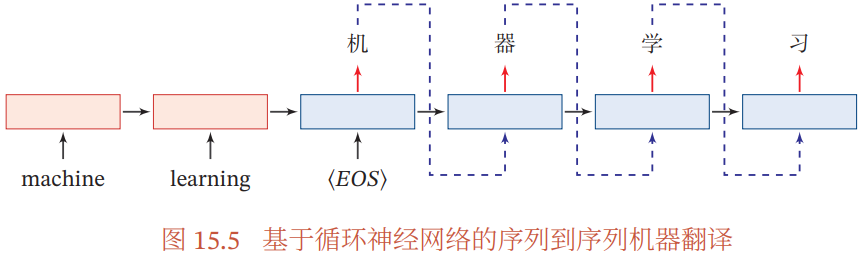
序列到序列模型的目标:估计条件概率 
- 给定训练数据,使用最大似然估计训练模型参数
- 训练完成,模型就可以根据一个输入序列 x 来生成最可能的目标序列

- 具体的生成过程可以通过 贪婪方法 or 束搜索 完成
15.6.1 基于循环神经网络的序列到序列模型
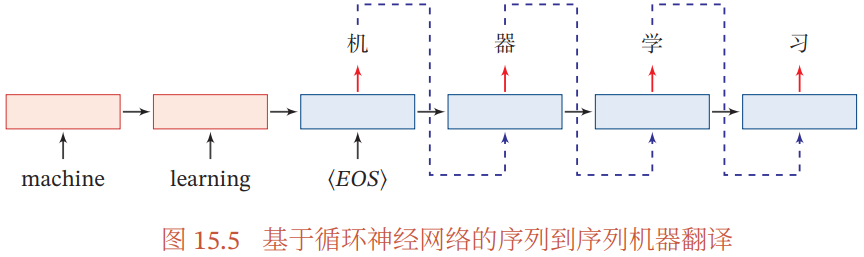
编码器-解码器模型(Encoder-Decoder 架构):使用两个循环神经网络(RNN)分别进行编码和解码
- Encoder 依次读入整个输入序列,每个 time step 读入一个 token,全部读入后,产生最后一个 time step 的隐向量,作为代表整个输入序列的语义向量
- Decoder 根据 Encoder 提供的语义向量和自身上一个 time step 的输出,得到当前 time step 的输出 token,最终得到整个输出序列
 > Seq2Seq Model without attention
> Seq2Seq Model without attention 图片来源:Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention)
基于循环神经网络的序列到序列模型的缺点:
- 编码向量 u 的容量问题,输入序列的信息很难全部保存在一个固定维度的向量中
- 当序列很长时,由于循环神经网络的长程依赖问题,容易丢失输入序列的信息
15.6.2 基于注意力的序列到序列模型
上一小节介绍了基于 RNN 的 Seq2Seq model,Encoder 处理完整个输入序列后将最后一个 time step 产生的向量作为代表整个输入序列的语义向量,交给 Decoder。但只用一个固定维度的语义向量,很难将一个很长的序列的所有语义资讯都囊括。因此,不如将 Encoder 处理输入序列的每个 token 后(每个 time step)产生的所有输出向量都交给 Decoder,让 Decoder 自己决定在生成新的序列的各个 token 时分别将“注意”放在 Encoder 的哪些输出向量上。
这就是注意力机制的中心思想:提供更多资讯给 Decoder,并通过类似资料库存取的概念,令其自行学会如何提取资讯
> Seq2Seq Model with attention
图片来源:Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention)
基于注意力的序列到序列模型:为了获取更丰富的输入序列信息,可以在每一步中通过注意力机制来从输入序列中选取有用的信息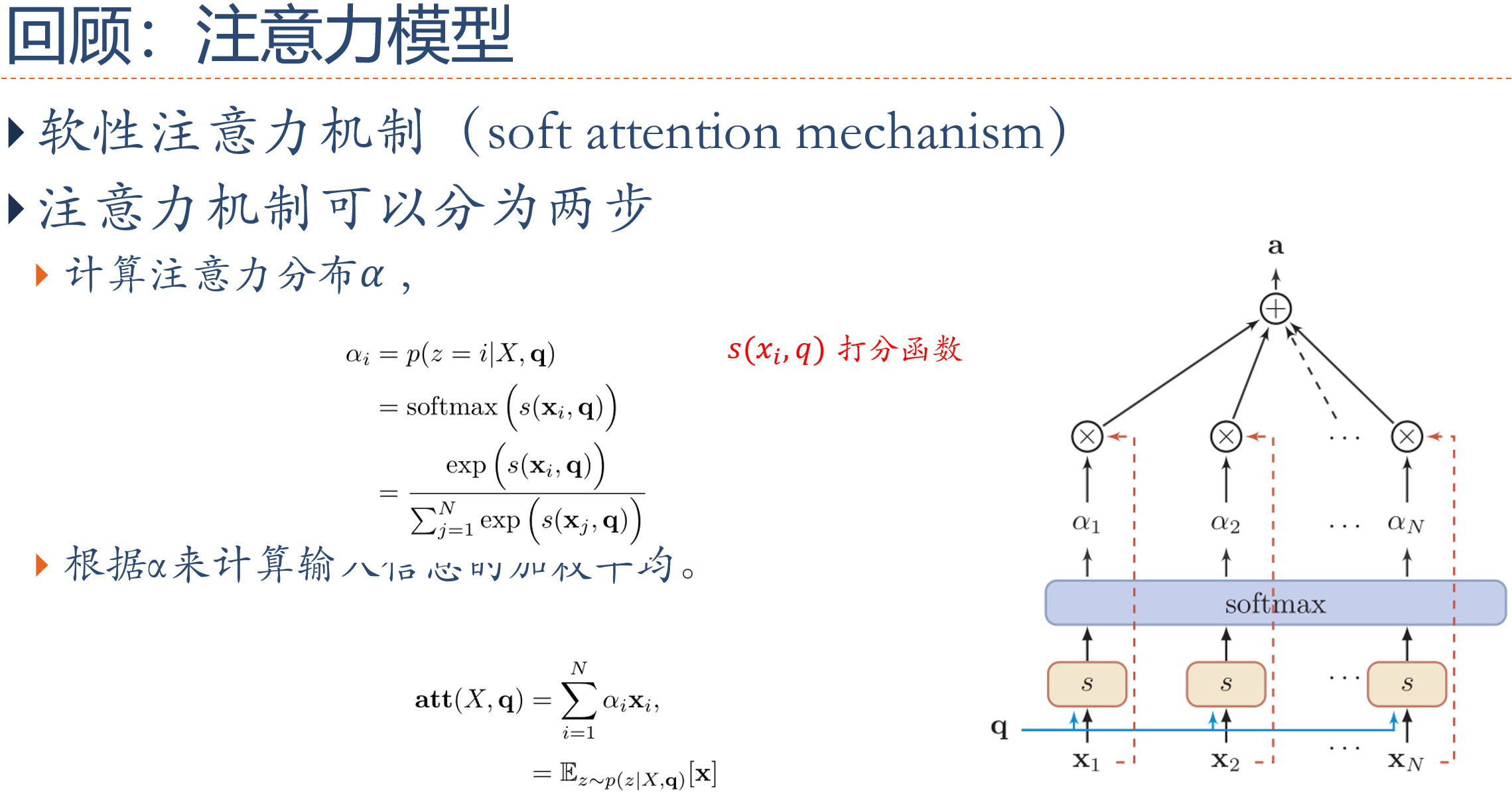
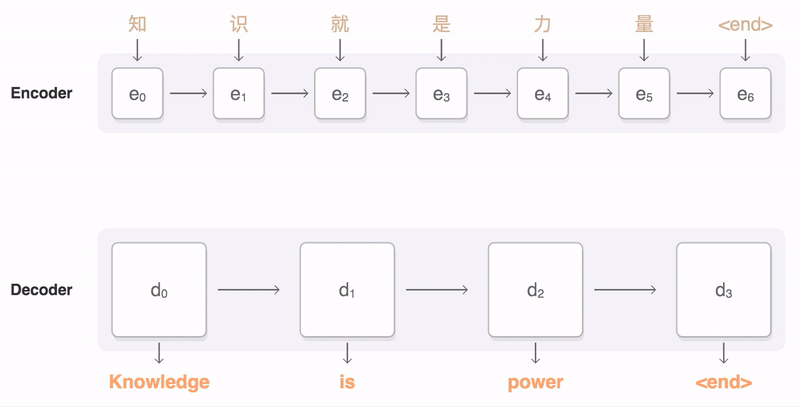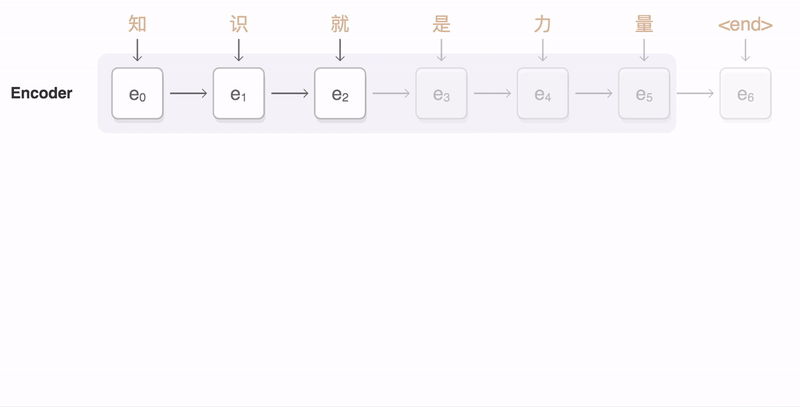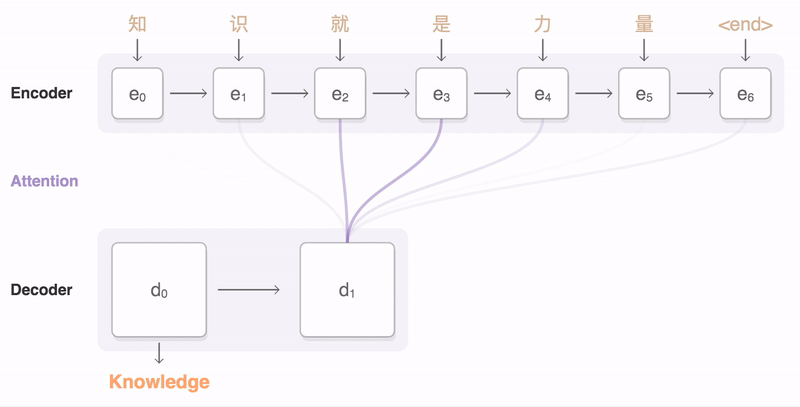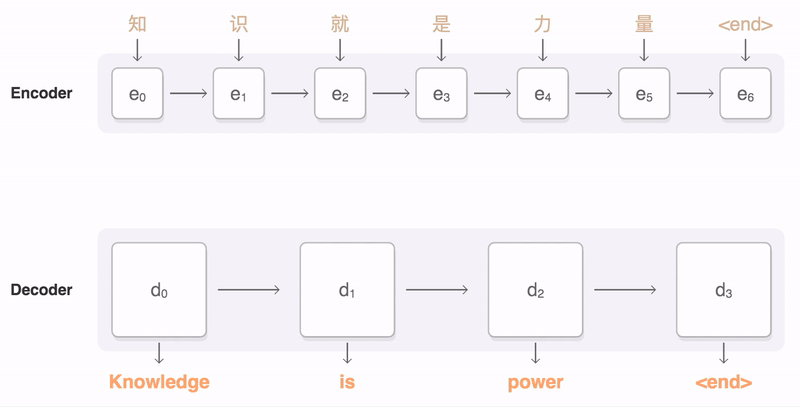
基于注意力的 Seq2Seq 模型又称为动态的条件序列生成(Dynamic Conditional Generation)。Encoder 将处理输入序列的每个 token 后产生的隐向量都交给 Decoder。通过注意力机制,Decoder 在生成新序列的每个 token 时都能动态地考虑要将注意力放在哪些 Encoder 输出的向量(以及从中获取多少资讯)
> 带 attention 的 Seq2Seq model 实例,法翻英。Decoder 在生成每个英文词汇时,对 Encoder 的每个输出向量有不同的关注程度
图片来源:Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention)
15.6.3 基于自注意力的序列到序列模型
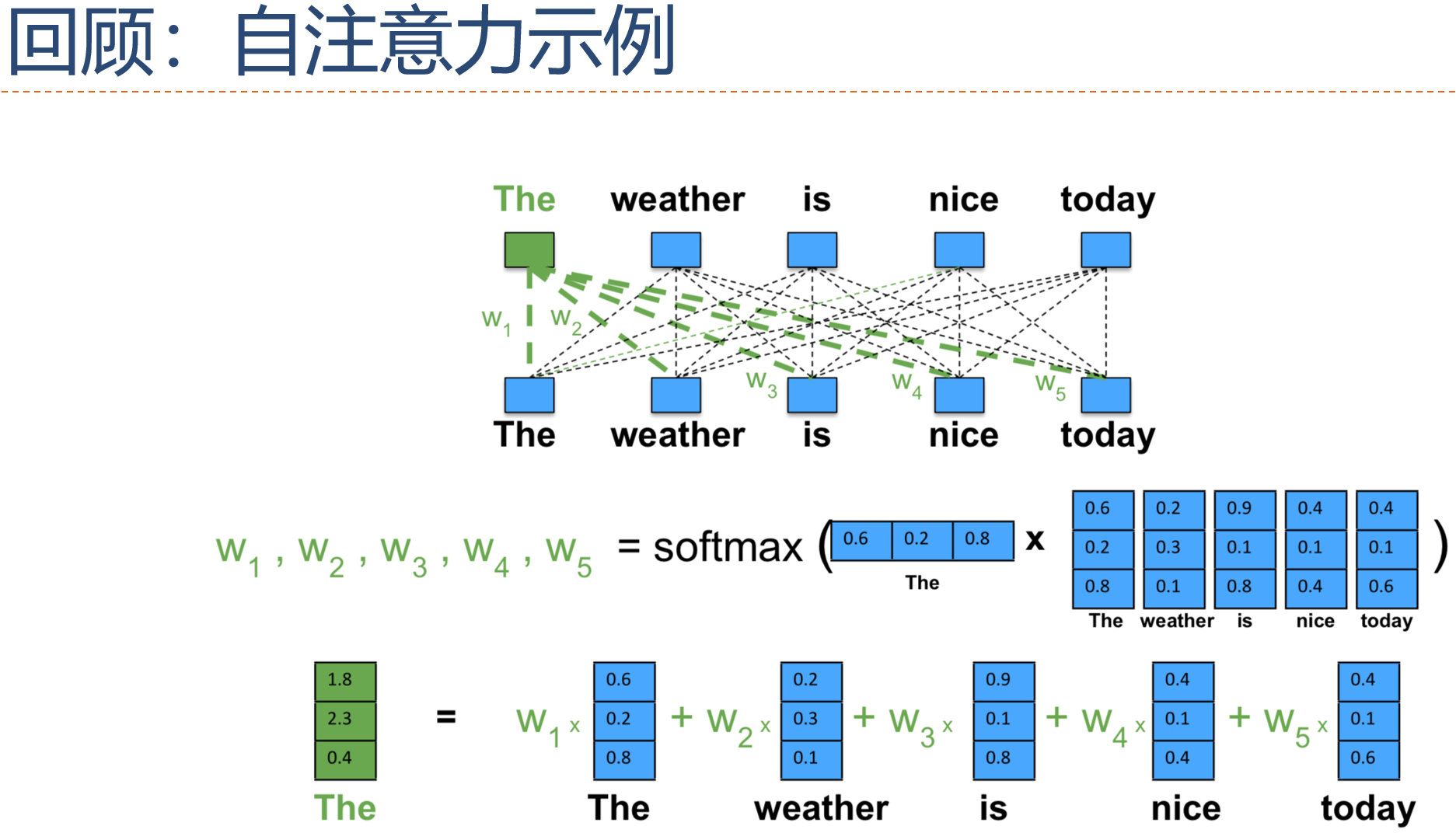
15.6.3.1 自注意力
详见笔记 Self-Attention(深度学习与人类语言处理 李宏毅 2020 - Transformer) 论文:Attention Is All You Need 2017.6 参考:淺談神經機器翻譯 & 用 Transformer 與 TensorFlow 2 英翻中
上一小节介绍了基于 Seq2Seq Model + 注意力机制,其中 Seq2Seq model 的 Encoder 和 Decoder 使用的都是 RNN,有一个缺点:不能并行化。因为例如输入序列有 m 个 tokens,那么 RNN 就要经过 m 个 time step 依次读入并处理 tokens,依次得到每个 tokens 对应的隐向量,最后一个隐向量包含整个输入序列的语义资讯。
改进:自注意力机制 - 用自注意力机制取代 RNN
- 优点:利用矩阵运算,自注意力层可以在相当于 RNN 的一个 time step 内就得到输入序列所有 tokens 的输出向量,并且每个向量都包含整个输入序列的资讯
- 自注意力机制的思想:在建立一个序列中每个 token 的 representation 时,同时去“注意”并获取同一个序列中其它 tokens 的语义资讯,将这些语义资讯合并为上下文资讯作为自己的 representation
- 典型模型:Transformer
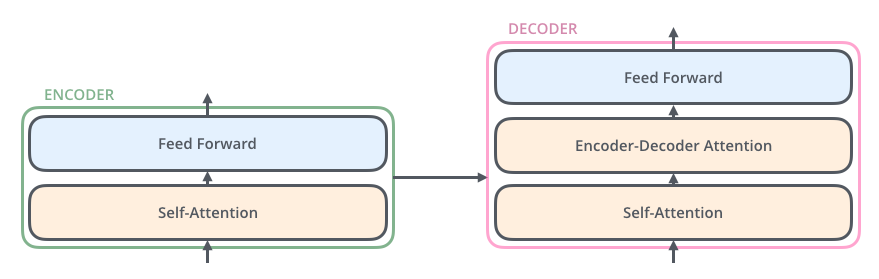
基于自注意力的 Seq2Seq model:Transformer 图片来源:The Illustrated Transformer
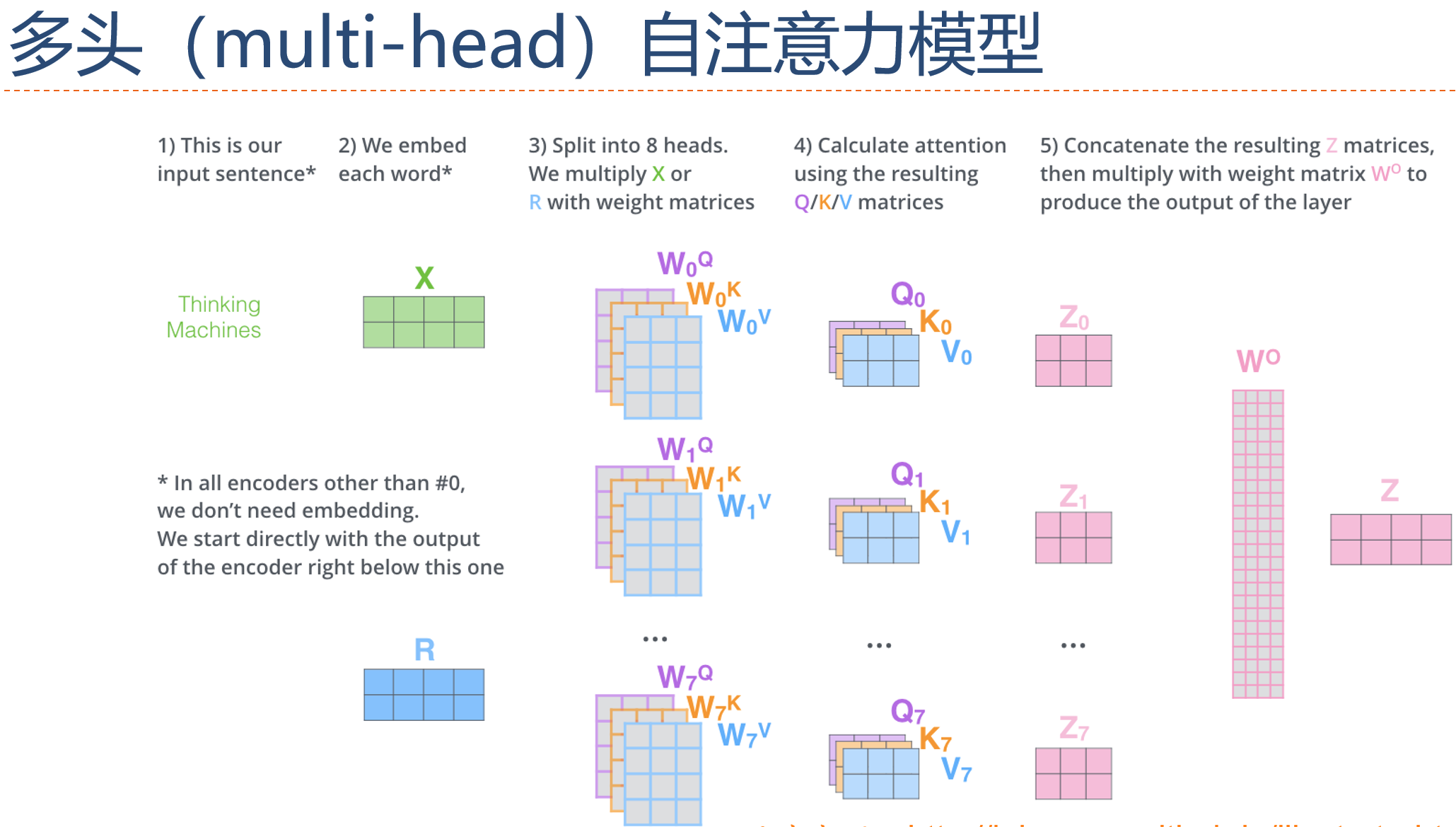
15.6.3.2 多头自注意力
15.6.3.3 基于自注意力模型的序列编码
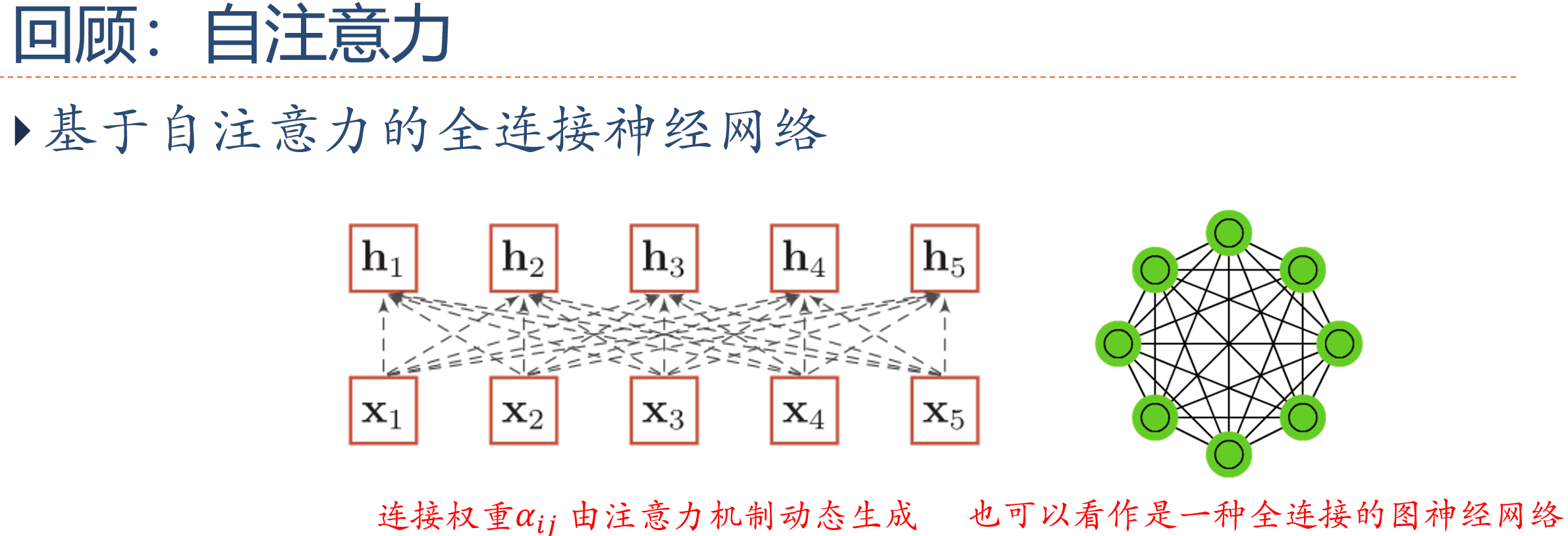
基于自注意力模型的序列编码可以看作一个全连接的前馈神经网络,其连接权重通过注意力机制动态计算得到
15.6.3.4 Transformer 模型

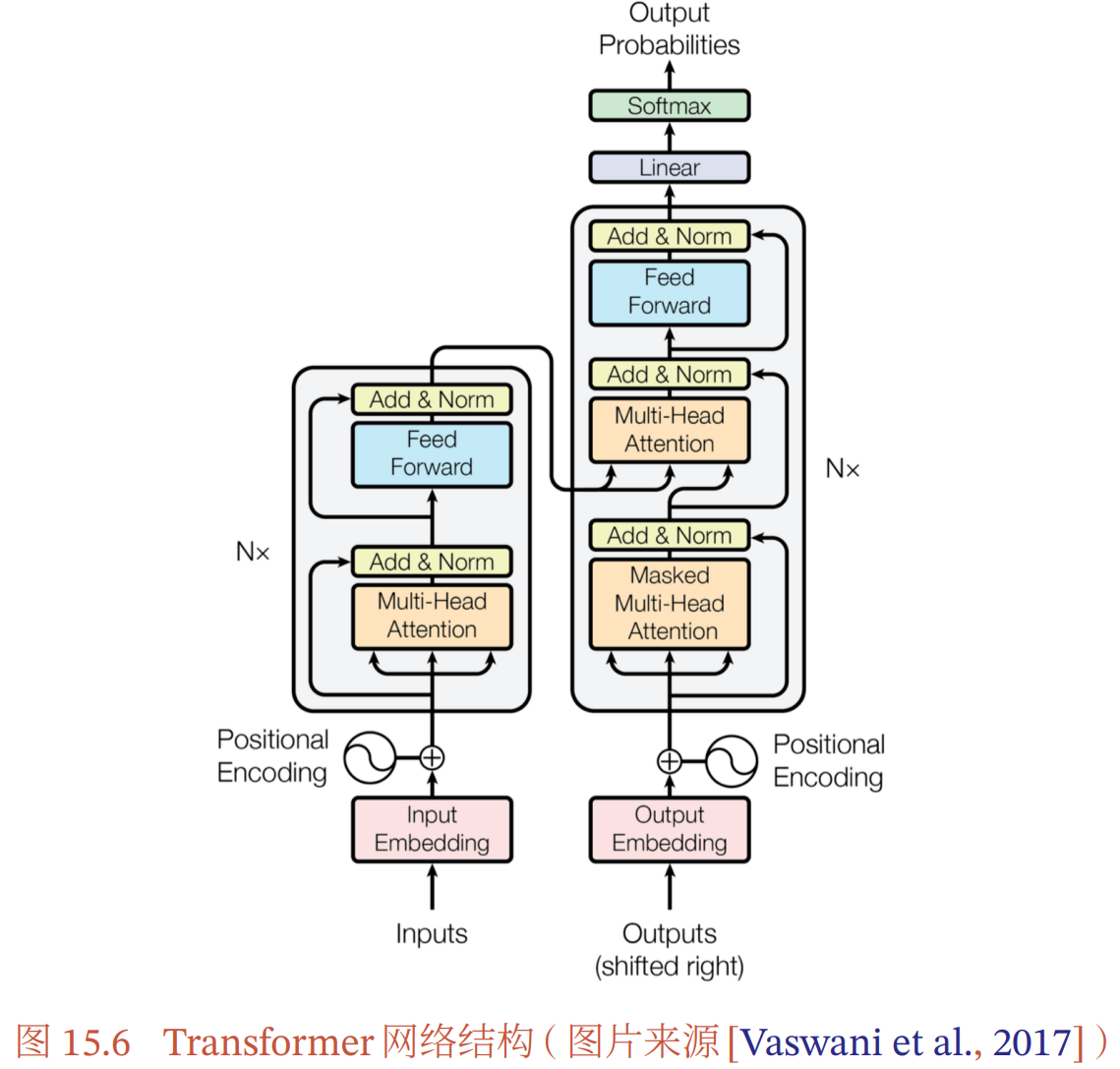
Transformer模型网络结构:
- 编码器:只包含多层的多头自注意力模块,每一层都接受前一层的输出作为输入
- 解码器:通过自回归的方式生成目标序列
- 掩蔽自注意力模块:
- 解码器到编码器注意力模块:
- 逐位置的前馈神经网络:
15.7 总结和深入阅读
- 序列生成模型主要解决序列数据的密度估计和生成问题
目前主流的序列生成模型都是自回归模型
解决曝光偏差问题:在训练时混合使用真实数据和模型生成的数据
提高计算效率:
- 层次化 softmax:使用层次化 softmax 函数来近似扁平的 softmax 函数
- 采样:
- 利用重要性采样来加速 softmax 的计算
- 噪声对比估计来计算非归一化的条件概率
序列到序列模型:
- 基于循环神经网络的序列到序列模型
- 使用注意力模型来改进循环神经网络的长程依赖问题
- Transformer:全连接的自注意力模型,是目前最成功的序列到序列模型
Texar 是一个非常好的序列生成框架,提供了很多主流的序列生成模型
习题

若有收获,就点个赞吧
0 人点赞
