除了模型和学习算法,特征 or 表示也是影响学习效果的重要因素,传统的机器学习问题在实际上都变成了特征工程问题。而深度学习是一种端到端的学习,中间不需要人为干预。深度学习要解决的问题是贡献度分配问题,而神经网络使用反向传播算法,可以有效解决这个问题。
目前,深度学习主要以神经网络模型为基础,研究如何设计模型结构,如何有效学习模型的参数,如何优化模型性能以及在不同任务上的应用等。
本书的知识体系如下图所示: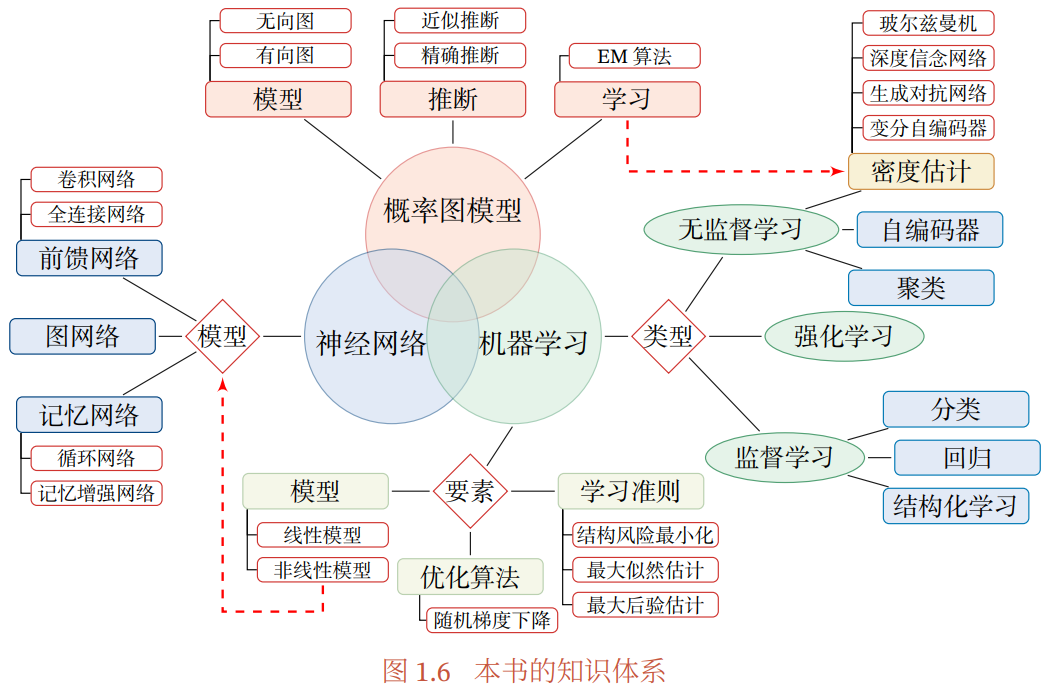
1.1 人工智能
人工智能的研究范畴:
- 机器感知:计算机视觉、语音信息处理
- 学习:模式识别、机器学习、强化学习
- 语言:自然语言处理
- 记忆:知识表示
- 决策:规划、数据挖掘
- … …
人工智能的定义:
- 人工智能就是要让机器的行为看起来像是人所表现出的智能行为一样(eg. 能通过图灵测试)
人工智能的主要领域:
- 感知:模拟人的感知能力,对外部刺激信息(视觉、语音等)进行感知和加工
- 主要研究领域包括 语音信息处理和计算机视觉等
- 学习:模拟人的学习能力,主要研究如何从样例或从环境的交互中进行学习
- 主要研究领域包括 监督学习、无监督学习、强化学习等
- 认知:模拟人的认知能力
- 主要研究领域包括 知识表示、自然语言理解、推理、规划、决策等
- 感知:模拟人的感知能力,对外部刺激信息(视觉、语音等)进行感知和加工
人工智能的发展历史:

- 人工智能的流派:
- 符号主义:优点是可解释性
- 连接主义:优点是由大量简单的信息处理单元组成互联网络,具有非线性、分布式、并行化、局部性计算以及自适应等特性
- 深度学习的主要模型神经网络就是一种连接主义模型
1.2 机器学习
机器学习的定义:
- 机器学习是指从有限的观测数据中学习(or 猜测)出具有一般性的规律,并利用这些规律对未知数据进行预测的方法
实际任务中使用机器学习模型一般包含如下步骤:(实际上很多机器学习问题都变成了特征工程问题)
- 数据预处理:去除噪声等,eg. 文本分类中去除停用词
- 特征提取:从原始数据中提取一些有效的特征,eg. 图像分类中提取边缘,尺度不变特征变换
- 特征转换:特征加工,比如 降维 or 升维,eg. 降维的两种途径:特征抽取、特征选择
- 常用的特征转换方法:主成分分析(PCA)、线性判别分析(LDA)
- 预测:学习一个函数并预测

- 特征工程问题:传统机器学习中,除了模型和学习算法,特征或表示也是影响最终学习效果的重要因素,甚至在很多任务上比算法更重要,因此实际上人们往往需要花费大量的精力去尝试设计不同的特征以及特征组合,来提高最终的系统能力
1.3 表示学习
- 表示:即特征,为了提高机器学习系统的准确率,需要将输入信息转换为有效的特征
表示学习:自动学习出有效的特征,并提高最终机器学习模型的性能,这种学习算法称为表示学习
语义鸿沟:即输入数据的底层特征与高层语义信息的不一致性和差异性
- 底层特征:eg. 图片在像素级别的表示
- 高层语义:抽象的概念,eg. 图片里是“车”
- 一个好的表示在某种程度上能够反映出数据的高层语义信息,从而能更容易地构建后续的机器学习模型
- 表示学习的关键是解决语义鸿沟问题
表示学习的两个核心问题:
- 什么是一个好的表示
- 如何学习到好的表示
好的表示应该具有的优点:
- 具有很强的表示能力,即同样大小的向量可以表示更多信息
- 使后续的学习任务变得简单,即需要包含更高层的语义信息
- 具有一般性,是任务或领域独立的,可以比较容易地迁移到其他任务上
机器学习中常用地表示特征的两种方式:
- 局部表示:也称离散表示/符号表示,可以表示为 one-hot 向量的形式
- eg. 用一个
 维的 one-hot 向量表示每一种颜色,第 i 种颜色的第 i 维为 1,其它维都为 0
维的 one-hot 向量表示每一种颜色,第 i 种颜色的第 i 维为 1,其它维都为 0 - 优点:
- 这种离散的表示具有很好的解释性,有利于人工归纳和总结特征,并通过特征组合进行高效的特征工程
- 通过多种特征组合得到的表示向量通常是稀疏的二值向量,当用于线性模型时计算效率非常高
- 缺点:
- one-hot 向量的维数很高,且不能扩展,增加一种颜色就要增加一维
- 不同颜色之间的相似度都为 0,无法知道“红色”和“中国红”的相似度高于“红色”和“黑色”
- eg. 用一个
- 分布式表示:通常可以表示为低维的稠密向量
- eg. 用 RGB 值表示颜色,不同颜色对应到 R、G、B 三维空间中的一个点,即一种颜色的语义分散到语义空间中的不同基向量上,而不是每个样本都在坐标轴上
- 优点:
- 表示能力强很多,分布式表示的向量维度一般都比较低(三维稠密向量可以表示所有颜色),也能方便地扩展新颜色
- 不同颜色之间的相似度也容易计算
- 局部表示:也称离散表示/符号表示,可以表示为 one-hot 向量的形式
嵌入:将一个度量空间中的一些对象映射到另一个低维的度量空间中,并尽可能保持不同对象之间的拓扑关系
- 一种降维,将高维的局部表示空间映射到一个非常低维的分布式表示空间,每个特征不再是坐标轴上的点,而是分散在整个低维空间中
- eg. 自然语言处理中词的分布式表示,也常称为“词嵌入”
好的高层语义表示一般为分布式表示,通常需要从底层特征开始,经过多步非线性转换才能得到
- 深层结构的优点是可以增加特征的重用性,从而指数级地增加表示能力
- 因此, 表示学习的关键是构建具有一定深度多层特征表示
1.4 深度学习
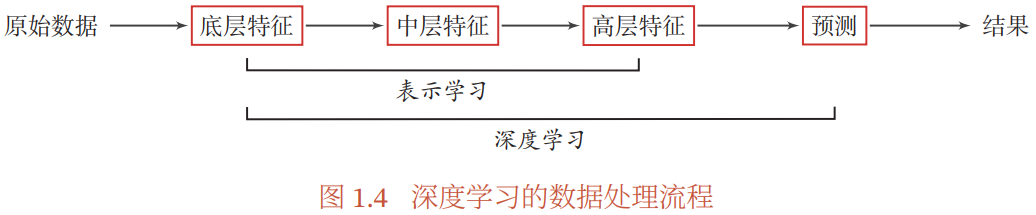
上节提到,为了学习出一种好的特征表示(从底层→中层→高层特征),需要构建具有一定深度的模型
深度:原始数据进行非线性特征转换的次数;有向图从输入节点到输出节点所经过的最长路径的长度
深度学习:主要目的是从数据中自动学习到有效的特征表示(高层次、抽象的表示)
- 这些学习到的表示可以替代人工设计的特征,从而避免 1.2 节提到的“特征工程”
深度学习的数据处理流程:
贡献度分配问题:
- 深度学习的样本输入到输出之间经过多个线性 or 非线性的组件,每个组件都会对信息进行加工,并进而影响后续组件,当最后得到输出结果时,我们并不清楚其中每个组件的贡献是多少,这就是贡献度分配问题
- 这是深度学习要解决的一个关键问题,关系到如何学习每个组件的参数
- 深度学习采用的模型主要是神经网络模型,因为神经网络模型可以使用误差反向传播算法,从而可以比较好地解决贡献度分配问题
端到端学习/端到端训练:在学习过程中不进行分模块或分阶段训练,直接优化任务的总体目标
- 端到端的学习的训练数据为“输入-输出”对的形式,无须提供其它额外信息
- 端到端学习也是要解决贡献度分配问题
- 传统机器学习不是端到端训练,而是认为在输入输出之间划分多个模块,每个模块分开学习,单独优化,优化目标和总体目标无法保持一致,学习到的特征不一定能提升最终模型的性能,且前一步的错误会对后续模型产生很大影响
- 大部分采用神经网络模型的深度学习可以视为端到端学习,将表示学习和预测模型的学习进行端到端的学习,中间不需要人工干预(最后的输出层作为预测学习,其它层作为表示学习)
1.5 神经网络
人工神经网络:神经网络可以看作信息从输入到输出的信息处理系统,由人工神经元和神经元之间的有向连接构成
- 连接:神经元(节点)之间的连接被赋予不同的权重,每个权重代表一个节点对另一个节点的影响大小
- 神经元/节点:每个节点代表一种特定函数
- 人工神经网络可以用作一个通用的函数逼近器(一个两层的神经网络可以逼近任意的函数)
- 理论上,只要有足够的训练数据和神经元数量,人工神经网络可以学到很多复杂的函数
- 网络容量:一个人工神经网络塑造复杂函数的能力
人工神经网络考虑三方面:
- 神经元的激活规则
- 主要指神经元输入到输出之间的映射关系,一般为非线性函数
- 网络的拓扑结构
- 不同神经元之间的连接关系
- 学习算法
- 通过训练数据来学习神经网络的参数
- 神经元的激活规则
神经网络结构的三种类型:
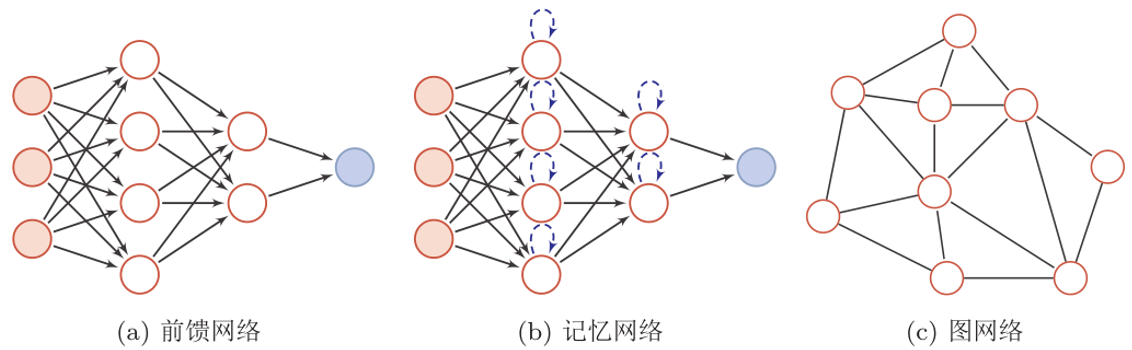
反向传播算法是迄今最为成功的神经网络学习算法
梯度消失问题的一种解决办法:采用两部来训练一个多层循环神经网络:
- 通过无监督学习的方式来逐层训练每一层循环神经网络,即预测下一个输入
- 通过反向传播算法进行精调
1.6 总结和深入阅读
- 深度学习入门课程
- 计算机视觉:斯坦福大学 CS231n ,b 站
- 自然语言处理:斯坦福大学 CS224n , b 站
编程练习

若有收获,就点个赞吧
0 人点赞
