分库分表,
1.查询时使用分区键。
2.查询时候需要大量连表查询。
3.一种垂直拆分(主库,用户库和内容库),一种水平拆分(按照某种字段的哈希值做拆分和按照常用的一个字段的区间来拆分如:时间字段)。
4.如果在性能上没有瓶颈点那么就尽量不做分库分表。
5.如果要做,就尽量一次到位,比如说 16 库,每个库 64 表就基本能够满足几年内你的业务的需求。
6.很多的 NoSQL 数据库,例如 Hbase,MongoDB 都提供 auto sharding 的特性,如果你的团队内部对于这些组件比较熟悉,有较强的运维能力,那么也可以考虑使用这些 NoSQL 数据库替代传统的关系型数据库。
7.或者使用分布式数据库例如:TiDB。
分库分表ID的全局性,
1.使用业务字段作为主键,比如说对于用户表来说,可以使用手机号,email 或者身份证号作为主键。
2.使用生成的唯一 ID 作为主键。
3.基于snowflake算法搭建发号器。
数据库和NoSql如何做到互补,
1.Redis、LevelDB 这样的 KV 存储。这类存储相比于传统的数据库的优势是极高的读写性能,一般对性能有比较高的要求的场景会使用。
2.Hbase、Cassandra 这样的列式存储数据库。这种数据库的特点是数据不像传统数据库以行为单位来存储,而是以列来存储,适用于一些离线数据统计的场景。
3.像 MongoDB、CouchDB 这样的文档型数据库。这种数据库的特点是 Schema Free(模式自由),数据表中的字段可以任意扩展,比如说电商系统中的商品有非常多的字段,并且不同品类的商品的字段也都不尽相同,使用关系型数据库就需要不断增加字段支持,而用文档型数据库就简单很多了。
4.ClickHouse可以作为日志存储数据库。
5.很多NoSql数据库都是使用基于LSM树的存储引擎。
6.TokuDB使用的名为Fractal tree的索引结构,它们的核心思想就是将随机IO变成顺序的IO,从而提升性能。
7.MongoDB的Replica,也叫做副本集,你可以理解为主从分离,也就是通过将数据拷贝成多份来保证当主挂掉后数据不会丢失。
8.MongoDB的Shard,也叫做分片,你可以理解为分库分表,即将数据按照某种规则拆分成多份,存储在不同的机器上。
9.MongoDB支持负载均衡,就是当 MongoDB 发现 Shard 之间数据分布不均匀,会启动 Balancer 进程对数据做重新的分配,最终让不同 Shard Server 的数据可以尽量的均衡。
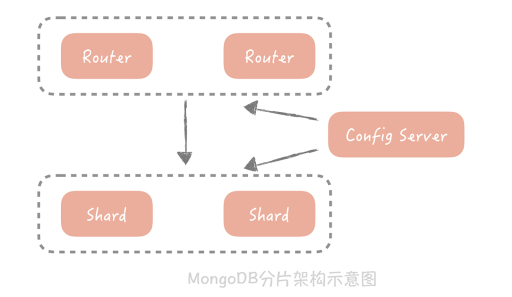
Shard Server,它是实际存储数据的节点, 独立的 Mongod 进程
Config Server,也是一组 Mongod 进程,主要存储一些元信息
Route Server,它不实际存储数据,仅仅作为路由使用,它从 Config Server 中获取元信息后,将请求路由到正确的 Shard Server 中
缓存,
1.Linux 内存管理, MMU(Memory Management Unit)。
2.播放器中通常会设计一些缓存的组件,在未打开视频时缓存一部分视频数据。
3.HTTP 协议也是有缓存机制的。
4.静态缓存(Nginx)、分布式缓存(Memcached/Redis)和热点本地缓存(HashMap/Guava Cache/Ehcache)。
5.缓存可以提高低速设备的访问速度,或者减少复杂耗时的计算带来的性能问题。
6.缓冲区则是一块临时存储数据的区域,这些数据后面会被传输到其他设备上。
7.缓存比较适合于读多写少的业务场景,并且数据最好带有一定的热点属性,缓存会给整体系统带来复杂度,并且会有数据不一致的风险,之前提到缓存通常使用内存作为存储介质,但是内存并不是无限的。
缓存读写策略,
1.Cache Aside(旁路缓存)策略,读策略(从缓存中读取数据;如果缓存命中,则直接返回数据;如果缓存不命中,则从数据库中查询数据;查询到数据后,将数据写入到缓存中,并且返回给用户。)写策略(更新数据库中的记录;删除缓存记录。)
2.Write Through 的策略是这样的:先查询要写入的数据在缓存中是否已经存在,如果已经存在,则更新缓存中的数据,并且由缓存组件同步更新到数据库中,如果缓存中数据不存在,我们把这种情况叫做“Write Miss(写失效)”。
3.Read Through 策略就简单一些,它的步骤是这样的:先查询缓存中数据是否存在,如果存在则直接返回,如果不存在,则由缓存组件负责从数据库中同步加载数据。
4.Write Back(回写策略)这个策略的核心思想是在写入数据时只写入缓存,并且把缓存块儿标记为“脏”的。而脏块儿只有被再次使用时才会将其中的数据写入到后端存储中。
缓存做到高可用,
1.客户端方案就是在客户端配置多个缓存的节点,通过缓存写入和读取算法策略来实现分布式,从而提高缓存的可用性。
2.中间代理层方案是在应用代码和缓存节点之间增加代理层,客户端所有的写入和读取的请求都通过代理层,而代理层中会内置高可用策略,帮助提升缓存系统的高可用。
3.服务端方案就是 Redis 2.4 版本后提出的 Redis Sentinel 方案。
4.写入数据时,需要把被写入缓存的数据分散到多个节点中,即进行数据分片;
5.读数据时,可以利用多组的缓存来做容错,提升缓存系统的可用性。关于读数据,这里可以使用主从和多副本两种策略,两种策略是为了解决不同的问题而提出的。
缓存穿透,
1.回种空值(给这个空值加一个比较短的过期时间,减少占用空间)。
2.使用布隆过滤器,先查询这个ID在布隆过滤器中是否存在,如果不存在就直接返回空值,而不需要继续查询数据库和缓存(实现技术bitmap+过滤器)。
3.在代码中控制在某一个热点缓存项失效之后启动一个后台线程,穿透到数据库,将数据加载到缓存中,在缓存未加载之前,所有访问这个缓存的请求都不再穿透而直接返回。
4.通过在 Memcached 或者 Redis 中设置分布式锁,只有获取到锁的请求才能够穿透到数据库。
CDN,
1.静态资源加速。
2.一种是 Local DNS,它是由你的运营商提供的 DNS,一般域名解析的第一站会到这里。
3.一种是权威 DNS,它的含义是自身数据库中存储了这个域名对应关系的 DNS。
4.GSLB(Global Server Load Balance,全局负载均衡)的含义是对于部署在不同地域的服务器之间做负载均衡,下面可能管理了很多的本地负载均衡组件。
数据迁移,
1.迁移应该是在线的迁移,也就是在迁移的同时还会有数据的写入;
2.数据应该保证完整性,也就是说在迁移之后需要保证新的库和旧的库的数据是一致的;
3.迁移的过程需要做到可以回滚,这样一旦迁移的过程中出现问题,可以立刻回滚到源库不会对系统的可用性造成影响。
4.使用一些开源工具DataX,Canal等。
消息队列,
1.网络抖动处理:重发
2.消息队列服务器宕机:集群
3.消息重复:使用唯一 ID 保证消息唯一性(redis自增主键,数据库唯一索引,incr,乐观锁等)。
4.Kafka是写性能,Redis是读性能,普通关系数据库是事务。
5.使用消息队列提供的工具,通过监控消息的堆积来完成(kafka-consumer-groups.sh/进度信息存储在zooKeeper中/JMX)。
6.优化消费代码提升性能,增加消费者的数量。
7.消息的存储(Page Cache),零拷贝技术(Sendfile函数/Socket缓冲区/文件缓冲区直接写到网卡)。
微服务拆分,
1.原则一, 做到单一服务内部功能的高内聚和低耦合。
2.原则二, 你需要关注服务拆分的粒度,先粗略拆分再逐渐细化。
3.原则三, 拆分的过程,要尽量避免影响产品的日常功能迭代。
4.优先剥离比较独立的边界服务(比如短信服务、地理位置服务),从非核心的服务出发减少拆分对现有业务的影响,也给团队一个练习、试错的机会。
5.当两个服务存在依赖关系时优先拆分被依赖的服务。
6.服务接口的参数类型最好是封装类,这样如果增加参数就不必变更接口的签名,而只需要在类中添加字段就可以了(原则四, 服务接口的定义要具备可扩展性)。
7.分布式追踪工具(skywalking/Sleuth+Zipkin),以及更细致的服务端监控报表。
10万QPS实现,
1.选择合适的网络模型,有针对性地调整网络参数优化网络传输性能(Nagle算法/DelayedACK合并多个ACK,提升网络传输效率)。
2.选择合适的序列化方式,以提升封包、解包的性能(JSON,Thrift, Protobuf. IDL(Interface description language))。
RPC调用过程,
- 在一次 RPC 调用过程中,客户端首先会将调用的类名、方法名、参数名、参数值等信息,序列化成二进制流;
- 然后客户端将二进制流通过网络发送给服务端;
- 服务端接收到二进制流之后将它反序列化,得到需要调用的类名、方法名、参数名和参数值,再通过动态代理的方式调用对应的方法得到返回值;
- 服务端将返回值序列化,再通过网络发送给客户端;
- 客户端对结果反序列化之后,就可以得到调用的结果了。
注意:
1.一些偶发的超时,重启时的慢请求,系统中有没有出现,有没有追查根本的原因。
2.有上亿人都用到的项目固然好,没有其实可以自己造一个,比如:一亿条数据的一个文件,怎么高效的落库等等。

若有收获,就点个赞吧
0 人点赞
