01、起因
朋友遇到个问题,我的回答是这样的:
本来以为这样就结束了,其实才刚刚进入正题;
02、问题原因定位
朋友把文件下载下来:
文件好大,这么大的文件咋统计出来是哪类线程最多呢?这就到了妥妥的文本处理内容了(关键时候这类文本命令可以帮助提供非常多的效率);
我们打开文本看看内容:
一共有 80 万行,我们来看下规律:
每个线程的开始都是” 开头,我们仅仅是需要获取线程名即可,那么就简单了,不是的” 开头都删除即可;
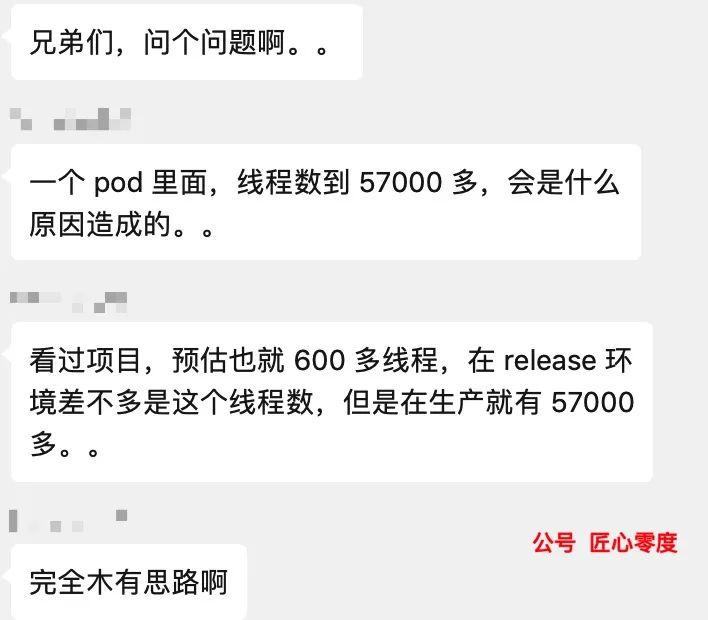
输入命令::v/"/d

之后效果: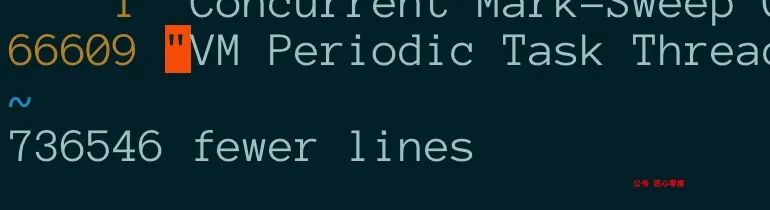
80 万的文件仅仅只剩 6.66 万行了,每一行都是一个线程,我们需要提取线程名称进行排序: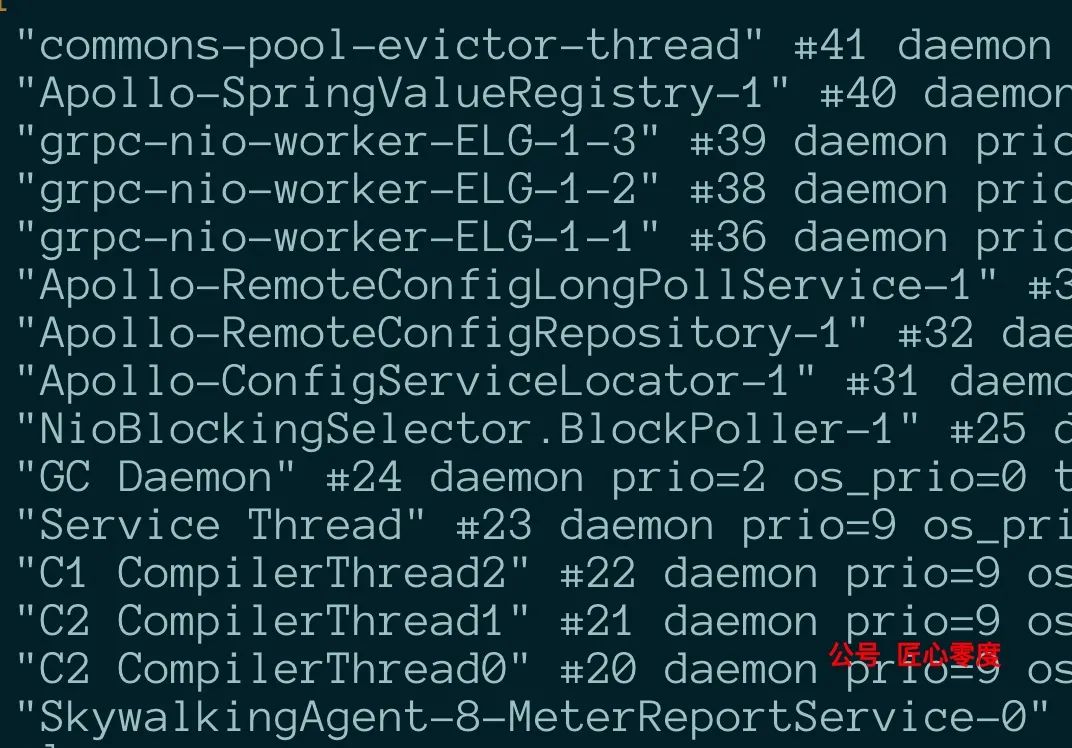
发现规律线程名称就是”线程名称” 被(双引号包围的)
输入命令:cat jstack.txt| awk -F '"' '{print $2}'>thread.txt
那么我们通过 awk 进行操作;
我们发现确实获取到了线程名称了,但是线程名称后面有后缀,我们需要把后缀给去掉,因为他们都是一类,等会我们还需要汇总统计的;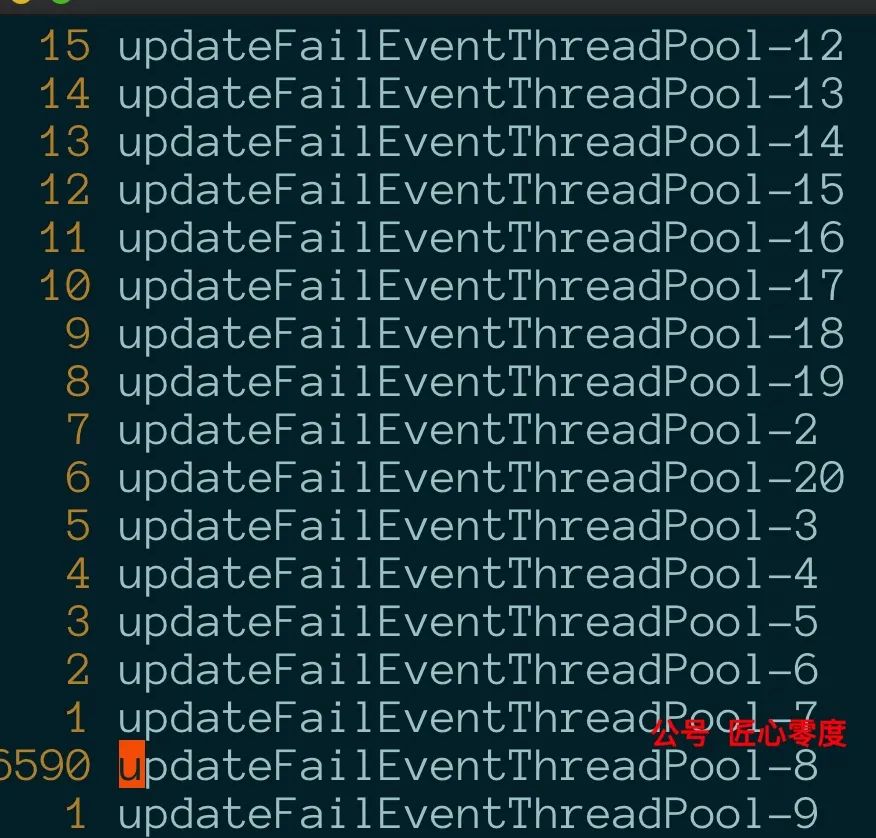
那么这个时候正则表达式就要起作用了,
输入命令::%s#\d\+$##g
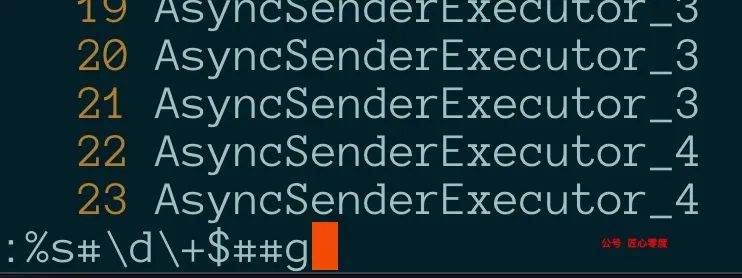
执行效果如下:
接下来就简单了,进行排序,之后获取重复次数的计数即可统计了;
输入命令:cat thread.txt|sort |uniq -c |sort -nr |head -10
效果如下: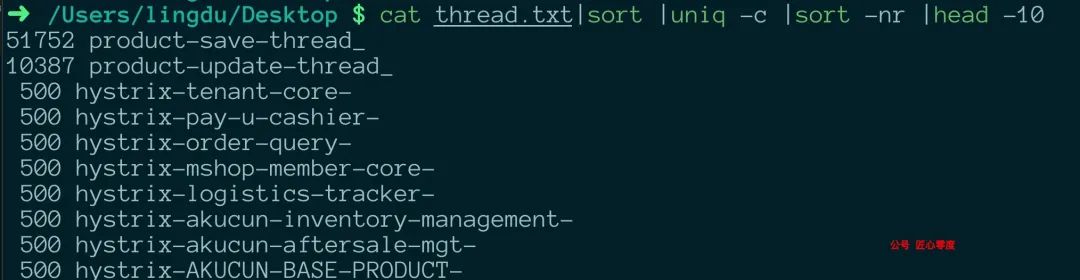
到这里我们就基本知道是哪个线程了,接下来的事情就比较简单了,告诉朋友,朋友很快就定位解决了;
03、总结
文本类的处理,还是需要熟悉的,很多时候排查定位问题还是需要这类技能的,希望今天的这个案例可以让你有所收获;

若有收获,就点个赞吧
0 人点赞
