WMS仓储管理系统
http://47.113.229.131:9080/wms/#
问:供应链选址 (仓库选址)
1.答:我们是大区 分部 DC 这样的 地理划分的,我们是自有仓,所以订单下来就已经指派DC了,我们是物流园或自有仓,仓库是固定的,就算增加客户,也会根据客户位置判断最近的仓库。
2.答:估计是通过几个点,确定仓库位置 物流或者自由仓, 物流园你应该都有坐标,geo这个有现成的,物流园都是公开的,应该也有现成的。在客户的那个位置已经知道了,然后选选个地方,然后造仓库,仓库不是现成儿的,就是客户儿固定的,通过客户的位置来确定这个仓库建在哪里, 坐标找最近的仓。
参考:https://zhuanlan.zhihu.com/p/380397512
背景介绍
出于种种原因,在供应链环节需要添加新的配送中心(Distribution Center)来满足业务需求。这些原因可能是因为需求逐年增长,也有可能因为需要更高的服务水平,来提供差异化的服务。比如需要次日达,需要三小时上门等等。
扩充DC不仅在新兴电商行业有着广泛的应用,在传统制造行业也颇为流行,只不过多数传统制造行业响应市场变化的能力较弱,反应较为滞后,一般还是仅仅只有一两个DC。
确定DC个数以及位置,就是所谓的选址的问题。当然,选址涉及的内容很多,比如:
- DC受物流的影响,这就需要考虑DC的基础设施与物流成本的权衡, DC数量与服务水平的权衡等
- DC的创建预算以及预期的自动化水平,这就需要考虑房地产成本,当地劳动力成本等
- DC的战略位置,需要考虑是否有税收优惠。比如我上一家公司,各个DC都在自贸区,因为可以客户主要分布全球,这样合理避税。多数公司都会在工厂附近设置一个
选址项目分析
选址是一个大项目,从需求收集,到方案确定,再到最后签约和承建,当然不是一篇文章能涵盖的。这里我们重点讨论如何基于python 模拟理论选址问题。
我们先定义一下简化后问题:
- 假如我们已知客户的个数和分布位置,比如100个客户以及对应的地址
- 我们假定已经确定需要的DC个数,比如6个。这个DC个数的确定以及优化我们可以后续探讨
- 现在我们需要将客户合理分配给DC。这里我们限制一个客户只允许被一个DC服务。
需求如上,我们查看一下其中的技术解决方案:
- 首先需要量化信息,因为地址作为文本内容,一般很难被模型处理,所以我们需要将地址转换为经纬度。
- 经纬度能确定一个点,两个点之间的距离是一个很好的量化指标。 但是距离其实有很多计算方式,我们默认的“距离”一般指的是欧式距离,对于小范围的选址问题,比如一个城市内,可能欧式距离也可以求得比较理想的结果。但是对于大范围选址,比如在国内选址,在全球选址,这就是造成很大的误差。因为: 地球是圆的,球面上的两点不适用欧式距离。
- 如何确定一个客户属于哪个DC呢?直觉很简单:把它分配到离它最近的那一簇里面。 距离怎么计算呢? 用该客户到这一簇的“均值点”即可。其实就是一个聚类问题,最常见的是kmeans。
- 求得DC的经纬度,应该将其还原为地址文本,这样便于人类理解。
一点点数学
球面距离
关于球面距离的计算,其中需要提到的是半正弦距离。它指的是球体表面上两点之间的角距离。假设每个点的第一个坐标是纬度,第二个是经度,以弧度表示,计算公式如下: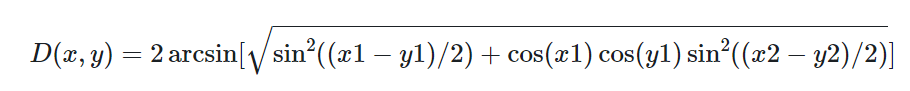
公式很简单,看不懂也不要紧,因为其实sklearn里面已经有函数了,调用haversine_distances即可。k-means 聚类
K-means 算法分为以下个步骤:
- 选择初始质心
- 将每个样本分配到其最近的质心
- 取当前所有样本的平均值来创建新质心
- 计算新旧质心之间的差异
- 算法重复最后两个步骤,直到该值小于阈值。
需要注意的是:Kmeans的计算其实采用的欧式距离,也就是两点之间的直线距离。
开始实战
一如既往,No code,No BB。
下面就开始实战了,在实战中我们打算完成如下选址任务:
- 在全国范围进行选址
- 假定100个客户,随机分布在全国范围
- 将他们分配给指定数量的DC
- 我们采用直线距离和球面距离分别求解
- 最后进行可视化对比,这里会采用Plotly地图
数据集我们就采用全国县级以上的城市的地址集,数据集和代码见文末。
全国有3500+ 县级城市,这里我们随机抽取100个作为客户的地址。采样直接调用sample 函数即可,为了保证结果可以复现,可以设定随机种子为2021。
import pandas as pdrandom_seed = 2021all_cities_df = pd.read_csv(file,encoding='gb18030')all_cities_df.shapecustomer_df = all_cities_df.sample(n=100,random_state=random_seed)customer_df
为了便于分析结果,我们先预览一下为分组前客户的分布情况。这里采用plotly Scattermapbox 进行快速绘图。采用Scattermapbox 绘图,我们需要指定经度,维度,以及鼠标悬停的显示文本即可。经纬度采用数据集中的”东经“和”北纬“数据。因为快速画图,这里marker 就采用默认的圆点。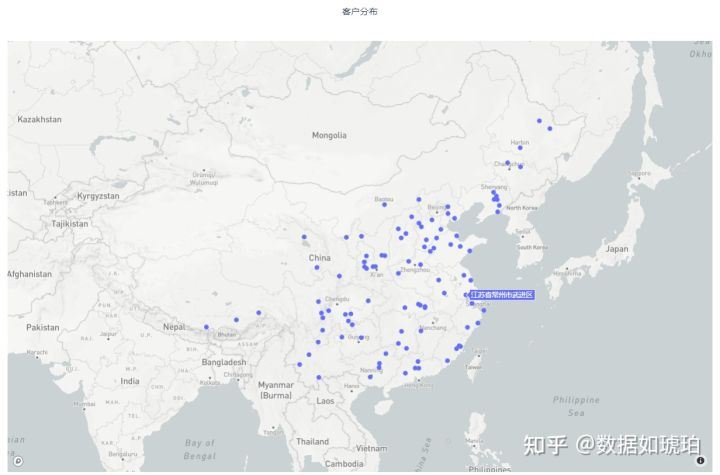
基于传统K-means 确定DC位置
前面提到K-means可以基于欧式距离快速聚类,虽然欧式距离不一定适合全国范围的选址,但是我们可以将其作为一个baseline。
from sklearn.cluster import KMeanskclusters = 6kmeans = KMeans(n_clusters=kclusters, random_state=12).fit(customer_df[['东经','北纬']])
所求得的kmeans 结果会包含clustercenters**属性,其实就是质心的位置。对应于我们的应用场景,就是求得的DC的经纬度**。
为了便于展示,我们可以通过经纬度反求出实际地址,这里调用geopy即可。
from geopy.geocoders import Nominatimgeolocator = Nominatim(user_agent="Bing")dc_kmeans_df = pd.DataFrame(kmeans.cluster_centers_,columns=['lon','lat'])def get_city(df):df['location'] = geolocator.reverse(str(df['lat'])+","+str(df['lon'])).addressreturn dfdc_kmeans_df = dc_kmeans_df.apply(get_city, axis=1)print(dc_kmeans_df)

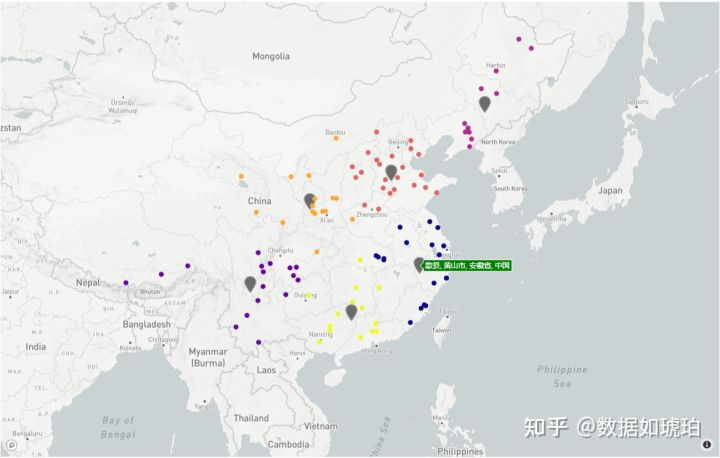
同样我们绘制客户分布以及DC分布的地图,并且用颜色和Marker区分。
fig = go.Figure()fig.add_trace(go.Scattermapbox(mode='markers',lon = dc_kmeans_df['lon'],lat = dc_kmeans_df['lat'],hovertext = dc_kmeans_df['location'],hoverinfo = 'text',marker=go.scattermapbox.Marker(size=20,color='green',symbol='marker'),))fig.add_trace(go.Scattermapbox(mode='markers',lon = customer_df['东经'],lat = customer_df['北纬'],hovertext = customer_df['地名'],hoverinfo = 'text',marker=go.scattermapbox.Marker(size=10,color = kmeans.labels_),))fig.update_layout(hovermode='closest',mapbox={'accesstoken':map_box_token,'center':{'lon':customer_df['东经'].values[0],'lat':customer_df['北纬'].values[0]},'zoom':3.6},title={'text':'客户分布','xref':'paper','x':0.5},autosize=False,width=1500,height=1000,)fig.show()
采用自定义距离来聚类
首先我们根据上面的一点点数学知识通过python 计算球面距离。其中需要注意的是P1和p2的list 顺序一定是纬度和经度,另外geopy也有distance 函数可以调用,这里计算结果略有差异。
from sklearn.metrics.pairwise import haversine_distancesfrom math import radiansdef geo_distance(p1,p2):dis = haversine_distances([[radians(_) for _ in p1], [radians(_) for _ in p2]])[0][1]* 6371000/1000 # multiply by Earth radius to get kilometersreturn dis
sklearn 的kmeans 并不支持自定义距离。这里我们需要引入更广义的Kmeans 方法:k-medoids (K中心点)。所谓的更广义是指它不再指定中心是簇样本之间的平均值,而是任意可以定义的距离中心,比如我们我们可以定义大圆距离。更幸运的是,sklearn-extra 里面已经实现了该算法,并且遵守同样的规约。
所以我们轻易的就实现了基于我们自定义的大圆距离作为metic的”广义Kmeans“算法。
from sklearn_extra.cluster import KMedoidskclusters = 6kmedoids_custom = KMedoids(n_clusters=kclusters, random_state=12,metric=geo_distance).fit(customer_df[['北纬','东经']])dc_kmedoids_custom_df = pd.DataFrame(kmedoids_custom.cluster_centers_,columns=['lat','lon'])dc_kmedoids_custom_df = dc_kmedoids_custom_df.apply(get_city, axis=1)

同样的我们再次对选址结果进行可视化,我们对比两次的结果。采用红色圆点表示基于直线距离的选址结果,采用绿色圆点表示基于大圆距离的选址结果,可以看到差别很明显。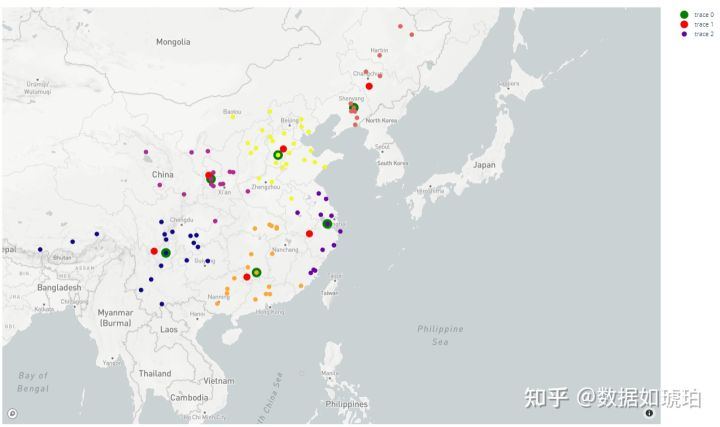
总结
本文初步探讨了供应链配送中心的选址问题,主要是采用Kmeans 方法和k-medoids 方法进行距离,从而确定DC中心点的位置。
当然文中还有一些其他小的技术解决方案,比如计算球面距离,plotly 画图等,也可供参考。
后续我们将继续探讨,如果引入服务水平,以及如何针对大客户进行优化DC的位置。

若有收获,就点个赞吧
0 人点赞
