前言
自毕业以来,开发、运维streamsets也差不多半年左右,对streamsets的使用也积累了一些经验,也踩了不少的坑,在此,为大家分享一下自己浅显经验。现阶段,我们主要在Streamsets进行实时数据同步、实时ETL、实时宽表等工作,使用Streamsets来实现实时宽表是非常简单、舒服的。
在这里,我将从Streamsets入门(介绍数据怎么在Streamsets流通的)、实时数据同步、实时宽表等方面介绍我们的工作
Streamsets介绍
Streamsets是一款大数据实时采集和ETL工具,可以实现不写一行代码完成数据的采集和流转。通过拖拽式的可视化界面,实现数据管道(Pipelines)的设计和定时任务调度。最大的特点有:1、可视化界面操作,可以直观排查错误;2、 内置监控,可是实时查看数据流传输的基本信息和数据的质量;3、强大的整合力,对现有常用组件全力支持。
对于Streamsets来说,最重要的概念就是数据源(Origins)、操作(Processors)、目的地(Destinations)、执行器(Executor)。
具体的介绍,请参考:https://streamsets.com/documentation/datacollector/3.9.x/help/index.html
官方论坛:https://ask.streamsets.com/questions/
Streamsets安装
整体来说,安装Streamsets非常简单
1、下载安装包
下载链接:https://streamsets.com/products/dataops-platform/open-source/
这里,我用的是Streamsets-3.9.1(文件名:streamsets-datacollector-3.9.1.tar)
2、安装
安装前准备:安装jdk
系统环境:centos7
解压:tar -zxvf streamsets-datacollector-3.9.1.tar
3、启动
我们先不改Streamsts参数,直接启动
cd streamsets-datacollector-3.9.1/bin 前端启动:./streamsets dc 后端启动: nohup ./streamsets dc &
4、登录
Streamsets默认端口号:18630
所以访问链接为:http://host:18630http://localhost:18630
密码:admin/admin
登录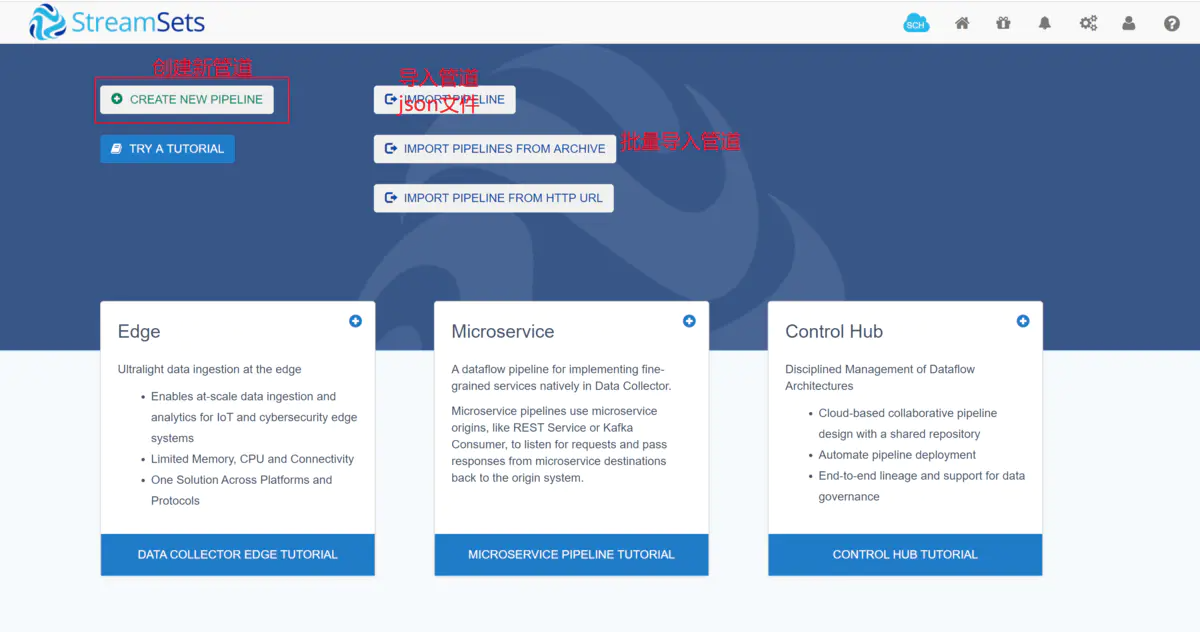
首页
实时数据同步管道,我们现在主要是将postgresql的数据同步到snappydata中。目前,我将实时数据分成了三部分(数据采集、数据过滤、操作数据库),以项目为单位创建管道(一个项目一个管道)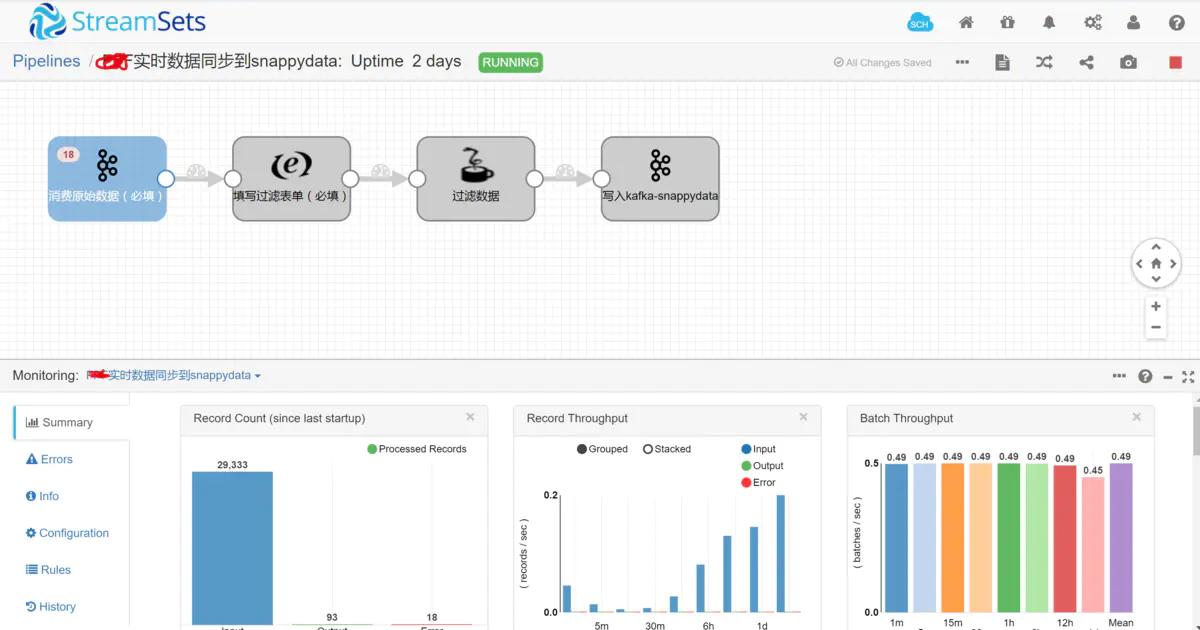
数据过滤
这是我们现在在用的实时宽表(real-time wide table)管道,后续我将详细介绍实时宽表的思路、实现过程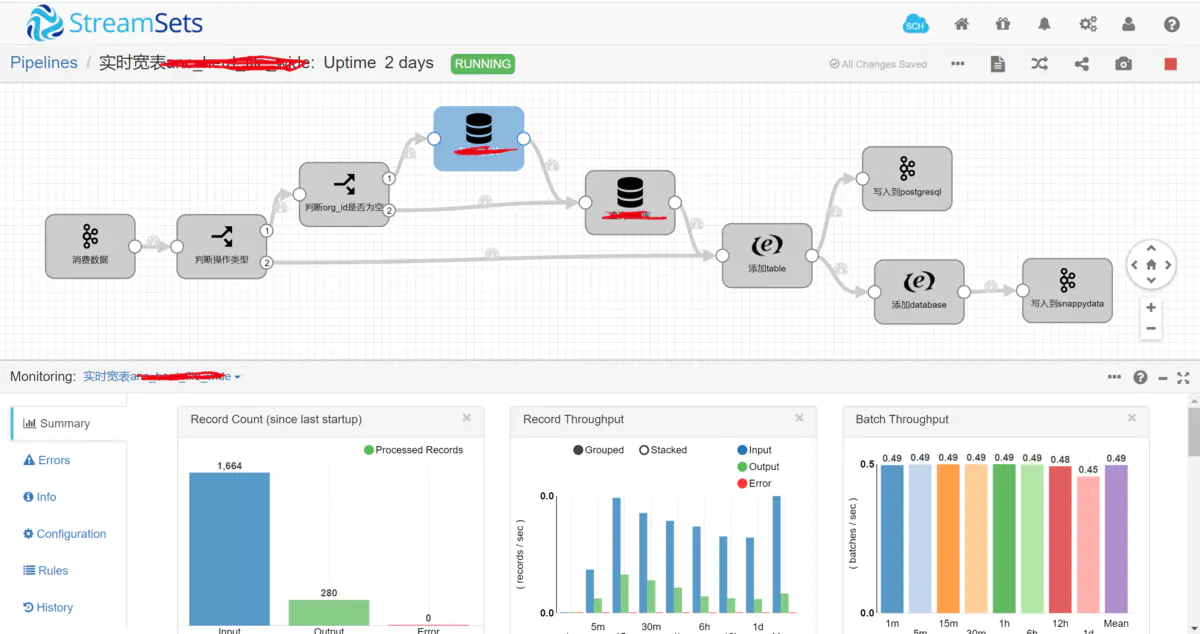
实时宽表

若有收获,就点个赞吧
0 人点赞
