Hadoop生态圈的技术繁多。HDFS一直用来保存底层数据,地位牢固。Hbase作为一款Nosql也是Hadoop生态圈的核心组件,它海量的存储能力,优秀的随机读写能力,能够处理一些HDFS不足的地方。Clickhouse是一个用于联机分析(OLAP)的列式数据库管理系统(DBMS)。能够使用SQL查询实时生成分析数据报告。它同样拥有优秀的数据存储能力。
Apache Kudu是Cloudera Manager公司16年发布的新型分布式存储系统,结合CDH和Impala使用可以同时解决随机读写和sql化数据分析的问题。分别弥补HDFS静态存储和Hbase Nosql的不足。
既然可选的技术路线有这么多,本文将从安装部署、架构组成、基本操作等方面横向对比一下Hbase、Kudu和Clickhouse。另外这里还引入了几个大厂的实践作为例子予以参考。
安装部署方式对比
具体的安装步骤不过多赘述,这里只简要比较安装过程中需要依赖的外部组件。
Habse安装
依赖HDFS作为底层存储插件 依赖Zookeeper作为元数据存储插件
Kudu安装
依赖Impala作为辅助分析插件 依赖CDH集群作为管理插件,但是不是必选的,也可以单独安装
Clickhouse安装
依赖Zookeeper作为元数据存储插件和Log Service以及表的 catalog service
组成架构对比
Hbase架构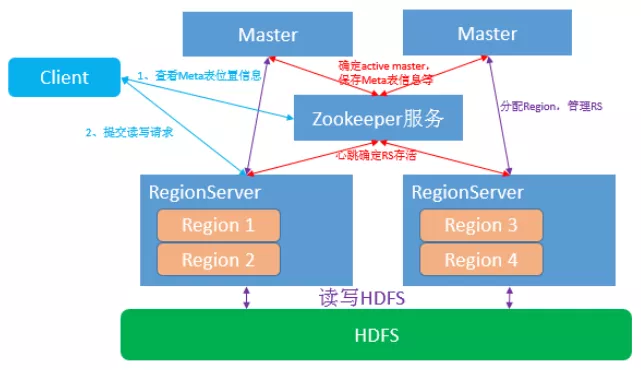
Kudu架构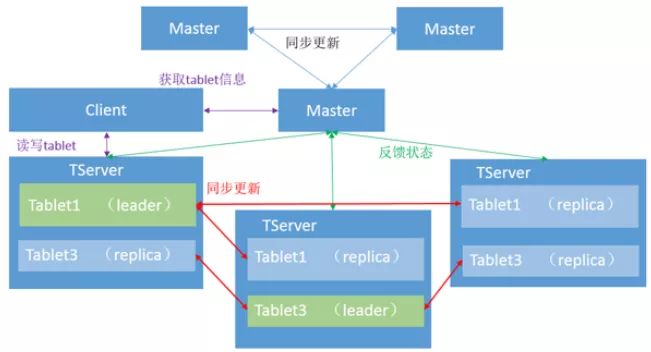
Clickhouse架构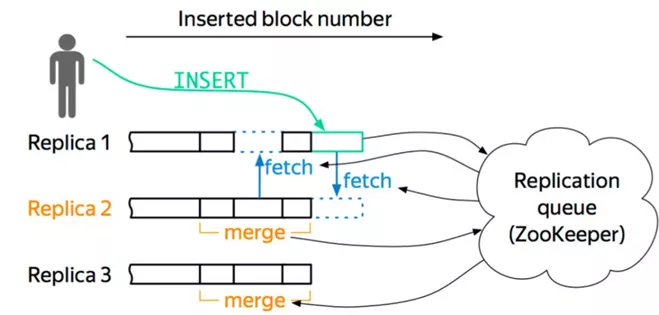
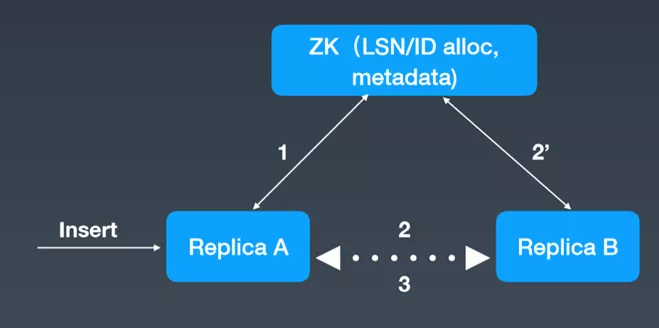
综上所示,Hbase和Kudu都是类似于Master-slave的架构而Clickhouse不存在Master结构,Clickhouse的每台Server的地位都是等价的,是multi-master模式。不过Hbase和Clickhouse额外增加了一个Zookeeper作为辅助的元数据存储或者是log server等,而Kudu的元数据是Master管理的,为了避免server频繁从Master读取元数据,server会从Master获取一份元数据到本地,但是会有元数据丢失的风险。
基本操作对比
数据读写操作
•Hbase读流程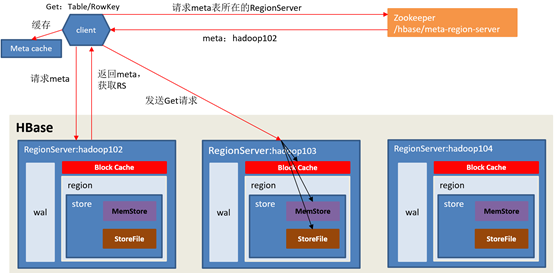
•Hbase写流程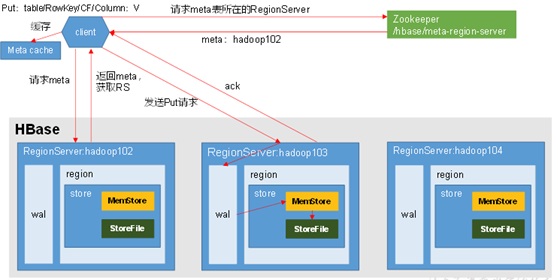
•Kudu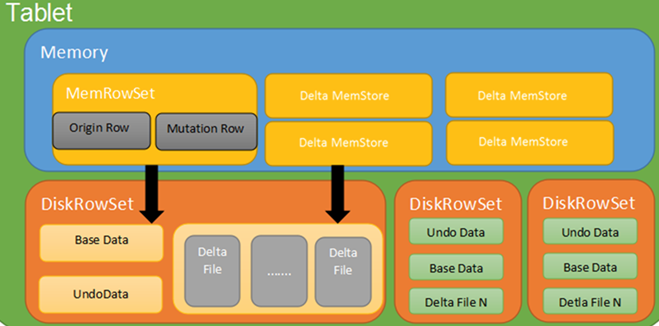
•Clickhouse
Clickhouse是个分析型数据库。这种场景下,数据一般是不变的,因此Clickhouse对update、delete的支持是比较弱的,实际上并不支持标准的update、delete操作。
Clickhouse通过alter方式实现更新、删除,它把update、delete操作叫做mutation(突变)。
标准SQL的更新、删除操作是同步的,即客户端要等服务端反回执行结果(通常是int值);而Clickhouse的update、delete是通过异步方式实现的,当执行update语句时,服务端立即反回,但是实际上此时数据还没变,而是排队等着。
Mutation具体过程
首先,使用where条件找到需要修改的分区;然后,重建每个分区,用新的分区替换旧的,分区一旦被替换,就不可回退;对于每个分区,可以认为是原子性的;但对于整个mutation,如果涉及多个分区,则不是原子性的。
•更新功能不支持更新有关主键或分区键的列•更新操作没有原子性,即在更新过程中select结果很可能是一部分变了,一部分没变,从上边的具体过程就可以知道•更新是按提交的顺序执行的•更新一旦提交,不能撤销,即使重启Clickhouse服务,也会继续按照system.mutations的顺序继续执行•已完成更新的条目不会立即删除,保留条目的数量由finished_mutations_to_keep存储引擎参数确定。超过数据量时旧的条目会被删除•更新可能会卡住,比如update intvalue=’abc’这种类型错误的更新语句执行不过去,那么会一直卡在这里,此时,可以使用KILL MUTATION来取消
综上所示,Hbase随机读写,但是Hbase的update操作不是真的update,它的实际操作是insert一条新的数据,打上不同的timestamp,而老的数据会在有效期之后自动删除。而Clickhouse干脆就不支持update和delete。
数据查询操作
•Hbase
不支持标准sql,需要集成Phoenix插件。Hbase自身有Scan操作,但是不建议执行,一般会全量扫描导致集群崩溃
•Kudu
与Impala集成实现查询
•Clickhouse
自身有优良的查询性能
HBASE在滴滴出行的应用场景和最佳实践
HBase在滴滴主要存放了以下四种数据类型:
•统计结果、报表类数据:主要是运营、运力情况、收入等结果,通常需要配合Phoenix进行SQL查询。数据量较小,对查询的灵活性要求高,延迟要求一般。•原始事实类数据:如订单、司机乘客的GPS轨迹、日志等,主要用作在线和离线的数据供给。数据量大,对一致性和可用性要求高,延迟敏感,实时写入,单点或批量查询。•中间结果数据:指模型训练所需要的数据等。数据量大,可用性和一致性要求一般,对批量查询时的吞吐量要求高。•线上系统的备份数据:用户把原始数据存在了其他关系数据库或文件服务,把HBase作为一个异地容灾的方案。
订单事件
近期订单的查询会落在Redis,超过一定时间范围,或者当Redis不可用时,查询会落在HBase上。业务方的需求如下:
•在线查询订单生命周期的各个状态,包括status、event_type、order_detail等信息。主要的查询来自于客服系统•在线历史订单详情查询。上层会有Redis来存储近期的订单,当Redis不可用或者查询范围超出Redis,查询会直接落到HBase•离线对订单的状态进行分析•写入满足每秒10K的事件,读取满足每秒1K的事件,数据要求在5s内可用
按照这些要求,我们对Rowkey做出了下面的设计,都是很典型的scan场景。
•订单状态表
Rowkey:reverse(order_id) + (MAX_LONG - TS)
Columns:该订单各种状态
•订单历史表
Rowkey:reverse(passenger_id | driver_id) + (MAX_LONG - TS)
Columns:用户在时间范围内的订单及其他信息
司机乘客轨迹
举几个使用场景上的例子:用户查看历史订单时,地图上显示所经过的路线;发生司乘纠纷,客服调用订单轨迹复现场景;地图部门用户分析道路拥堵情况。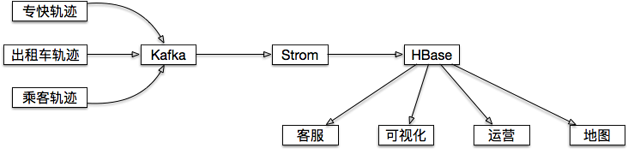
用户们提出的需求:
•满足App用户或者后端分析人员的实时或准实时轨迹坐标查询;•满足离线大规模的轨迹分析;•满足给出一个指定的地理范围,取出范围内所有用户的轨迹或范围内出现过的用户。其中,关于第三个需求,地理位置查询,我们知道MongoDB对于这种地理索引有源生的支持,但是在滴滴这种量级的情况下可能会发生存储瓶颈,HBase存储和扩展性上没有压力但是没有内置类似MongoDB地理位置索引的功能,没有就需要我们自己实现。通过调研,了解到关于地理索引有一套比较通用的GeohHash算法 。把GeoHash和其他一些需要被索引的维度拼装成Rowkey,真实的GPS点为Value,在这个基础上封装成客户端,并且在客户端内部对查询逻辑和查询策略做出速度上的大幅优化,这样就把HBase变成了一个MongoDB一样支持地理位置索引的数据库。如果查询范围非常大(比如进行省级别的分析),还额外提供了MR的获取数据的入口。两种查询场景的Rowkey设计如下:•单个用户按订单或时间段查询:reverse(user_id) + (Integer.MAX_LONG-TS/1000)•给定范围内的轨迹查询:reverse(geohash) + ts/1000 + user_id
ETA
ETA是指每次选好起始和目的地后,提示出的预估时间和价格。提示的预估到达时间和价格,最初版本是离线方式运行,后来改版通过HBase实现实时效果,把HBase当成一个KeyValue缓存,带来了减少训练时间、可多城市并行、减少人工干预的好处。整个ETA的过程如下:
1.模型训练通过Spark Job,每30分钟对各个城市训练一次2.模型训练第一阶段,在5分钟内,按照设定条件从HBase读取所有城市数据3.模型训练第二阶段在25分钟内完成ETA的计算4.HBase中的数据每隔一段时间会持久化至HDFS中,供新模型测试和新的特征提取
Rowkey:salting+cited+type0+type1+type2+TS Column:order, feature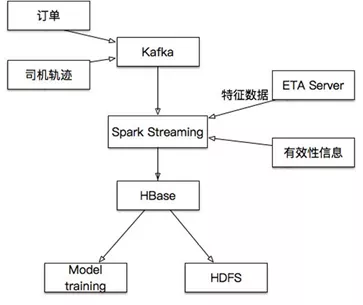
监控工具DCM
用于监控Hadoop集群的资源使用(Namenode,Yarn container使用等),关系数据库在时间维度过程以后会产生各种性能问题,同时我们又希望可以通过SQL做一些分析查询,所以使用Phoenix,使用采集程序定时录入数据,生产成报表,存入HBase,可以在秒级别返回查询结果,最后在前端做展示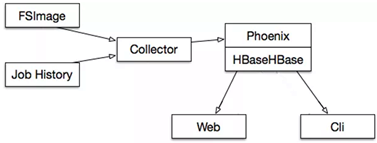
小结
在滴滴推广和实践HBase的工作中,我们认为至关重要的两点是帮助用户做出良好的表结构设计和资源的控制。有了这两个前提之后,后续出现问题的概率会大大降低。良好的表结构设计需要用户对HBase的实现有一个清晰的认识,大多数业务用户把更多精力放在了业务逻辑上,对架构实现知之甚少,这就需要平台管理者去不断帮助和引导,有了好的开端和成功案例后,通过这些用户再去向其他的业务方推广。资源隔离控制则帮助我们有效减少集群的数量,降低运维成本,让平台管理者从多集群无止尽的管理工作中解放出来,将更多精力投入到组件社区跟进和平台管理系统的研发工作中,使业务和平台都进入一个良性循环,提升用户的使用体验,更好地支持公司业务的发展。
网易考拉基于KUDU构建实时流量数仓实践
Kudu不但提供了行级的插入、更新、删除API,同时也提供了接近Parquet性能的批量扫描操作。使用同一份存储,既可以进行随机读写,也可以满足数据分析的要求
实时流/业务数据写入
可以使用Spark Streaming 提供的KafkaUtils.createDirectStream方法来创建一个对应topic的Dstream。这种方法topic的offset将完全由我们自己控制
private val stream = KafkaUtils.createDirectStream[String, String](ssc,PreferConsistent,Subscribe[String, String](topics, kafkaParams))
写入Kudu分以下几个步骤:
•获取kafka offset•创建KuduContext•定义写入Kudu表的schema•按照解析逻辑解析流量日志并构建DataFrame•将df插入Kudu并提交offset
val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRangesval spark = SparkSession.builder.config(rdd.sparkContext.getConf).getOrCreate()val kuduContext = new KuduContext(kuduMaster, spark.sparkContext)val flowDf = spark.createDataFrame(rdd.map(r => {processFlowLine(r.value)}).filter(row => if (row.get(0) == null) false else true), schema)kuduContext.upsertRows(flowDf, "impala::kaola_kudu_internal.dwd_kl_flw_app_rt")stream.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges)
写入性能测试
Kudu写入表: haitao_dev_log.dwd_kl_flw_app_rt,分片: 240个,Spark Streaming调度间隔: 15s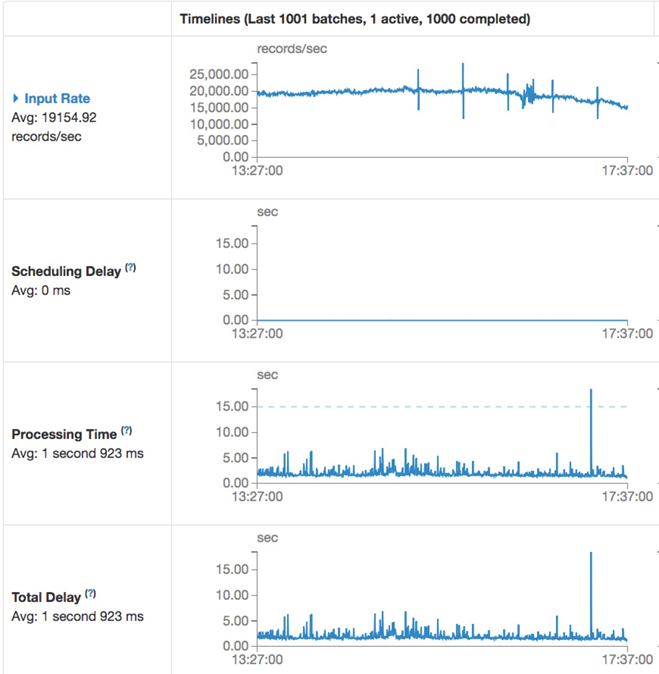

可以发现75%的任务都在1s完成,有少数任务跑的较慢但整体在2s都跑完了,这里需要注意一种极端情况,由于Spark的默认配置并发数是1,如果有一个进程迟迟没有跑完(一般是数据分布不均)那么后面的任务将会排队,直到最初的任务跑完才会去调度下一个任务。这样会造成资源浪费,多个空闲的executor会一直等待最后一个executor,流量日志不要求顺序插入,因此我们可以加大任务的并发数。具体参数设置
spark.streaming.concurrentJobs = N
小结
目前实时写入Kudu的流量日志在每日数十亿条,写入量在TB级,而且已有实时流量拆解等业务依赖Kudu的底层流量数据,接下来将会有更多的业务线迁移至Kudu以满足不同维度下的分析需求
携程CLICKHOUSE日志分析实践
结合携程的日志分析场景,日志进入ES前已经格式化成JSON,同一类日志有统一的Schema,符合ClickHouse Table的模式;日志查询的时候,一般按照某一维度统计数量、总量、均值等,符合ClickHouse面向列式存储的使用场景。偶尔有少量的场景需要对字符串进行模糊查询,也是先经过一些条件过滤掉大量数据后,再对少量数据进行模糊匹配,ClickHouse也能很好的胜任。另外我们发现90%以上的日志没有使用ES的全文索引特性,因此我们决定尝试用ClickHouse来处理日志。
消费数据到CLICKHOUSE
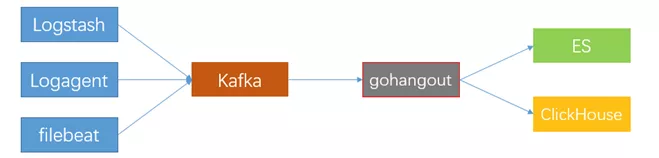
我们使用gohangout消费数据到ClickHouse,关于数据写入的几点建议:
•采用轮询的方式写ClickHouse集群的所有服务器,保证数据基本均匀分布。•大批次低频率的写入,减少parts数量,减少服务器merge,避免Too many parts异常。通过两个阈值控制数据的写入量和频次,超过10w记录写一次或者30s写一次。•写本地表,不要写分布式表,因为分布式表接收到数据后会将数据拆分成多个parts,并转发数据到其它服务器,会引起服务器间网络流量增加、服务器merge的工作量增加,导致写入速度变慢,并且增加了Too many parts的可能性。•建表时考虑partition的设置,之前遇到过有人将partition设置为timestamp,导致插入数据一直报Too many parts的异常。我们一般按天分partition。•主键和索引的设置、数据的乱序等也会导致写入变慢。
数据展示
我们调研了像Supperset、Metabase、Grafana等几个工具,最终还是决定采用在Kibana3上开发支持ClickHouse实现图表展示。主要原因是Kibana3这种强大的数据过滤功能,很多系统都不具备,另外也考虑到迁移到其他系统成本较高,用户短期内难以适应。
查询优化
Kibana中的Table Panel用于显示日志的明细数据,一般查询最近1小时所有字段的数据,最终只展示前500条记录。这种场景对于ClickHouse来说非常不友好。
针对这个问题,我们将table Panel的查询分两次进行:第一次查询单位时间间隔的数据量,根据最终显示的数据量计算出合理查询的时间范围;第二次根据修正后的时间范围,结合Table Panel中配置的默认显示的Column查询明细数据。
经过这些优化,查询的时间可以缩短到原来的1/60,查询的列可以减少50%,最终查询数据量减少到原来的1/120;ClickHouse提供了多种近似计算的方法,用于提供相对较高准确性的同时减少计算量;使用MATERIALIZED VIEW或者MATERIALIZED COLUMN将计算量放在平常完成,也能有效降低查询的数据量和计算量。
CLICKHOUSE基本运维
总体来说ClickHouse的运维比ES简单,主要包括以下几个方面的工作:
•新日志的接入、性能优化;•过期日志的清理,我们通过一个定时任务每天删除过期日志的partition;•ClickHouse的监控,使用ClickHouse-exporter+VictoriaMetrics+Grafana的实现;•数据迁移,通过ClickHouse分布式表的特性我们一般不搬迁历史数据,只要将新的数据接入新集群,然后通过分布式表跨集群查询。随着时间的推移,历史数据会被清理下线,当老集群数据全部下线后,新老集群的迁移就完成了。确实需要迁移数据时,采用ClickHouse_copier或者复制数据的方式实现。•常见问题处理:
慢查询,通过kill query终止慢查询的执行,并通过前面提到的优化方案进行优化 Too many parts异常:Too many parts异常是由于写入的part过多part的merge速度跟不上产生的速度,导致part过多的原因主要包括几个方面:
•设置不合理•小批量、高频次写ClickHouse•写的是ClickHouse的分布式表•ClickHouse设置的merge线程数太少了
• 无法启动:之前遇到过ClickHouse无法启动的问题,主要包括两个方面:
- 文件系统损坏,通过修复文件系统可以解决- 某一个表的数据异常导致ClickHouse加载失败,可以删除异常数据后启动,也可以把异常的文件搬到detached目录,等ClickHouse起来后再attach文件恢复数据
小结
将日志从ES迁移到ClickHouse可以节省更多的服务器资源,总体运维成本更低,而且提升了查询速度,特别是当用户在紧急排障的时候,这种查询速度的成倍提升,对用户的使用体验有明显的改善。
但是ClickHouse毕竟不是ES,在很多业务场景中ES仍然不可替代;ClickHouse也不仅只能处理日志,进一步深入研究ClickHouse,让ClickHouse在更多领域发挥更大的价值,是我们一直努力的方向
总结
这里简单总结一下三者的特点。
首先说一下Hbase与Kudu,可以说是Kudu师承Hbase,架构是类似的master-slave结构。Hbase的物理模型是master和regionserver,regionserver存储的是region,region里边很有很多store,一个store对应一个列簇,一个store中有一个memstore和多个storefile,store的底层是hfile,hfile是hadoop的二进制文件,其中HFile和HLog是Hbase两大文件存储格式,HFile用于存储数据,HLog保证可以写入到HFile中。
Kudu的物理模型是master和tserver,其中table根据hash和range分区,分为多个tablet存储到tserver中,tablet分为leader和follower,leader负责写请求,follower负责读请求,总结来说,一个ts可以服务多个tablet,一个tablet可以被多个ts服务(基于tablet的分区,最低为2个分区)。
而Clickhouse的特点在于它号称最快的查询性能,虽然也能存储数据,但并不是他的强项,而且Clickhouse还不能update/delete数据。
最后从下面几个维度来对比一下Hbase、Kudu和Clickhouse。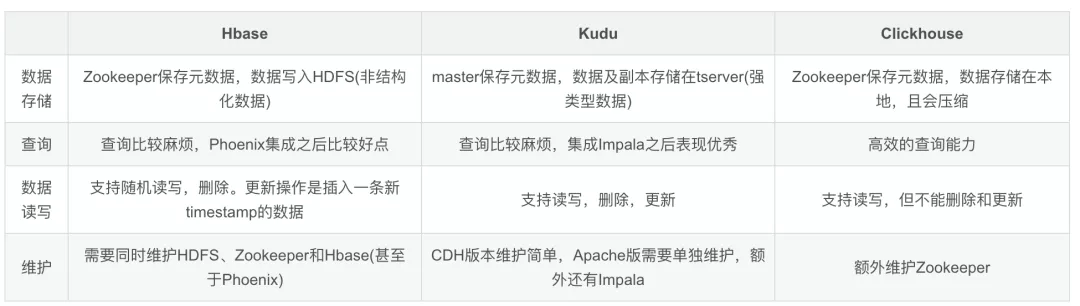
所以Hbase更适合非结构化的数据存储;在既要求随机读写又要求实时更新的场景,Kudu+Impala可以很好的胜任,当然再结合CDH就更好了,瓶颈并不在Kudu,而在Impala的Apache部署。如果只要求静态数据的极速查询能力,Clickhouse则更好。

若有收获,就点个赞吧
0 人点赞
