Filebeat 介绍
概要
Filebeat 是使用 Golang 实现的轻量型日志采集器,也是 Elasticsearch stack 里面的一员。本质上是一个 agent ,可以安装在各个节点上,根据配置读取对应位置的日志,并上报到相应的地方去。
Filebeat 的可靠性很强,可以保证日志 At least once 的上报,同时也考虑了日志搜集中的各类问题,例如日志断点续读、文件名更改、日志 Truncated 等。
Filebeat 并不依赖于 ElasticSearch,可以单独存在。我们可以单独使用Filebeat进行日志的上报和搜集。filebeat 内置了常用的 Output 组件, 例如 kafka、ElasticSearch、redis 等,出于调试考虑,也可以输出到 console 和 file 。我们可以利用现有的 Output 组件,将日志进行上报。
当然,我们也可以自定义 Output 组件,让 Filebeat 将日志转发到我们想要的地方。
filebeat 其实是 elastic/beats 的一员,除了 filebeat 外,还有 HeartBeat、PacketBeat。这些 beat 的实现都是基于 libbeat 框架。
整体工作原理
Filebeat 由两个主要组件组成:harvester 和 prospector。
采集器 harvester 的主要职责是读取单个文件的内容。读取每个文件,并将内容发送到 the output。 每个文件启动一个 harvester,harvester 负责打开和关闭文件,这意味着在运行时文件描述符保持打开状态。如果文件在读取时被删除或重命名,Filebeat 将继续读取文件。
查找器 prospector 的主要职责是管理 harvester 并找到所有要读取的文件来源。如果输入类型为日志,则查找器将查找路径匹配的所有文件,并为每个文件启动一个 harvester。每个 prospector 都在自己的 Go 协程中运行。
注:Filebeat prospector只能读取本地文件, 没有功能可以连接到远程主机来读取存储的文件或日志。
由以上两个组件一起工作来读取文件(tail file)并将事件数据发送到您指定的输出。
下图是 Filebeat 官方提供的架构图:
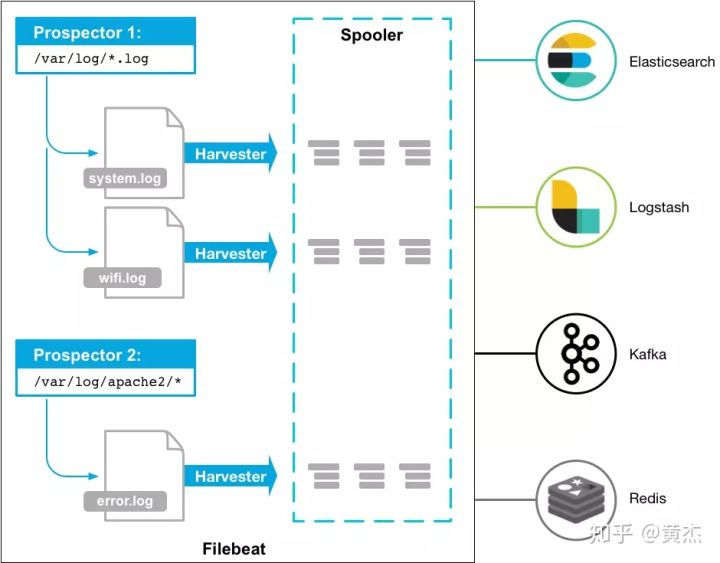
其工作流程如下:当启动 Filebeat 程序时,它会启动一个或多个查找器去检测指定的日志目录或文件。对于查找器 prospector 所在的每个日志文件,FIlebeat 会启动收集进程 harvester。 每个 harvester 都会为新内容读取单个日志文件,并将新日志数据发送到后台处理程序,后台处理程序会集合这些事件,最后发送集合的数据到 output 指定的目的地。
除了图中提到的各个组件,整个 filebeat 主要包含以下重要组件:
- Crawler:负责管理和启动各个 Input
- Input:负责管理和解析输入源的信息,以及为每个文件启动 Harvester。可由配置文件指定输入源信息。
- Harvester: Harvester 负责读取一个文件的信息。
- Pipeline: 负责管理缓存、Harvester 的信息写入以及 Output 的消费等,是 Filebeat 最核心的组件。
- Output: 输出源,可由配置文件指定输出源信息。
- Registrar:管理记录每个文件处理状态,包括偏移量、文件名等信息。当 Filebeat 启动时,会从 Registrar 恢复文件处理状态。
filebeat 的整个生命周期,几个组件共同协作,完成了日志从采集到上报的整个过程。
安装与使用
Filebeat 基于 Go 语言开发无其他依赖,它最大的特点是性能稳定、配置简单、占用系统资源很少,安装使用也非常简单,可访问 Elastic-Beats 官网获取各版本 Filebeat。因为 Filebeat 各版本之间的差异较大,这里推荐7以上的新版,首先进行下载解压:
tar -zxvf filebeat-7.tar.gzmv filebeat-7 filebeatcd filebeat
FileBeat启停指令:
调试模式下采用:终端启动(退出终端或 ctrl+c 会退出运行)
./filebeat -e -c filebeat.yml
线上环境配合 error 级别使用:以后台守护进程启动启动 filebeats
nohup ./filebeat -e -c filebeat.yml &
零输出启动(不推荐):将所有标准输出及标准错误输出到/dev/null空设备,即没有任何输出信息。
nohup ./filebeat -e -c filebeat.yml >/dev/null 2>&1 &
停止运行 FileBeat 进程
ps -ef | grep filebeatKill -9 线程号
FileBeat配置文件
FileBeat 的配置文件定义了在读取文件的位置,输出流的位置以及相应的性能参数,本实例是以 Kafka 消息中间件作为缓冲,所有的日志收集器都向 Kafka 输送日志流,相应的配置项如下,并附配置说明: ```java $ vim fileat.yml
filebeat.inputs:
- type: log enabled: true paths:
output.kafka: enabled: true hosts: [“kafka-1:9092”,”kafka-2:9092”] topic: applog version: “0.10.2.0” compression: gzip
processors:
- drop_fields: fields: [“beat”, “input”, “source”, “offset”]
logging.level: error name: app-server-ip
- **paths**:定义了日志文件路径,可以采用模糊匹配模式,如*.log- **fields**:topic 对应的消息字段或自定义增加的字段。- **output.kafka**:filebeat 支持多种输出,支持向 kafka,logstash,elasticsearch 输出数据,此处设置数据输出到 kafka。- **enabled**:这个启动这个模块。- **topic**:指定要发送数据给 kafka 集群的哪个 topic,若指定的 topic 不存在,则会自动创建此 topic。- **version**:指定 kafka 的版本。- **drop_fields**:舍弃字段,filebeat 会 json 日志信息,适当舍弃无用字段节省空间资源。- **name**:收集日志中对应主机的名字,**建议 name 这里设置为 IP**,便于区分多台主机的日志信息。以上参数信息,需要用户个性化修改的主要是:paths,hosts,topic,version 和 name。<a name="vRdSR"></a>### 异常堆栈的多行合并问题在收集日志过程中还常常涉及到对于应用中异常堆栈日志的处理,此时有两种方案,一种是在采集是归并,一种是 Logstash 过滤时归并,更建议在客户端 agent 上直接实现堆栈的合并,把合并操作的压力在输入源头上进行控制,filebeat 合并行的思路有两种,正向和逆向处理。由于 filebeat 在合并行的时候需要设置 negate 和 match 来决定合并动作,意义混淆,简直是一种糟糕的设计,直接附上配置源码和说明便于理解。<br />**第一种:符合条件才合并,容易有漏网之鱼** 说明:将以空格开头的所有行合并到上一行;并把以Caused by开头的也追加到上一行```javamultiline:pattern: '^[[:space:]]+(at|\.{3})\b|^Caused by:'negate: falsematch: after
negate 参数为 false,表示“否定参数=false”。multiline 多行参数负负得正,表示符合 pattern、match 条件的行会融入多行之中、成为一条完整日志的中间部分。如果match=after,则以b开头的和前面一行将合并成一条完整日志;如果 match=before,则以 b 开头的和后面一行将合并成一条完整日志。
第二种:不符合条件通通合并,需事先约定 说明:约定一行完整的日志开头必须是以“[”开始,不符合则归并。
multiline:pattern: '^\['negate: truematch: after
negate 参数为 true,表示“否定参数=true”。multiline 多行参数为负,表示符合 match 条件的行是多行的开头,是一条完整日志的开始或结尾。如果 match=after,则以 b 开头的行是一条完整日志的开始,它和后面多个不以 b 开头的行组成一条完整日志;如果 match=before,则以 b 开头的行是一条完整日志的结束,和前面多个不以 b 开头的合并成一条完整日志。
最后,如果对 FileBeat 占用资源的要求比较苛刻,有如下几个参数可以配置:
采用文件缓冲限制内存使用:
queue.spool:file:path: "tmp/spool.dat" #缓冲区路径size: 512MiB #缓冲区大小page_size: 16KiB #文件页面大小,采用16kb默认值write:buffer_size: 10MiB #写缓冲大小flush.timeout: 5s #写缓冲最旧事件的最长等待时间flush.events: 1024 #缓冲事件数量,满足则刷新。
文件资源优化,filebeat 是贪婪式的采集,只要有日志就会坚持采集完日志,否则就会永久持有文件句柄不“放手”,可设置文件资源配置参数优化:
close_inactive: 1m#没有新日志多长时间关闭文件句柄,默认5分钟可改短一些clean_inactive: 72h#多久清理一次registry文件,默认值为0,运行时间长可能会导致该文件变大带来性能问题。
CPU最大数量使用限制:
max_procs: 4
其他原理扩充
日志采集流程
Filebeat 不仅支持普通文本日志的作为输入源,还内置支持了 redis 的慢查询日志、stdin、tcp 和 udp 等作为输入源。
本文只分析下普通文本日志的处理方式,对于普通文本日志,可以按照以下配置方式,指定 log 的输入源信息。 ```java filebeat.inputs:- type: log
enabled: true
paths:
- /var/log/*.log
由于指定的 paths 可以配置多个,而且可以是 Glob 类型,因此 Filebeat 将会匹配到多个配置文件。其中 Input 也可以指定多个, 每个 Input 下的 Log 也可以指定多个。<br />filebeat 启动时会开启 Crawler,对于配置中的每条 Input,Crawler 都会启动一个 Input 进行处理,代码如下所示:```javafunc (c *Crawler) Start(...){...for _, inputConfig := range c.inputConfigs {err := c.startInput(pipeline, inputConfig, r.GetStates())if err != nil {return err}}...}
Input 对于每个匹配到的文件,都会开启一个 Harvester 进行逐行读取,每个 Harvester 都工作在自己的的 goroutine 中。
Harvester 的工作流程非常简单,就是逐行读取文件,并更新该文件暂时在 Input 中的文件偏移量(注意,并不是 Registrar 中的偏移量),读取完成则结束流程。
同时,我们需要考虑到,日志型的数据其实是在不断增长和变化的:
- /var/log/*.log
- 会有新的日志在不断产生
- 可能一个日志文件对应的 Harvester 退出后,又再次有了内容更新。
为了解决这两个情况,filebeat 采用了 Input 定时扫描的方式。代码如下,可以看出,Input 扫描的频率是由用户指定的 scan_frequency 配置来决定的 (默认 10s 扫描一次)。
func (p *Runner) Run() {p.input.Run()if p.Once {return}for {select {case <-p.done:logp.Info("input ticker stopped")returncase <-time.After(p.config.ScanFrequency): // 定时扫描logp.Debug("input", "Run input")p.input.Run()}}}
此外,如果用户启动时指定了 —once 选项,则扫描只会进行一次,就退出了。
日志定时扫描及异常处理
我们之前讲到 Registrar 会记录每个文件的状态,当 Filebeat 启动时,会从 Registrar 恢复文件处理状态。
其实在 filebeat 运行过程中,Input 组件也记录了文件状态。不一样的是,Registrar 是持久化存储,而 Input 中的文件状态仅表示当前文件的读取偏移量,且修改时不会同步到磁盘中。
每次,Filebeat 刚启动时,Input 都会载入 Registrar 中记录的文件状态,作为初始状态。Input 中的状态有两个非常重要:
- offset: 代表文件当前读取的 offset,从 Registrar 中初始化。Harvest 读取文件后,会同时修改 offset。
- finished: 代表该文件对应的 Harvester 是否已经结束,Harvester 开始时置为 false,结束时置为 False。
对于每次定时扫描到的文件,概括来说,会有三种大的情况:
- Input 找不到该文件状态的记录, 说明是新增文件,则开启一个 Harvester,从头开始解析该文件
- 如果可以找到文件状态,且 finished 等于 false。这个说明已经有了一个 Harvester 在处理了,这种情况直接忽略就好了。
- 如果可以找到文件状态,且 finished 等于 true。说明之前有 Harvester 处理过,但已经处理结束了。
对于这种第三种情况,我们需要考虑到一些异常情况,Filebeat 是这么处理的:
- 如果 offset 大于当前文件大小:说明文件被 Truncate 过,此时按做一个新文件处理,直接从头开始解析该文件
- 如果 offset 小于当前文件大小,说明文件内容有新增,则从上次 offset 处继续读即可。
对于第二种情况,Filebeat 似乎有一个逻辑上的问题: 如果文件被 Truncate 过,后来又新增了数据,且文件大小也比之前 offset 大,那么 Filebeat 是检查不出来这个问题的。
除此之外,一个比较有意思的点是,Filebeat 甚至可以处理文件名修改的问题。即使一个日志的文件名被修改过,Filebeat 重启后,也能找到该文件,从上次读过的地方继续读。
这是因为 Filebeat 除了在 Registrar 存储了文件名,还存储了文件的唯一标识。对于 Linux 来说,这个文件的唯一标识就是该文件的 inode ID + device ID。
至此,我们可以清楚的知道,Filebeat 是如何采集日志文件,同时做到监听日志文件的更新和修改。而日志采集过程,Harvest 会将数据写到 Pipeline 中。我们接下来看下数据是如何写入到 Pipeline 中的。
Pipeline 的写入
Haveseter 会将数据写入缓存中,而另一方面 Output 会从缓存将数据读走。整个生产消费的过程都是由 Pipeline 进行调度的,而整个调度过程也非常复杂。
此外,Filebeat 的缓存目前分为 memqueue 和 spool。memqueue 顾名思义就是内存缓存,spool 则是将数据缓存到磁盘中。本文将基于 memqueue 讲解整个调度过程。
我们首先看下 Haveseter 是如何将数据写入缓存中的,如下图所示:
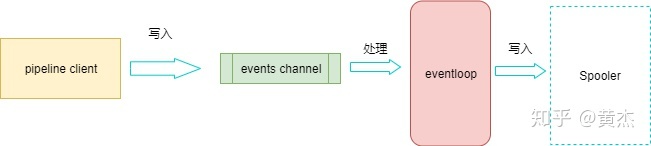
Harvester 通过 pipeline 提供的 pipelineClient 将数据写入到 pipeline 中,Haveseter 会将读到的数据会包装成一个 Event 结构体,再递交给 pipeline。
在 Filebeat 的实现中,pipelineClient 并不直接操作缓存,而是将 event 先写入一个 events channel 中。
同时,有一个 eventloop 组件,会监听 events channel 的事件到来,等 event 到达时,eventloop 会将其放入缓存中。
当缓存满的时候,eventloop 直接移除对该 channel 的监听。 每次 event ACK 或者取消后,缓存不再满了,则 eventloop 会重新监听 events channel。
以上是 Pipeline 的写入过程,此时 event 已被写入到了缓存中。 但是 Output 是如何从缓存中拿到 event 数据的?
Pipeline 的消费过程
整个消费的过程非常复杂,数据会在多个 channel 之间传递流转,如下图所示: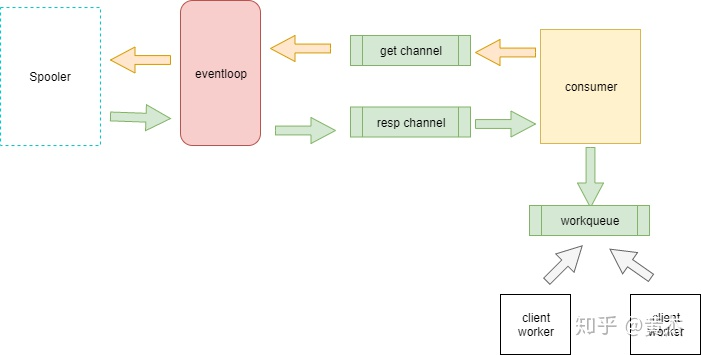
首先再介绍两个角色:
- consumer: pipeline 在创建的时候,会同时创建一个 consumer。consumer 负责从缓存中取数据
- client worker:负责接收 consumer 传来的数据,并调用 Output 的 Publish 函数进行上报。
与 producer 类似,consumer 也不直接操作缓存,而是会向 get channel 中写入消费请求。 consumer 本身是个后台 loop 的过程,这个消费请求会不断进行。
eventloop 监听 get channel, 拿到之后会从缓存中取数据。并将数据写入到 resp channel 中。 consumer 从 resp channel 中拿到 event 数据后,又会将其写入到 workQueue。
workQueue 也是个 channel。client worker 会监听该 channel 上的数据到来,将数据交给 Output client 进行 Publish 上报。
而且,Output 收到的是 Batch Events,即会一次收到一批 Events。BatchSize 由各个 Output 自行决定。
至此,消息已经递交给了 Output 组件。
Ack 机制
filebeat 之所以可以保证日志可以 at least once 的上报,就是基于其 Ack 机制。
简单来说,Ack 机制就是,当 Output Publish 成功之后会调用 ACK,最终 Registrar 会收到 ACK,并修改偏移量。
而且, Registrar 只会在 Output 调用 batch 的相关信号时,才改变文件偏移量。其中 Batch 对外提供了这些信号:
type Batch interface {Events() []Event// signalsACK()Drop()Retry()RetryEvents(events []Event)Cancelled()CancelledEvents(events []Event)}
Output 在 Publish 之后,无论失败,必须调用这些函数中的其中一个。
以下是 Output Publish 成功后调用 Ack 的流程: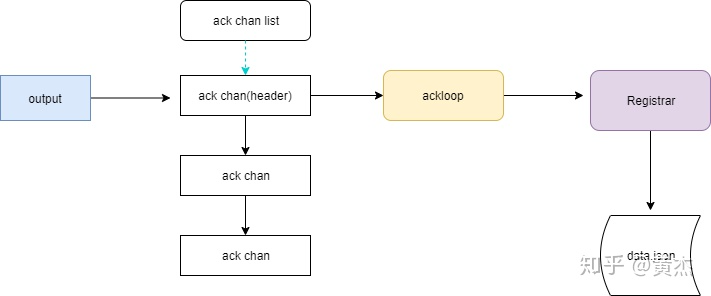
可以看到其中起核心作用的组件是 Ackloop。AckLoop 中有一个 ackChanList,其中每一个 ackChan,对应于转发给 Output 的一个 Batch。 每次新建一个 Batch,同时会建立一个 ackChan,该 ackChan 会被 append 到 ackChanList 中。
而 AckLoop 每次只监听处于 ackChanList 最头部的 ackChan。
当 Batch 被 Output 调用 Ack 后,AckLoop 会收到对应 ackChan 上的事件,并将其最终转发给 Registrar。同时,ackChanList 将会 pop 头部的 ackChan,继续监听接下来的 Ack 事件。
总结
了解了 Filebeat 的实现原理,我们才有会明白 Filebeat 配置中各个参数对程序的最终影响。同时,由于 FileBeat 是 At least once 的上报,但并不保证 Exactly once, 因此一条数据可能会被上报多次,所以接收端需要自行进行去重过滤。

若有收获,就点个赞吧
0 人点赞
