数据类型
原始值类型(值类型/基本数据类型)
NumberStringBooleanNullUndefinedObjectSymbol-
对象类型(引用数据类型)
标准普通对象:
object- 标准特殊对象:
Array、RegExp、Date、Math、Error…… - 非标准特殊对象:
Number、String、Boolean…… - 可调用/执行对象”函数”:
function类型转化
显式类型强制转换是指当开发人员通过编写适当的代码用于在类型之间进行转换Number(value)
隐式类型转换是指在对不同类型的值使用运算符时,值可以在类型之间自动的转换
1 == null
在 JS 中只有 3 种类型的转换
- 转化为
Number类型:Number()/parseFloat()/parseInt() - 转化为
String类型:String()/toString() - 转化为
Boolean类型:Boolean()
堆/栈
- JS 就是动态语言,因为在声明变量之前并不需要确认其数据类型,所以 JS 的变量是没有数据类型的,值才有数据类型,变量可以随时持有任何类型的数据。
- JS 数据类型可分为两大类——基本类型和引用类型。
手动回收
例如以前学 C 的时候,何时分配内存、何时销毁内存都是由代码控制的,如下:
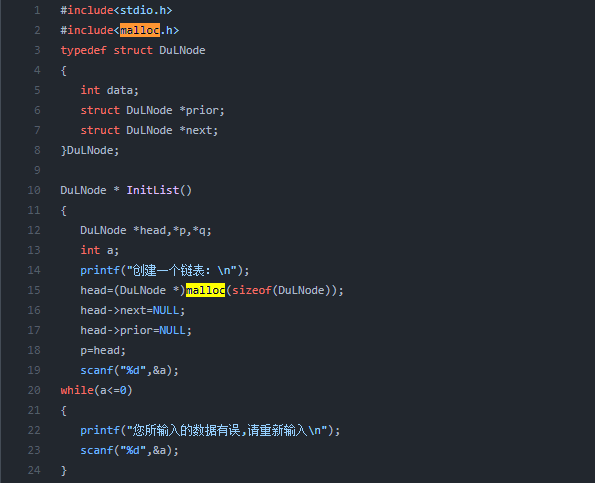
自动回收
自动垃圾回收的策略,如 JavaScript,产生的垃圾数据是由垃圾回收器来释放的,并不需要手动通过代码来释放。下面记录几个小疑惑。
- 对于栈中的垃圾回收,JS 引擎通过向下移动
ESP(extended stack pointer当前执行状态针)指针(记录调用栈当前执行状态的指针),来销毁该函数保存在栈中的执行上下文(变量环境、词法环境、this、outer),这里是不需要通过V8的垃圾回收机制的,效率非常高。 - 对于堆中的垃圾回收,主要通过副垃圾回收器(新生代)和主垃圾回收器(老生代)负责的,副垃圾回收器采用
scavenge算法将区域分为对象区域和空闲区域,通过两个区域的反转让新生代区域无限使用下去。主垃圾回收器采用Mark-Sweep(Mark-Compact Incremental Marking解决不同场景下问题的算法改进)算法进行空间回收的。无论是主副垃圾回收器的策略都是标记-清除-整理三个大的步骤。另外还有新生代的晋升策略(两次未清除的),大对象直接分配在老生代。新生代和老生代
新生代
算法:
Scavenge算法
:::info 原理:
- 把新生代空间对半划分为两个区域,一半是对象区域,一半是空闲区域。
- 新加入的对象都会存放到对象区域,当对象区域快被写满时,就需要执行一次垃圾清理操作。
- 先对对象区域中的垃圾做标记,标记完成之后,把这些存活的对象复制到空闲区域中
- 完成复制后,对象区域与空闲区域进行角色翻转,也就是原来的对象区域变成空闲区域,原来的空闲区域变成了对象区域。
对象晋升策略:经过两次垃圾回收依然还存活的对象,会被移动到老生区中。 :::
老生代
算法:标记 - 清除(
Mark-Sweep)算法
:::info 原理:
- 标记:标记阶段就是从一组根元素开始,递归遍历这组根元素,在这个遍历过程中,能到达的元素称为活动对象,没有到达的元素就可以判断为垃圾数据。
- 清除:将垃圾数据进行清除。
- 碎片:对一块内存多次执行标记 - 清除算法后,会产生大量不连续的内存碎片。而碎片过多会导致大对象无法分配到足够的连续内存。 :::
算法:标记 - 整理(
Mark-Compact)算法
:::info 原理:
- 标记:和标记 - 清除的标记过程一样,从一组根元素开始,递归遍历这组根元素,在这个遍历过程中,能到达的元素标记为活动对象。
- 整理:让所有存活的对象都向内存的一端移动
- 清除:清理掉端边界以外的内存 :::
优化算法:增量标记(
Incremental Marking)算法
:::info 原理:
- 为了降低老生代的垃圾回收而造成的卡顿
- V8把一个完整的垃圾回收任务拆分为很多小的任务
- 让垃圾回收标记和 JavaScript 应用逻辑交替进行 :::
判断内存泄漏
- 可能长时间运行页面卡顿,感官上猜测可能会有内存泄漏,通过
DynaTrace(IE)、Performance(Chrome)等工具收集数据。 - 在页面进行各种交互,在一定的时间内(越长越好),生成统计数据,观察内存变化(
timeline),如变化规律为周期且平稳的,则不存在泄漏可能。但是变化趋势是向上,就存在内部泄漏的可能! 但有个小问题,在统计图表发现
heap、document、Nodes、Listeners等。这个变化趋势是由什么控制的?—- js堆内存吗工作中避免内存泄漏
确定不使用的临时变量置为
nulles6普及场景下少使用闭包也是一种方法闭包
闭包就是能够读取其他函数内部变量的函数,或者子函数在外调用,子函数所在的父函数的作用域不会被释放。 当在一个函数内定义另外一个函数就会产生闭包。
作用
为什么要用:
匿名自执行函数:我们知道所有的变量,如果不加上 var 关键字,则默认的会添加到全 局对象的属性上去,这样的临时变量加入全局对象有很多坏处,比如:别的函数可能误用这些变量;造成全局对象过于庞大,影响访问速度(因为变量的取值是需要从原型链 上遍历的)。除了每次使用变量都是用 var 关键字外,我们在实际情况下经常遇到这样一种情况,即有的函数只需要执行一次,其内部变量无需维护,可以用闭包。
结果缓存:我们开发中会碰到很多情况,设想我们有一个处理过程很耗时的函数对象, 每次调用都会花费很长时间,那么我们就需要将计算出来的值存储起来,当调用这个函数的时候,首先在缓存中查找,如果找不到,则进行计算,然后更新缓存并返回值,如果找到了,直接返回查找到的值即可。闭包正是可以做到这一点,因为它不会释放外部的引用,从而函数内部的值可以得以保留。
Links

若有收获,就点个赞吧
0 人点赞
