第二周从单变量线性回归,推广到多变量线性回归。
第一小节介绍了推广到多变量上的模型假设函数、代价方程和梯度下降,特征缩放可以加快梯度下降,均值归一化在除以范围大小前需要减去均值,学习速率对梯度下降的影响,以及多项式回归对更复杂问题的拟合。
第二小节,介绍了另一种对线性回归方程求最佳参数的方法——分析法,以及在不同情况如何选择使用梯度下降和分析法优化线性回归参数。
多变量线性回归Linear Regression With Multiple Variables
2.2 Multivariate Linear Regression
多特征Multiple Feature
单变量线性回归例子中,我们只是用了房屋面积一个特征,事实上,我们还可以考虑房间数量、楼层数量、使用年限等多个特征。
对应的假设函数,将由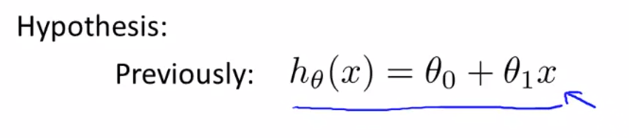
变为
多变量线性回归中的梯度下降 Gradient Descend for Multiple Variable
随着特征增多、参数增多,同样代价方程、和梯度下降的步骤也更复杂。
我们可以将单变量和多变量的梯度下降过程进行对比。
特征缩放 Gradient Descent in Featrue Scaling
不同变量的定义域大小也许不一样,会拉慢梯度下降的速度。
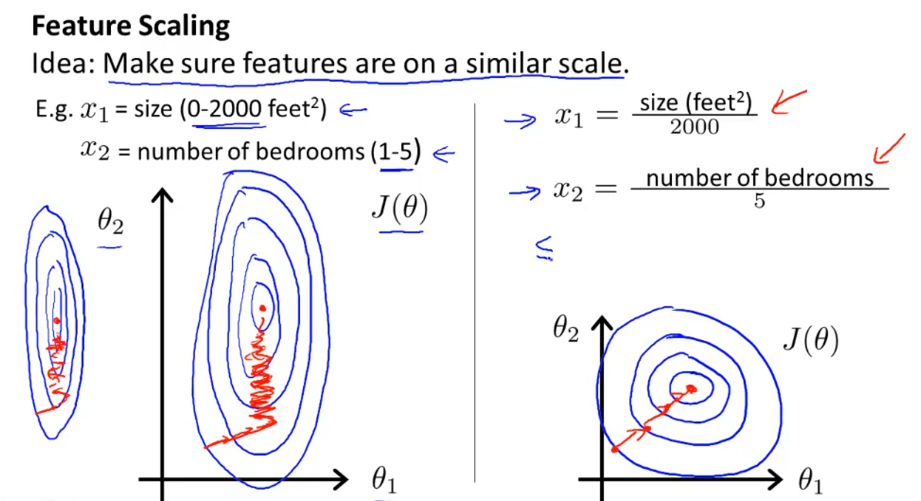
缩放的范围并不需要太精确。
均值归一化也是一种选择,在缩放之前减去均值。
学习速率 Gradient Descent in Learning Rate
将迭代次数和代价指绘制学习曲线,确认梯度下降正在起作用。
学习速度的大小可以直观地影响在学习曲线。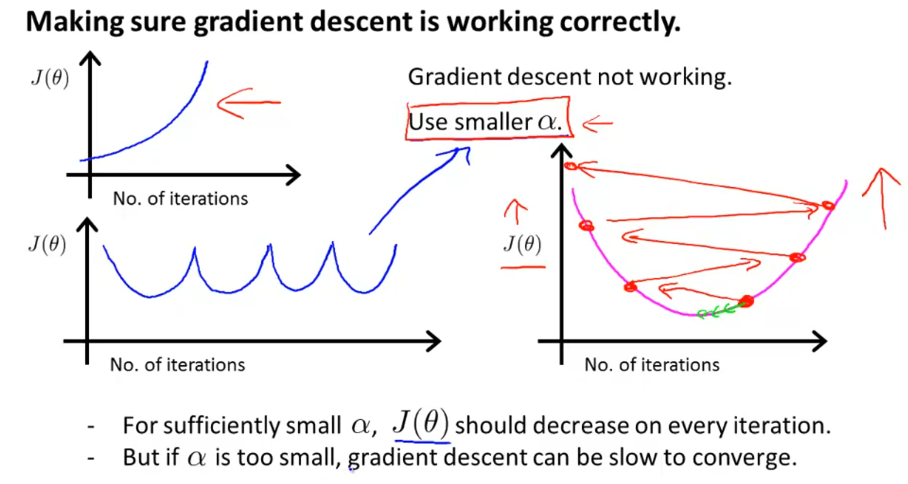
如果学习速率太小,学习曲线会收敛的很慢;但如果太大,代价可能不会减少、不会收敛。
学习速率可以选择 0.001,0.01,0.1,1等。
特征和多项式回归 Features and Polynormial Regression
选择特征的方法
回到之前的单变量回归,有时候我们会发现一个特征和结果的关系并不单单是直线关联,特征的一次表示就有点不够用了,这时候一个特征,我们可以使用不同次的多项式来拟合。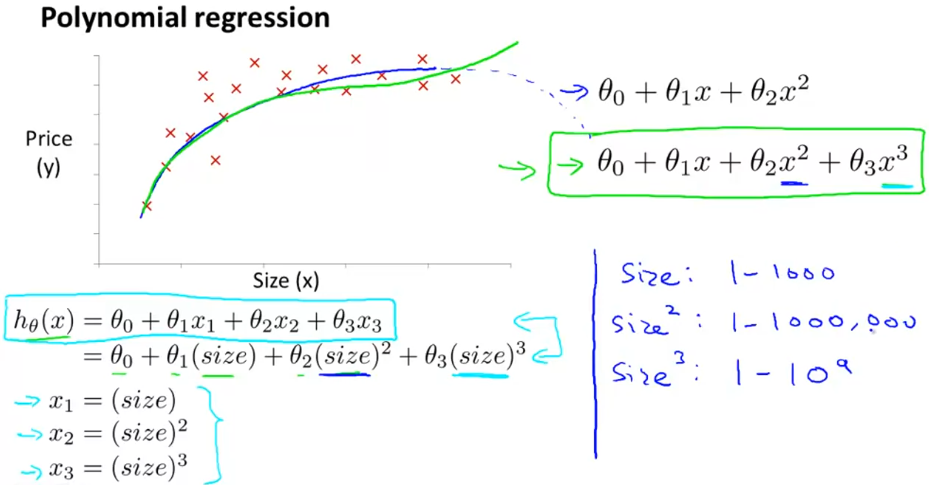

2.3 分析法计算参数Computing Parameters Analytically
正规方程 Normal Equation
梯度下降需要一次次求偏导更新参数,然后观察性能再确定理想的theta值。
而正规方程提供了一种直接计算最佳theta参数的方法,理解为求偏导之后,令等式为0再解方程组。

然而一一求解方程组很复杂,线性代数中抽象出了更简单的方法。直接用下列等式计算。粉字表示正规方程不需要均值归一化。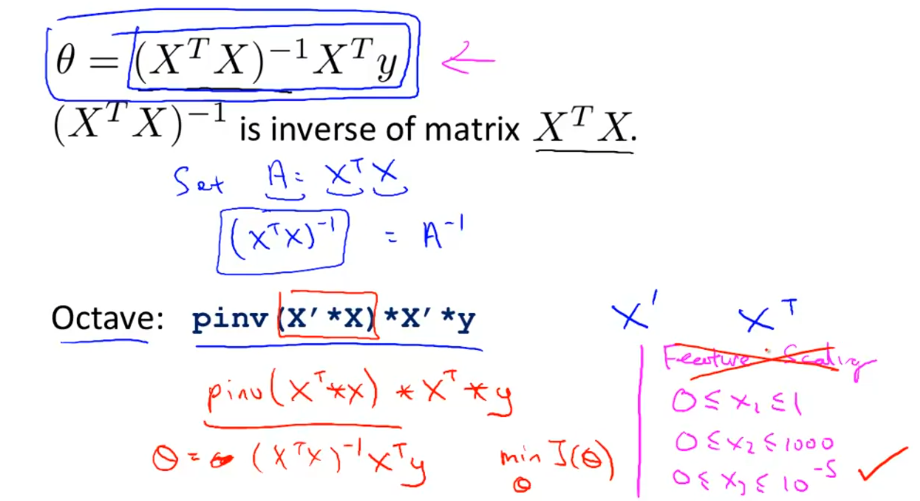
以下是梯度下降和正规方程的对比,根据特征数量的多少来选择。
不可逆性 Normal Equation Noninvertibility
如果矩阵X’X结果是不可逆的
通常有两种最常见的原因
第一个原因是 拥有重复的参数。
例如 在预测住房价格时,如果x1是以英尺为尺寸规格计算的房子,x2是以平方米为尺寸规格计算的房子,1米等于3.28英尺 ( 四舍五入到两位小数 ) 。这样 你的这两个特征值将始终满足约束 x1等于x2倍的3.28平方,这两个变量就重复了。
第二个原因是 特征值数量比样本数量多,即m小于或等于n。

若有收获,就点个赞吧
0 人点赞
