Support Vector Machines
面对处理非线性问题,支持向量机同样是一个强大的的算法。
7.1 Large Margin Classfication 大边缘分类
Optimization Objectives 优化目标
回顾逻辑回归中的代价方程,左右两项的逻辑映射函数如下图所示。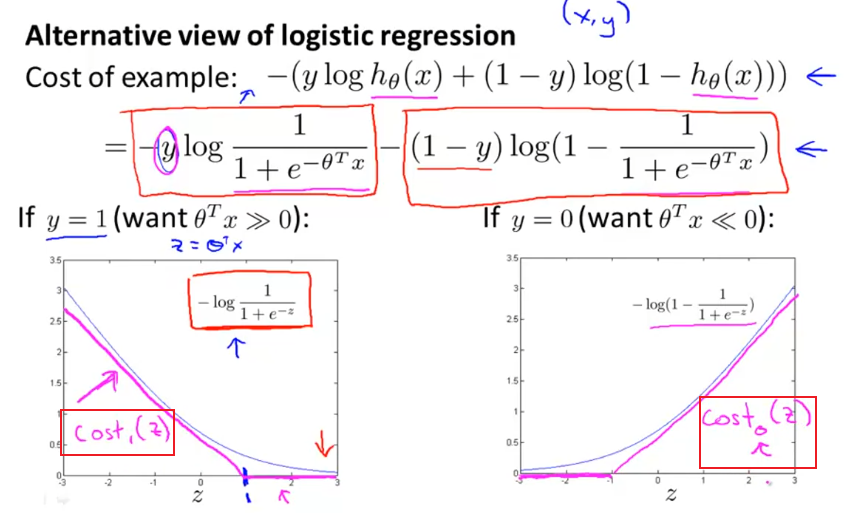
我们可以近似的将这两条曲线,换成直线的分段函数cost1和cost2,就可以初步得到支持向量机形式的代价方程。
中间还有两点无关痛痒的变化,只是为了更加符合支持向量机的惯例。
1、取消了各项除以m。
2、取消正则项的lambda,在代价项上加上一个常数C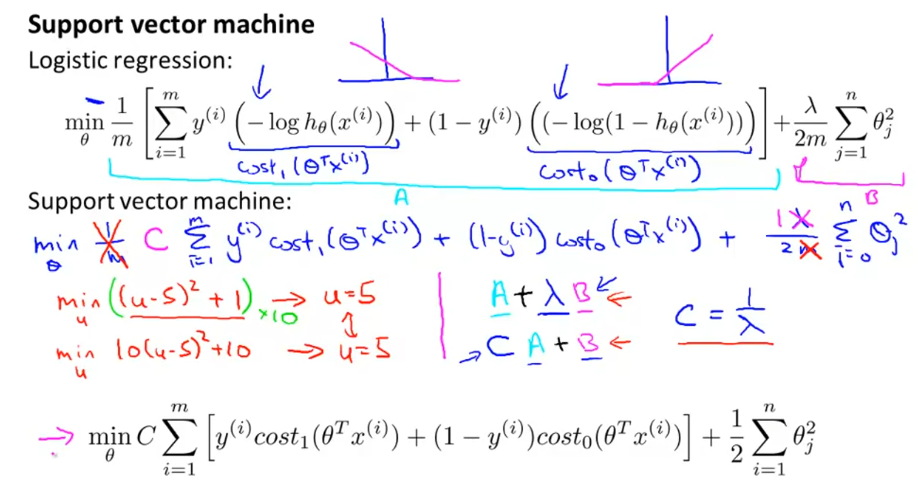
所以以上可以看出,支持向量机的更加直接的给出结果。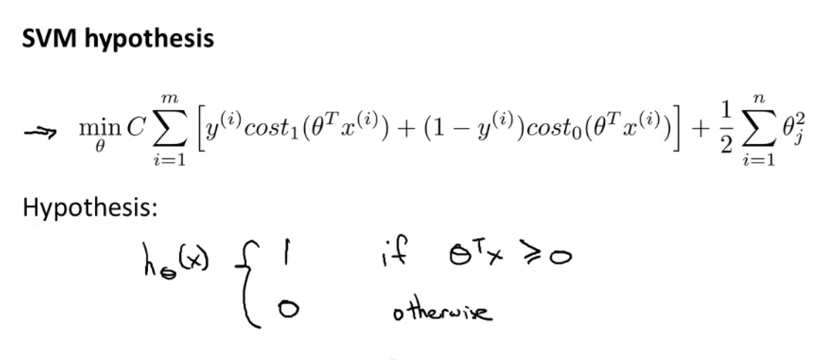
接下来将从更直观的角度,看优化目标实际上是在做什么,以及SVM的假设函数将会学习什么,同时也会谈谈如何做修改,使学习更加复杂、非线性的函数。
Large Margin Intuition 大分类分类器介绍
人们有时将支持向量机看做是大间距分类器,因为我们可以修改cost0和cost1的方程,控制分类器的筛选效果。
当C特别大时,很容易受异常点影响;当C不是特别大时,就可以忽略一些异常点。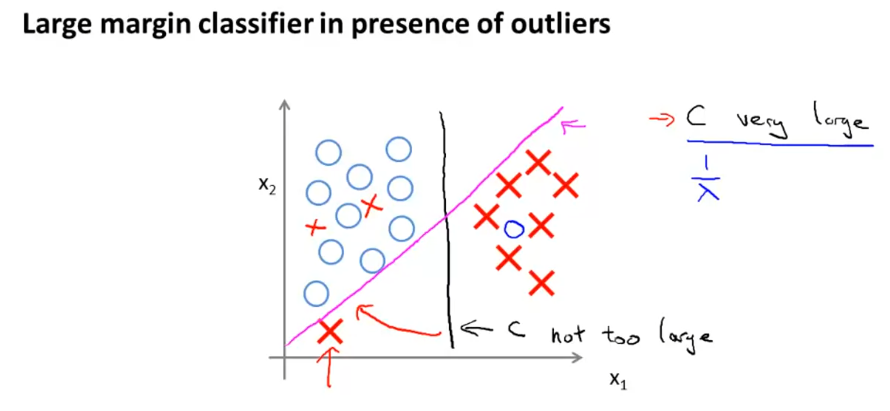
7.2 Kernels 核函数
假设我们有下面如图的训练集,一般的方法可以通过构造多项式线性回归,但如果有很多特征时,计算量会非常大,那么可不可以构造一些新的变量呢?
我们可以手动选取几个点,然后根据特征x构造新的特征f,比如说通过相似性核函数,计算他们的欧氏距离的负数的指数函数。
当x接近于某个特征点时,对应构造的新特征f会接近1;反之远离时,会接近0。
通过新特征f,当一个点在圈内时,参数和特征f的点积会大于零,通过激活函数会判断为1;反之如果对于一个在圈外的点,则点积小于0,判断为0。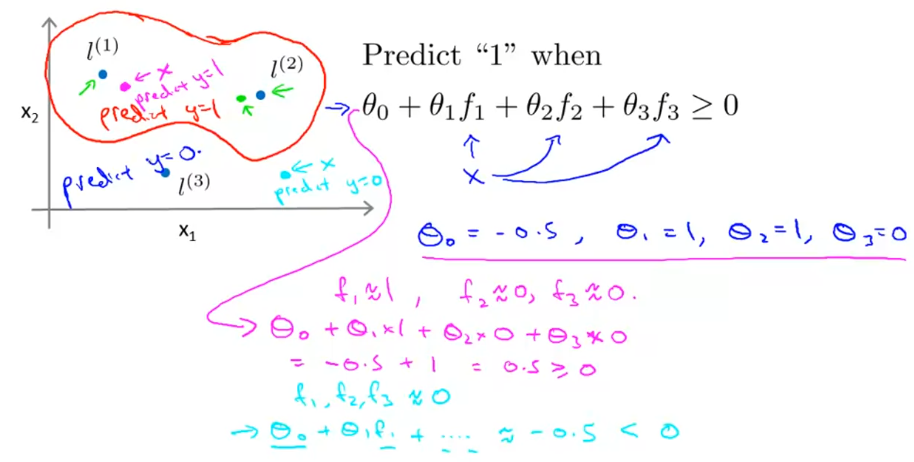

若有收获,就点个赞吧
0 人点赞
