Advice for Applying Machine Learning
6.1 评估算法 Evaluating a Learning Algorithm
Deciding What to Try Next
在前几周的学习中,我们已经学习了很多先进的机器学习技术。
但是目前为止,我们只是说了如何做,还没有说怎么样才算做的好。
评估一个假设 Evaluating a Hypothesis
我们可以简单地从数据集中抽出一小部分,作为测试集,测试我们模型假设的性能。
比如说按照7:3的比例,70%的数据做来给模型训练,剩下的测试模型的表现。
模型选择和数据集划分 Model Selection and Train/Validation/Test Sets
模型的训练不仅仅包括训练参数,我们同样需要选择合适的参超数,这时候再分出一部分数据集,称为交叉验证集,用来调整超参,测试集用来测试实际效果。
一般按照6:2:2的比例划分训练集、交叉验证集和测试集。
我们会在训练集上训练多个模型,然后选择在交叉验证集上性能最好的那个。
6.2 误差 Bias vs. Variance
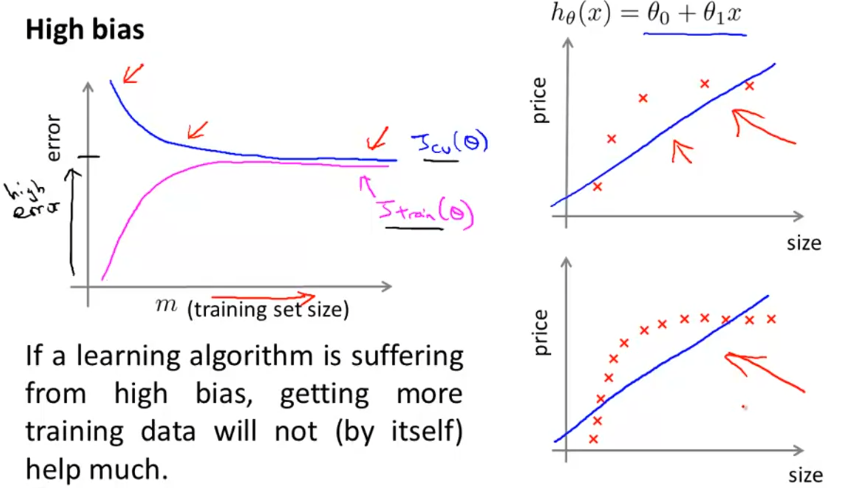
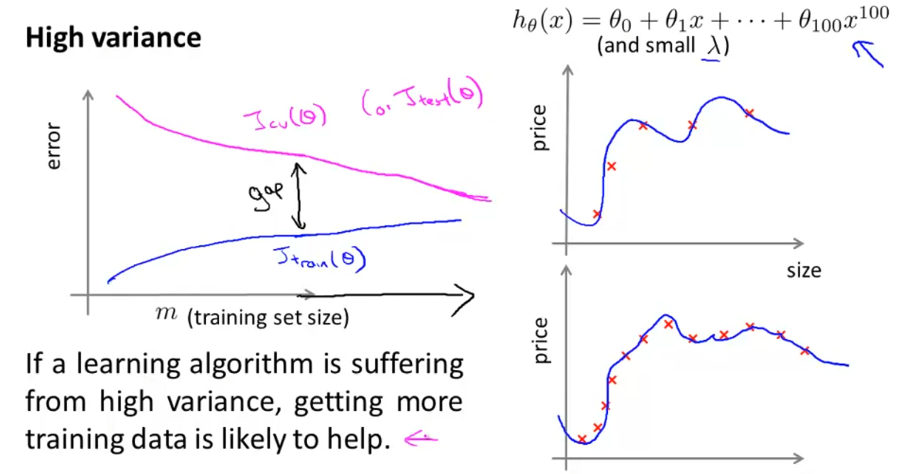
判断偏差还是方差 Diagnosing Bias vs. Variance
当一个模型不理想时,要么是偏差bias比较大,要么是方差variance比较大。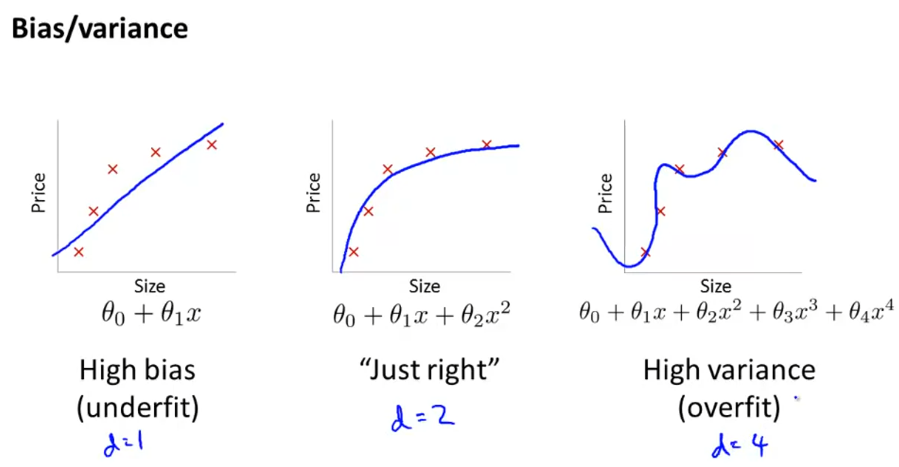
在多项式回归中,特征次数越高,越容易方差,反之容易偏差。
正则化与偏差方差 Regularization and Bias/Variance
正则化和误差有什么关系呢?
正则化参数越小越容易方差,反之容易偏差。
学习曲线 Learning Curves
学习曲线横轴是数据集大小,纵轴是模型代价。
随着数据大小增加,训练误差增加,验证机代价减小。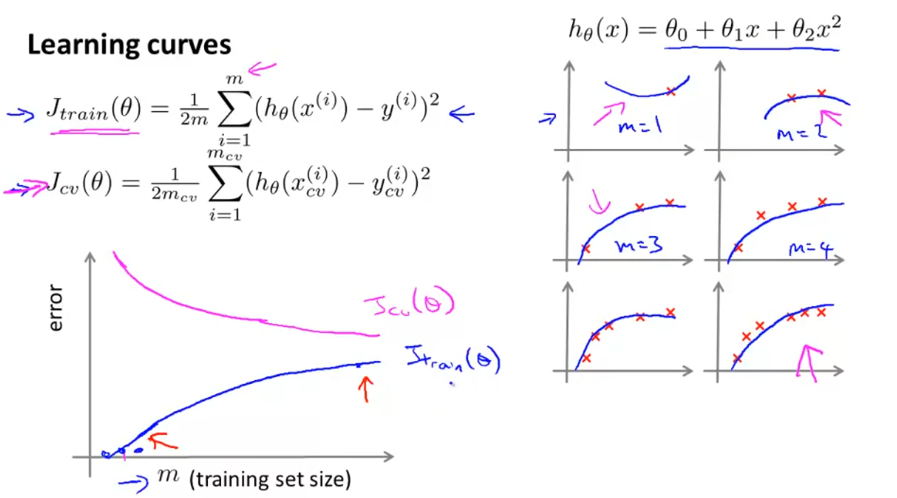
建议 Deciding What to Do Next Revisited
我们分别有以下这些选项,分别可以用于蓝字的用途。
Machine Learning System Design
6.3 Building a Spam Classifier
我们试图构造一个垃圾邮件过滤器,采用以下词向量方法将邮件文本内容转换为特征向量。
在构造这个一个系统时,我们往往要面对一个关键的问题:如何投入我们的时间?
误差分析 Error Analysis
如果你准备 研究机器学习的东西 或者构造机器学习应用程序 最好的实践方法 不是建立一个 非常复杂的系统 拥有多么复杂的变量 而是 构建一个简单的算法 这样你可以很快地实现它。
当我们有一个实现的系统后,我们可以对它表现出的误差例子进行观察分析,思考可能存在的问题。
并尽量设计数值计算的方式来评估你的机器学习算法。
大家经常干的事情是,花费大量的时间在构造算法上,构造他们以为的简单的方法。因此 不要过于纠结算法,而是尽快实现你的算法,通过观察初代模型的表现,再决定下一步的做法。因为我们可以先看看算法造成的错误,通过误差分析,看看具体什么错误,然后来决定优化的方式。
另一件事是,如果有了一个快速而不完美的算法实现,有一个数值的评估数据,这会帮助你尝试新的想法,快速地验证这些想法是否能够提高算法的表现,从而更快地做出决定,在算法中放弃什么、吸收什么。
6.4 处理偏斜类 Handling Skewed Classes
不恰当的衡量标准 Error Metrics for Skewed Classes
通常,我们用准确率或者召回率作为测试集的衡量标准。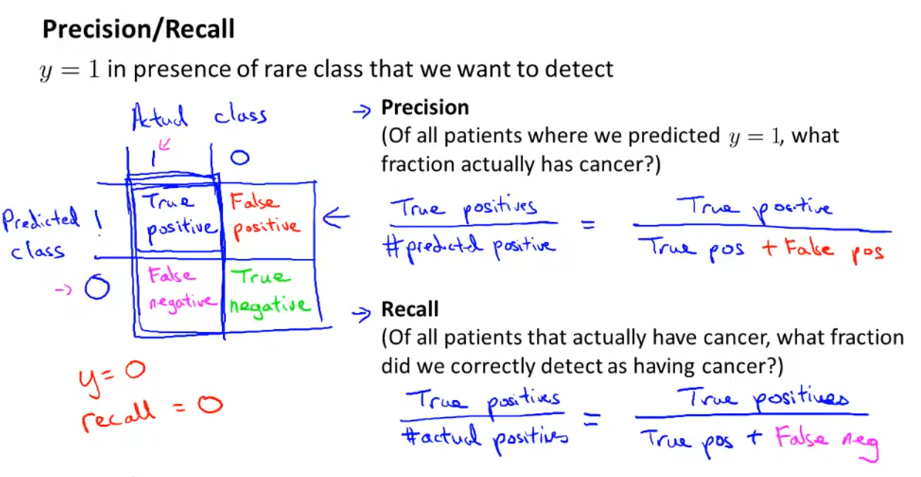
Skewed classes偏斜类让我们要仔细考虑衡量标准的选用。取一个极端的例子,再一个正负9比1的数据集中,全部猜正类就会有90%的正确率,听起来不错,但是模型什么也没做。
准确率和召回率的平衡 Trading Off Precision and Recall
为了弥补准确率和召回率的不足,提出了F score。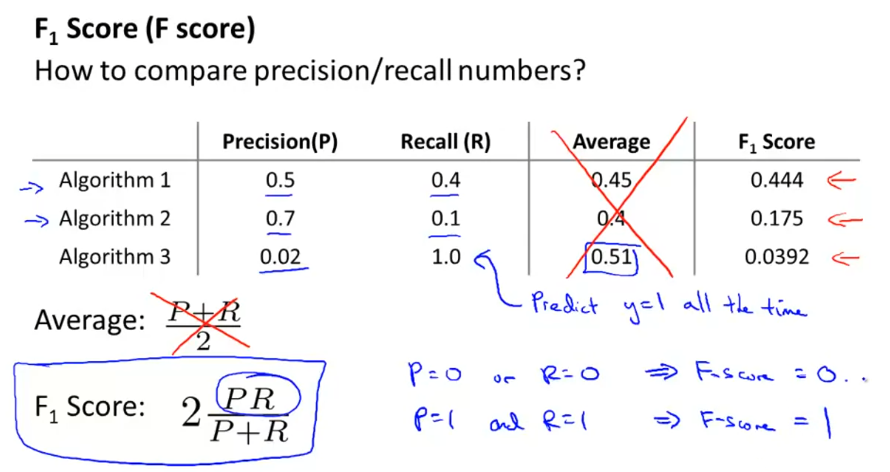
6.5 Using Large Data Sets
Data For Machine Learning
当你设计了一个很复杂拥有很多参数的模型,需要大量的数据才能避免过拟合的问题。

若有收获,就点个赞吧
0 人点赞
