非监督学习部分,介绍了聚类这一典型的非监督学习方法,K均值算法的优化目标、随机初始化和K值确定。
维度约简部分,介绍了它的两个好处数据压缩和可视化,然后介绍了最常用的一个主成分分析法技术。
Unsupervised Learning
8.1 聚类 Clustering
非监督学习介绍 Unsupervised Learning: Introduction
在监督学习中,训练集中的每个样本都有一个预期的输出。
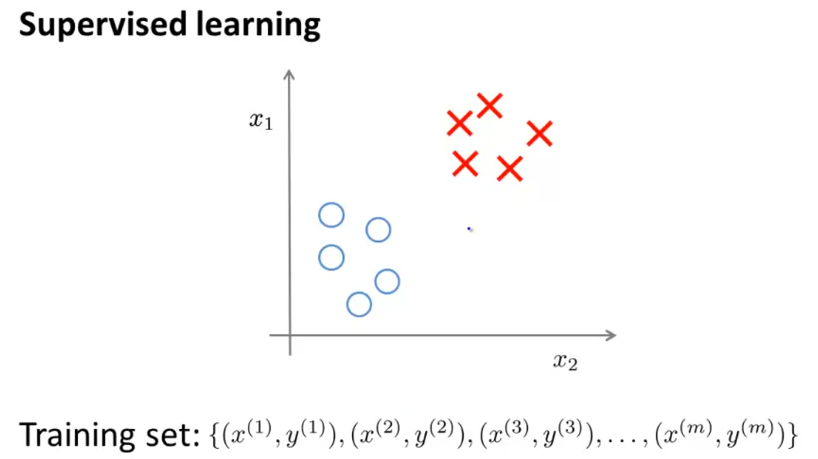
而在非监督学习的训练集中,每个样本只有特征描述,而没有特定的输出。需要程序自己在训练集中寻找潜在的规律。
K均值算法 K-Means Algorithm
在聚类问题中,对于未加标签的数据,我们希望有一个算法能够自动的把这些数据分成有紧密关系的子集或是簇。
K均值 (K-means) 算法就是现在最为广泛使用的聚类方法。
对于没有标签的数据集,首先随机两个簇中心,
然后按照离这两个点的距离打标签。
再根据各个类别数据集计算新的聚簇中心点,更新。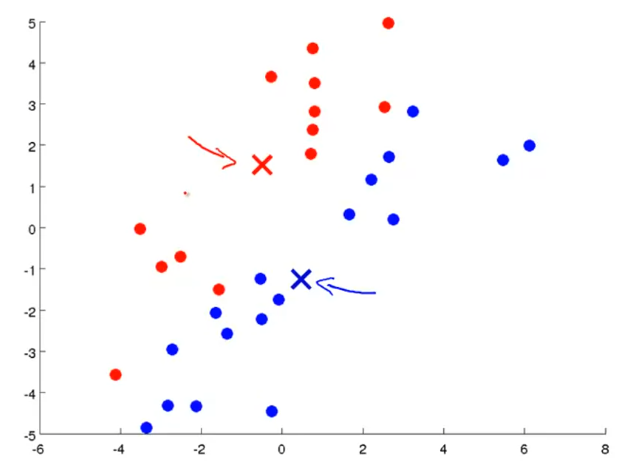
不断重复更新。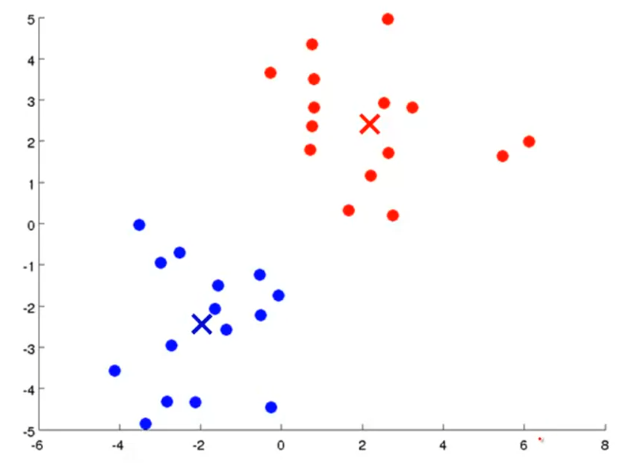
具体的K均值算法,如下所示。
优化目标 Optimization Objective
在大多数我们已经学到的监督学习算法中,类似于线性回归、逻辑回归以及更多的算法,都有一个优化目标函数或者需要通过算法进行最小化的某个代价函数。
那么,K均值也有一个需要最小化的代价函数。
随机初始化 Random Initialization
讨论一下如何初始化,这将引导我们如何避开局部最优。
随机初始化很简单,随机从样本点中选出k个作为中心点。
但是随机意味着运气不好的时候,会导致局部优解。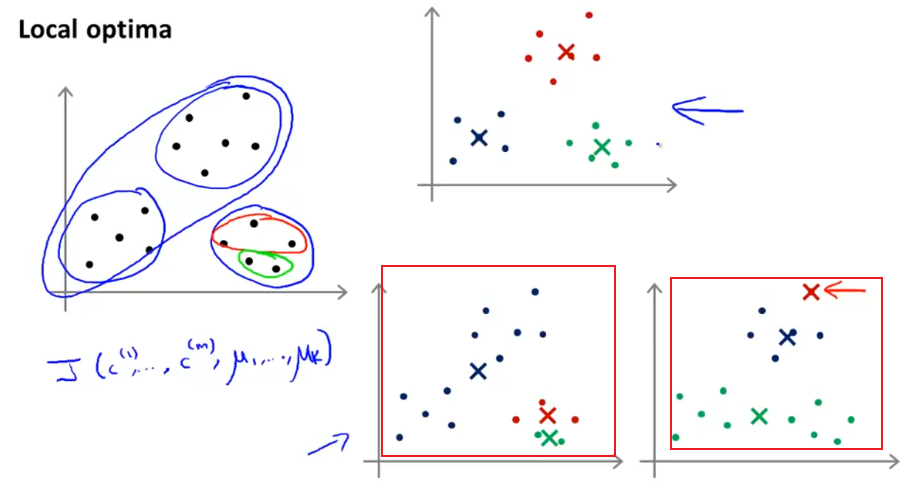
所以为了避免这种情况,我们需要做多次随机初始化,以免陷入局部最优。
K值选择 Choosing the Number of Clusters
讨论一下 K-均值聚类的最后一个细节,如何选择聚簇中心的数量。
事实上,如果要直接给出一个合适的数字,那么现在是没有什么很好的方法。
我们只有通过多次尝试不同的K值并进行优化,再绘制以下表格来确定。
通常通过肘部法则会选择中间凹下去的那个点。
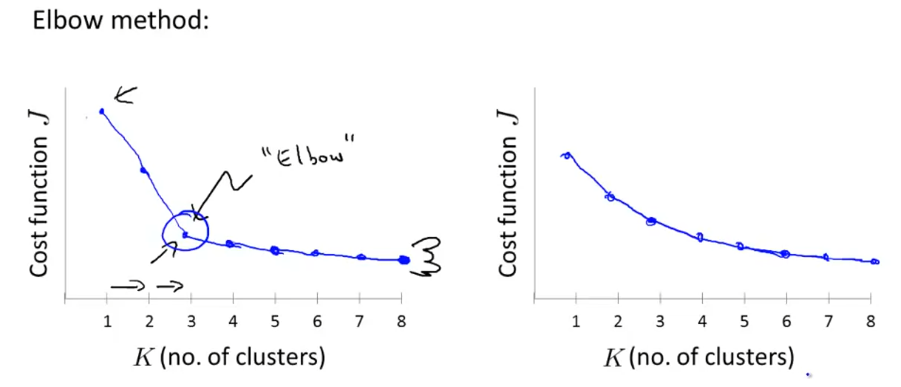
不过,在一些情况中,并没有最合适的K值之说。
维度约简 Dimensionality Reduction
8.2 Motivation
第二种无监督学习方法是维数约减 (dimensionality reduction)。
数据压缩 Motivation I: Data Compression
使用维数约简的原因之一,是数据压缩。它不经使得数据占用更少的计算机内存和硬盘空间,它还能给算法提速。

可视化 Motivation II: Visualization
第二种数据降维的应用,就是数据。
对于大多数的机器学习应用,数据可视化可以帮我们能更好地理解数据,从而开发更高效的学习算法。
面对如下的数据,我们可以有50个特征。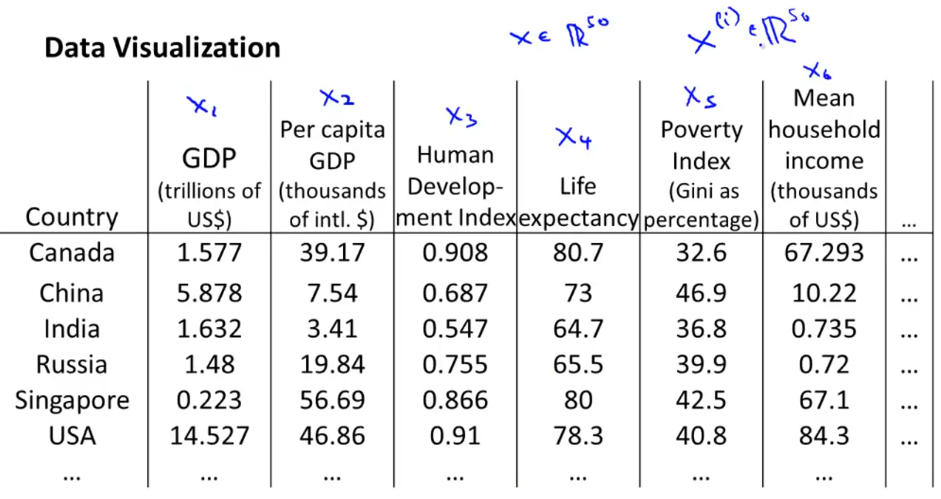
我们可以设计两个数来总结这些特征
从而更直观的展示数据
8.3 Principal Component Analysis 主成分分析法
PCA Problem Formulation
对于降维问题来说,目前最流行、最常用的算法是主成分分析法 (Principal Componet Analysis, PCA)。
首先介绍,PCA适合于哪些情景。
比如说把下面的样本点投影到中间红线的距离,进行2D到1D的转换。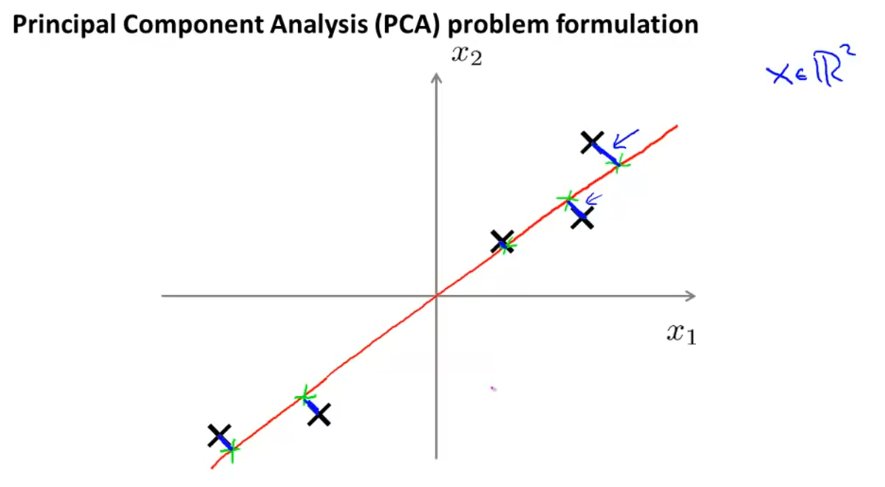
简单的说,PCA 寻找一个低维的层次。在这个例子中,是一条数据投射的直线,使得这些蓝色小线段的平方和达到最小。这些蓝色线段的长度,常被叫做投影误差。
所以 PCA 所做的就是寻找一个投影平面,对数据进行投影,使得距离能够最小化。
另外在应用PCA之前,需要先进行均值归一化和特征规范化,使得 特征均值为0,数值在可比较的范围之内。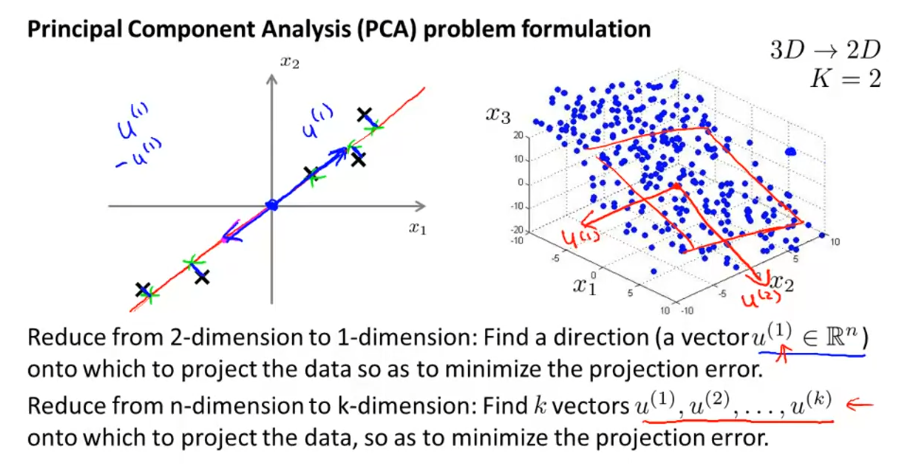
这里需要注意,PCA不是线性回归。线性回归是使Y值误差最小,PCA是使样本点到直线距离最小。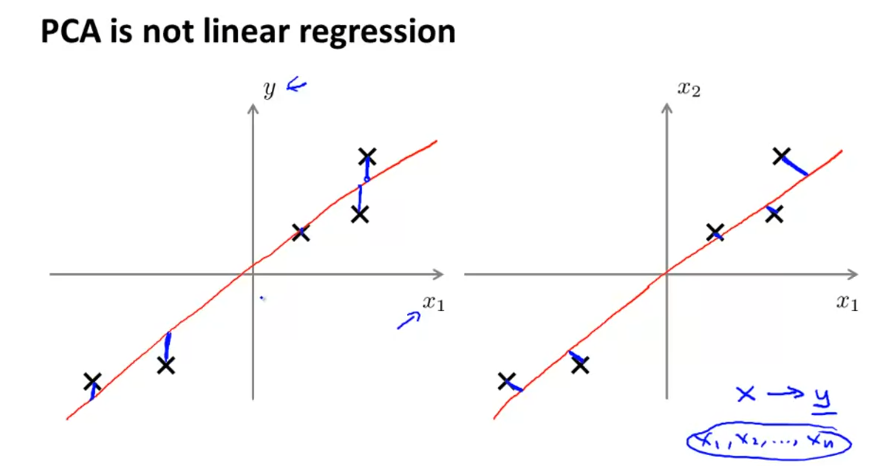
PCA Algorithm
待补充

若有收获,就点个赞吧
0 人点赞
