第一周有两个部分,分别是机器学习简介和单变量的线性回归。
机器学习简介部分,首先介绍了机器学习的定义,其次将其大致分为监督学习、非监督学习。
单变量线性回归部分,通过一个变量、两个参数构造最简单的模型假设函数,再引入代价方程的概念,这里使用的是均方误差方程;然后优化参数降低代价,引入梯度下降这一优化方法。
机器学习介绍 Introduction
1.1 介绍 Introduction
欢迎来到机器学习的世界,你可能已经了解、或者使用过许多机器学习的应用。
例如你熟悉的搜索出来的网页排序,垃圾邮件的识别,亦或者QQ、支付宝中提示你可能认识的人。
在这些熟悉的场景中,都有着机器学习的影子。
有同学可能已经听过深度学习,这里可以把他理解为机器学习发展的一个阶段、或者一个分支。
什么是机器学习 Machine Learning
如何让机器学习?
1950年,有人写了一个下跳棋的程序。要让电脑下棋其实很简单,只要不违法规则,怎么下都行。但是要让电脑下的和人一样好,就不容易了。这个人最终成功了,成功地被自己的跳棋程序打败了。他也许不是一个优秀的跳棋选手,但他通过思考,给出机器学习的最初定义:
- 赋予机器学习能力而无需明确怎么去学gives computers the ability to learn without explicitly learned
这个定义有点老了,所以“最近”有个新的定义。
一个计算机程序可以从一些任务T的经验E学习而提升任务性能P。A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E.
对于跳棋玩例子,体验 E 将是 让程序玩成千上万的游戏本身的经验。 任务 T 将 是玩跳棋的任务,性能测量 P 将 赢得下一场比赛的跳棋对阵一些新的对手的概率。
监督学习 Supervised Learning
机器学习可以大概分为监督学习和非监督学习。
监督学习,举两个例子:
一个是波士顿房价预测。给定房子的面积和它们的价格的数据集,通过学习后,试图预测新房的价格。
另一个例子是乳房肿瘤的预测。给定病理情况以及它们的诊断结果,通过学习后,试图预测病人是否患有乳房肿瘤。
上面两个例子中,给出参考的条件数值,在机器学习中称为特征Feature。可以类比为函数中的自变量x。
这组特征对应的真实结果,称为真值Ground Truth。
对于一组特征和其所对应的真值,称为一组样本sample。
前者的结果是连续的,可以将特征看作自变量x,将实际房价看作因变量y,可以将其拟合成为一个线性函数,当遇到一个新房子,我们只需要输入特定的特征值即可预测出它的价格。
我们称这种结果连续的问题为回归问题Regression。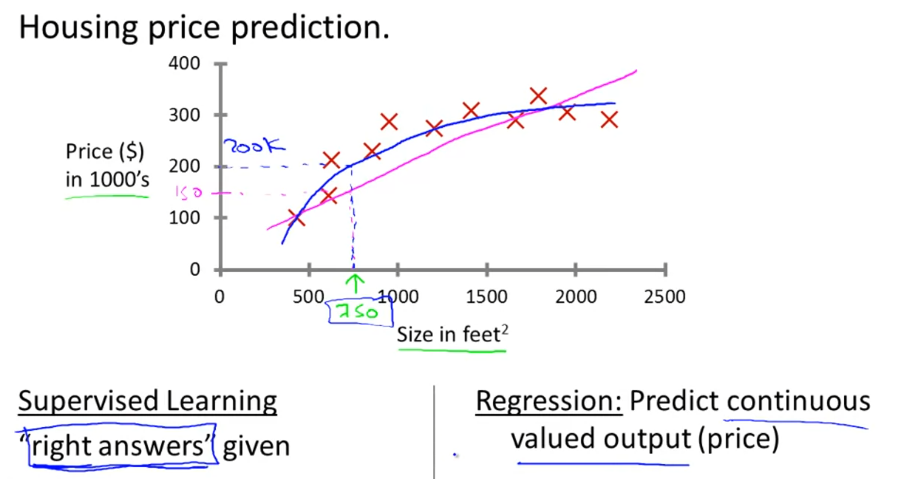
后者的结果是离散的,例如诊断肿瘤时是为1,否则为0,我们统称这类结果离散的问题为分类问题Classification 。同时对于只有是和否的分类问题,也称为二分类问题,结果为1的样本称正样本,结果为0的称为负样本。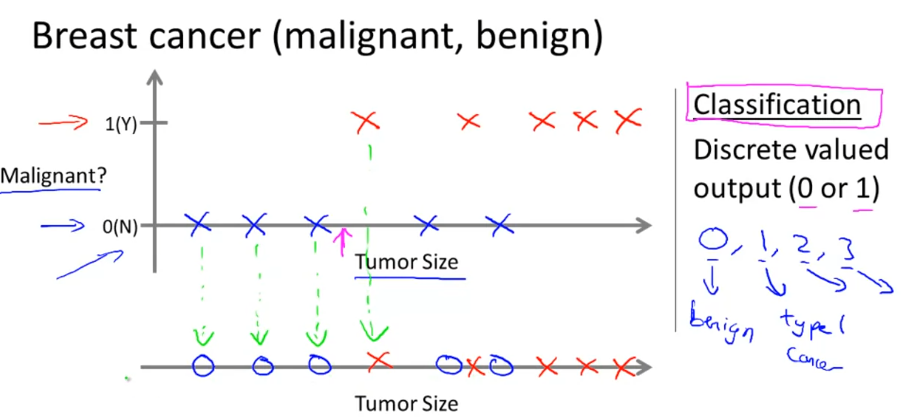
对于回归问题,可以通过拟合函数,输入变量数值直接计算出预测的数值结果(房价);那么对于分类问题,如何通过输入变量的数值得出离散值呢?
针对肿瘤诊断的问题,假定输入特征为年龄age和肿瘤大小tumor size,通过位置信息绘图(下图左)如下,其中红叉叉代表是乳房肿瘤,蓝圈圈表示不是。
可以通过拟合一条线(上图右黑线)将俩个区域分开,计算特征点到这条线的距离正负,再映射为0-1的离散值。
无监督学习 Unsupervised Learning
监督学习中的每个样本都给出了真值,但是对于非监督学习来说,我们只有一个没有结果的数据集。非监督学习的任务就是从这个没有标注结果的数据集中,寻找出某种有用的结构。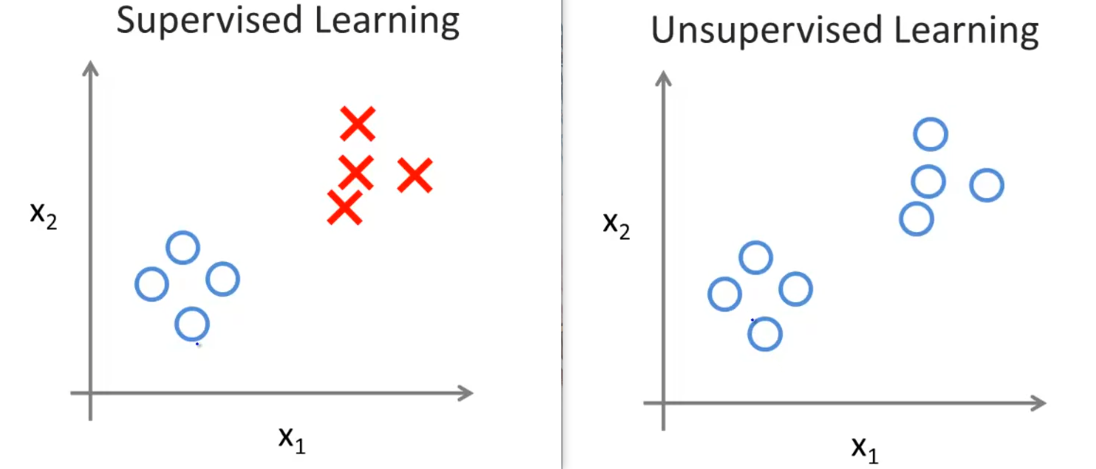
对于上图右中的非监督学习样本集,我们可以发现可以将它们根据位置信息分为两团。
将特征坐标相近的点聚成一类,也就是非监督学习中常用的聚类Clustering算法。
接下来举几个例子。
每天互联网上都会新增许多的新闻报告,门户网站会自动帮你把相近内容的新闻归成一类。
在基因科学方面,可以通过将具有特定基因的人分为各个类别。
在工业方面,一方面大型数据中心可以通过数据流向的交互特定,判断哪些计算机是属于一个集群。
社交应用方面,可以分析社交网络各给你推荐可能认识的人。
商业市场中,可以通过对客户数据进行分析,将市场进一步分割。
单变量线性回归 Linear Regression with One Variable
1.2 模型和代价方程 Model and Cost Function
模型表示 Model Representation
这一节我们将学习线性回归算法,只采用一个变量。
回忆一下之前对回归问题的描述,我们需要一个函数对新样本进行预测,这个函数就称为假设Hypothesis。通常表示为 。
。
然后 代表第
代表第 个输入,
个输入, 代表第
代表第 个输出,一对输入输出称作训练样本training example。
个输出,一对输入输出称作训练样本training example。 的取值范围是
的取值范围是 ,其中
,其中 代表样本的个数。
代表样本的个数。
我们采用房价预测的例子,特征x为房价面积,y为价格。
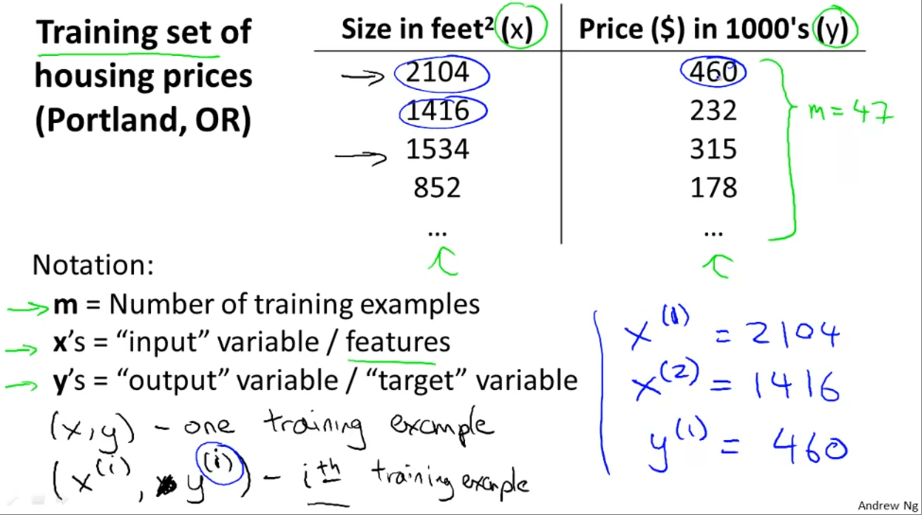
那么我们可以大胆假设 ,这就是我们最简单的模型,接下来的问题就是如何取到最佳的参数值。
,这就是我们最简单的模型,接下来的问题就是如何取到最佳的参数值。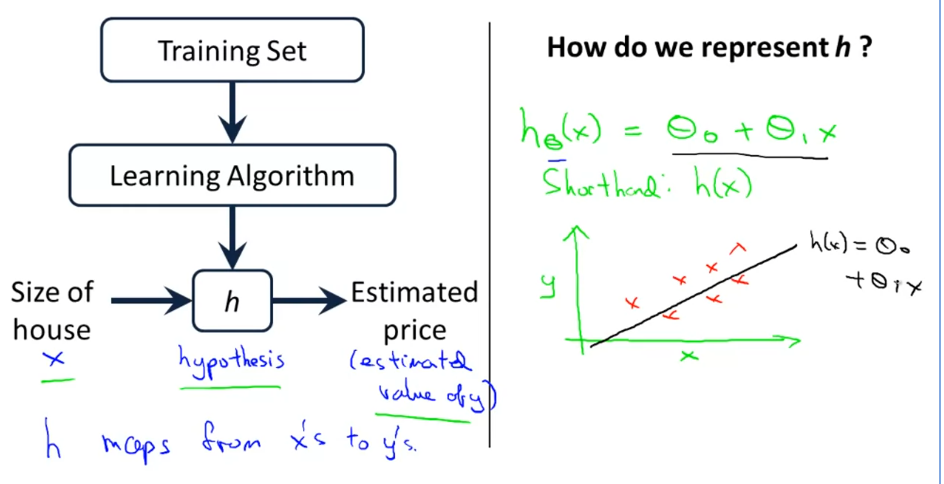
代价方程 Cost Function
代价方程代表了当前模型的不满意程度,值越大说明目前的模型越不满意。
上图左,根据我们的假设h,针对需要优化的目标参数thetas,提出以theta为参数代价方程 ,目标是最小化整个数据集的代价值。
,目标是最小化整个数据集的代价值。
这里的代价方程设计的是每个样本预测值和真值之间的平方差均值,再除二,除二是为了求导方便。
下图右,为了方便演示逐个样本逐步计算总代价的过程,简化到了一个theta。
吴恩达视频中演示了三个样本的情况下,theta取0.5,1,0的代价计算过程,我就不整理了。


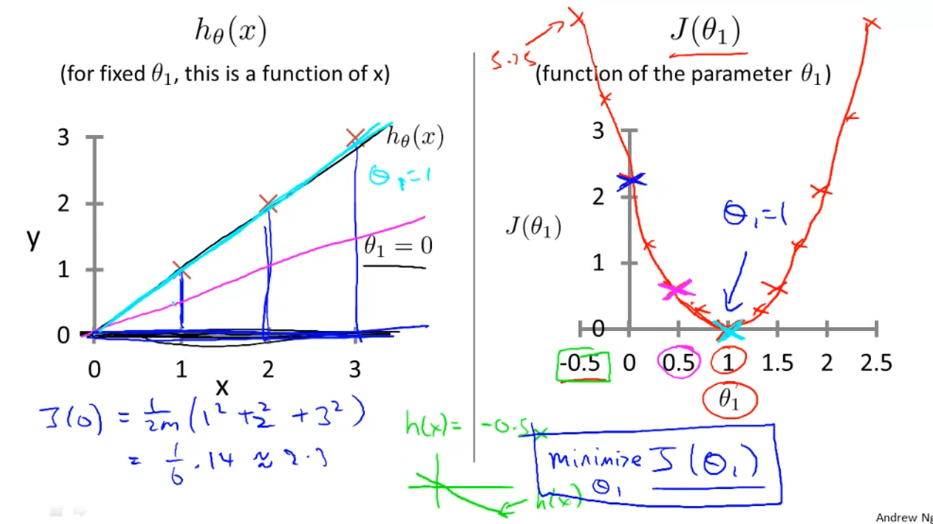
所以我们可以看出,当theta取1时,模型在这个数据集上的代价最小。
以上代价方程只有一个theta的基础,得到一条2D平面曲线;
如果有两个theta的话,那么两个theta的值组合对应的代价值将构成一个曲面,如下所示。
好了,你需要知道
- 代价方程反应了当前模型对当前数据集的拟合匹配程度(此时用来优化模型的数据集也叫做训练集)
- 代价方程以模型参数theta为自变量,假设方程以特征x为自变量
- 代价方程的意义在于不断寻找合适的theta参数,是它在训练集上的代价值降低
那么问题来了,上述过程中,我们只是人工在试参数组合,有没有一种更好的方法,让我们快速找到合适的模型参数,使训练集上的总体代价降低呢?
1.3 参数学习 Parameter Learning
梯度下降 Gradient Descent
梯度下降是快速使代价方程最小化的一个算法。
梯度下降是一个形象的名称,想象在水泥坡上放下一颗玻璃珠,玻璃珠会沿着坡度最大角度的滚下去。
现在我们的模型处于随机的一组参数中,这组参数代表模型在水泥坡地上的位置,通过参数计算的代价代表了模型所在的高度。
在一元二次方程中,梯度或者坡度可以理解为函数的导数值,所以可以通过代价方程对参数求导,获得梯度的方向。
接下来我们的模型只需要不断计算梯度,并朝着梯度方向小小的迈一步就好了。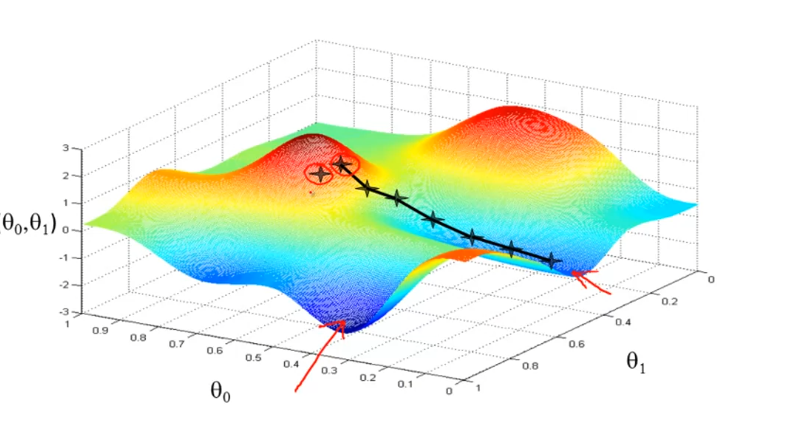
这个迈出的步长,就称之为学习速率Learning Rate,常记为 。
。
在代码上体现为
梯度下降用于线性回归Gradient Descent For Linear Regression
本节逐步演算,通过梯度下降使线性回归模型达到理想。

这里的模型是一元二次函数,所以拥有两个参数theta,所以以代价方程就有两个变量,需要分别求偏导,并乘学习速率后更新参数值。

将一元一次线性模型代价方程对参数求导之后的式子代入梯度下降的算法,如上所示。
根据每次梯度下降算法使用的训练集比例,我们也可以将上面的梯度下降算法称为批梯度下降算法Batch Gradient Descent。

若有收获,就点个赞吧
0 人点赞
