写了 300000 行基础设施代码,我学到了这五条经验
Saturday, December 8, 2018
9:54 AM
|
| | —- |
| Tags: #微信 |
写了 300000 行基础设施代码,我学到了这五条经验
Yevgeniy Brikman CSDN

本文为作者 Yevgeniy Brikman 分享了他在 Gruntwork 工作时创建并维护一个超过 30 万行基础设施代码的库(https://gruntwork.io/infrastructure-as-code-library/)时学到的五条经验。
- 《Lessons learned from writing over 300,000 lines of infrastructure code》PPT 下载地址:https://www.slideshare.net/brikis98/lessons-learned-from-writing-over-300000-lines-of-infrastructure-code-120597849

DevOps 仍在石器时代**
尽管业界充斥着大量尖端的词汇——Kubernetes、微服务、服务网格、不可改变的架构、大数据、数据湖等等,但现实是,在真正构建基础设施时,你完全感觉不到任何现代化。
在我看来,DevOps 就像是这样:




建立生产级别的基础设施很难、压力很大、而且很花时间。非常耗时间。
下面是我对于基础设施项目的时间估计,来自几百家与我们合作过的公司的经验数据: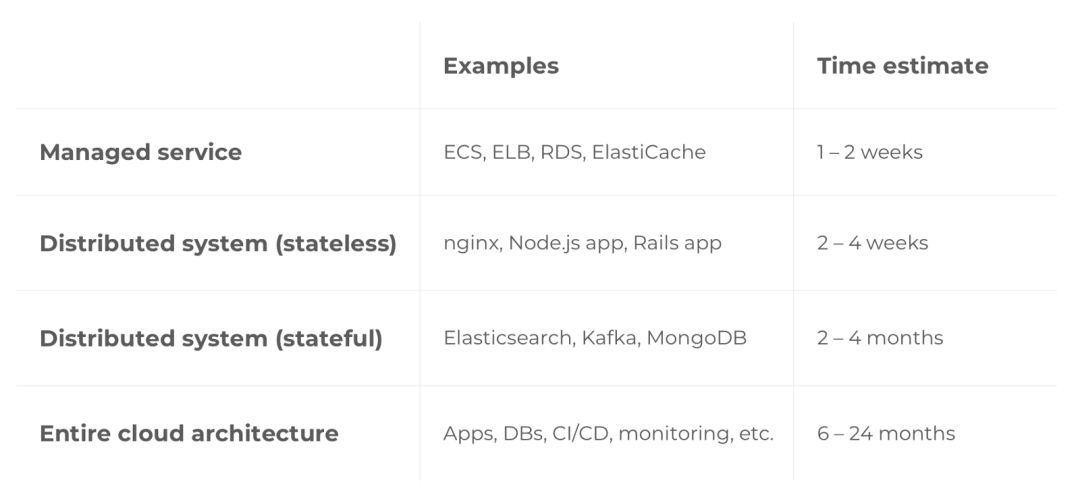

第一条:生产级基础设施的检查列表
DevOps 项目永远比你预想的时间长。为什么呢?
第一个原因就是:剪牛鬃。(https://seths.blog/2005/03/dont_shave_that/。简单来说,“剪牛鬃”指的是完成一项任务所需的一系列动作中的最后一步,比如:今天我需要给车打蜡,但洗车的水龙头坏了,得去五金店买个新的,但五金店在桥对面,但我没有通行证又不想交过桥费……不过我可以借邻居的通行证,但我儿子借了他的靠垫,要不先还给他靠垫他是不会借给我通行证的……但靠垫上的一个小东西掉了,我需要一些牛鬃毛才能修好……于是第二天你就去剪牛鬃了,这样你才能去给车打蜡。)下面这张来自美剧《马尔科姆的一家》的动图很好地说明了这一点:
第二个原因就是,打造生产级基础设施(即你的公司可以依赖的基础设施)涉及大量的小细节。绝大多数开发者都不知道这些细节,所以在估算项目时,你通常会漏掉很多重要且耗时间的细节问题。
为了避免这个问题,每次在构建新的基础设施时,应当使用下面的检查列表: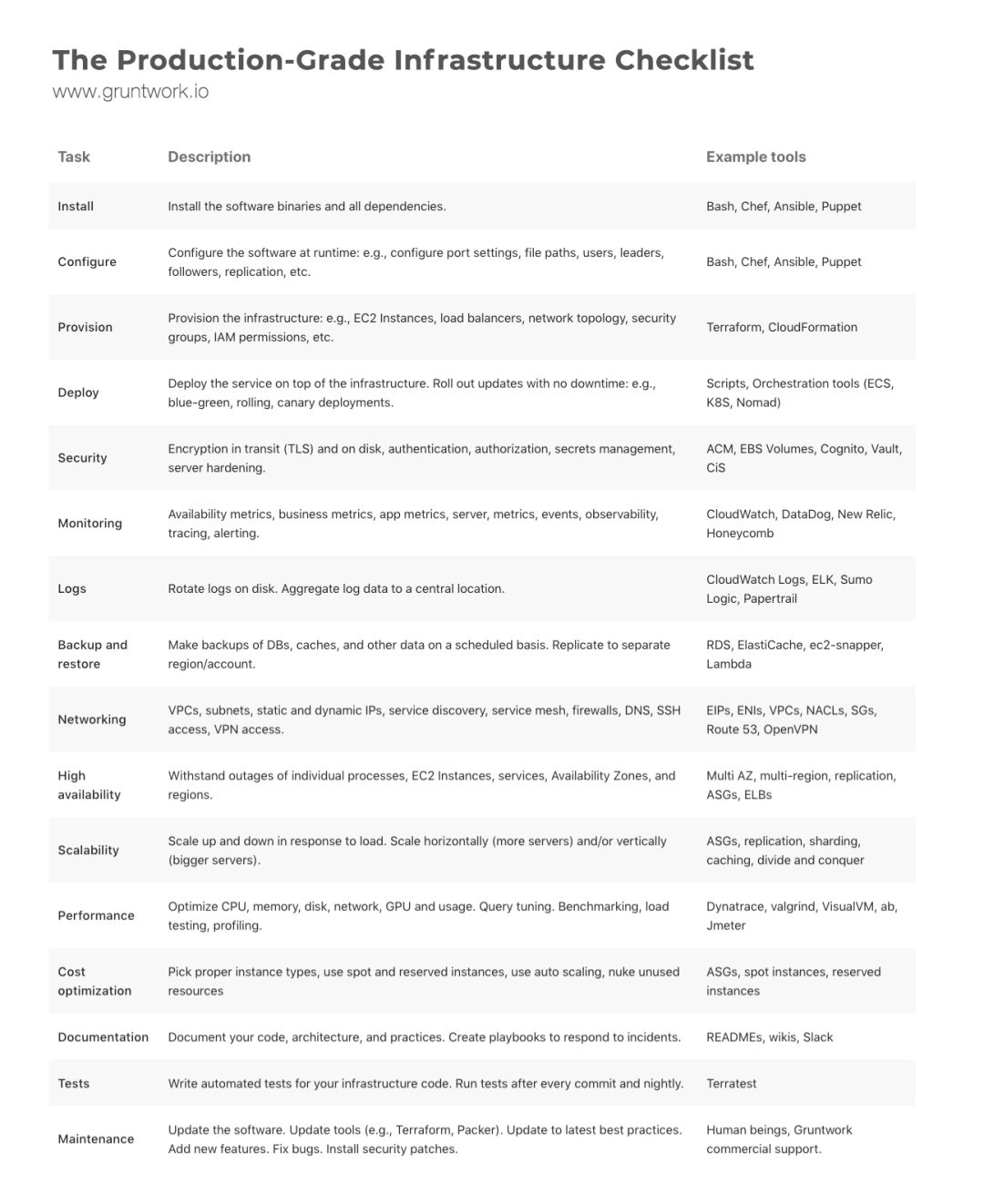
并不是每个基础设施都需要列表中的每一项,但应当认真检查每一项,找出哪些你应当实现,哪些应当忽略,以及原因。
第二条:工具集**
2018 年我们在 Gruntwork 用来构建和管理基础设施的主要工具有: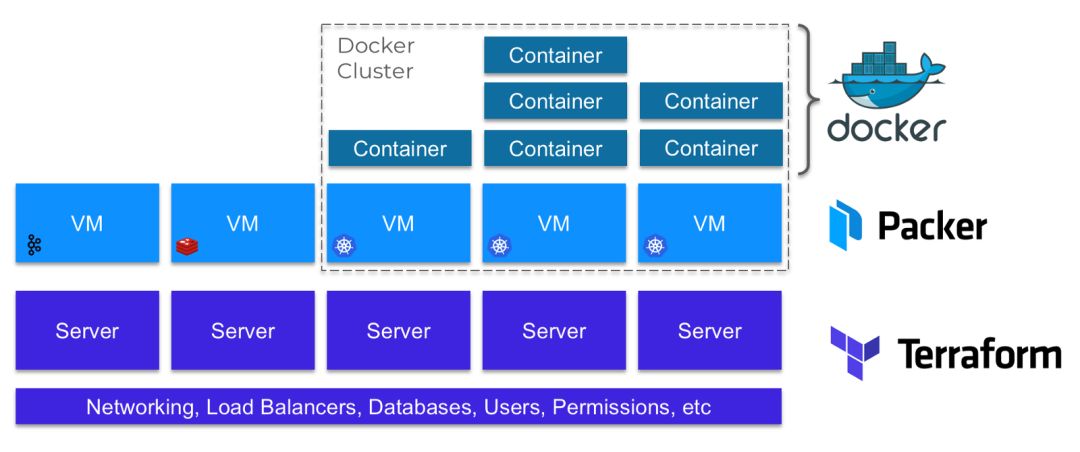
- Terraform:我们使用 Terraform 来管理所有基本的基础设施,包括网络、负载均衡器、用户、权限和所有服务器。
- Packer:我们使用Packer来定义并构建服务器上运行的虚拟机的映像。
- Docker:我们的一些服务器组成集群,在集群上我们通过Docker容器运行应用程序。我们使用的主要Docker集群工具是Kubernetes、ECS和Fargate。
所有这些工具都很有用,但这并不是重点。真正的重点是,仅有工具本身是不够的。你还需要改变团队的行为模式。
具体来说,如果你的团队不习惯使用那些工具,或者没有足够的时间学习那些工具,那么即使世界上最好的工具也无法为你的团队提供一丝一毫帮助。因此,主要的经验是:以代码的方式使用基础设施(infrastructure as code)是一项重要的投入。一定的前期投入是不可避免的,只有这样才能让它运转起来,但如果正确地投入了时间和精力,长期来看你会获得巨大的收益。
第三条:大型模块是有害的
以代码方式使用基础设施(infrstructure as code)的新手们经常会把所有基础设施的所有环境(dev、stage、prod等)都放在一个文件中,或者放在一组文件中但作为一个单元来部署。这是个很糟糕的习惯。
下面是几条缺陷:
- 速度慢。如果所有基础设施都在一个地方定义,那么运行任何命令都会花很长时间。我们遇到过许多公司中,terraform plan 需要花五六分钟时间!
- 不安全。如果所有基础设施都在同一个地方管理,那么做任何修改都需要拥有访问一切的权限。也就是说,每个用户都必须是管理员,这同样是个非常糟糕的想法。
- 高风险。把所有鸡蛋放在一个篮子里,那么任何地方出错都会破坏一切。可能你只想对dev里的前端app做一点微小改动,但一个输入错误或运行错误的命令,就可能会删掉生产数据库。、
- 难理解。同一个地方的代码越多,别人就越难看懂。如果所有代码都在同一个地方,那么你无法理解的部分早晚会坑你。
- 难测试。基础设施的代码很难测试,大量基础设施的代码几乎不可能测试。我们稍后会讨论着一点。
- 难审查。一些命令(如terraform plan)的输出结果变得毫无意义,因为根本没人会查看几千条plan的输出。而且,进一步会让代码审查变得毫无意义:

简单来说,你应当将代码写成小型、独立、可重用、可组合的模块。这也不是什么新观点或有争议的观点了。你肯定已经听过上千次了,只不过是在不同的领域:
“只做一件事并把它做好。”——Unix 的哲学
“函数的第一条规则就是它们应当很小。第二条规则就是它们应该比第一条更小。”——《代码整洁之道》
第四条:没有自动化测试的基础设施无法使用
如果你的基础设施代码没有自动化测试,那就没办法使用。只不过你还没意识到罢了。虽然这么说,但测试基础设施代码非常困难。你没有真正的“localhost”可以使用(例如,你不能把 AWS 上的 VPC 部署到自己的笔记本电脑上),也没有真正的“单元测试”(例如,你没办法把 Terraform 的代码与“外界”隔离开来,因为 Terraform 的功能就是要与外部交流)。
因此,要想恰当地测试你的基础设施代码,通常都要将其部署到一个真实的环境,运行真实的基础设施,验证它能实现你想要的功能,最后全部拆毁(这种风格的测试可以参见 Terratest(https://blog.gruntwork.io/open-sourcing-terratest-a-swiss-army-knife-for-testing-infrastructure-code-5d883336fcd5),这是个开源库,包含了一些用来测试 Terraform、Packer 和 Docker 代码的工具,支持 AWS、GCP 和 Kubernetes API,可以在本地执行命令,也可以通过 SSH 在远程服务器上执行命令,还有去多其他功能)。这意味着,在基础设施测试中,一些术语的定义需要稍作修改: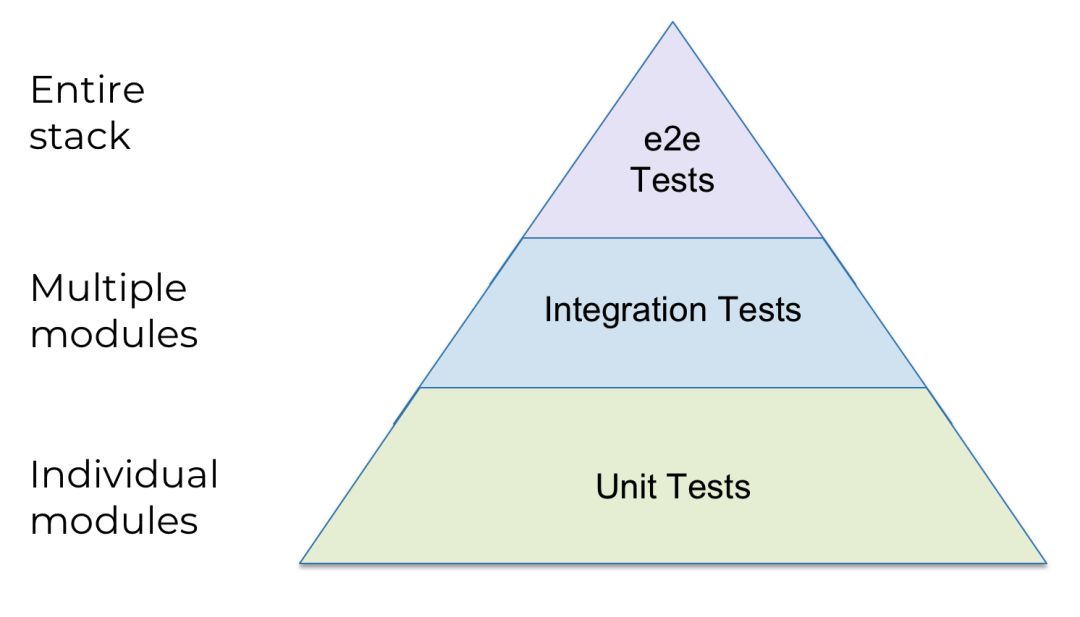
- 单元测试:部署并测试一种类型的基础设施中的一个或几个紧密相关的模块(例如,测试一个数据库中的模块)。
- 集成测试:部署并测试来自不同类型的基础设施中的多个模块,验证它们能正确地合作(例如,测试某个数据库的模块和某个Web服务的模块)。
- 端到端(e2e)测试:部署并测试整个架构。
注意图示是个金字塔,也就是说,里面有很多单元测试,几个集成测试,和非常少的 e2e 测试。为什么?因为每种测试的执行时间如下: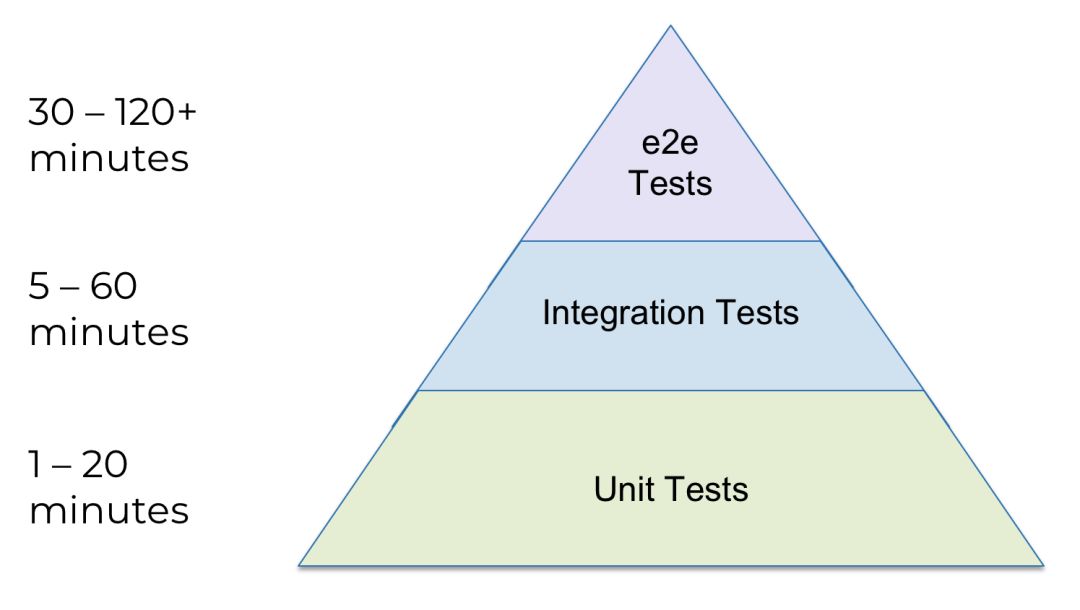
基础设施的测试非常慢,特别是在进入金字塔顶端之后,所以应当尽可能多地在金字塔底层抓出 Bug。也就是说:
- 构建小型、简单、独立的模块(还记得第三条吗?)并为之编写许多单元测试,确保它们能正确工作。
- 将小型、简单、测试过的模块组合成更复杂的基础设施,并通过几个集成测试和 e2e 测试进行测试。

第五条:发布过程
现在我们总结一下。从今以后,构建和管理基础设施的过程应当如下:
- 仔细阅读“生产级基础设施检查列表”确保构建的方向正确。
- 使用工具实现通过代码方式使用基础设施,如 Terraform、Packer、Docker 等。确保团队有足够的时间掌握这些工具(参见“DevOps资源”(https://gruntwork.io/devops-resources/))。
- 写代码时要写成小型、独立、可组合的模块(或使用 Infrastructure as Code Library(https://gruntwork.io/infrastructure-as-code-library/)中提供的现成的模块)。
- 使用 Terratest 为模块编写自动化测试。
- 提交拉取请求,让别人审查代码。
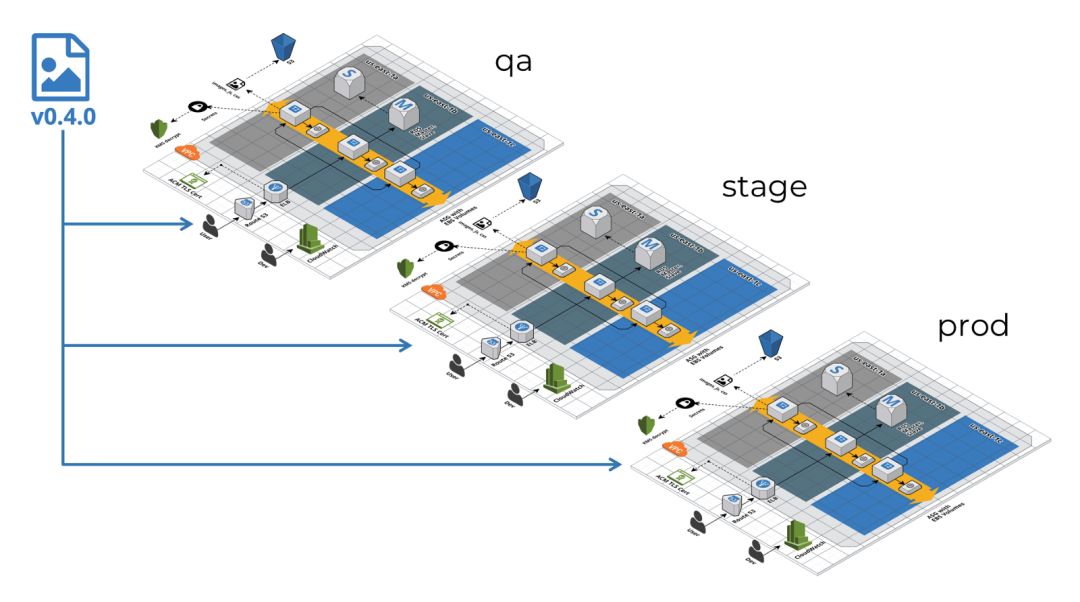
- 发布代码的新版本。
- 将新版本的代码从一个环境提升到下一个环境。
链接:https://blog.gruntwork.io/5-lessons-learned-from-writing-over-300-000-lines-of-infrastructure-code-36ba7fadeac1
作者:Yevgeniy Brikman,Gruntwork联合创始人,著有《Hello, Startup》和《Terraform: Up & Running》。
译者:弯月,责编:屠敏
【完】

若有收获,就点个赞吧
0 人点赞
