一条SQL查询语句如何执行?
MySQL是典型的C/S架构(客户端/服务器架构),以Mysql为例,解读一下一条sql查询语句的执行过程。
客户端进程向服务端进程发送一段文本(MySQL指令),服务器进程进行语句处理然后返回执行结果。如下图所示,服务器进程在处理客户端请求的时候,大致需要进行3个步骤:
- 处理连接
- 解析与优化
- 存储引擎
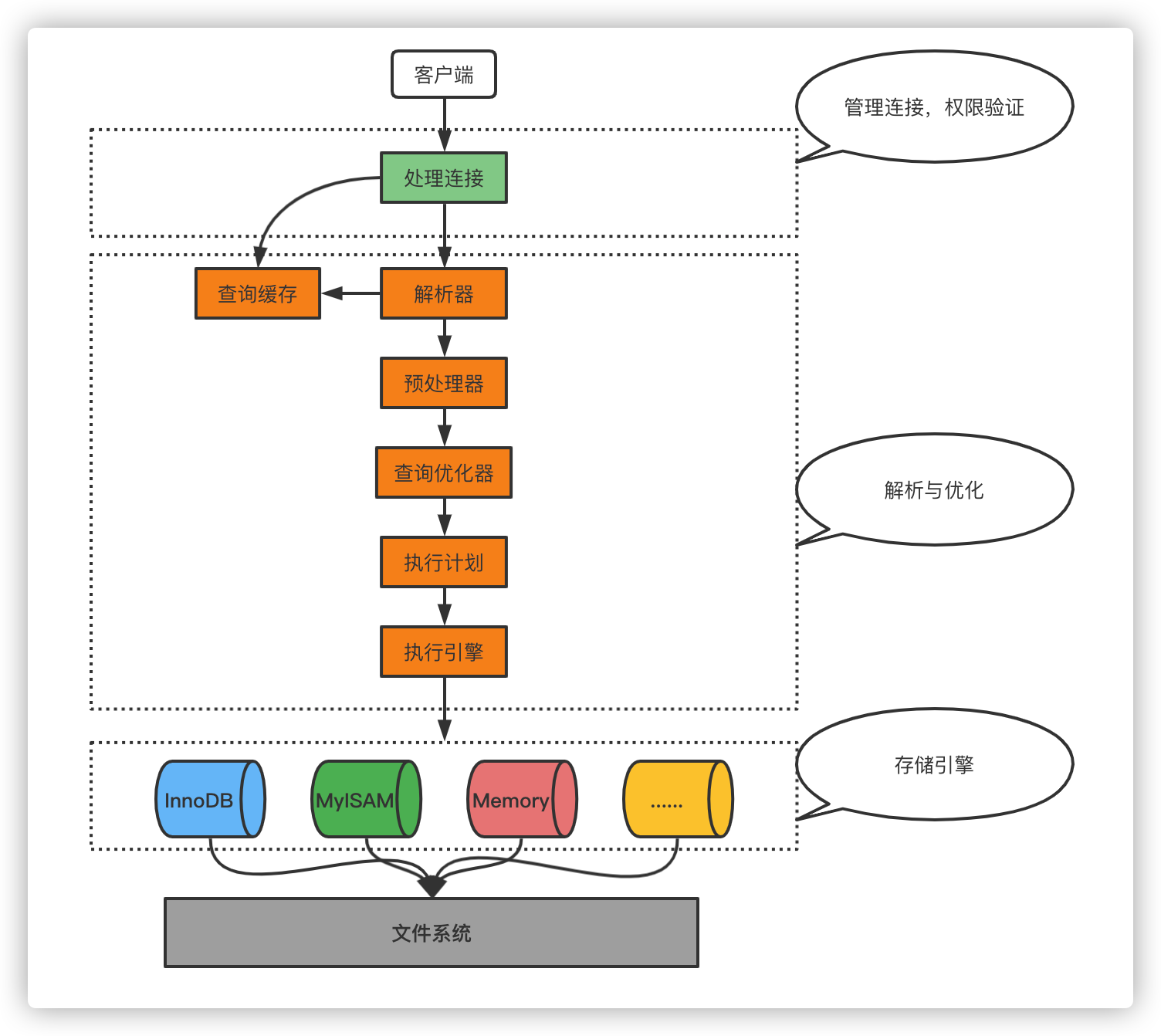
1.处理连接
客户端向服务器发送请求并最终收到响应,本质上是一个进程间通信的过程。
2. 解析与优化
服务器收到客户端传来的请求之后,还需要经过查询缓存、词法语法解析和预处理、查询优化的处理。
2.1 查询缓存
如果我们两次都执行同一条查询指令,第二次的响应时间会不会比第一次的响应时间短一些?
使用过Redis缓存工具应该会有这个很自然的想法,MySQL收到查询请求之后应该先到缓存中查看一下,看一下之前是不是执行过这条指令。如果缓存命中,则直接返回结果;否则重新进行查询,然后加入缓存。
2.2 解析器 & 预处理器(Parser & Preprocessor)
现在跳过缓存这一步了,接下来需要做什么了?
如果我随便在客户端终端里输入一个字符串chanmufeng,服务器返回了一个1064的错误
服务器是怎么判断出我的输入是错误的呢?这就是MySQL的Parser解析器的作用了,它主要包含两步,分别是词法解析和语法分析。
2.2.1 词法解析
分析器先会做“词法分析”,就是把一条完整的SQL语句打碎成一个个单词,比如一条简单的SQL语句,会打碎成8个符号,每个符号是什么类型,从哪里开始到哪里结束。
2.2.2 语法分析
2.2.3 预处理器
本质上,解析和预处理是一个编译过程,涉及到词法解析、语法和语义分析。
2.3 查询优化器(Optimizer)与查询执行计划
3.存储引擎
经历千辛万苦,MySQL终于算出了最终的执行计划,然后就可以直接执行了吗?
依然还不可以。知道计划还需要通过存储引擎找到实际的存储位置,再进行处理。
3.1 什么是存储引擎
到底该把数据存储在什么位置,是内存还是磁盘?怎么从表里读取数据,以及怎么把数据写入具体的表中,这都是存储引擎 负责的事情。
3.2 为什么需要存储引擎
因为存储的需求不同。
试想一下:
- 如果一张表,需要很高的访问速度,而不需要考虑持久化的问题,是不是最好把数据放在内存呢?
- 如果一张表,是用来做历史数据存档的,不需要修改,也不需要索引,那是不是要支持数据的压缩?
- 如果一张表用在读写并发很多的业务中,是不是要支持读写互不干扰,而且要保证比较高的数据一致性呢?
大家应该明白了,为什么要支持这么多的存储引擎,因为一种存储引擎不能提供所有的特性。
存储引擎是计算机抽象的典型代表,它的功能就是接受上层指令,然后对表中数据进行读取和写入,而这些操作对上层完全是屏蔽的。你甚至可以查阅MySQL文档定义自己的存储引擎,只要对外实现同样的接口就可以了。
存储引擎就是MySQL对数据进行读写的插件而已,可以根据不同目的随意更换(插拔)
3.3 如何选择存储引擎
- 如果对数据一致性要求比较高,需要事务支持,可以选择InnoDB。
- 如果数据查询多更新少,对查询性能要求比较高,可以选择MyISAM。
- 如果需要一个用于查询的临时表,可以选择Memory。
附参考资料:

若有收获,就点个赞吧
0 人点赞
