环境:Centos7 版本:zookeeper-3.4.10.tar.gz 软件安装 配置 集群部署 验证
Zookeeper集群安装在hadoop001、hadoop002、hadoop003
软件安装
zookeeper-3.4.10.tar.gz ,解压安装
tar -zxvf zookeeper-3.4.10.tar.gz -C /root/ 解压到/root/目录vm zookeeper-3.4.10 zookeeper #重命名
配置
工作文件夹
创建 zkData文件夹用于保存zookeeper相关数据
mkdir /root/zookeeper/zkData
zoo.cfg
cp /root/zookeeper/conf/zoo_sample.cfg /root/zookeeper/conf/zoo.cfg#修改文件内容tickTime=2000initLimit=10syncLimit=5dataDir=/root/zookeeper/zkData/dataLogDir=/usr/local/zookeeper-cluster/log/clientPort=2181#增加内容# server.1 这个1是服务器的标识,可以是任意有效数字,#标识这是第几个服务器节点,这个标识要写到dataDir目录下面myid文件里# 指名集群间通讯端口和选举端口server.1=hadoop001:2888:3888server.2=hadoop002:2888:3888server.3=hadoop003:2888:3888
server .A=B:C:D
A:数字,表示第几台服务器
B:IP地址
C:这台服务器与集群中的leader服务器交换信息的端口
D:表示当集群中leader服务器无法正常运行时,需要一个端口来重新进行选举,选出一个新的leader服务器,这个端口就是用来执行选举时服务器相互通信的端口。
集群模式下配置工作目录下一个文件myid,其中数据就是A的值,Zookeeper启动时读取此文件,并将里面的数据与zoo.cfg文件配置信息进行比较,从而判断到底是哪台服务器。
myid
touch /root/zookeeper/zkData/myidvi /root/zookeeper/zkData/myid1 #zoo.cfg中A的值
集群部署
scp -r /root/zookeeper/ hadoop002:/root/scp -r /root/zookeeper/ hadoop003:/root/
启动
/root/zookeeper/bin/zkServer.sh start
验证
/root/zookeeper/bin/zkServer.sh status
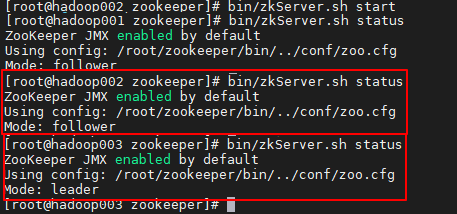
集群启动、停止脚本
通过执行ssh命令,分别登录集群节点服务器,然后执行启动、停止或查看服务状态的命令。
vi zk.shcase $1 in"start"){for i in hadoop001 hadoop002 hadoop003dossh $i "source /etc/profile; /root/zookeeper/bin/zkServer.sh start"done};;"stop"){for i in hadoop001 hadoop002 hadoop003dossh $i "source /etc/profile; /root/zookeeper/bin/zkServer.sh stop"done};;"status"){for i in hadoop001 hadoop002 hadoop003dossh $i "source /etc/profile; /root/zookeeper/bin/zkServer.sh status"done};;esac

若有收获,就点个赞吧
0 人点赞
