Flume简介
Flume 是一种分布式、可靠且可用的服务,用于高效收集、聚合和移动大量日志数据。它具有基于流数据流的简单而灵活的体系结构。它具有强大的容错能力,具有可调的可靠性机制以及许多故障转移和恢复机制。它使用一个简单的可扩展数据模型,允许在线分析应用程序。
Flume 分为 NG 和 OG (1.0 之前) 两个版本,NG 在 OG 的基础上进行了完全的重构,是目前使用最为广泛的版本。下面的介绍均以 NG 为基础。
Flume架构
架构示意图:
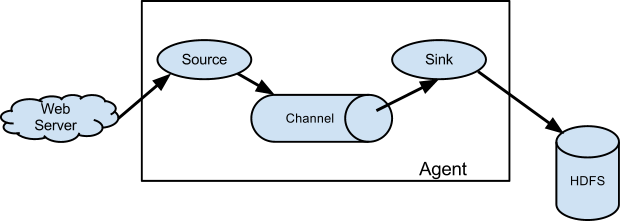
基本架构
外部数据源以特定格式向 Flume 发送 events (事件),当 source 接收到 events 时,它将其存储到一个或多个 channel,channe 会一直保存 events直到它被 sink 所消费。sink 的主要功能从channel 中读取 events,并将其存入外部存储系统或转发到下一个 source,成功后再从 channel 中移除 events。
基本概念
Event
Event 是 Flume NG 数据传输的基本单元。类似于 JMS 和消息系统中的消息。一个 Event 由标题和正文组成:前者是键/值映射,后者是任意字节数组。
Source
数据收集组件,从外部数据源收集数据,并存储到 Channel 中。
Channel
Channel 是源和接收器之间的管道,用于临时存储数据。可以是内存或持久化的文件系统:
Memory Channel: 使用内存,优点是速度快,但数据可能会丢失 (如突然宕机);File Channel: 使用持久化的文件系统,优点是能保证数据不丢失,但是速度慢。Sink
Sink的主要功能从Channel中读取Event,并将其存入外部存储系统或将其转发到下一个Source,成功后再从Channel中移除Event。Agent
是一个独立的 (JVM) 进程,包含Source、Channel、Sink等组件。
组件种类
- Source 类型 :内置了几十种类型,如
Avro Source,Thrift Source,Kafka Source,JMS Source; - Sink 类型 :
HDFS Sink,Hive Sink,HBaseSinks,Avro Sink等; - Channel 类型 :
Memory Channel,JDBC Channel,Kafka Channel,File Channel等。
对于 Flume 的使用,除非有特别的需求,否则通过组合内置的各种类型的 Source,Sink 和 Channel 就能满足大多数的需求。在 Flume 官网 上对所有类型组件的配置参数均以表格的方式做了详尽的介绍,并附有配置样例;同时不同版本的参数可能略有所不同,所以使用时建议选取官网对应版本的 User Guide 作为主要参考资料。
Flume配置格式
Flume 配置通常需要以下两个步骤:
- 分别定义好 Agent 的 Sources,Sinks,Channels,然后将 Sources 和 Sinks 与通道进行绑定。需要注意的是一个 Source 可以配置多个 Channel,但一个 Sink 只能配置一个 Channel。基本格式如下:
<Agent>.sources = <Source><Agent>.sinks = <Sink><Agent>.channels = <Channel1> <Channel2># set channel for source<Agent>.sources.<Source>.channels = <Channel1> <Channel2> ...# set channel for sink<Agent>.sinks.<Sink>.channel = <Channel1>
- 分别定义 Source,Sink,Channel 的具体属性。基本格式如下:
<Agent>.sources.<Source>.<someProperty> = <someValue># properties for channels<Agent>.channel.<Channel>.<someProperty> = <someValue># properties for sinks<Agent>.sources.<Sink>.<someProperty> = <someValue>

若有收获,就点个赞吧
0 人点赞
