本文提出了一种简单的 Source-free Domain Adaptation 方法,可以看作将传统的 Domain Adaptation 方法 MCD 巧妙地拓展到了 Source-free 的场景中。
本文提出的方法可以很容易的拓展到在线场景中来,也就是每个样本仅被用于更新模型一次。
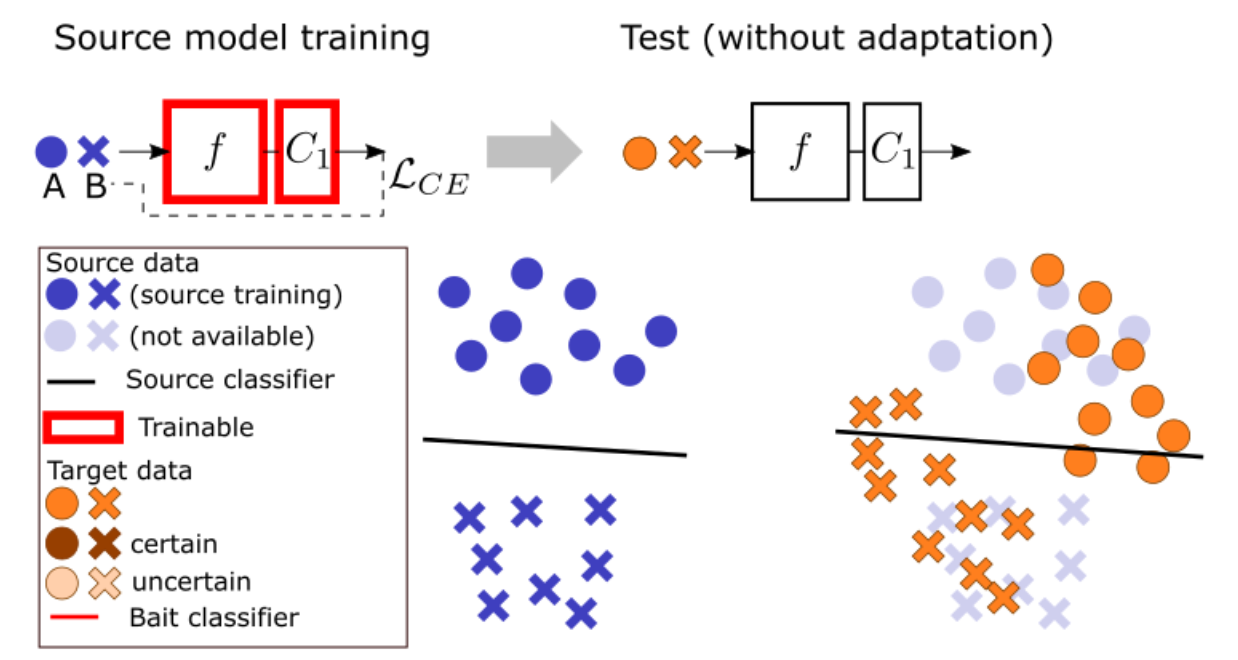
考虑到模型不进行域自适应直接应用到目标域时,特征表示会因为域偏移而偏移,导致模型没有办法正确分类部分样本。本文期望找到这些偏移样本所在的表示空间,通过对齐存在分歧的表示空间,使模型能够适应于目标分布。
整个方法分为两个步骤:
- 利用原始模型 f 与 C1 在每一个 mini-batch 中对数据进行分类,然后利用置信度将其分对半分为置信样本与非置信样本两个部分。然后训练一个分类器 C2,使其在置信样本上分类与 C1 一致,在非置信样本上的分类与 C1 不一致:
 。通过这样的步骤,可以认为是将分类置信度上的高置信与低置信,通过 C1 分类器与 C2 分类器反向投射到了特征表示空间上。
。通过这样的步骤,可以认为是将分类置信度上的高置信与低置信,通过 C1 分类器与 C2 分类器反向投射到了特征表示空间上。 - 更新表示分类器 f 使其在分类器 C1 与分类器 C2 上的输出结果相同:
 ,可以认为是利用了两个存在分歧的分类器,将两个分类器存在分歧的表示空间对齐了。进一步的,为了防止模型表示坍缩到平凡解,此方法引入了一个类别平衡的强假设,同时优化模型的分类使类别平衡的:
,可以认为是利用了两个存在分歧的分类器,将两个分类器存在分歧的表示空间对齐了。进一步的,为了防止模型表示坍缩到平凡解,此方法引入了一个类别平衡的强假设,同时优化模型的分类使类别平衡的: ,其中
,其中  是一个均匀分布。
是一个均匀分布。
在线情形,本文方法能够天然适应到在线的情形,即对于每个 mini-batch 的数据都进行 BAIT 的算法,在在线的算法中,取消了根据阈值划分置信与非置信样本的过程,应该是将所有的样本都当作非置信样本进行学习。

若有收获,就点个赞吧
0 人点赞
