本文的作者提出自监督学习预训练对于类别不平衡问题更加鲁棒的观点。据此,本文作者按照分析现象、理论解释、提出改进三个步骤呈现了本工作:
- 作者在监督表示与自监督表示上进行了实验,发现自监督表示面对不同类别不平衡程度的性能差异更小,从而验证了本文所提的观点。
- 作者在简易情况下进行的理论分析与实验,对此观点进行解释:自监督学习时不需要利用样本的标记信息,因此更容易学到能够迁移至少数类别的特征表示。
- 作者利用正则化,进一步提升了自监督学习所得的表示对于类别不平衡数据的鲁棒性。
分析现象
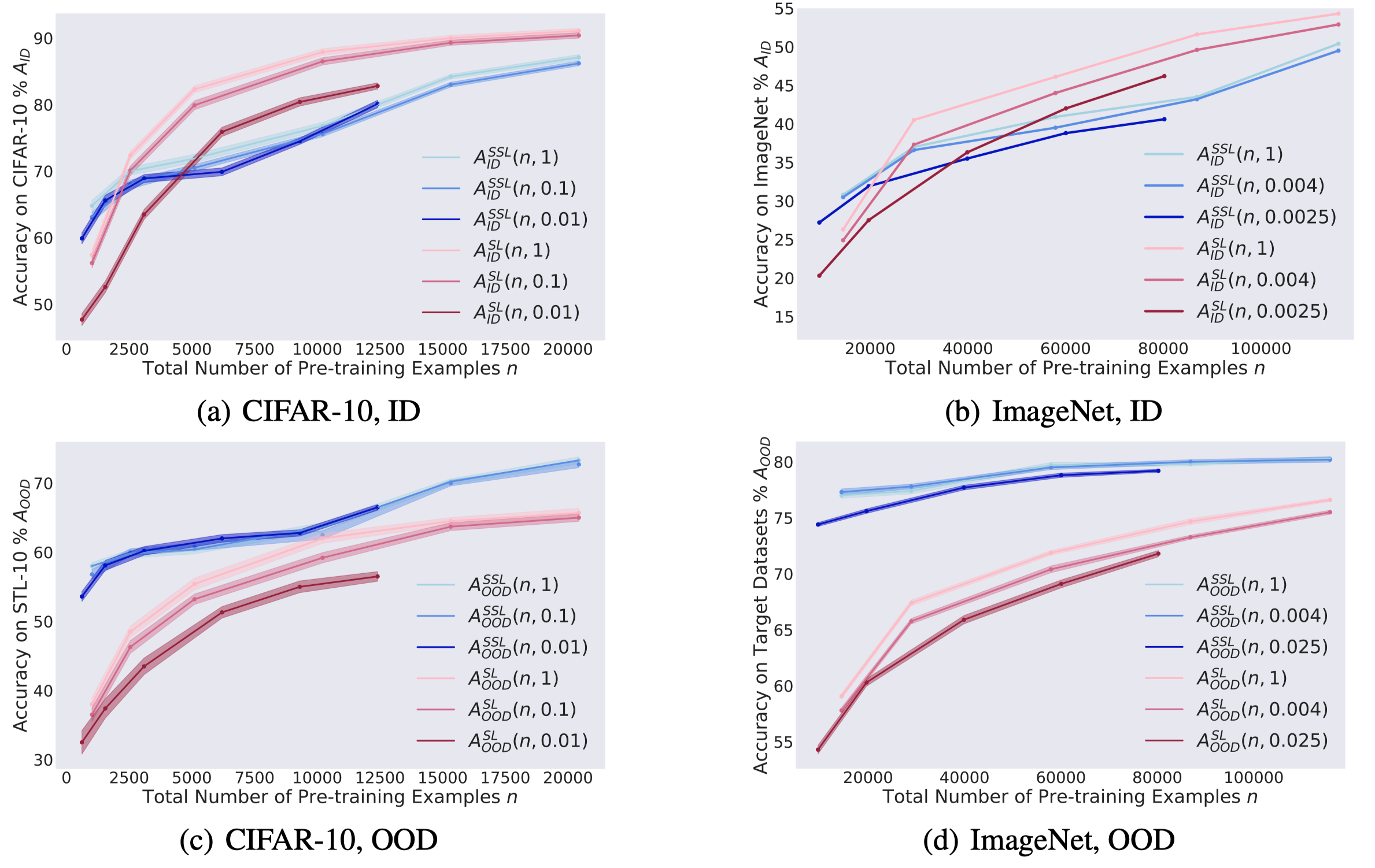
本文作者在数据集不平衡程度为 1(平衡)、0.1、0.01 情况下分别验证了监督表示SL与自监督表示SSL在ID数据与OOD数据上的性能差异。在ID数据上评估可以认为是通过SL、SSL获取特征表示,在OOD数据上评估,可以认为是评估预训练模型在下游任务上的性能。
可以看到不管是什么数据集、ID/OOD,自监督学习表示的在不同不平衡程度下的性能差异更小。
ID情况下,自监督打不过监督,这也是合情合理的,获取表示时一个使用了标记一个没使用标记,而最终评估性能时仅仅是重新训练了一个线性分类器。OOD情况下,自监督一致比监督好,这也验证了自监督学习在下游任务上的泛化能力。
理论分析
本文作者给出了一个例子,方向e1与e2正交,多数类别仅使用e1就可以分开,多数类别与少数类别则需要使用e2才能分开。此时,监督学习会学得方向e1与方向v,方向v会过拟合于少数样本;自监督学习则能利用数据自身的结构较好的学习e1与e2,这使其在监督学习上能够获得较好的性能。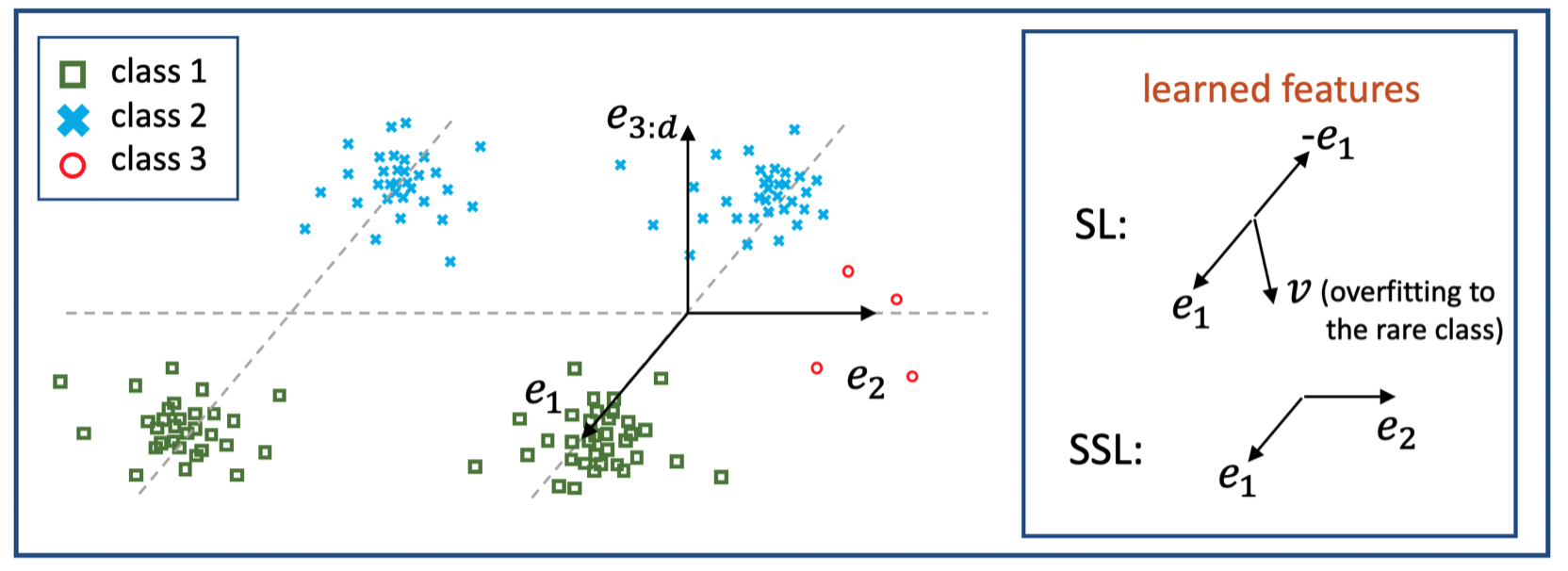
这也给出了启发,即,假设我们知道区分少数类样本所需的e2,那么所学特征与e2的相关程度就决定了,特征在少数类别上的性能。据此,本文给出了一个理论,监督学习不能够很好的学得e2,而自监督学习则相反:
本文还在真实数据集上做了一个实验,将多数类样本改造成(左:标记相关、右:标记无关)、少数类样本改造成(左:黑,右:标记相关),可以发现监督学习模型所学的特征完全集中于左侧,即,特征无法很好的区分少数类,而自监督学习所学特征则比较平均。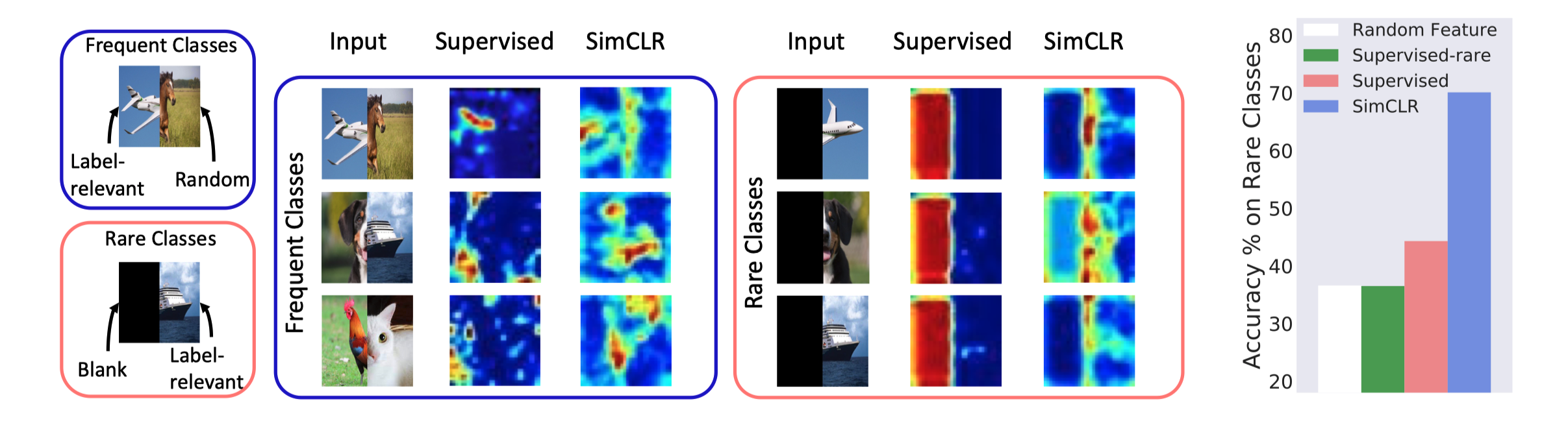
提出改进
基于上述实验与分析,已经证明了SSL对于类别不平衡问题更加鲁棒。进而,本文考虑如何进一步提升SSL对于类别不平衡问题的鲁棒性。参考了类别不平衡方法 SAM ,即,要求每个样本及其小临域内的损失要尽可能平坦(一致的小)。将SAM拓展至IMSSL问题中得到rwSAM方法。
同样要求,样本及其临域内的损失要一致的小,但是,通过权重w来考虑多数类样本与少数类样本 ,即,少数类样本的临域内损失应该更加平坦:
,即,少数类样本的临域内损失应该更加平坦:
因为SSL过程中不使用标记,所以w通过核密度估计的方法来近似标记。
总结
认同本文的观点“自监督学习预训练对于类别不平衡问题更加鲁棒”,同时本文在Toy Dataset上进行实验的操作可以学习一波。
技术上,其实是在SSL的过程中进一步引入了特征层面的数据增强,同时,这种数据增强考虑到了样本的多数与少数,相当于样本自适应的数据增强,这对于SSL来说是具有合理性的。
行文上,前两部分很合理,技术改进略奇怪,既然已经证明了SSL对不平衡问题更加鲁棒,还要进一步提升SSL的鲁棒性,那这与本文的前两部分好像没什么关系。反而,应该是从SSL的角度来提升SL对于不平衡问题的鲁棒性更合理一些。
Discussion

若有收获,就点个赞吧
0 人点赞
