问题设定
考虑真实的环境逐渐变化的 Domain Adaptation,在训练阶段可以获得源域标记数据和部分环境变化条件下的无标记数据训练模型,在测试阶段快速适应到新的逐渐变化的数据分布中来。
相关定理
文章推导定理表明当环境逐渐变化时且相邻两个环境之间的距离有保障,目标环境中的性能能够有所保障: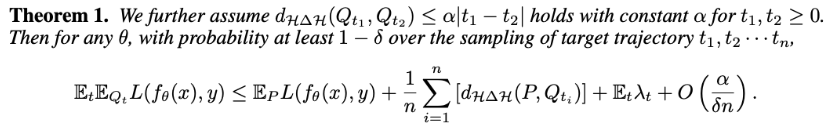
所提方法
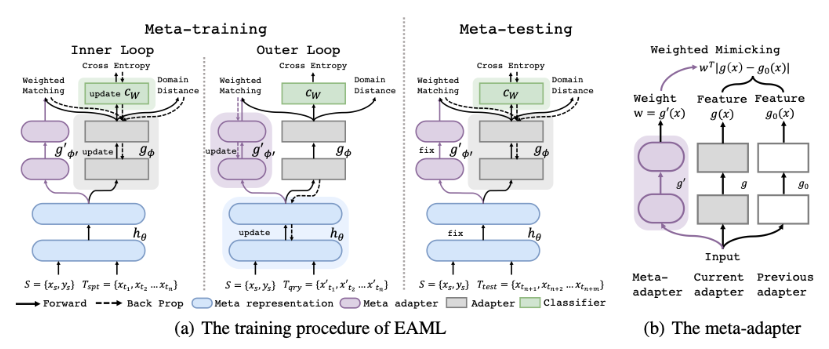
本文使用一种 Meta-Training 训练框架,在元训练阶段使用双层优化:
- 内层优化固定特征表示 f,训练特征变换器 g 与分类模型 c,目标式为:
 。降低模型在源域内的分类损失与目标域与源域之间的距离。
。降低模型在源域内的分类损失与目标域与源域之间的距离。 - 外层优化则固定 g 和 c,训练内层特征 f,目标式为:
 。
。
在优化源域域分类损失、目标域与源域之间的距离的同时,还尝试拉近相邻两个源域之间的距离,得到一个域不变的特征。同时本文还提出一种 Feature Matching 函数 g’(x) 能够通过样本算数不同层特征的重要性,在内层优化的过程中对其特征空间,保证特征空间的可复用性。最终内层优化目标为:
实验部分
使用了 Rotated MNIST 模拟这种环境的缓慢变化,在0度作为源域,[0, 60]度作为 Meta-Training 的目标域每个目标域100张图片,[120, 180]作为 Meta-Testing 的目标域,每个域依旧能够有 100 张图片。泛化到最后一个域时,测试模型在 Meta-Testing 中所有域上的性能。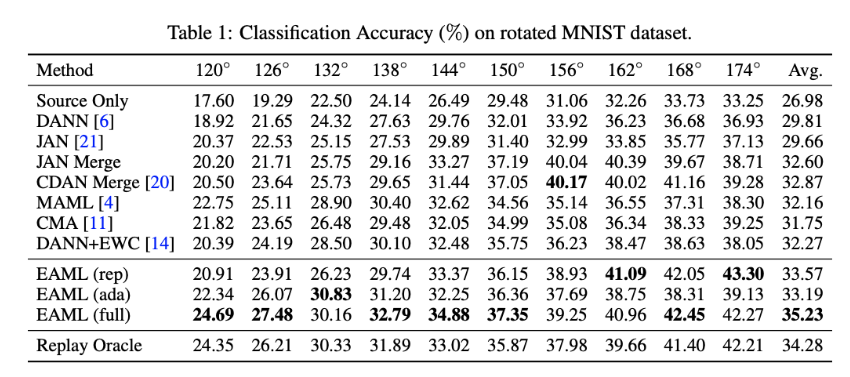
其他内容
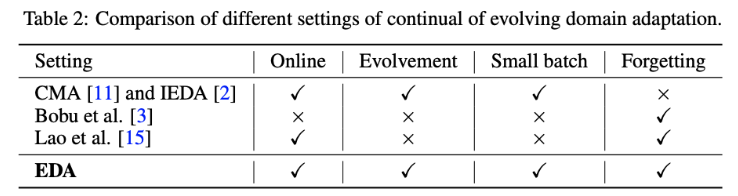
对比了一下问题设定如下图,本文所提的方法可以支持动态环境、在线小批量更新并克服了灾难性遗忘。
Question 1: 在这种流式的环境下是否还有必要克服灾难性遗忘?流式的场景下其实我们只关心当前任务上的性能,模型只需要快速泛化到当前任务上即可。一个可以提升的点在于当环境变化产生循环的时候,即遇到了之前已经遇到过的环境,模型是否能够做的更好,而不是克服灾难性遗忘减少性能下降。
Question 2: 对于在数据中存在新类的情况,是否能够依旧鲁棒,这个应该是一个比较容易做的东西。

若有收获,就点个赞吧
0 人点赞
