研究问题
开放半监督学习 Open-set Semi-Supervised Learning 中标记空间不匹配的问题。
主要贡献
- 提出了 Soft Open-set cConsistency Regularization,使无标记数据的不同增广在一场检测器上输出的 Logits 具有一致性。
- 提出了 OVA 分类器,每个分类器仅检测一个类别,当所有分类器都拒绝时样本被分类成为异常样本。
- 本文主要的研究在于如何减少半监督中有效的正则化,例如一致性正则化,熵最小化正则化引入到无标记数据中无法直接对分类模型使用的问题:因为无标记数据中存在 Outliers 这些正则化会强迫模型给这些样本分配不应存在的伪标记.
相关领域
Open-Set Domain Adaptation:区别在于标记数据和无标记数据来源于不同的数据分布,即 ; OSSL 需要从头训练一个模型.
; OSSL 需要从头训练一个模型.
Novelty Detection: 无法使用如此多的标记样本训练模型,同时无标记数据中可能同时存在Inliers和Outliers.所提方法
本文提出了一种 OVA 分类器检测无标记数据中的异常样本,为每个类别定义检测器 表示样本是否属于类别
表示样本是否属于类别 或其他类别. OVA分类器在标记数据上优化OVA损失:
或其他类别. OVA分类器在标记数据上优化OVA损失:
相当于优化样本所属类别的对数似然,降低样本不属于类别的对数似然.应用OVA分类器,可以不需要阈值直接判定OOD样本,即不被任何OVA分类器接受的样本.
本文又提出了一种Open-set Entropy Minimization方法,在无标记数据上强化OVA分类器的输出,使分类器对自己的决策更加置信,强化OVA分类器区分ID和OOD的能力:
最终本文提出了一种 Soft Open-set Consistency Regularization 使得标记信息可以在标记数据与无标记数据之间传递. 传统的硬标记一致面对 Outlier 时,并没有合理的硬标记赋给它,导致这种硬标记的一致性会使OSSL的性能退化.因此仅保持数据不同增广对应的未锐化的logits输出一致:

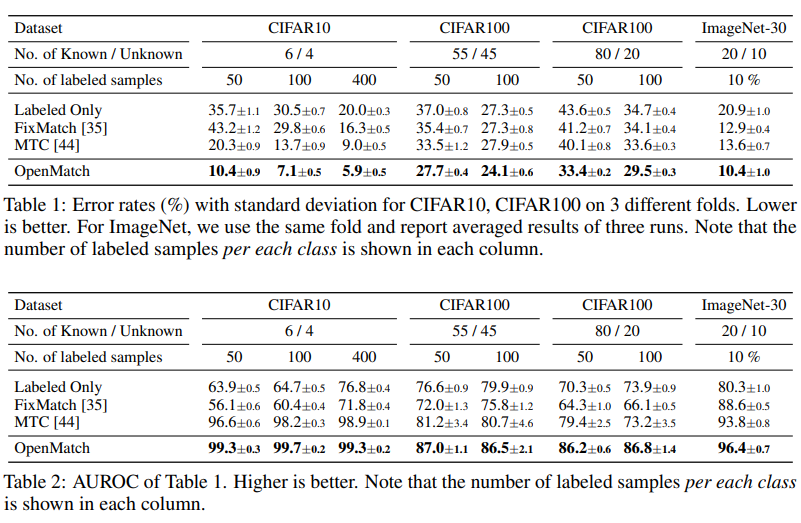
一些启发
在模型训练的过程中加入 OVA 分类器,能够更有效地将特征空间聚类.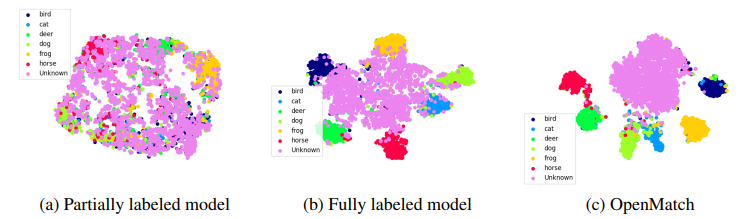
在分类模型上增加一致性,也能够增加模型检测Outlier的能力,但是在OVA分类器上使用这种一致性效果更好.
子监督学习模型的预训练作为模型的初始化并不会提升模型最终检测Outlier的能力
模型训练的过程中加入子监督损失,例如SimCLR的损失或者旋转预测的损失:增加SimCLR损失对于提升检测Outlier的并没有效果,增加选择的预测的子监督任务在标记数据上在部分任务中有一定的提升,如果对于无标记数据也加入这种子监督任务,则无效果,因为Inliers和Outliers都会被赋予相同的旋转标记.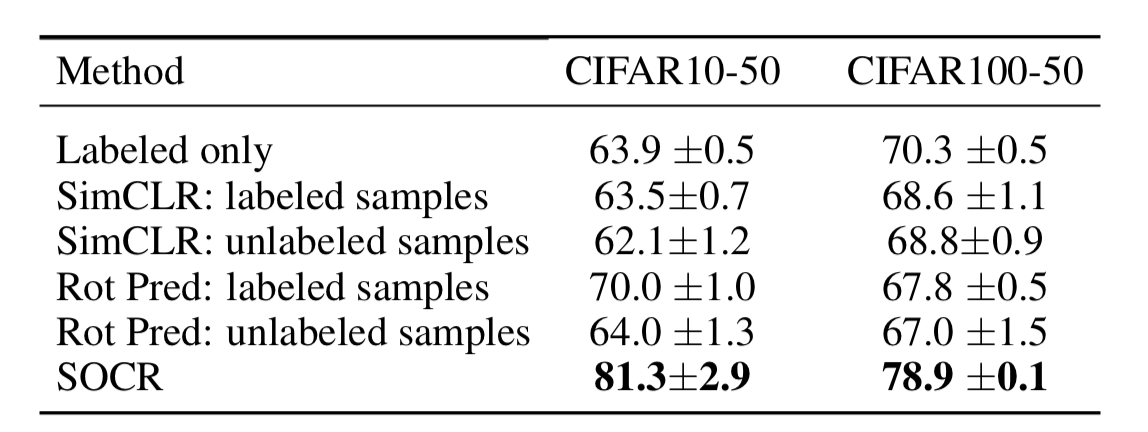

若有收获,就点个赞吧
0 人点赞
