考虑仅有目标域数据  时进行 Domain Adaptation,源域的知识仅从模型 C 中获得。
时进行 Domain Adaptation,源域的知识仅从模型 C 中获得。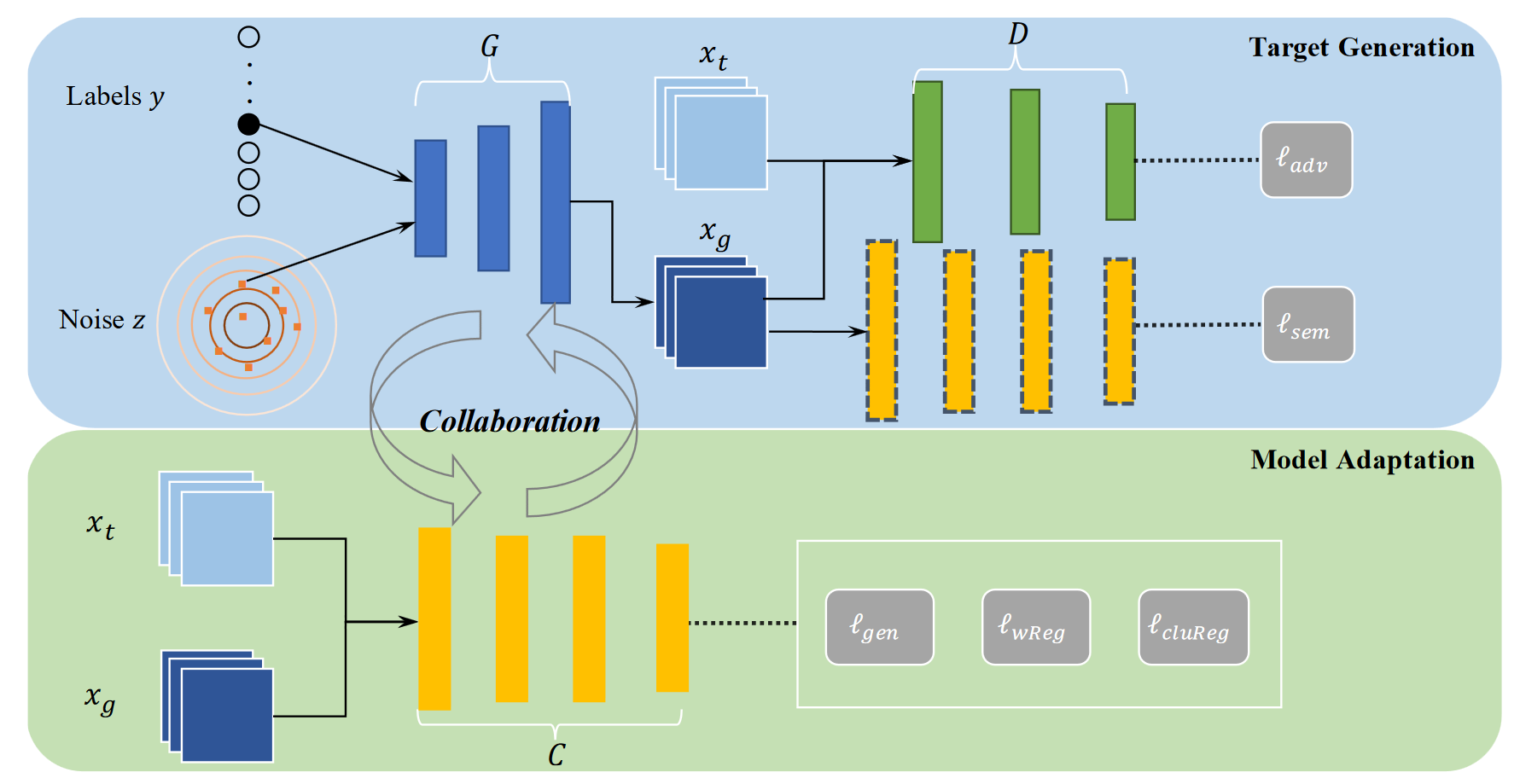
算法提出了一种具有三个模块条件GAN模型:
- G 根据随机噪声与给定的类别标记生成虚拟样本

- D 区别目标域样本
 和生成的虚拟样本
和生成的虚拟样本 
- ·C 为给定的源域模型,指导 G 生成条件样本并且逐渐更新到目标域上。
整体算法与GAN类似,迭代地更新 G、D 与 C。
对于判别器 G,我们直接训练其区分真实数据与生成数据的能力:
对于生成器 D,首先我们需要优化其生成的数据与真实数据分布相似,这个过程利用判别器 G 完成:
进一步的需要通过模型 C 抽取语义信息,使 D 拥有生成条件样本的能力:
这个过程可以看作是同时让生成器 G 与 D、C 进行对齐,在对齐的过程中环境特征部分是对抗的而语义部分是一致的,使得 G 同时抽取了目标域与语义信息。
最终,需要更新模型 C,使其能够在目标域上进行对齐: 。
。
第一项是利用 G 生成的条件样本进行监督学习,第二项与第三项利用了半监督中的一致性损失与熵最小化损失。
MA 方法可以认为,这是一种隐式域自适应方法,利用了 GAN 的学习过程,逐渐从原始模型 C 和目标域数据中提取语义与分布信息,用于更新模型 C 。

若有收获,就点个赞吧
0 人点赞
