问题
本文作者考虑了一种训练数据中可能包含未知类导致模型性能下降的潜在情形,即,由于数据特征信息量不足导致标记空间被错误指定,并进而使模型无法准确感知未见类样本。
如下图例子所示,真实标记空间存在 A、P、L 三种疾病。由于社区医疗中心的医疗检测手段有限(例如无法照 X 光),其仅能检测 A、P 两种疾病,罕见且需要高级检测手段的 L 疾病被错误标记成 A 或 P。
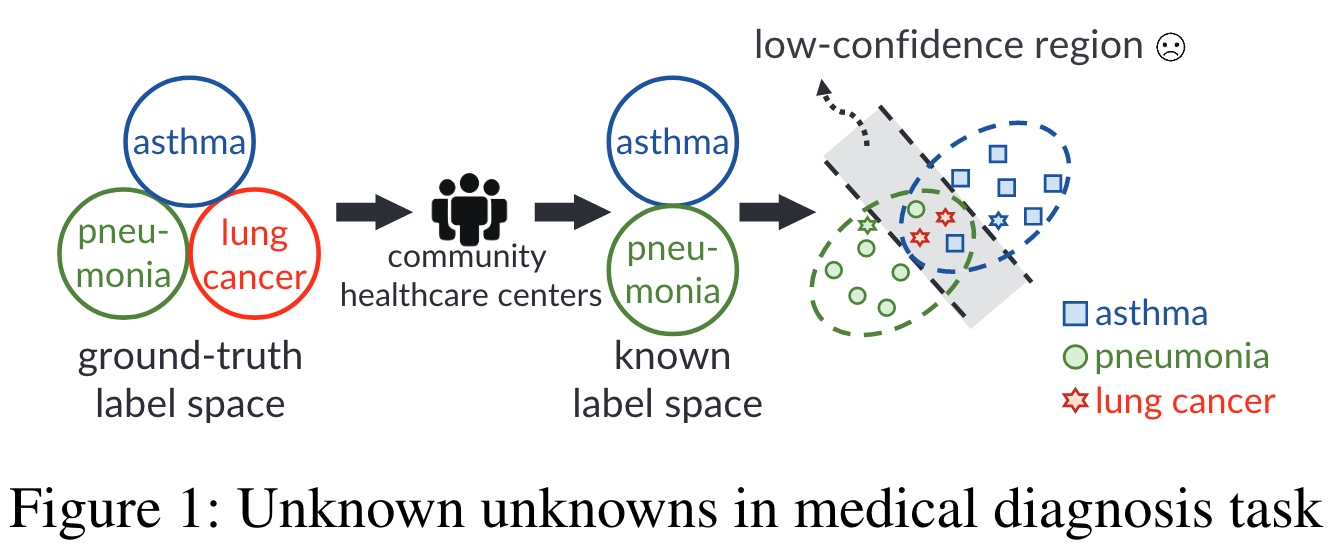
在这种情形下,“增加训练数据”或“使用更为先进的学习算法”都没有办法进一步提升所训练的机器学习性能,因为,这两种常见方式无法补充特征层面的缺失(Feature Deficiency)带来的对未知类感知能力弱的问题。
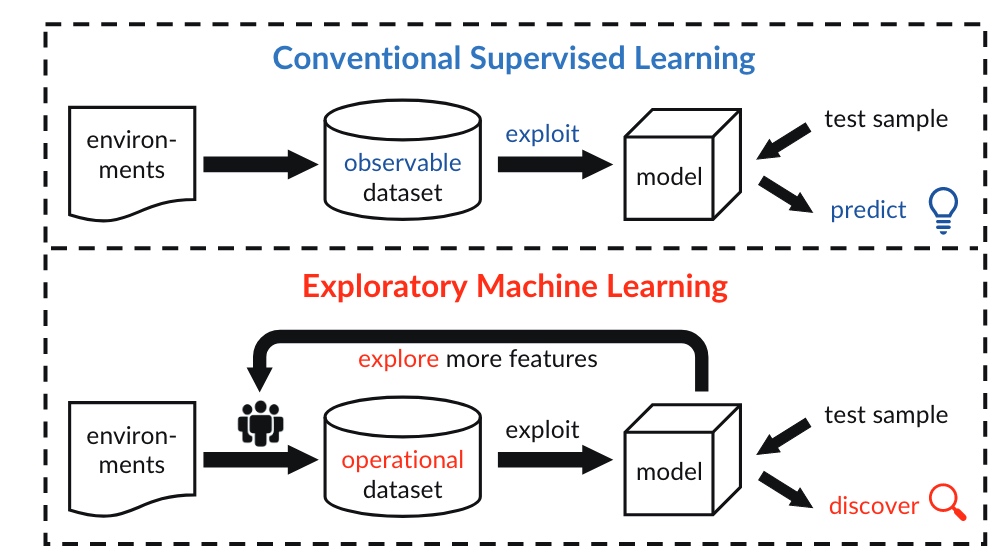
因此,需要学习算法需要支持对于数据特征进一步扩充,以应对此类特征信息不足导致对未见类感知能力弱,进而影响模型的分类性能问题。整体的学习范式(ExML)如图所示,在学习的过程中探索更多的特征。
此问题可以被进一步形式化:初始给定数据集 %5Cright%5C%7D%7Bi%3D1%7D%5E%7Bm%7D#card=math&code=%5Cwidehat%7BD%7D%7Bt%20r%7D%3D%5Cleft%5C%7B%5Cleft%28%5Cwidehat%7B%5Cmathbf%7Bx%7D%7D%7Bi%7D%2C%20%5Cwidehat%7B%5Cmathbf%7By%7D%7D%7Bi%7D%5Cright%29%5Cright%5C%7D_%7Bi%3D1%7D%5E%7Bm%7D),其中
是基于现有特征集合对于样本的观测,
是基于现有标记空间得到的样本标记。算法需要从特征候选空间中
中使用不超过
的预算找到最佳的
个候选特征,来最大化模型的性能(OSL性能:分类已知类并检测未知类)。
在本文中后续的研究中,所研究的问题被进一步简化。查询每个样本的每个新特征对应值的代价均为 ,同时,算法仅需要找到最佳的一个候选特征,即
。
在本文的研究中,寻找未见类样本依旧遵循低熵的原则,作者表示这是当前问题设定下必要的假设,未来工作中可以讨论如何抛弃这一假设。从后续技术部分来看,这一假设扮演了至关重要的角色,因此,当数据不满足此假设时,此方法不会奏效。
方法
本文所提的算法分为三个部分:拒绝模型、特征探索与模型层叠。
拒绝模型的目标式为:%20%5Csim%20%5Cwidehat%7B%5Cmathcal%7BD%7D%7D%7D%5Cleft%5B%5Cell%7B0%20%2F%201%7D(f%2C%20%5Cwidehat%7B%5Cmathbf%7Bx%7D%7D%2C%20%5Cwidehat%7B%5Cmathbf%7By%7D%7D%20%3B%20%5Ctheta)%5Cright%5D#card=math&code=%5Cmin%20%7Bf%7D%20%5Cmathbb%7BE%7D%7B%28%5Cwidehat%7B%5Cmathbf%7Bx%7D%7D%2C%20%5Cwidehat%7By%7D%29%20%5Csim%20%5Cwidehat%7B%5Cmathcal%7BD%7D%7D%7D%5Cleft%5B%5Cell%7B0%20%2F%201%7D%28f%2C%20%5Cwidehat%7B%5Cmathbf%7Bx%7D%7D%2C%20%5Cwidehat%7B%5Cmathbf%7By%7D%7D%20%3B%20%5Ctheta%29%5Cright%5D),其中,
%3D%5Cmathbb%7B1%7D%7B%5Cwidehat%7By%7D%20%5Ccdot%20h(%5Cwidehat%7B%5Cmathbf%7Bx%7D%7D)%3C0%7D%20%5Ccdot%20%5Cmathbb%7B1%7D%7Bg(%5Cwidehat%7B%5Cmathbf%7Bx%7D%7D)%3E0%7D%2B%5Ctheta%20%5Ccdot%20%5Cmathbb%7B1%7D%7Bg(%5Cwidehat%7B%5Cmathbf%7Bx%7D%7D)%5Cle0%7D#card=math&code=%5Cell%7B0%20%2F%201%7D%28f%2C%20%5Cwidehat%7B%5Cmathbf%7Bx%7D%7D%2C%20%5Cwidehat%7B%5Cmathbf%7By%7D%7D%20%3B%20%5Ctheta%29%3D%5Cmathbb%7B1%7D%7B%5Cwidehat%7By%7D%20%5Ccdot%20h%28%5Cwidehat%7B%5Cmathbf%7Bx%7D%7D%29%3C0%7D%20%5Ccdot%20%5Cmathbb%7B1%7D%7Bg%28%5Cwidehat%7B%5Cmathbf%7Bx%7D%7D%29%3E0%7D%2B%5Ctheta%20%5Ccdot%20%5Cmathbb%7B1%7D_%7Bg%28%5Cwidehat%7B%5Cmathbf%7Bx%7D%7D%29%5Cle0%7D)。解读为在学习的过程中拒绝训练集中潜在的未知类样本,并使用剩余的样本训练模型。作者在本文中认为,当拒绝模型在训练的过程中拒绝了太多的样本,就说明数据集中存在特征信息不足的问题。
特征探索过程为使用不超过 的特征值询问次数,探索潜在特征集合
中最好的特征。本文使用加入某个候选特征后模型的期望风险(后续用经验风险近似)来估计后续特征的质量:
%3D%5Cmin%20%7Bf%7D%20%5Cmathbb%7BE%7D%7B(%5Cmathbf%7Bx%7D%2C%20%5Cwidehat%7B%5Cmathbf%7By%7D%7D)%20%5Csim%20%5Cmathcal%7BD%7D%7Bi%7D%7D%5Cleft%5B%5Cell%7B0%20%2F%201%7D(f%2C%20%5Cmathbf%7Bx%7D%2C%20%5Cwidehat%7B%5Cmathbf%7By%7D%7D%20%3B%20%5Ctheta)%5Cright%5D#card=math&code=R%7Bi%7D%5E%7B%2A%7D%3DR%7Bi%7D%5Cleft%28f%7Bi%7D%5E%7B%2A%7D%5Cright%29%3D%5Cmin%20%7Bf%7D%20%5Cmathbb%7BE%7D%7B%28%5Cmathbf%7Bx%7D%2C%20%5Cwidehat%7B%5Cmathbf%7By%7D%7D%29%20%5Csim%20%5Cmathcal%7BD%7D%7Bi%7D%7D%5Cleft%5B%5Cell_%7B0%20%2F%201%7D%28f%2C%20%5Cmathbf%7Bx%7D%2C%20%5Cwidehat%7B%5Cmathbf%7By%7D%7D%20%3B%20%5Ctheta%29%5Cright%5D)。
本文提出了两种查询的方式:随机查询(Uniform Allocation)与中位数消除(Median Elimination),并根据随机查询推到了相关的算法收敛结论。
模型层叠:在增广数据集的特征之后,本文使用模型层叠的方式来增强模型的进一步分类已知类并识别未知类的能力:当原模型置信度较高时直接输出分类结果,当原模型置信度较低时,利用新的特征再训练两层简单网络对于模型预测结果进一步优化。
实验
实验上,本文在模拟数据集上验证了 ExML 寻找潜在最优特征的能力,并在两个真实数据集上探索了本文所提方法的性能。实际上,本文的贡献主要在于提出了这样一个学习范式并且给出了初步的解决方案,因此,实验部分其实简单论证一下方法的有效性即可。

若有收获,就点个赞吧
0 人点赞
