net模块
工作中不太会用到net模块,但要了解,为了http模块做铺垫,了解发展史。
回顾http请求:
普通模式:三次握手、四次挥手
长连接模式:请求头中配置字段 Connection: keep-alive
同样三次握手,四次挥手,只是他们中间可以保持连接传输数据
net模块能干什么
- net是一个通信模块
利用它可以实现:
socket是一个特殊的文件
在node中表现为一个双工流对象
- 双工流就是同时实现了 Readable 和 Writable 的流,即可以作为上游生产数据,又可以作为下游消费数据,这样可以处于数据流动管道的中间部分,即
rs.pipe(rws1).pipe(rws2).pipe(rws3).pipe(ws);
- 双工流就是同时实现了 Readable 和 Writable 的流,即可以作为上游生产数据,又可以作为下游消费数据,这样可以处于数据流动管道的中间部分,即
通过向流写入内容发送数据
- 通过监听流的内容获取数据

所以前面怎么玩 流 的,就怎么玩socket
- socket.write(
......); 写入的内容要严格按照http协议的格式,不要多了什么空格、回车、符号等!``javascript socket.write(GET / HTTP/1.1 Host: duyi.ke.qq.com Connection: keep-alive
请求体`);
2. **socket.on("data", chunk=>{});** 监听收到来自服务器的消息;所以得先write给服务器内容才有服务器响应2. socket.on("close", callback); 挂断电话后触发2. socket.end(); 客户端手动挂断电话,即 断开连接2. 服务端响应的消息中的响应头中的:**Content-Length**:消息体的总字节数。故可根据这个判断是否消息传完<a name="ylw62"></a>## 格式化响应信息+判断何时消息传完```javascriptconst net = require("net");const socket = net.createConnection({host: "duyi.ke.qq.com",port: 80},() => {console.log("连接成功");});var receive = null;/*** 提炼出响应字符串的消息头和消息体* @param {*} response*/function parseResponse(response) {const index = response.indexOf("\r\n\r\n");const head = response.substring(0, index);const body = response.substring(index + 2);const headParts = head.split("\r\n");const headerArray = headParts.slice(1).map(str => {return str.split(":").map(s => s.trim());});const header = headerArray.reduce((a, b) => {a[b[0]] = b[1];return a;}, {});return {header,body: body.trimStart()};}function isOver() {//需要接收的消息体的总字节数const contentLength = +receive.header["Content-Length"];const curReceivedLength = Buffer.from(receive.body, "utf-8").byteLength;console.log(contentLength, curReceivedLength);return curReceivedLength > contentLength;}socket.on("data", chunk => {const response = chunk.toString("utf-8");if (!receive) {//第一次receive = parseResponse(response);if (isOver()) {socket.end();}return;}receive.body += response;if (isOver()) {socket.end();return;}});socket.write(`GET / HTTP/1.1Host: duyi.ke.qq.comConnection: keep-alive`);socket.on("close", () => {console.log(receive.body);console.log("结束了!");});
创建服务器
const server = net.createServer();
返回值:server对象
server提供的方法如下:
- server.listen(port); 服务器开始监听端口,不手动关闭就会一直监听,除非遇到什么其他错误
- server.on(“listening”, callback); 服务器开始监听端口号后触发回调
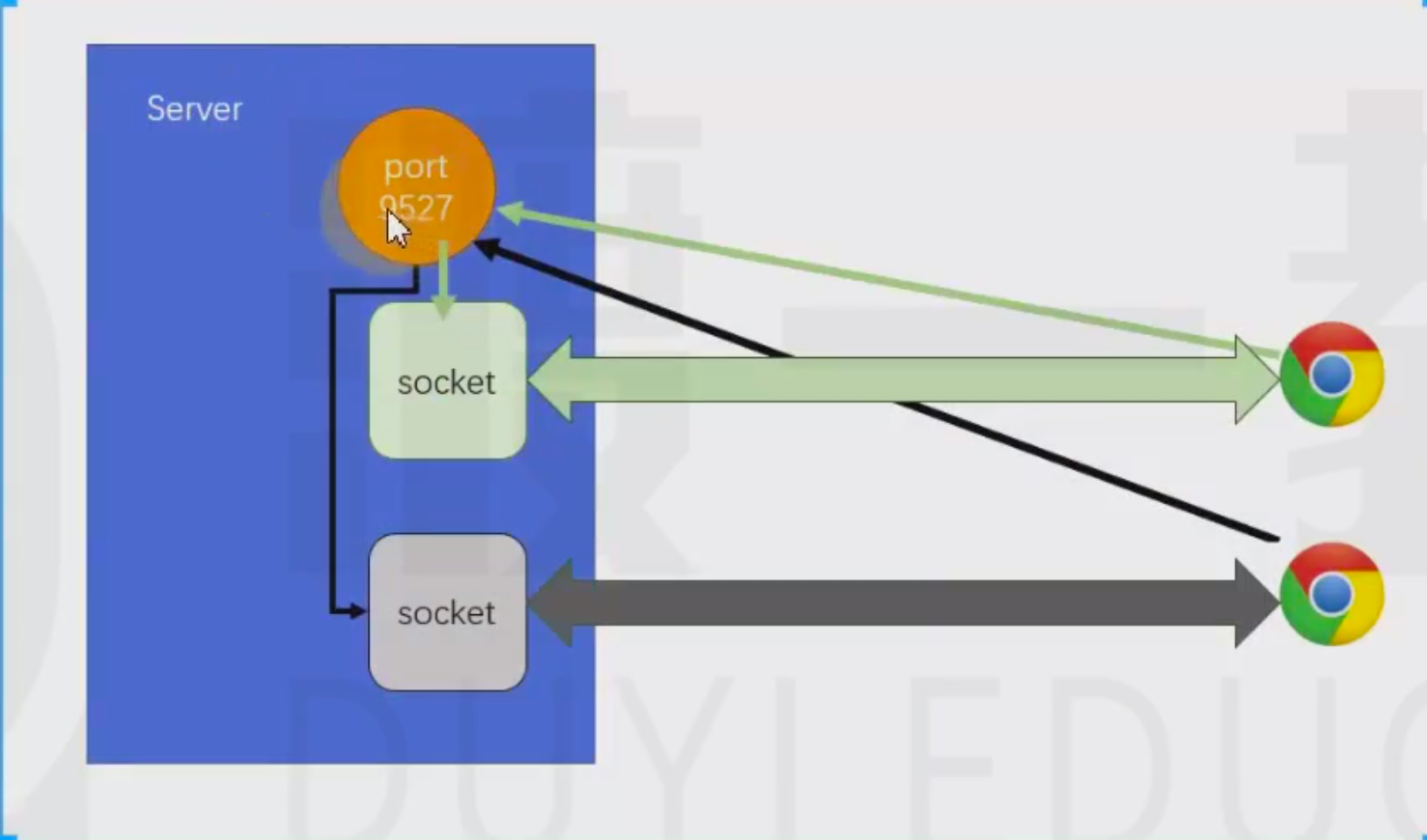
- server.on(“connection”, socket => {}); 有客户端连接到服务器后就会触发回调
- 有两次连接是因为,客户端有时会先发送一个预检请求
- 当某个连接到来时,触发该事件
- 事件的监听函数会获得一个socket对象作为参数。因为不同的连接就会产生不同的socket,应该在这个回调中,操作socket,给其注册需要的事件等。
服务器响应一张图片:
const net = require("net");const server = net.createServer();const fs = require("fs");const path = require("path");server.listen(9527); // 服务器监听9527端口server.on("listening", () => {console.log("server listen 9527");});server.on("connection", socket => {console.log("有客户端连接到服务器");socket.on("data", async chunk => {console.log(chunk.toString("utf-8"));const filename = path.resolve(__dirname, "./hsq.jpg");const bodyBuffer = await fs.promises.readFile(filename);const headBuffer = Buffer.from(`HTTP/1.1 200 OKContent-Type: image/jpeg`,"utf-8");const result = Buffer.concat([headBuffer, bodyBuffer]);socket.write(result);socket.end();});socket.on("end", () => {console.log("连接关闭了");});});
http模块
net模块比较底层,所以有了http模块,虽然工作时还是得再次封装,但是http模块必须要玩明白!
http模块建立在net模块之上
- 无须手动管理socket,也不用管它何时打开与关闭
- 无须手动组装消息格式
创建客户端发送请求
const request = http.request(url[, options][, callback: (resp) => {}]); Node作为客服端,发送一个请求
无论什么请求类型,http.request必须要有请求体才能发送请求完毕
但是这里的options配置中不能写body,没这个配置,那咋办?用下面的返回值request
resp属性中没有响应体,需要 流 读出来,给 resp注册data事件即可拿到每次的chunk!注册end就知道何时读完
返回值:request对象
request是个可写流
- 手动调用request.end(); 表示发送请求体结束。然后请求才真正发送完毕
- 不这么干的话,服务器就会接收不到这个请求,因为一直没给请求体
- request.write(); 如果是post请求,这里面就可以写键值对。比如:”a=1&b=2”。然后再调用end
搭建服务器
const server = http.createServer([options][, requestListener]); Node搭建一个服务器
返回值:server对象
//res是可写流, 不然就没法写响应体呀const server = http.createServer((req, res) => {console.log("有请求来了!url: ", req.url, "请求头: ", req.headers);// 请求体要从req的流里读, 响应体要从res的流里写});
server提供的方法如下:
- server.listen(port); 服务器开始监听端口,不手动关闭就会一直监听,除非遇到什么其他错误
- server.on(“listening”, callback); 服务器开始监听端口号后触发回调
搭建静态资源服务器
```javascript //静态资源服务器 // http://localhost:9527/index.html -> public/index.html 文件内容 // http://localhost:9527/css/index.css -> public/css/index.css 文件内容
const http = require(“http”); const URL = require(“url”); const path = require(“path”); const fs = require(“fs”);
async function getStat(filename) { try { return await fs.promises.stat(filename); } catch { return null; } }
/**
- 得到要处理的文件内容 */ async function getFileContent(url) { const urlObj = URL.parse(url); let filename; //要处理的文件路径 filename = path.resolve(dirname, “public”, urlObj.pathname.substr(1)); let stat = await getStat(filename); if (!stat) { //文件不存在 return null; } else if (stat.isDirectory()) { //文件是一个目录 filename = path.resolve( dirname, “public”, urlObj.pathname.substr(1), “index.html” ); stat = await getStat(filename); if (!stat) { return null; } else { return await fs.promises.readFile(filename);// 这里最好肯定是用流一点点读 } } else { return await fs.promises.readFile(filename); } }
async function handler(req, res) { const info = await getFileContent(req.url); if (info) { res.write(info); } else { res.statusCode = 404; res.write(“Resource is not exist”); } res.end(); }
const server = http.createServer(handler); server.on(“listening”, () => { console.log(“server listen 6100”); }); server.listen(6100);
<a name="ABXQM"></a>## 总结1. **我是客户端**,我发送请求,request是**ClientRequest**的实例。得到的响应resp 是**IncomingMessage**的实例1. **我是服务器**,别人给的请求 是**IncomingMessage**实例,我响应给别人的resp是**ServerResponse**的实例1. **请求体需要从流中读、写**<a name="sWoqw"></a># https协议<a name="gN9GE"></a>## 铺垫见ppt<br />https保证的是,数据在 **传输过程中** 不被窃取(你可以窃取到,但你看不懂,改不了)和篡改<br />**浏览器希望,通过https协议拿到的网页中,其他资源也均应该使用https协议获取。https默认端口443.****服务器诞生之初,如果想用https协议,一定要向CA机构去申请CA证书。**<br />**CA出现的目的,就是为了解决第一次双方通信时,密钥被中间人窃取、篡改的情况!以及信任服务器。**<br />**CA机构本身也有一对儿公私钥(绝对不会泄漏,否则世界就GG)和自己的证书。因为它也要用服务器啊****故CA证书包含:数字签名+给我们的公钥key1+明文数据+hash算法+CA机构信息+我们访问的服务器地址。**<br />**证书签名的hash算法也是公开的,它出现的目的,就是为了让每个拿到证书的终端,可以验证签名是否被篡改!**1. **服务器传给浏览器CA证书**1. **浏览器验证CA证书信息,如果通过了,后续双方就可以正常通信了!****虽然信息没泄漏,但中间人可以把信息留住,然后不转发给另外一方。导致原先人苦苦等待,了无音讯。**<a name="GUxIQ"></a>## 主要解决如下问题**CA颁发机构**<br />依然考虑**中间人攻击**的情况,非对称加密的算法都是**公开**的,所有人都可以自己生成一对公钥私钥。<br />当服务端向客户端返回公钥A1的时候,中间人将其**替换**成自己的公钥B1传送给浏览器。<br />而浏览器此时一无所知,傻乎乎地使用公钥B1加密了密钥K发送出去,又被**中间人截获**,中间人利用自己的私钥B2解密,得到密钥K,再使用服务端的公钥A1加密传送给服务端,完成了通信链路,而服务端和客户端毫无感知。<br />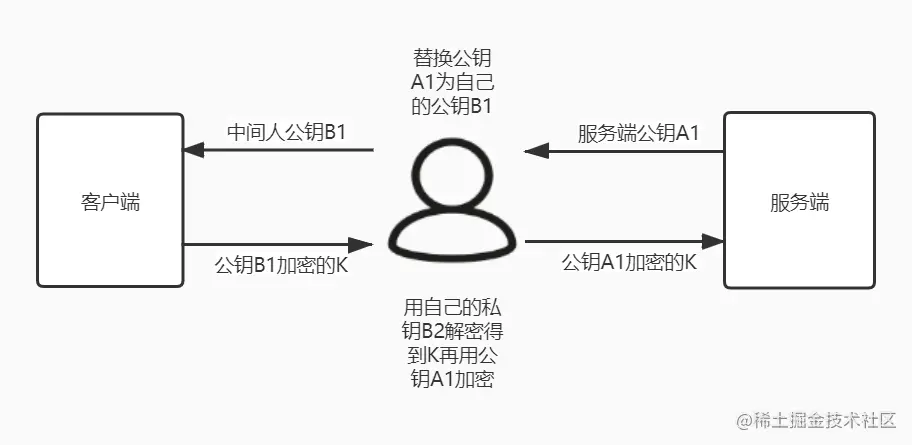<br />**HTTPS中间人**<br />出现这一问题的核心原因是**客户端无法确认收到的公钥是不是真的是服务端发来的**。为了解决这个问题,互联网引入了一个公信机构,这就是CA。<br />服务端在使用HTTPS前,去经过认证的CA机构申请颁发一份**数字证书**,数字证书里包含有证书持有者、证书有效期、公钥等信息,服务端将证书发送给客户端,客户端校验证书身份和要访问的网站身份确实一致后再进行后续的加密操作。<br />但是,如果中间人也聪明一点,**只改动了证书中的公钥部分**,客户端依然不能确认证书**是否被篡改**,这时我们就需要一些**防伪技术**了。<br />前面说过,非对称加密中一般公钥用来加密,私钥用来解密,虽然私钥加密理论上可行,但由于数学上的设计这么做并不适合,那么私钥就只有解密这个功能了么?<a name="oyMuS"></a>## 如何验证私钥除了解密外的真正用途其实还有一个,就是**数字签名**,其实就是一种防伪技术,只要有人篡改了证书,那么数字签名必然校验失败。具体过程如下:1. CA机构拥有自己的一对公钥和私钥(受信任的已知公钥内置于浏览器和OS)1. CA机构在颁发证书时对证书明文信息进行哈希1. 将哈希值用私钥进行**加签**,得到数字签名**明文数据和数字签名组成证书,传递给客户端。**1. 客户端得到证书,分解成明文部分Text和数字签名Sig11. 用CA机构的公钥进行**解签**,得到Sig2(由于CA机构是一种公信身份,因此在系统或浏览器中会内置CA机构的证书和公钥信息)1. 用证书里声明的哈希算法对明文Text部分进行哈希得到H1. 当自己计算得到的哈希值H与**解签**后的Sig2**相等**,表示证书可信,**没有被篡改**<br />这时,签名是由CA机构的私钥生成的,中间人篡改信息后无法拿到CA机构的私钥,保证了证书可信。<br />注意,这里有一个比较**难以理解**的地方:> 非对称加密的签名过程是,私钥将一段消息进行加签,然后将签名部分和消息本身一起发送给对方,收到消息后对签名部分利用公钥验签,如果验签出来的内容和消息本身一致,表明消息没有被篡改。在这个过程中,系统或浏览器中内置的CA机构的证书和公钥成为了至关重要的环节,这也是CA机构公信身份的证明,如果系统或浏览器中没有这个CA机构,那么客户端可以不接受服务端传回的证书,显示HTTPS警告。<br />实际上CA机构的证书是一条信任链,A信任B,B信任C,以**掘金的证书**为例,掘金向RapidSSL申请一张证书,而RapidSSL的CA身份是由DigiCert Global根CA认证的,构成了一条信任链。<br />各级CA机构的私钥是绝对的私密信息,一旦CA机构的私钥泄露,其公信力就会一败涂地。之前就有过几次**CA机构私钥泄露**,引发信任危机,各大系统和浏览器只能纷纷吊销内置的对应CA的根证书。<br />有些老旧的网站会要求使用前下载安装他自己的根证书,这就是这个网站使用的证书并不能在系统内置的CA机构和根证书之间形成一条信任链,需要自己安装根证书来构成信任链,这里的风险就要**使用者自己承担**了。<a name="H91Ah"></a># https模块<a name="PvOd2"></a>## 服务器结构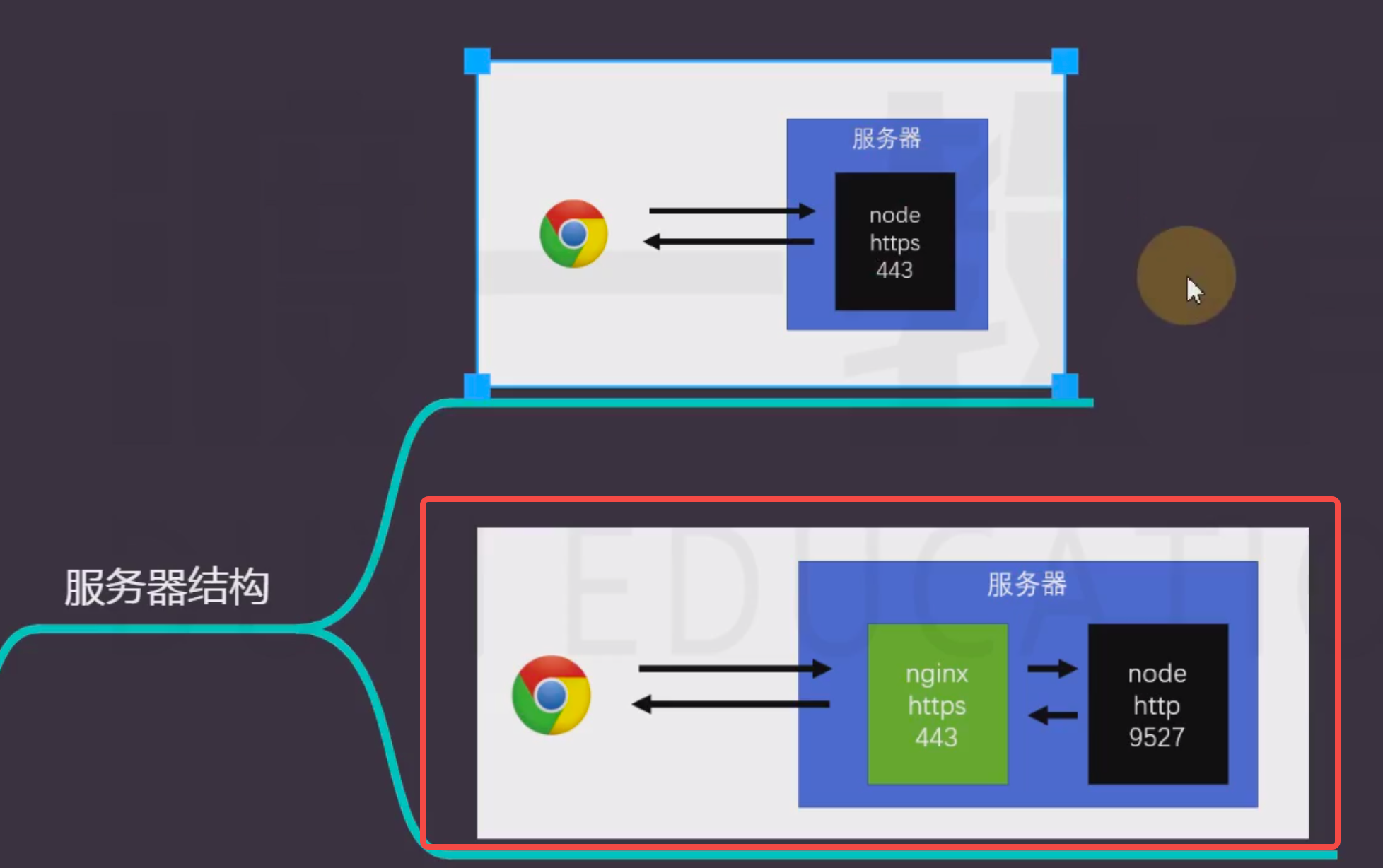<br />第二种是工业中的应用,所以实际开发中大概率用不到https模块<a name="HK81Y"></a>## 证书准备免费的千万不要用!免费一年,但是换证书很麻烦,主要是每个用户要换!而浏览器却缓存了之前的证书方式1. 网上购买权威机构证书:准备好 money、服务器、域名,该方式应用在部署环境中(部署到nginx)<br />方式2. 本地生产证书:自己作为权威机构发布证书,浏览器肯定不认,但它会给提示,我要真想访问也行<a name="Hm2rR"></a>### 本地生产CA证书流程:1. 安装openssl1. 可以下载源码,自行编译、构建1. 或者下载windows安装包(40多mb是完全版吧),安装到最后一步会问你能不能给点钱1. 然后去系统环境变量,加入其bin目录第路径即可3. 或者mac下自带3. 最后通过输入命令**openssl**测试2. 生成CA私钥:**openssl genrsa -des3 -out ca-pri-key.pem 1024**1. **1. genrsa:密钥对生成算法1. -des3:使用对称加密算法des3对私钥进一步加密1. -out ca-pri-key.pem:将加密后的私钥保存到当前目录的ca-pri-key.pem文件中1. 1024:私钥的字节数3. 生成CA公钥(证书请求密钥):openssl req -new -key ca-pri-key.pem -out ca-pub-key.pem1. 通过私钥文件ca-pir-key.pem中的内容,生成对应的公匙,保存到 ca-pub-key.pem1. 运行过程中要使用之前输入的密码来实现对私钥文件的解密1. 其他输入信息:1. 自己作为CA机构要填写的一些信息。4. 生成自己的根CA证书:openssl x509 -req -in ca-pub-key.pem -signkey ca-pri-key.pem -out ca-cert.crt1. 使用X.509证书标准,通过证书请求文件ca-pub-key.pem生成证书,并使用私钥ca-pri-key.pem加密,然后把证书保存到ca-cert.crt文件中5. ----华丽的分割线----5. 生成服务器私钥:openssl genrsa -out **server-key.pem** 10245. 生成服务器公钥:open req -new -key server-key.pem -out server-scr.pem5. 生成服务器证书:openssl x509 -req -CA ca-cert.crt -CAkey ca-pri-key.pem -CAcreateserial -in server-scr.pem -out **server-cert.crt**<a name="Z8tRk"></a>## https模块基本同http模块一致,名字换为https,然后创建服务时有区别:```javascriptconst server = https.createServer({key: fs.readFileSync(path.resolve(__dirname, "./server-key.pem")), //服务器私钥cert: fs.readFileSync(path.resolve(__dirname, "./server-cert.crt"))//服务器证书},handler);
至此,就可以启动一个由自己颁发的CA证书(浏览器和OS不认)的服务,然后进行https通信
Node生命周期
Node事件循环不同于浏览器环境下的事件循环。而且!不同的操作系统上,还有些细微的差异,涉及很深!!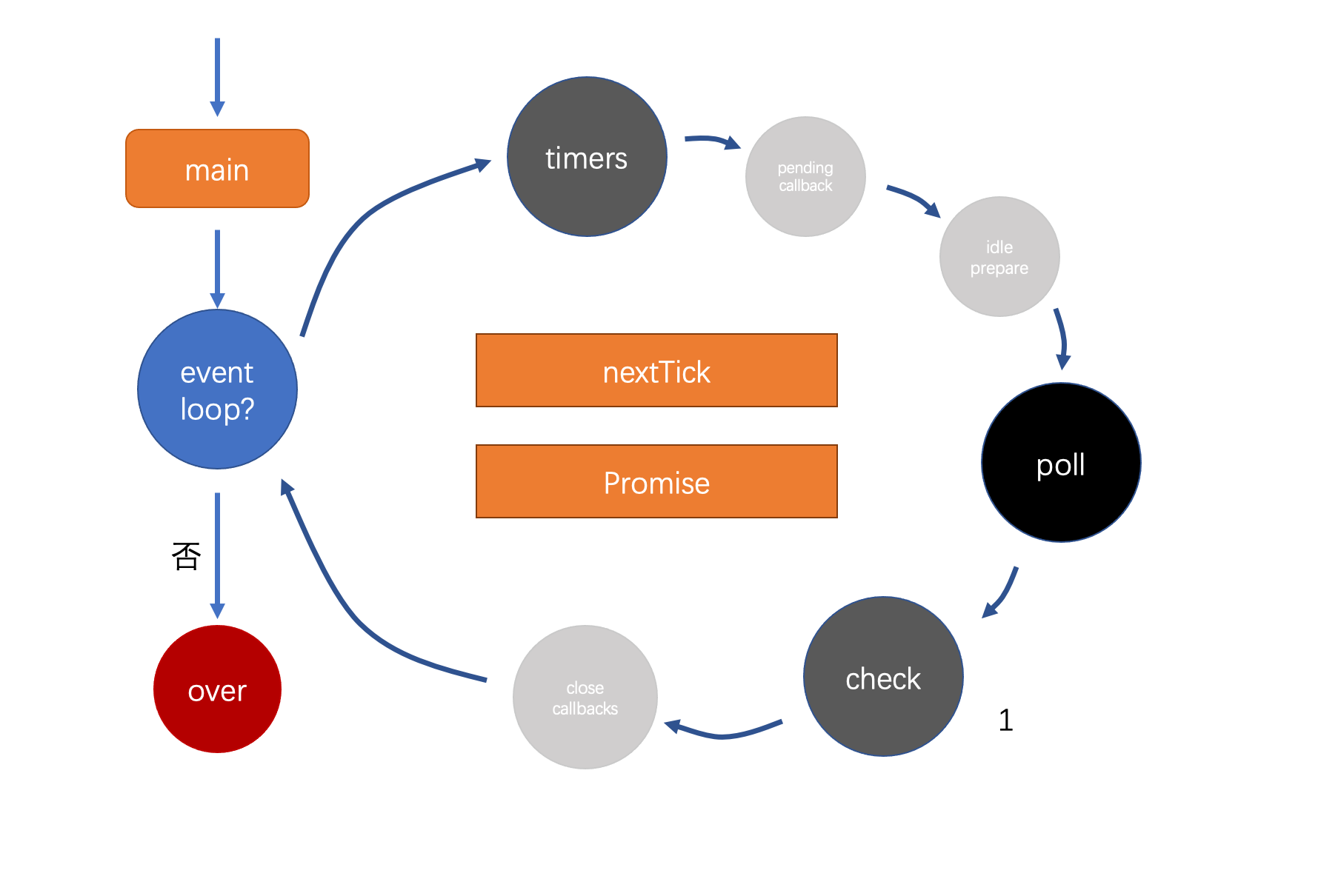
一次循环/tick会经过上述六个阶段,timers、poll、check是重要的三个阶段
每个阶段都可以看作是一个事件队列!
如果当前队列中有callback,就依次执行完!
中间的nextTick和Promise都是微任务,nextTick优先级最高。其他队列中的任务都是宏任务。
timers阶段/队列
存放计时器的回调函数,它真正等待的时间很可能就超过了我们设置的时间。首先要先判断时间是否到达
node环境下计时器最低设置为1ms。
⭐️poll阶段/队列
poll:轮询队列(理解轮询这个概念才行)
除了timers、checks以外,绝大部分回调都会放入该队列!
比如:文件的读取、监听用户请求的回调
运作方式
- 如果poll中有回调,则依次执行回调,直到清空队列。没回调 或 清空了,就走下面的逻辑
- 如果poll中没有回调,则等待其他队列中出现回调,出现后,则结束该阶段,进入下一阶段
- 如果其他队列也没有回调,则持续等待,直到出现回调为止
- 底层用libuv库,如果时间都等到OS都受不了了,就会结束本阶段。尝试进入下次Event Loop
check阶段/队列
检查阶段:setImmediate的回调函数,会直接进入该队列。它比setTimeout效率高很多,因为不用判断时间是否到达了
setTimeout(() => {console.log("setTimeout");}, 1);setImmediate(() => {console.log("setImmediate");});//这种情况下,他俩顺序并不一定谁前谁后// 但如果这俩句都在readFile的回调中,则一定先打印setImmediate
setImmediate和setTimeoutX谁先运行真的说不准的!
nextTick与Process
process.nextTick(callback);
事件循环中,每次打算执行一个宏任务的回调之前,必须要先清空nextTick和Promise队列!
nextTick的回调会被立即push入nextTick的队列中。它的优先级最高!
setImmediate(() => {console.log(1);});process.nextTick(() => {console.log(2);process.nextTick(() => {console.log(6);});});console.log(3);Promise.resolve().then(() => {console.log(4);process.nextTick(() => {console.log(5);});});//3 2 6 4 5 1,顺序一定是这样
nextTick的产生历程:setTimeout->setImmediate->nextTick(不能用immediate了,而且那会没Promise)
面试题:
async function async1() {console.log("async1 start");await async2();console.log("async1 end");}async function async2() {console.log("async2");}console.log("script start");setTimeout(function() {console.log("setTimeout0");}, 0);setTimeout(function() {console.log("setTimeout3");}, 3);setImmediate(() => console.log("setImmediate"));process.nextTick(() => console.log("nextTick"));async1();new Promise(function(resolve) {console.log("promise1");resolve();console.log("promise2");}).then(function() {console.log("promise3");});console.log("script end");script startasync1 startasync2promise1promise2script endnextTickasync1 endpromise3setTimeout0setImmediate//这个不一定在中间,也可能在0前,也可能在3后setTimeout3
其实最后那个setImmediate和setTimeoutX的顺序说不准,但setTimeout0一定在setTimeout3之前
补充
node环境下的事件循环机制
1.与浏览器环境有何不同?
在node中,事件循环表现出的状态与浏览器中大致相同。不同的是node中有一套自己的模型。node中事件循环的实现是依靠的libuv引擎。我们知道node选择chrome v8引擎作为js解释器,v8引擎将js代码分析后去调用对应的node api,而这些api最后则由libuv引擎驱动,执行对应的任务,并把不同的事件放在不同的队列中等待主线程执行。 因此实际上node中的事件循环存在于libuv引擎中。
2.事件循环模型
下面是一个libuv引擎中的事件循环的模型:
┌───────────────────────┐
┌─>│ timers(定时器回调) │
│ └──────────┬────────────┘
│ ┌──────────┴────────────┐
│ │ I/O callbacks │
│ └──────────┬────────────┘
│ ┌──────────┴────────────┐
│ │ idle, prepare(内部使用) │
│ └──────────┬────────────┘ ┌───────────────┐
│ ┌──────────┴────────────┐ │ incoming: │
│ │ poll │<──connections─── │
│ └──────────┬────────────┘ │ data, etc. │
│ ┌──────────┴────────────┐ └───────────────┘
│ │ check(setImmediate方法) │
│ └──────────┬────────────┘
│ ┌──────────┴────────────┐
└──┤ close callbacks │
└───────────────────────┘
3.事件循环各阶段详解
从上面这个模型中,我们可以大致分析出node中的事件循环的顺序:
外部输入数据—>轮询阶段(poll)—>检查阶段(check)—>关闭事件回调阶段(close callback)—>定时器检测阶段(timer)—>I/O事件回调阶段(I/O callbacks)—>闲置阶段(idle, prepare)—>轮询阶段…
这些阶段大致的功能如下:
- timers: 这个阶段执行定时器队列中的回调如 setTimeout() 和 setInterval()。
- I/O callbacks: 这个阶段执行几乎所有的回调。但是不包括close事件,定时器和setImmediate()的回调。
- idle, prepare: 这个阶段仅在内部使用,可以不必理会。
- poll: 等待新的I/O事件,node在一些特殊情况下会阻塞在这里。
- check: setImmediate()的回调会在这个阶段执行。
- close callbacks: 例如socket.on(‘close’, …)这种close事件的回调。
下面我们来按照代码第一次进入libuv引擎后的顺序来详细解说这些阶段:
poll阶段
当个v8引擎将js代码解析后传入libuv引擎后,循环首先进入poll阶段。poll阶段的执行逻辑如下: 先查看poll queue中是否有事件,有任务就按先进先出的顺序依次执行回调。 当queue为空时,会检查是否有setImmediate()的callback,如果有就进入check阶段执行这些callback。但同时也会检查是否有到期的timer,如果有,就把这些到期的timer的callback按照调用顺序放到timer queue中,之后循环会进入timer阶段执行queue中的 callback。 这两者的顺序是不固定的,收到代码运行的环境的影响。如果两者的queue都是空的,那么loop会在poll阶段停留,直到有一个i/o事件返回,循环会进入i/o callback阶段并立即执行这个事件的callback。
值得注意的是,poll阶段在执行poll queue中的回调时实际上不会无限的执行下去。有两种情况poll阶段会终止执行poll queue中的下一个回调:1.所有回调执行完毕。2.执行数超过了node的限制。
check阶段
check阶段专门用来执行setImmediate()方法的回调,当poll阶段进入空闲状态,并且setImmediate queue中有callback时,事件循环进入这个阶段。
close阶段
当一个socket连接或者一个handle被突然关闭时(例如调用了socket.destroy()方法),close事件会被发送到这个阶段执行回调。否则事件会用process.nextTick()方法发送出去。
timer阶段
这个阶段以先进先出的方式执行所有到期的timer加入timer队列里的callback,一个timer callback指得是一个通过setTimeout或者setInterval函数设置的回调函数。
I/O callback阶段
如上文所言,这个阶段主要执行大部分I/O事件的回调,包括一些为操作系统执行的回调。例如一个TCP连接生错误时,系统需要执行回调来获得这个错误的报告。
【扩展】EventEmitter
node事件管理的通用机制
平时写代码发现有同一个接口 on,怎么来的呢?其实都是使用了EventEmitter如下:
const { EventEmitter } = require("events");//创建一个事件处理对象//可以注册事件,可以触发事件const ee = new EventEmitter();//ee.addEventListener(xxx, func);ee.on("可以自定义事件名", callback);ee.emit("xxx");//触发名为xxx的事件, 会依次运行注册的事件函数, 同名的多个回调也会依次触发ee.once(xxx,func);//就会只触发一次ee.off(xxx,具名func);//移除指定事件的指定回调函数
EventEmitter 内部维护了多个事件队列,是普通数组,不同于事件循环中的队列
利用EventEmitter封装MyRequest
// MyRequest.js 发送网络请求模块const http = require("http");const { EventEmitter } = require("events");module.exports = class extends EventEmitter {constructor(url, options) {super();this.url = url;this.options = options;}send(body = "") {const request = http.request(this.url, this.options, res => {let result = "";res.on("data", chunk => {result += chunk.toString("utf-8");});res.on("end", () => {this.emit("res", res.headers, result);});});request.write(body);request.end();}};//index.jsconst MyRequest = require("./MyRequest");const request = new MyRequest("http://duyi.ke.qq.com");request.send();request.on("res", (headers, body) => {console.log(headers);console.log(body);});

若有收获,就点个赞吧
0 人点赞
