React —— UI的解决方案
React.Router —— 路由的解决方案
Redux ——- 数据的解决方案
Antd —— UI库
MVC
它是一个UI的解决方案,用于降低UI,以及UI关联的数据的复杂度
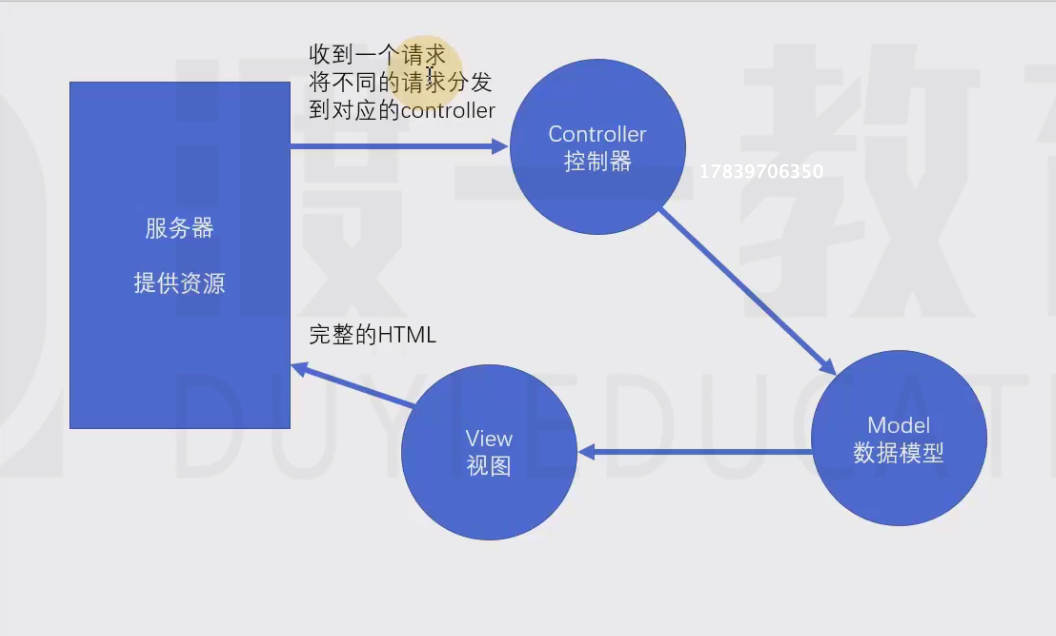
传统的服务器端的MVC
环境:
- 服务端需要响应一个完整的HTML
- 该HTML中包含页面需要的数据
- 浏览器仅承担渲染页面的作用
以上的这种方式叫做服务端渲染,即服务器端将完整的页面组装好之后,一起发送给客户端
服务器端需要处理UI中要用到的数据,并且要将数据嵌入到页面中,最终生成一个完整的HTML页面响应
Controller—控制器
将不同的请求分发到对应的controller:处理请求,组装这次请求需要的数据
Model—模型
View—视图
视图,用于将模型组装到界面
前端MVC模式的困难
前端若想mvc,理论上应该是这样的: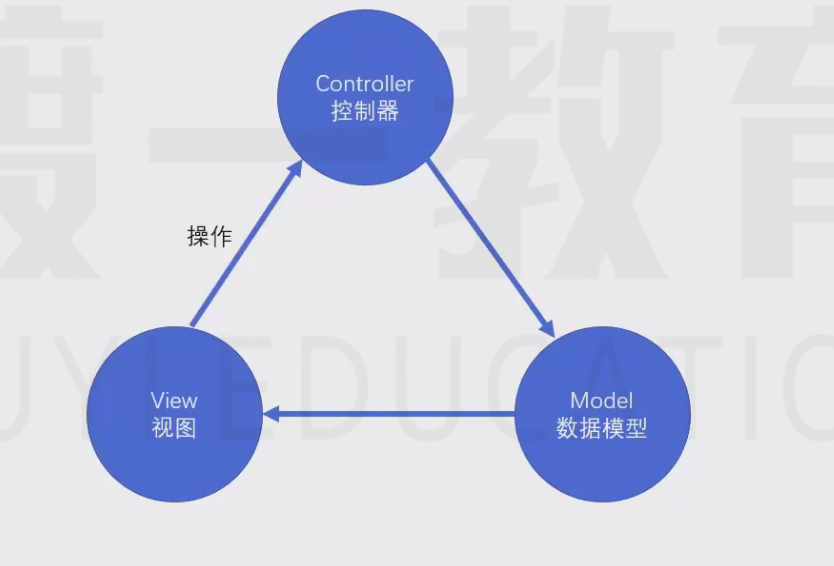
但假设,100个组件,平均每个组件有2个事件。 其中,有30个组件,进行了某种操作之后需要改变同一块数据。 这时候还用控制器的话,则控制器会异常庞大且难以维护
React解决了数据 -> 视图的问题
- 前端的controller要比服务器中的复杂,因为前端中的controller处理的是用户的操作,而用户的操作场景是非常复杂的。
- 对于那些组件化的框架(比如Vue,React),它们使用的是单向数据流—容易控制且安全,符合人类思维。它们若需要共享数据,则必须将数据提升到顶层组件,然后再将数据一层层传递,极其繁琐。
- 虽然可以使用上下文来提供共享数据,但对数据的监控难以监控,容易导致调试错误困难(你怎么知道是哪里触发的这个错误,1k个组件里50个都用这个数据,你怎么找这个bug?!)以及数据还原困难
- 并且,若开发一个大中型项目,共享的数据很多,会导致上下文中的数据非常复杂。会疯掉的
前端需要一个独立的数据解决方案
综上前端需要一个,独立的数据解决方案,来降低数据处理的复杂度!!
flux
是Facebook提出的数据解决方案,它的最大历史意义,在于它引入了action的概念。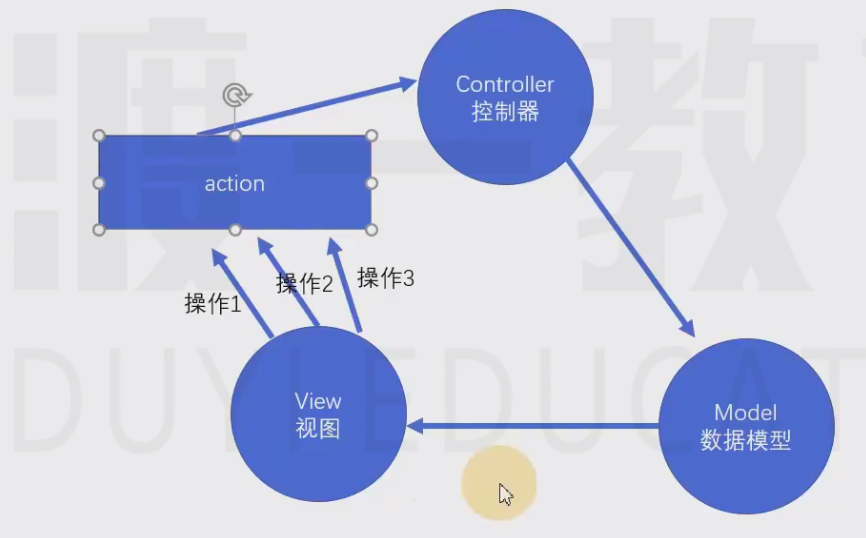
action是一个普通的对象{type, payload},用于描述要干什么。(服务端的控制器简单就是因为它也有个东西描述了要干什么,什么东西—>网络请求!!)这样一来就跟视图无关了。action是触发数据变化的唯一原因!
store表示数据仓库,用于存储共享数据。还可以根据不同的action更改仓库中的数据。
redux
进一步优化了flux(store还是很复杂),在flux的基础上,引入了reducer的概念。
reducer:处理器,用于根据action来处理数据,处理后的数据会被仓库重新保存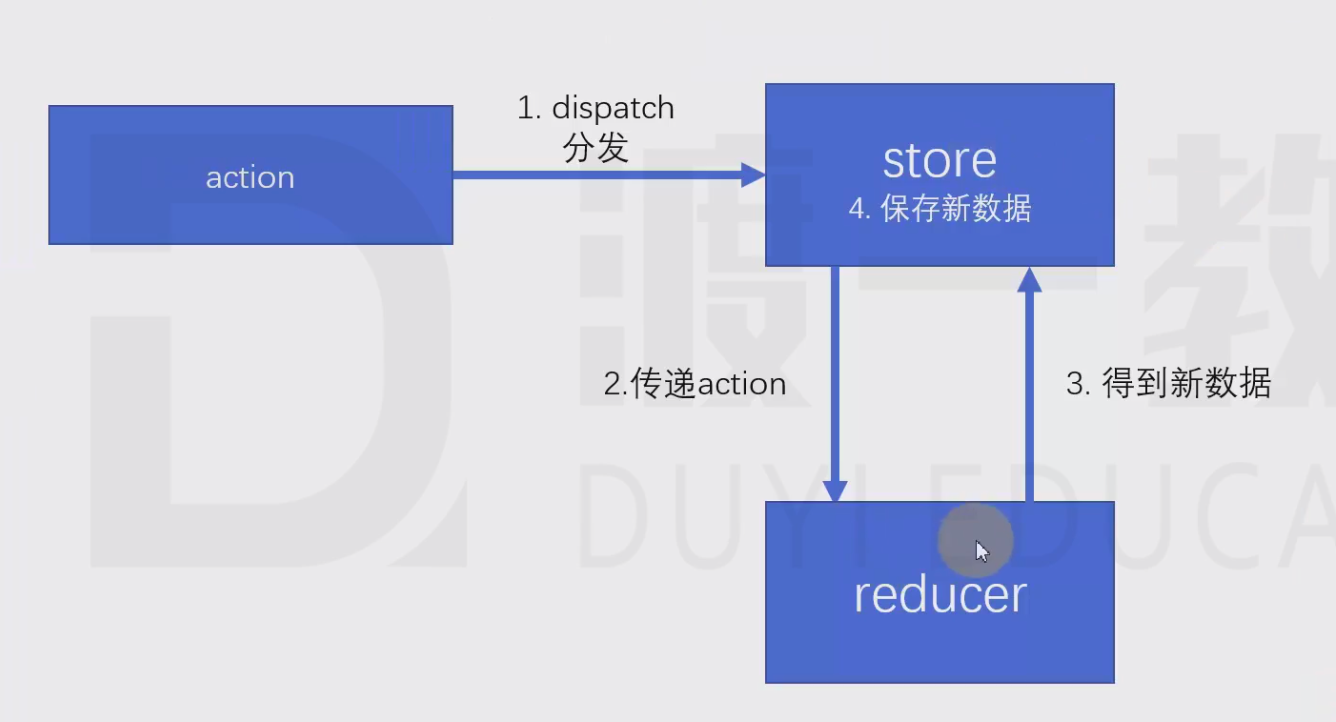
使用Redux管理数据
createStore用于创建一个数据仓库,第一个参数是reducer,第二个参数是数据默认值,返回一个对象
import { createStore } from 'redux';function reducer(state, action){if(action.type === 'increase') {return state+1;}else if(action.type === 'decrease') {return state-1;}return state;}const store = createStore(reducer, 10);//这个数据的默认值是10const action = {type: 'increase',payload: {},//这个示例中不需要}store.getState();//得到当前数据10store.dispatch(action);//向仓库分发一个actionstore.getState();//得到最新数据11
Action—指派任务
- action必须是一个plain-object(平面对象),可理解为是一个对象字面量。不能有什么乱七八糟的继承链
- 它的proto指向Object.prototype
- 通常,使用payload属性表示附加数据(没有强制要求)
- action中必须要有type属性,该属性用于描述操作的类型
- 但是,没有对type的类型作出要求
- 在大型项目中,由于操作类型非常多,为了避免硬编码(hard code,死板的,一次性的变量。即 将可变变量用一个固定数值表示,这样不利于后续更改。),会将action的类型存放到一个单独的文件中导出(样板代码)
- 但是名称多了可能冲突,所以最好别用字符串,用Symbol(‘whatever’);
- 为了方便传递action,通常会使用action创建函数(action creator)来创建一个action
- action创建函数应为无副作用的纯函数 — 唯一的输入对应唯一的输出。
- 不能以任何形式改动参数
- 不可以有异步
- 不可以对外部环境中的数据造成影响
- action创建函数应为无副作用的纯函数 — 唯一的输入对应唯一的输出。
为了方便利用action创建函数来分发action,redux提供了一个函数 bindActionCreators,该函数用于增强action创建函数的功能,使它不仅可以创建action,并且创建后会自动完成分发。
一个数据仓库,有且仅有一个reducer,并且通常情况下,一个工程只有一个仓库,因此,通常,一个系统,只有一个reducer!!
- 为了方便管理,通常会将reducer放到单独的文件中。
- reducer被调用的时机
- 通过store.dispatch分发了一个action,此时,会调用reducer
- 当创建一个store的时候,会调用一次reducer。为什么?—>初始化,type是”@@redux/INIT……”
- 可以利用这一点,用reducer初始化状态
- 创建仓库的时候,不设置默认状态
- 给reducer的第一个参数state设置默认值
- reducer内部通常使用switch-case来判断type值
- reducer必须是一个没有副作用的纯函数(虽然redux没有规定,但在公司实际工作中一定是这样)
- 为什么需要纯函数
- 有利于测试和调试
- 有利于换元数据
- 有利于将来和react结合时的优化
- 具体要求。同上 — action创建函数里说明的内容
- 为什么需要纯函数
- ⭐️⭐️由于在大中型项目中,数据结构、操作等都很复杂,因此需要对reducer进行细分。就是怕reducer太过庞大
- 就是按业务逻辑模块再把子reducer函数抽到单独的文件里导入导出…
- 比如这两个模块:当前所有用户、当前登录的用户
- 最后再将每个子reducer合并到根reducer
- 就是按业务逻辑模块再把子reducer函数抽到单独的文件里导入导出…
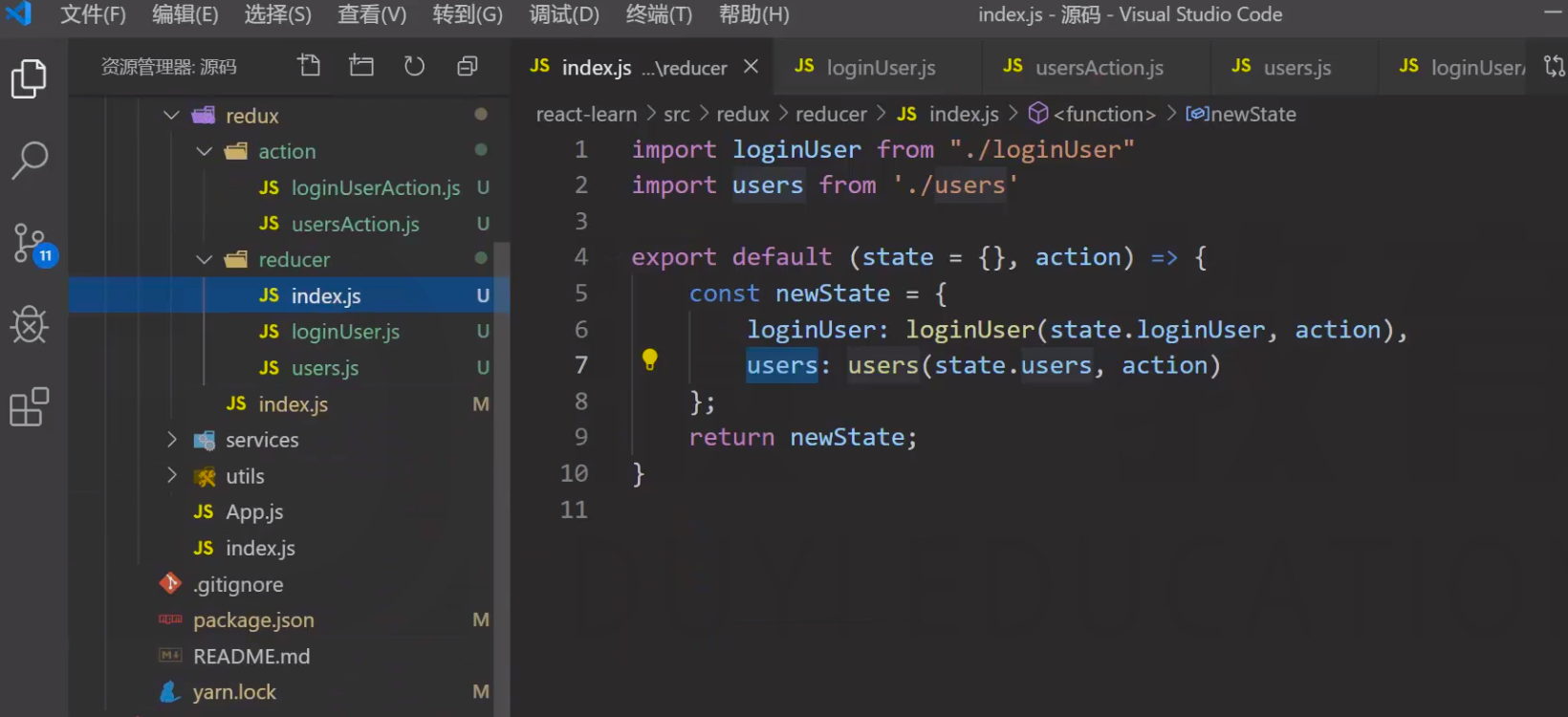
state中loginUser和users的数据分别是调用 子reducer — loginUser、users的结果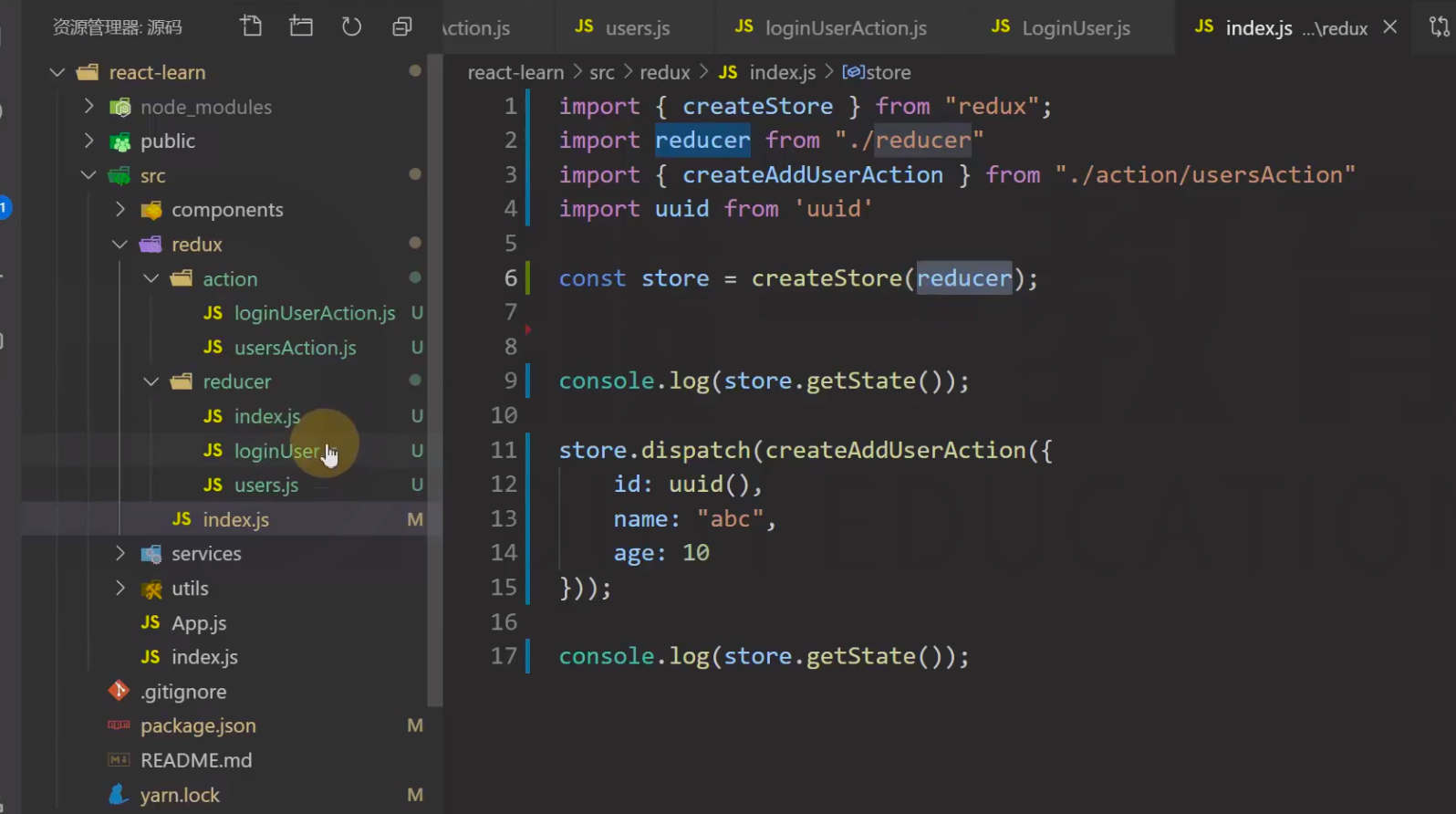
ps:可以安装一个库 uuid,调用uuid()即可很方便的生成一个唯一id;安装immutable可以得到克隆的新数据
- redux提供了更加方便的方法,帮助我们合并reducers — combineReducers
合并reducers得到一个新的reducer,新reducer管理一个对象,该对象中每个属性会交给对应reducer管理

- dispatch:分发一个action
- getState:得到仓库中当前的状态
- replaceReducer:一般用不到,特殊情况下,我们可能想要将当前reducer替换为新的reducer
- subscribe:主要用于监听状态发生变化,传入一个回调函数,该函数会在分发action完之后运行
- 可以多次注册监听函数;常配合react刷新组件使用
- 该函数会返回一个函数,调用则取消监听
- Symbol(observable):私有成员,内部方法
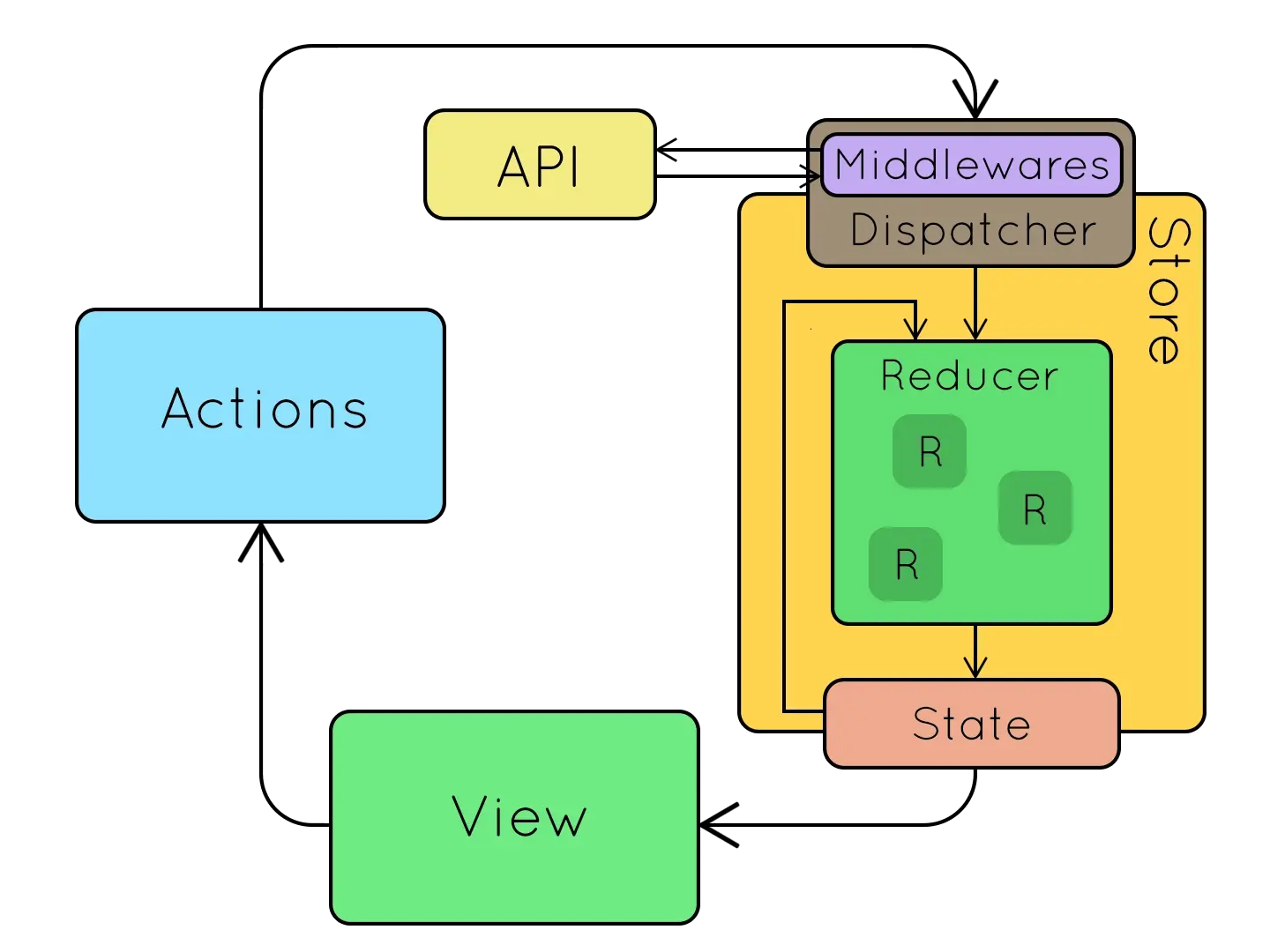
Redux中间件—Middleware
也方便做日志记录。
【中间件:类似于插件,可以在不影响原本功能的基础上,并且不改动原本代码的基础上,对其功能进行增强】。在Redux中,中间件主要用于增强dispatch函数。
- 比如,以前仓库的监听器函数里只能拿到新状态,拿不到之前的状态以及是哪个action触发的,此时就需要中间件来增强dispatch的功能
可以直接修改dispatch实现函数,增强功能。但这样不好,等于修改了源码层面,影响面太广,一般不这样做
模拟redux中间件的做法
实现Redux中间件的基本原理,是更改仓库中的dispatch函数。
核心思想就是不断的包裹一层 —— 洋葱模型,一层一层的剥开我的心~:
- 创建仓库,并保留原本dispatch函数
- 覆盖该仓库的dispatch函数,增强功能,并在内部适当时机的调用原本的dispatch函数
- 如果多个中间件,就不断的保存上一个dispatch函数,并覆盖、调用;形成一个链式调用结构
- 虽然功能都可以完成,但是我们这么写太low,中间件多了,写的不方便。
redux中间件真实做法
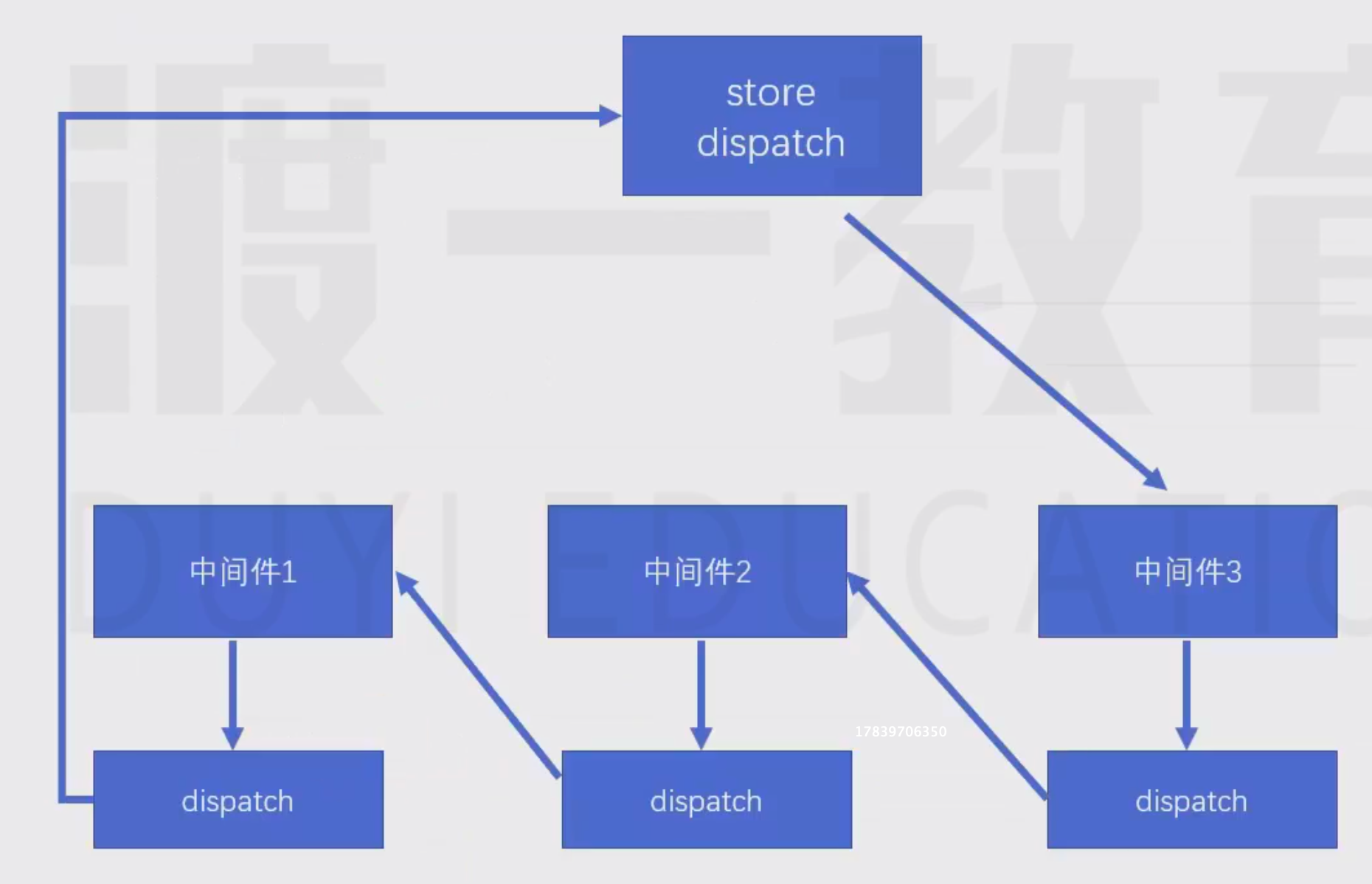
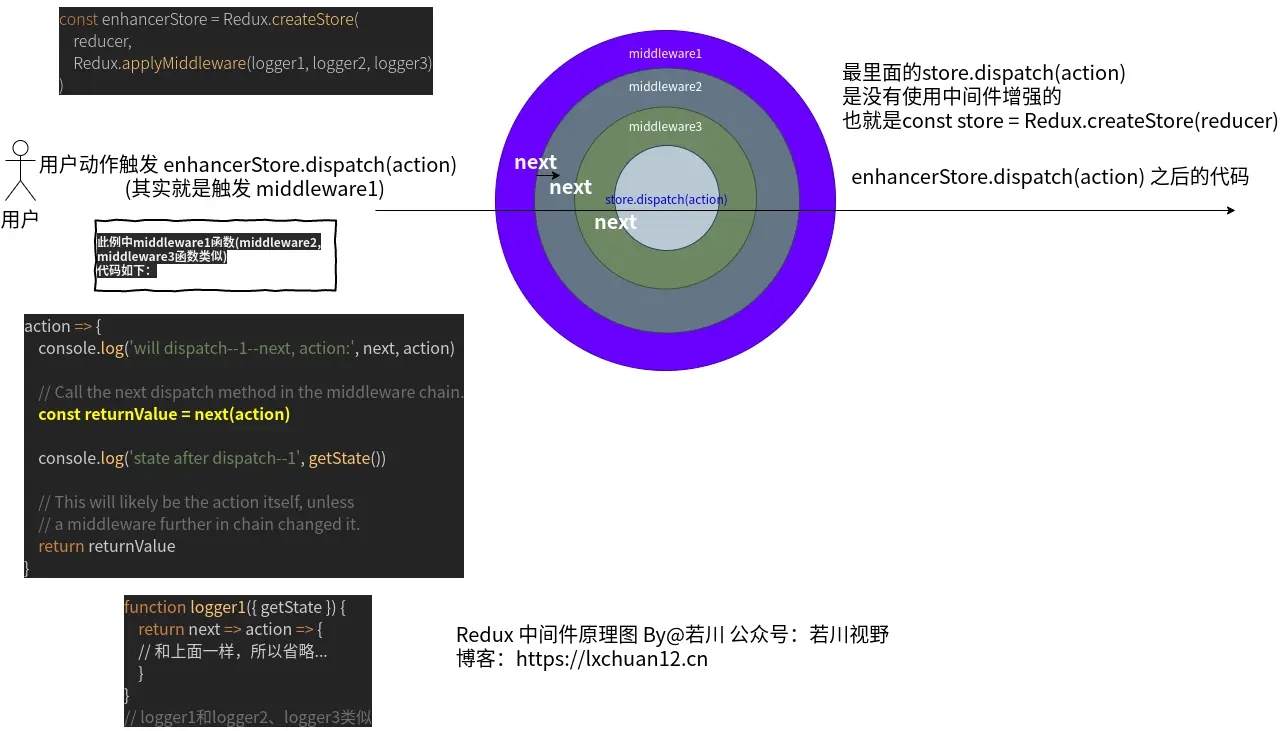
最内圈就是原始dispatch函数
中间件本身是一个函数,该函数接收一个store参数,表示创建的仓库,该仓库目前并非最后的完整仓库对象,仅包含原getState、dispatch函数。该函数运行的时机,是在仓库创建之后运行。
- 由于创建仓库后需要自动运行设置的中间件函数,因此,需要在创建仓库时就告诉仓库有哪些中间件
- 应用中间件需要调用applyMiddleware函数,将其返回结果作为createStore的第二个或第三个参数(redux能区分)
- applyMiddleware函数,用于记录有哪些中间件,它会返回一个函数
- 该函数接收的参数就是创建仓库的方法
- 它会返回一个函数接收reducer和默认值,用于创建仓库
- 该函数接收的参数就是创建仓库的方法
- 方式一:const store = createStore(reducer, applyMiddleware(logger1, logger2);
- 方式二:const store = applyMiddleware(logger1, logger2)(createStore)(reducer, 默认值);
- 它的每个参数就是一个中间件函数
- 看上图洋葱模型
- applyMiddleware函数,用于记录有哪些中间件,它会返回一个函数
- 中间件函数必须返回一个dispatch创建函数
- 该dispatch创建函数接收一个参数:dispatch函数—注册顺序中的后一个dispatch
- 该dispatch创建函数返回一个函数—增强功能后最终要应用的dispatch函数(接收一个参数action),但在其内部要调用上述那个后dispatch
- 中间件函数的参数store中的dispatch是原始dispatch,而它返回的dispatch创建函数中的参数dispatch是上一个dispatch。记住这点,这是不一样的!

可以用箭头函数简写: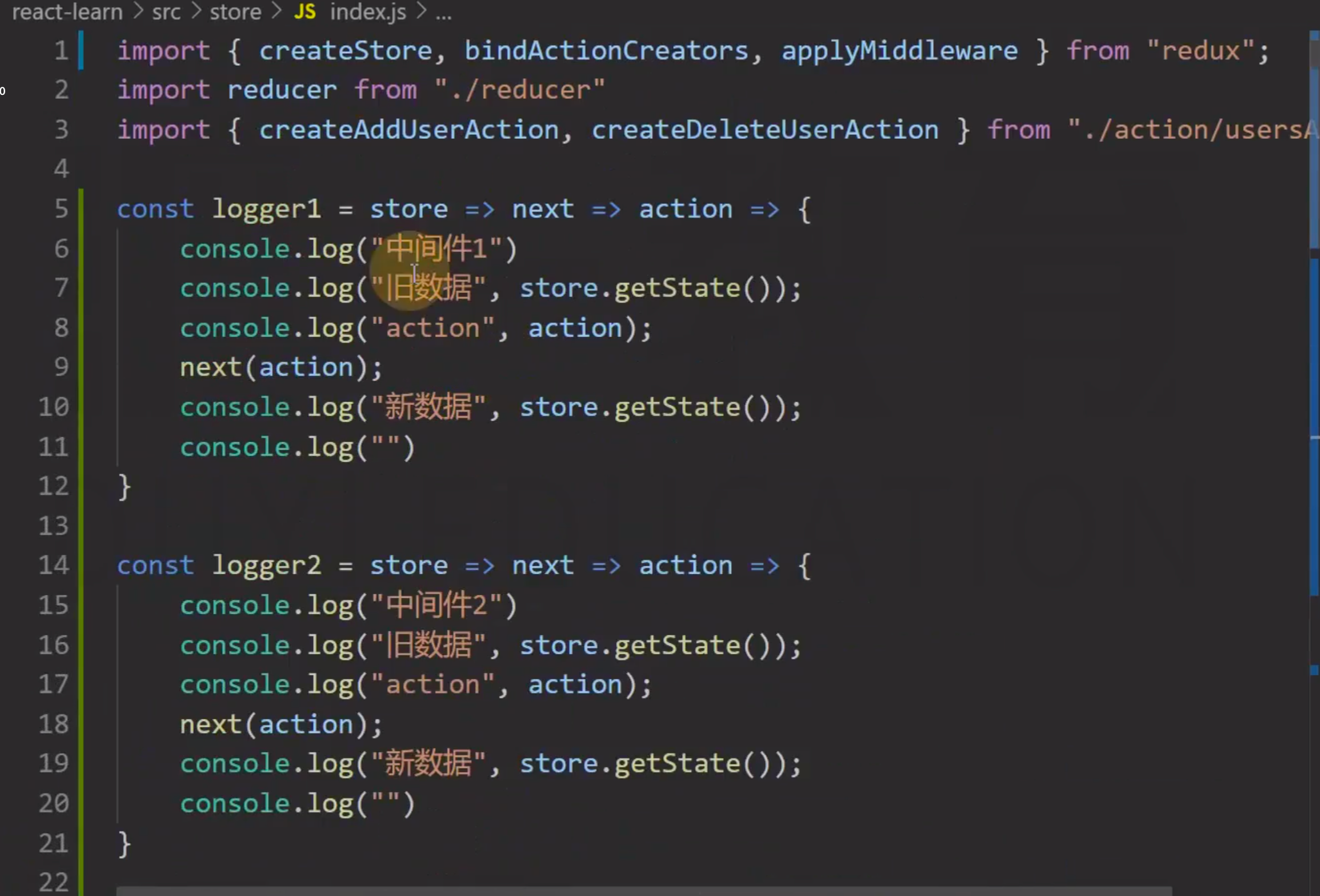
第一层用于接收仓库,第二层用于接收后面注册的中间件函数
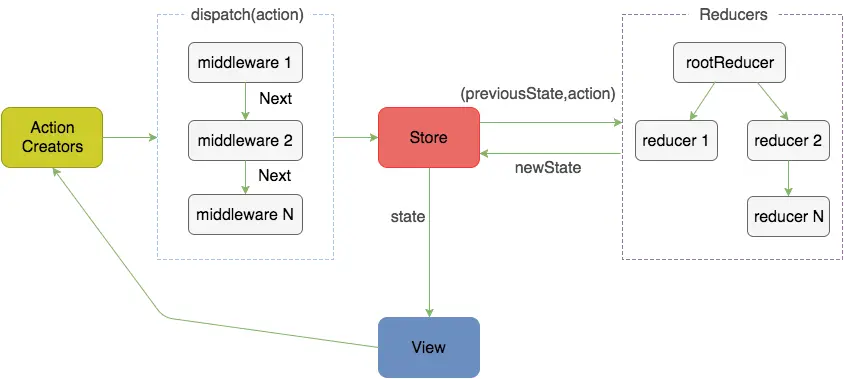
分发action时dispatch的调用顺序为:dispatch1 -> dispatch2 -> 原始dispatch -> dispatch2 -> dispatch1
形成这样是因为redux源码中,在compose中return funcs.reduce((a, b) => (…args) => a(b(…args)));
ps:这里有个小技巧如果需要异步,直接funcs.reduce((a, b)=>async (…args)=> a(await b(…args)));
最终的返回值就是最终的dispatch,func是一个数组,每个元素都是一个dispatch函数。
Redux工作流程图

若有收获,就点个赞吧
0 人点赞
