纵览 

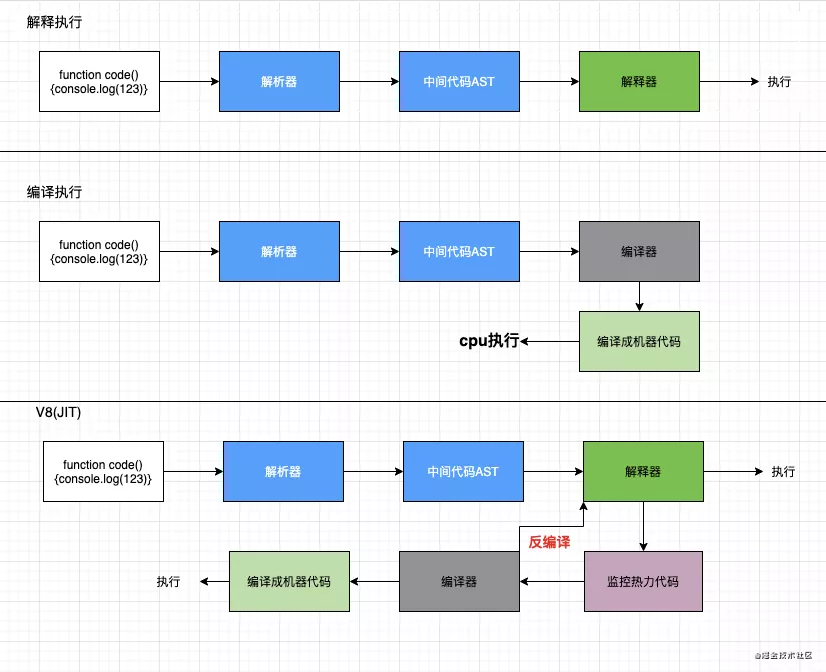 中间代码AST即为字节码!!此处机器码其实是汇编码。
中间代码AST即为字节码!!此处机器码其实是汇编码。
即时编译(Just-in-time compilation):长话短说,先走解释执行,在解释器对代码进行监控,对重复执行频率高的代码打上 tag,成为可优化的热点代码,之后流向编译执行的模式,对可优化的代码进行一个编译转成二进制机器码并存储,之后就地复用二进制码减少解释器和机器的压力再执行。
function add(a, b) {return a + b}for (let i = 0; i < 100; i++) {// 结构稳定类型稳定,打tag走编译执行二进制入内存优化add(250, 520)}// 我曹,吃了动态类型的亏啊,返回给解释器,我不接这个锅add(250, '520')
为什么要用字节码呢?
是编译过程中做了一个空间(编译执行)和时间(解释执行)上的权衡的中间代码(既要快,又要小)。
怎么做的呢?
- 字节码允许被解释器直接执行。
- 热力代码被优化,从字节码编译成二进制代码执行(字节码与二进制码的执行过程接近,所以编译能提效)。
- 因为移动端兴起,所以采用了比二进制占用空间小的字节码,这样可以被浏览器缓存(内存),被机器缓存(硬盘)。
- 字节码被解释器编译的速度更快增加了启动速度,同时直接执行只不过执行速度比机器代码慢。
- 不同 cpu 处理器因平台不同所以机器代码不同,字节码与机器代码执行流程接近因此降低了编译器将字节码转换机器代码的时间。
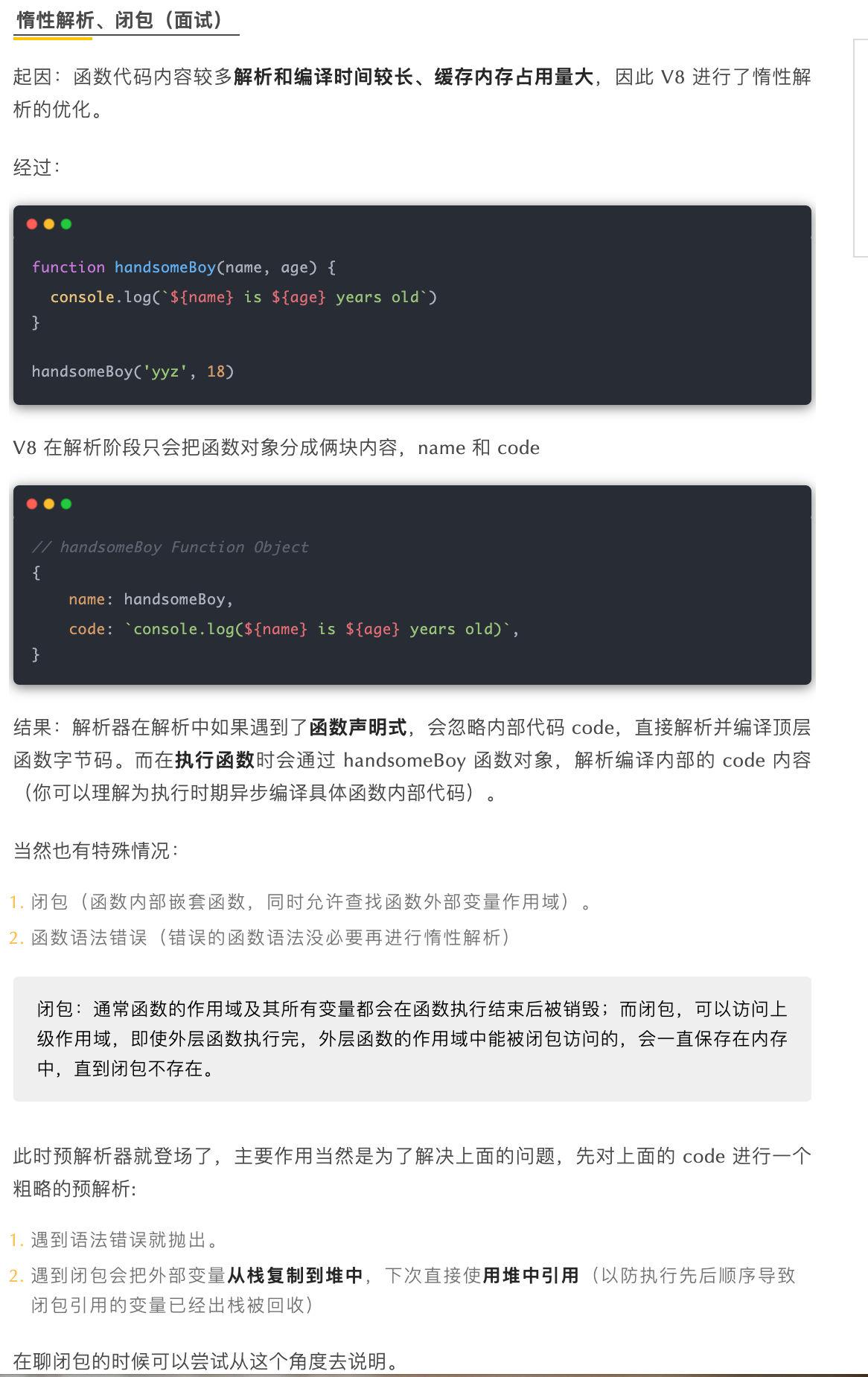
function yyz() {this['A'] = 'A'this[0] = '2'this['1'] = 3this[2] = '4'this['handsome'] = 5this[7.7] = 7.7this[888] = '6'this['B'] = 'B'}const handsomeBoy = new yyz()for (let key in handsomeBoy) {console.log(`${key}:${handsomeBoy[key]}`)}
在 V8 的对象中有分俩种属性,排序属性以(elements)及常规属性(properties),数字被分类为排序属性,字符串属性就被称为常规属性,其中排序属性按照数字大小升序而常规属性按照创建升序,执行顺序也是先查 elements 再查找 properties。
ps.图中对象内属性没拉满(达到上限)所以没有 properties,下文会说
堆空间和栈空间
在Chrome中只要打开一个渲染进程,渲染进程便会初始化V8,同时初始化堆栈空间。栈空间是用来管理JavaScript的函数调用的。没调用一个函数,就把该函数压入栈中,执行中又遇到函数,就再压入栈中,执行完后就函数出栈,直到所有函数调用完成,栈也就被清空了。
栈空间是一个连续的空间,在栈中每个元素的地址都是固定的,因此栈空间的查找效率非常高,但是通常在内存中很难分配到一块很大的连续空间,所以V8对栈空间的大小做了限制,如果函数调用过深,就可能会栈溢出。
堆空间是一种树形的存储结构,用来存储引用类型的离散的数据。堆空间可以存放很多数据,但是读取速度会比较慢。
function add (x, y) { return x + y } function main () { let num1 = 2 let num2 = 3 let num3 = add(num1, num2) let data = { sum: num3 } return data } main() 复制代码
下面我来解释一下,如上代码的执行过程:
- 创建main函数的栈帧指针
- 在栈中将num1初始化num1 = 2
- 在栈中将num2初始化num2 = 3
- 保存main函数的栈顶指针
- 创建add函数的栈帧指针
- 在栈中将x初始化x = 2
- 在栈中将y初始化y = 2
- 将x,y相加的值保存在寄存器中
- 销毁add函数
- 复活main函数的栈顶指针
- 在栈中将num3初始化num3 = 寄存器中的add函数的返回值
- 在堆空间新建对象,返回对象地址赋值给data
- 将返回值写入寄存器
- 销毁main函数
如下图,就表示一个栈:

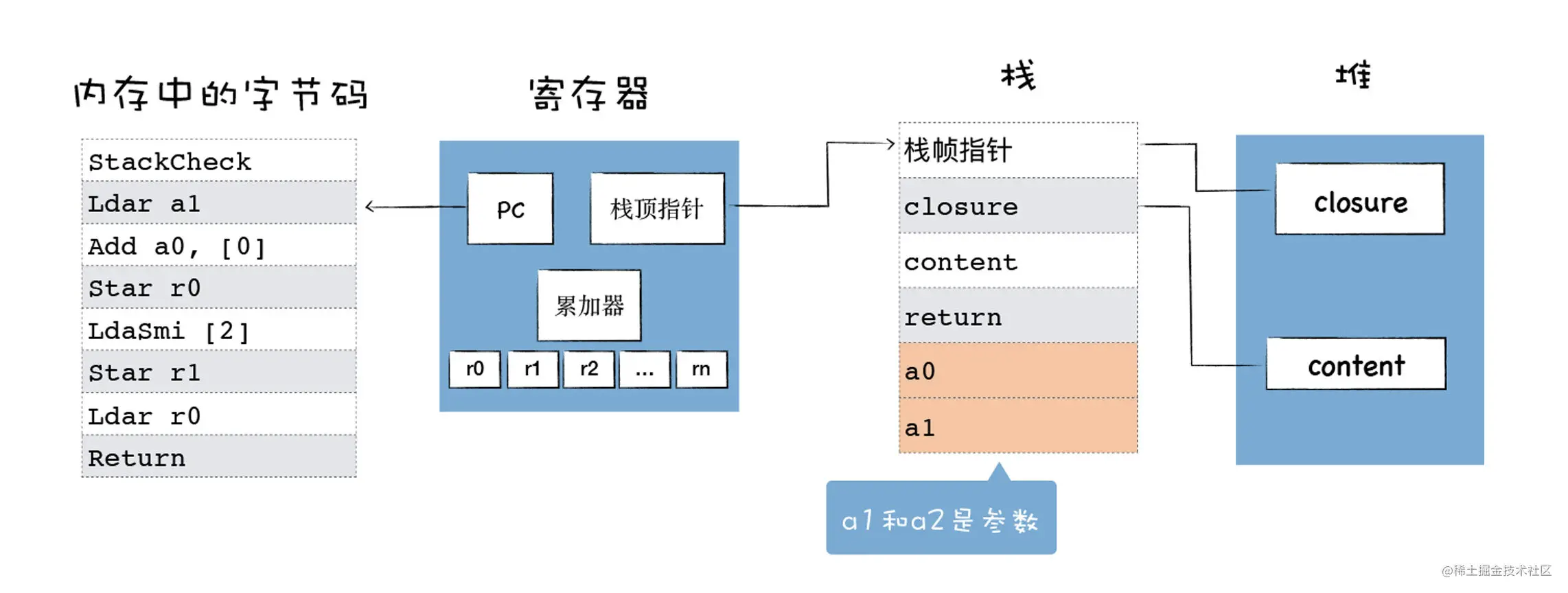
如下图是寄存器和字节码堆栈的关系:
- 使用内存中的一块区域来存放字节码
- 使用通用寄存器r0,r1…这些寄存器来存放一些中间数据
- PC寄存器用来指向下一条要执行的字节码
- 栈顶寄存器来指向栈顶的位置
- 累加器是一个非常特殊的寄存器,用来保存中间结果。比如:函数return结束当前函数的执行,并将控制权回传给调用方,返回的值是累加器中的值。
全局执行上下文
执行上下文中主要包含三部分,变量环境、词法环境和this关键字。比如在浏览器环境中,全局执行上下文包含了window对象,还有指向window的this关键字,另外还有一些web api函数,setTimeout、XMLHttpRequest等。而词法环境中,则包含了let、const等变量内容。
构造事件循环系统
对于事件循环系统,因为所有的任务都是运行在主线程的,在浏览器的页面中,V8会和页面共用主线程,共用消息队列,所以如果一个函数执行过久,会影响页面的交互性能。
机器代码:CPU是如何操作二进制代码的
看一段代码:
int main() { int x = 1; int y = 2; int z = x + y; return z; } 复制代码
如上代码会被编译程汇编代码,以及二进制代码。 如下图,栈的存储是连续的空间,通过指针与寄存器实现了函数的入栈出栈:
如下图,栈的存储是连续的空间,通过指针与寄存器实现了函数的入栈出栈: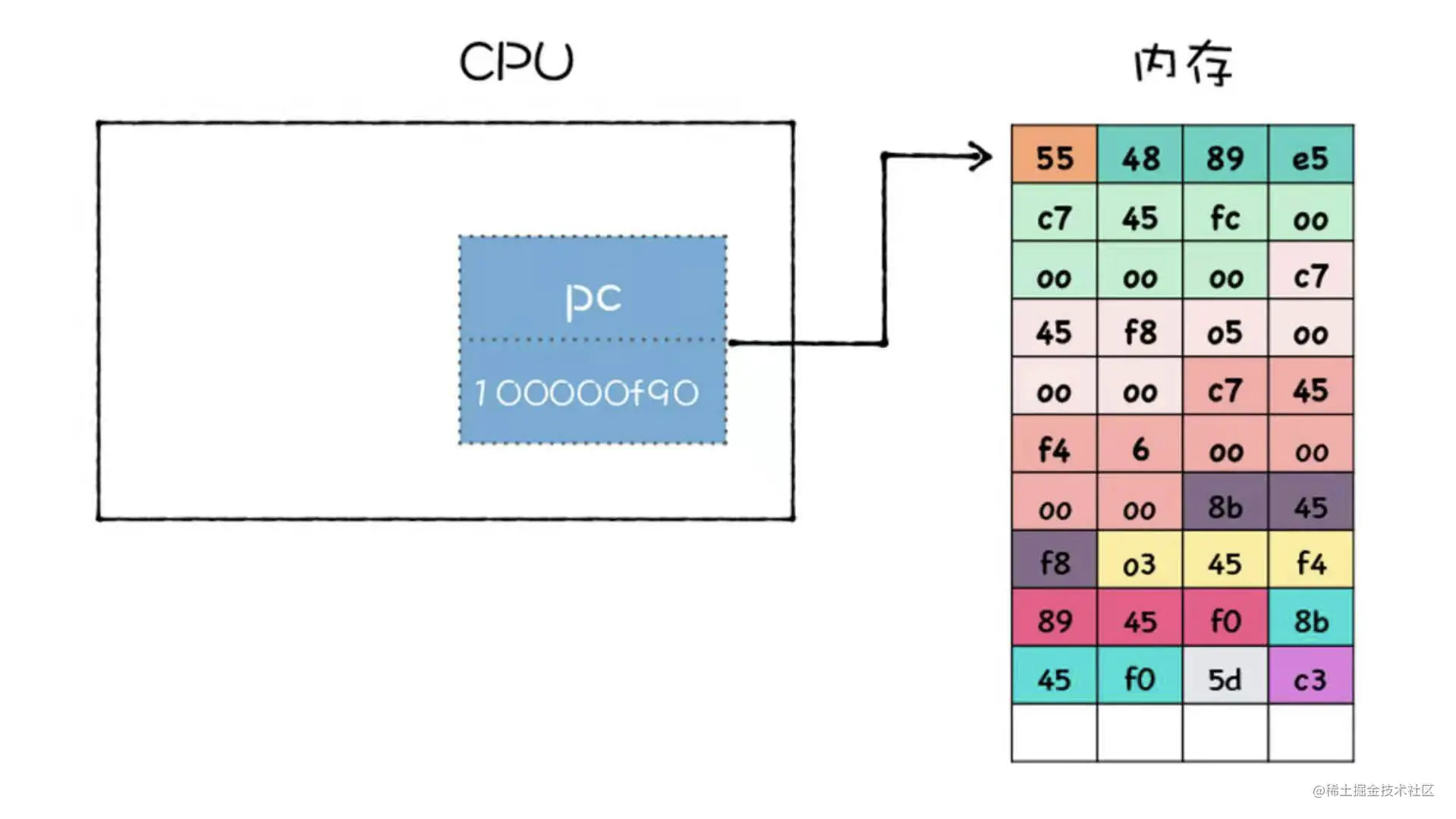
惰性解析
所谓惰性解释是指,解析器在解析过程中,如果遇到函数声明,那么会跳过函数内部的代码,并不会为其生成AST和字节码,而只生成一个函数对象。函数对象包含name,和code属性。name就是函数的名称,code是函数的源码。
function foo(a, b) { var d = 100 var f = 10 return d + f + a + b } var a = 1 var c = 4 foo(1, 5) 复制代码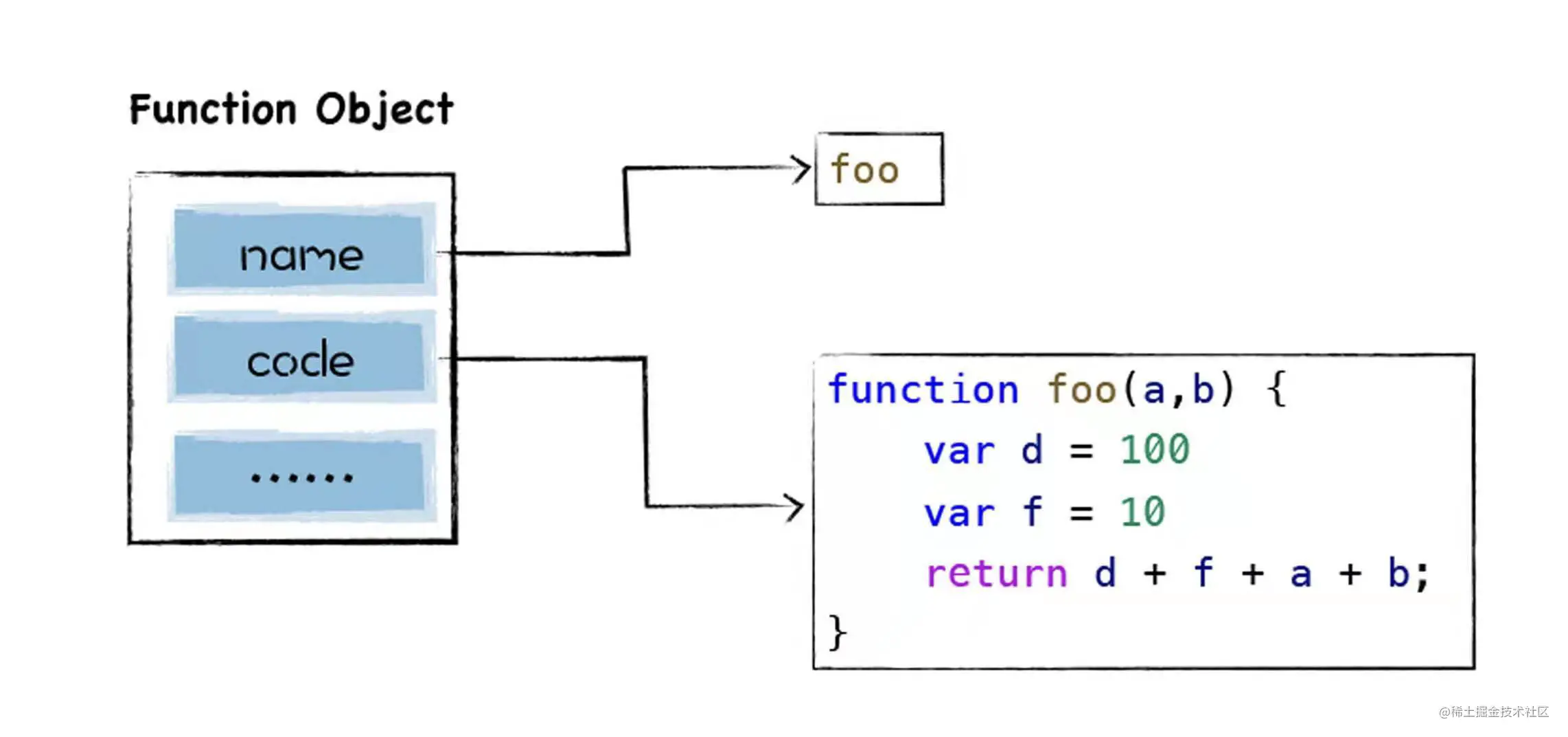 最终生成的是顶层代码的抽象语法数:
最终生成的是顶层代码的抽象语法数: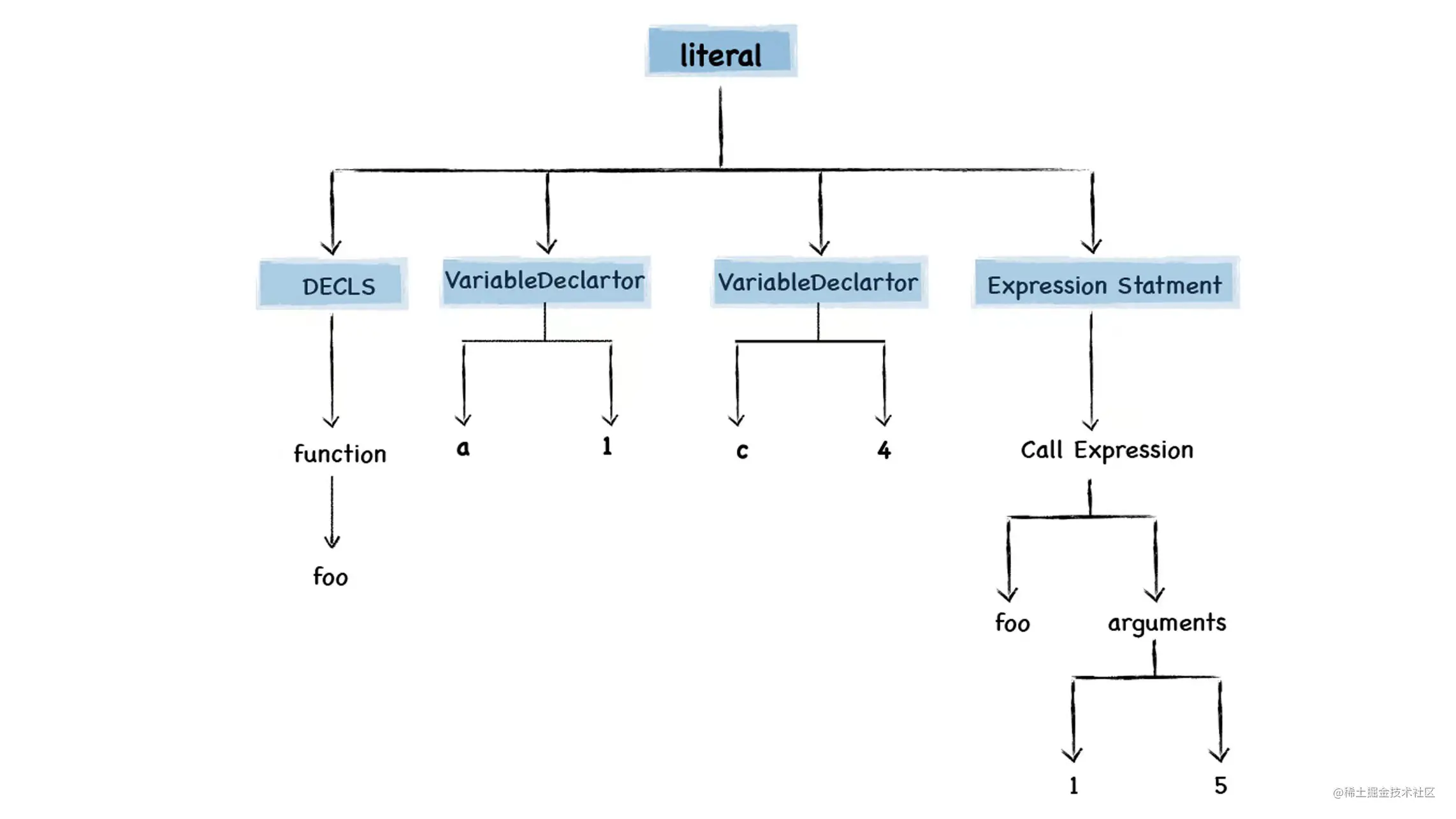
当遇到闭包的状况时,在执行函数的阶段,虽然不会解析和执行其内部函数,但是预解析器还是要判断其内部函数是否引用了其变量。
预解析器会判断语法错误,和检查函数内部是否引用的外部变量。如果引用了外部的变量,预解析器会将栈中的变量复制到堆中,在下次执行到该函数的时候,直接使用堆中的引用,这样就解决了闭包外部变量不能销毁的问题。
隐藏类
在V8中,隐藏类又称为map,每个对象都有一个map属性,其值指向内存中的隐藏类。隐藏类描述了对象的属性布局,主要包括了属性名称和每个属性所对应的偏移量。
var point = {x=200,y=400} 复制代码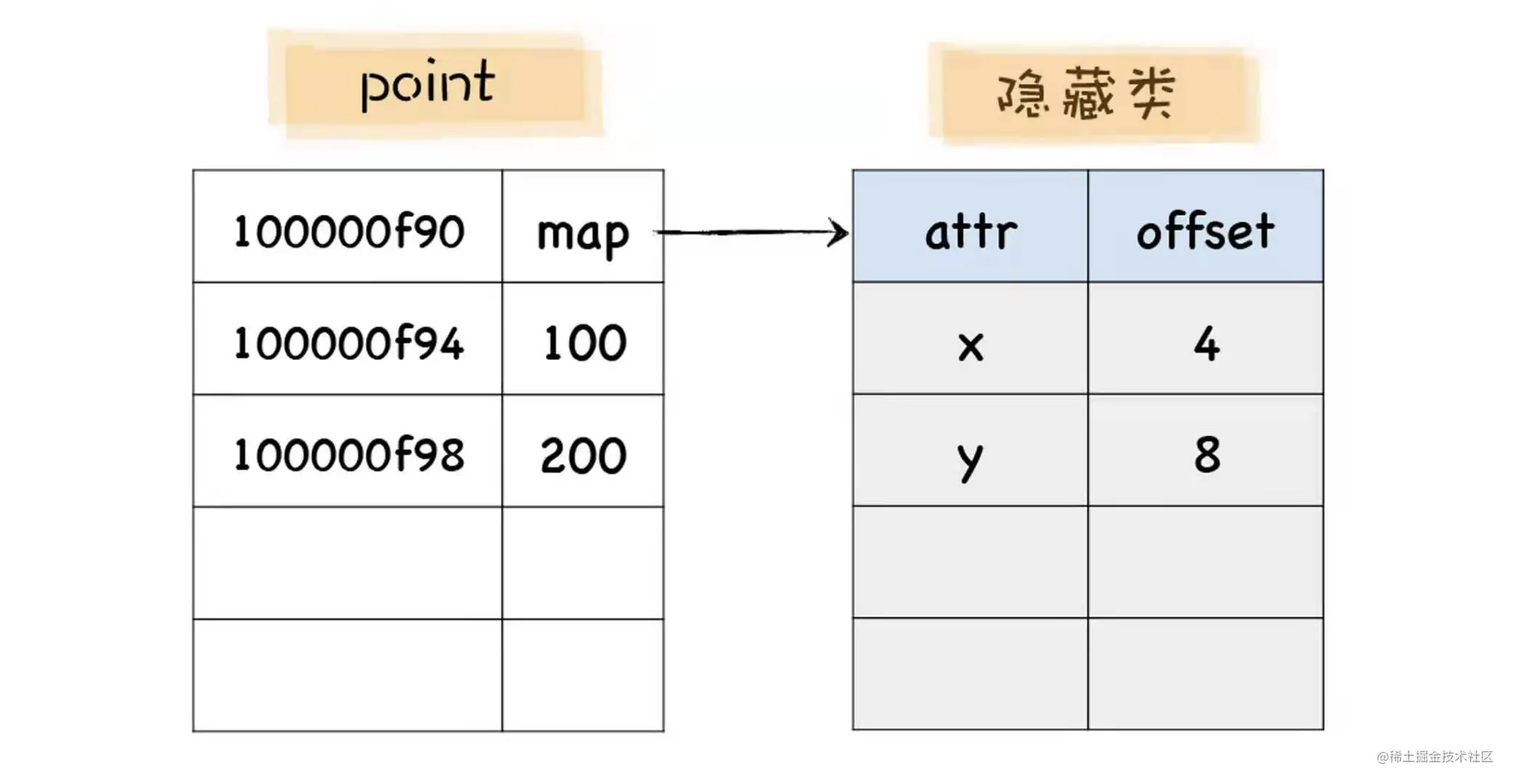 有了map之后,当你再次使用point.x访问属性x时,V8会查询point的map中x属性相对于point对象的偏移量,然后将point对象的起始位置加上偏移量,就得到了x属性的值在内存中的位置,省去了一个比较复杂的查找过程。
有了map之后,当你再次使用point.x访问属性x时,V8会查询point的map中x属性相对于point对象的偏移量,然后将point对象的起始位置加上偏移量,就得到了x属性的值在内存中的位置,省去了一个比较复杂的查找过程。
需要注意的是:
- 结构相同值不同的对象可以共用同一个隐藏类
- 如果对象结构发生变化,隐藏类就要重新创建,这会影响V8的执行效率
所以,在写代码时,要注意以下几点:
- 使用字面量初始化对象时,要保证属性的顺序是一致的。因为key初始化的顺序不一样,也会导致结构不一样。
- 尽量使用字面量一次性初始化完整的对象属性,不要一个一个添加。
- 尽量避免使用delete方法删除属性。
// bad var point = {x=200,y=400} var point2 = {y=200,x=400} // bad var x = {} x.a = 1 x.b = 2 复制代码
OSR
“执行引擎有多个不同优化程度的层级,一个函数正在执行的过程中可以在不同优化层级之间迁移”就是OSR的重点。
CSS文件加载问题


若有收获,就点个赞吧
0 人点赞
