- 1.eBPF Host-Routing 官网描述 ```properties kubeadm init —kubernetes-version=v1.20.5 —image-repository registry.aliyuncs.com/google_containers —pod-network-cidr=10.244.0.0/16 —service-cidr=10.96.0.0/12 —skip-phases=addon/kube-proxy —ignore-preflight-errors=Swap
[root@dev1 ~]# kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
dev1 Ready control-plane,master 28d v1.20.5 192.168.2.31
https://docs.cilium.io/en/latest/operations/performance/tuning/#ebpf-host-routing eBPF Host-Routing Even when network routing is performed by Cilium using eBPF, by default network packets still traverse some parts of the regular network stack of the node. This ensures that all packets still traverse through all of the iptables hooks in case you depend on them. However, they add significant overhead. For exact numbers from our test environment, see TCP Throughput (TCP_STREAM) and compare the results for “Cilium” and “Cilium (legacy host-routing)”.
We introduced eBPF-based host-routing in Cilium 1.9 to fully bypass iptables and the upper host stack, and to achieve a faster network namespace switch compared to regular veth device operation. This option is automatically enabled if your kernel supports it. To validate whether your installation is running with eBPF host-routing, run cilium status in any of the Cilium pods and look for the line reporting the status for “Host Routing” which should state “BPF”.
[Requirements:] Kernel >= 5.10 Direct-routing configuration or tunneling eBPF-based kube-proxy replacement eBPF-based masquerading [——————-]
官网中只有这个简单的描述,结合以前的学习包袱,使得一直在查找配合上找突破口,而使得一直没有什么进展。且eBPF 的host-Routing的能力是非常有助于我们理解一些社区上的文章的。通常情况下,目前写的较为明白的博客通常已经是建立在对Cilium或是BPF较为熟悉的人员,所以有些许的“预设”就没有在文章中提出,实际上对于新手来阅读这些文档的时候,有的对象和逻辑实际上看起来非常的费劲。这也使得学习上收到比较大的阻碍。比如这里的eBPF host-Routing的能力。
- [x] **2.eBPF 能力介绍[_bpf_redirect_neigh() - bpf_redirect_peer()_]:**
```properties
https://cilium.io/blog/2020/11/10/cilium-19
Virtual Ethernet Device Optimization with eBPF
Contributed by Daniel Borkmann
During the course of the 1.9 development cycle, we have performed a number of eBPF datapath performance optimizations. One that stands out in particular is the improvement of raw performance for network-namespaced Pods connected to the host namespace through a veth device pair, as is the default operation mode in Cilium. When Cilium is used in direct routing mode, traffic that is ingressing to or egressing from Pods is passed up the network stack inside the host namespace in order to let the routing layer perform the forwarding. Historically, this was a necessity mainly for letting the netfilter subsystem masquerade egressing Pod traffic. This masquerading also required the connection tracker to see traffic from both directions in order to avoid drops from invalid connections (asymmetric visibility of traffic in the connection tracker would apply here, too).
Thanks to recent advances of Cilium's datapath in prior releases, we are able to perform masquerading natively in eBPF code. Given that, in the course of 1.9 development, we have extended the eBPF networking functionality for the v5.10 kernel (part1 and part2) in order for Cilium to handle forwarding right in the tc eBPF layer instead of having to push packets up the host stack. This results in significant gains in single stream throughput as well as significant reductions in latency for request/response-type workloads. The two helpers bpf_redirect_peer() and bpf_redirect_neigh() that we have added to the Linux kernel as well as Cilium 1.9 code base enable the new packet handling in the host namespace.
The bpf_redirect_peer() enables switching network namespaces from the ingress of the NIC to the ingress of the Pod without a software interrupt rescheduling point when traversing the network namespace. The physical NIC can thus push packets up the stack into the application's socket residing in a different Pod namespace in one go. This also leads to quicker application wake-up for picking up the received data. Similarly, rescheduling points are reduced from 2 to 1 for local Pod-to-Pod communication resulting in better latency there as well.
The bpf_redirect_neigh() handles a Pod's egress traffic by injecting the traffic into the Linux kernel's neighboring subsystem, allowing to find the next hop and resolving layer 2 addresses for the network packet. Performing the forwarding only in tc eBPF layer and not pushing the packet further up the networking stack also provides proper back pressure for the TCP stack and feedback for TCP's TSQ (TCP Small Queues) mechanism to reduce potential excessive queueing of TCP packets. That is, feedback is given to the TCP stack that the packet has left the node instead of inaccurately providing it too early when it would be pushed up to the host stack for routing. This is now possible because the packet's socket association can be kept intact when it is passed down into the NIC driver.
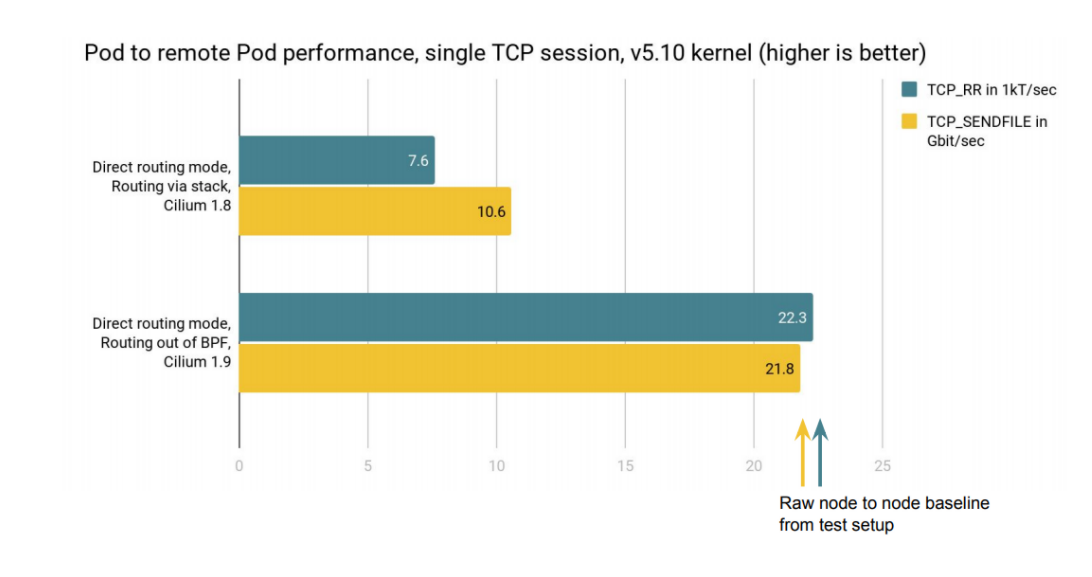
As can be seen from initial results, the single stream TCP throughput for a Pod to remote Pod session under direct routing doubles in throughput for the nodes under test when using Cilium 1.9's eBPF extensions on a v5.10 kernel as opposed to having both directions handled by the host stack's forwarding. Similarly, the TCP request/response transaction performance improved by almost 3x for the Pods under test when avoiding the host stack.
The underlying kernel is automatically probed from Cilium by default and if available for the configuration the eBPF kernel extensions will be transparently enabled for new deployments. The latter requires the use of Cilium's eBPF kube-proxy replacement as well as eBPF-based masquerading given netfilter in the host namespace is then bypassed. This behavior can also be opted-out through the Helm bpf.hostRouting option.
[x] 2.1:bfp_redirect_peer()
The bpf_redirect_peer() enables switching network namespaces from the ingress of the NIC to the ingress of the Pod without a software interrupt rescheduling point when traversing the network namespace. The physical NIC can thus push packets up the stack into the application's socket residing in a different Pod namespace in one go. This also leads to quicker application wake-up for picking up the received data. Similarly, rescheduling points are reduced from 2 to 1 for local Pod-to-Pod communication resulting in better latency there as well.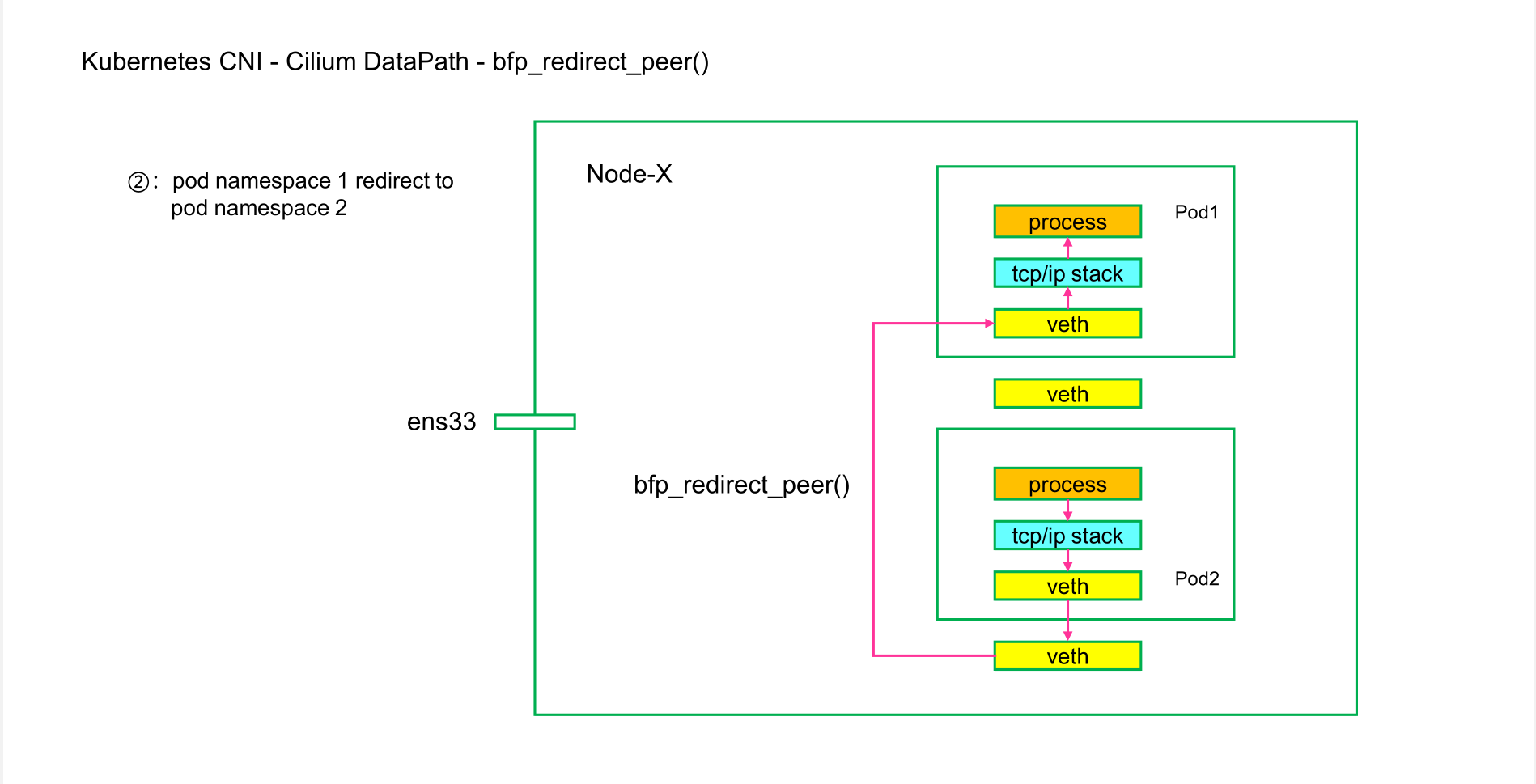
[x] 2.2:bfp_redirect_neigh()
The bpf_redirect_neigh() handles a Pod's egress traffic by injecting the traffic into the Linux kernel's neighboring subsystem, allowing to find the next hop and resolving layer 2 addresses for the network packet. Performing the forwarding only in tc eBPF layer and not pushing the packet further up the networking stack also provides proper back pressure for the TCP stack and feedback for TCP's TSQ (TCP Small Queues) mechanism to reduce potential excessive queueing of TCP packets. That is, feedback is given to the TCP stack that the packet has left the node instead of inaccurately providing it too early when it would be pushed up to the host stack for routing. This is now possible because the packet's socket association can be kept intact when it is passed down into the NIC driver.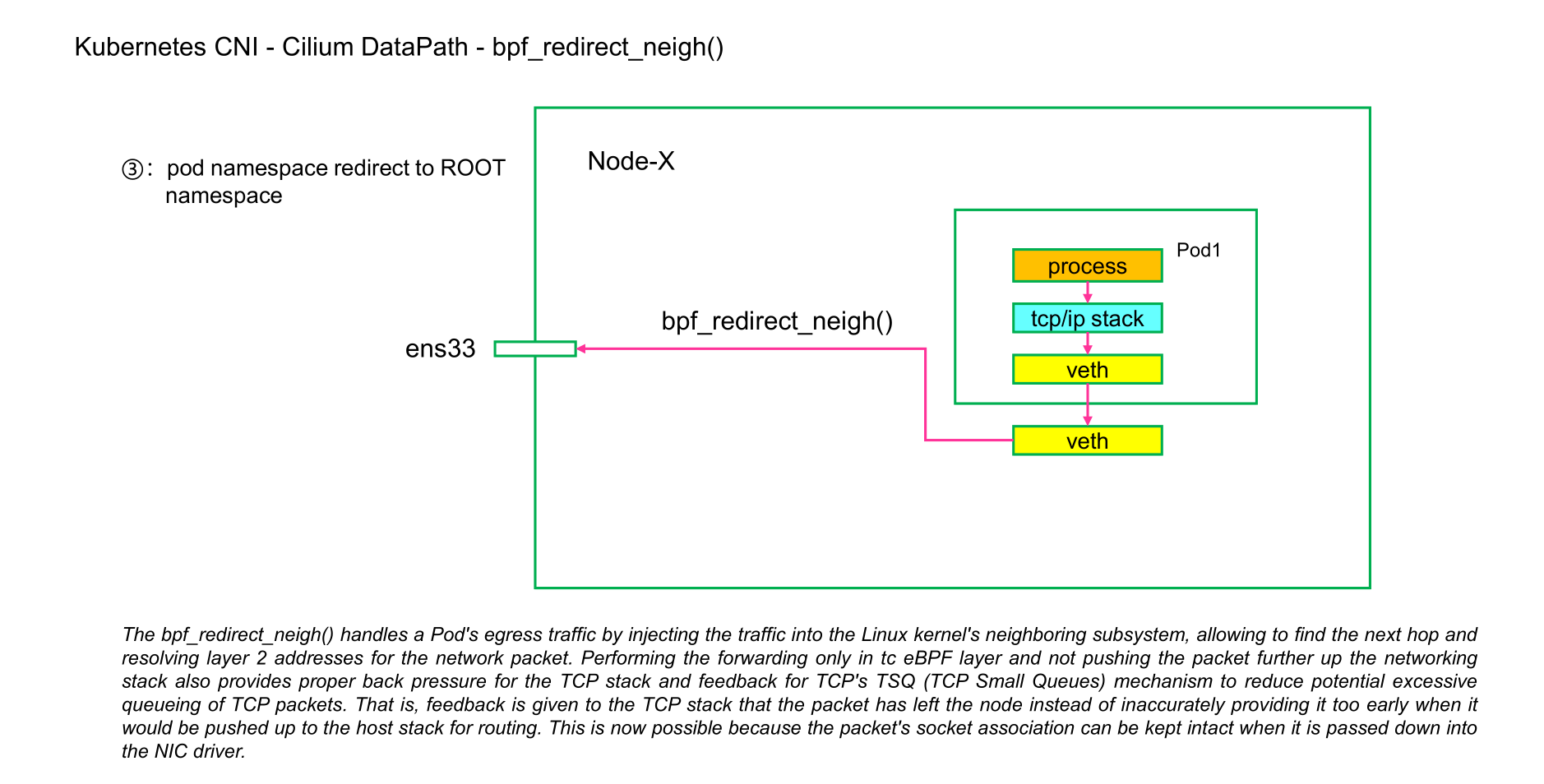
[Breaking the Rules: eBPF Host-Routing] https://cilium.io/blog/2021/05/11/cni-benchmark You may be wondering about the difference between the configurations "Cilium eBPF" and "Cilium eBPF (legacy host-routing)" in the benchmarks before and why the native Cilium eBPF datapath is considerably faster than the legacy host routing. When referring to the Cilium eBPF native datapath, an optimized datapath called eBPF host-routing is in use: eBPF host-routing allows to bypass all of the iptables and upper stack overhead in the host namespace as well as some of the context-switching overhead when traversing through the Virtual Ethernet pairs. Network packets are picked up as early as possible from the network device facing the network and delivered directly into the network namespace of the Kubernetes Pod. On the egress side, the packet still traverses the veth pair, is picked up by eBPF and delivered directly to the external facing network interface. The routing table is consulted directly from eBPF so this optimization is entirely transparent and compatible with any other services running on the system providing route distribution. For information on how to enable this feature, see eBPF Host-Routing in the tuning guide.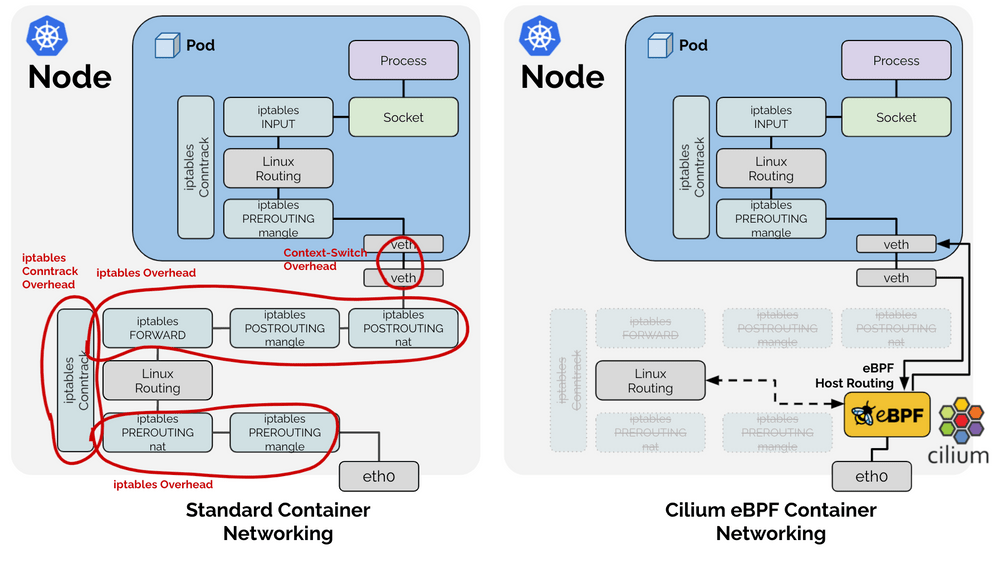
[x] 3.安装ENABLE eBPF host-Routing Mode CIlium ```properties 阅读完成官网中的介绍,我们可以看到只有几个Requirements,实际上我们如果直接采用helm安装Cilium的v1.11.0的版本以后,它对应的cilium status 依然是Leagcy。那么此时就表明我们eBPF的host-Routing并没有enable成功。 那我们怎么来TS呢: 我们的内核是5.15的,并且是基于VXLAN(tunnel)模式。 在Github上找到一个相似的Issue:https://github.com/cilium/cilium/issues/18120 我们尝试查看我们的环境: [root@dev1 kubernetes]# kubectl -nkube-system logs cilium-2h8cc | grep nable-host-legacy-rou level=info msg=” —enable-host-legacy-routing=’false’” subsys=daemon level=info msg=”BPF host routing requires enable-bpf-masquerade. Falling back to legacy host routing (enable-host-legacy-routing=true).” subsys=daemon [root@dev1 kubernetes]# 果然我们的环境中也有此种问题:enable-bpf-masquerade 所以我们需要在Cilium的tempplate的config文件中配置:
enable-bpf-masquerade: “true”
此时我们再查看cilium status:
[root@dev1 kubernetes]# kubectl -nkube-system exec -it cilium-v9n66 bash
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] — [COMMAND] instead.
root@dev3:/home/cilium# cilium status
KVStore: Ok Disabled
Kubernetes: Ok 1.20 (v1.20.5) [linux/amd64]
Kubernetes APIs: [“cilium/v2::CiliumClusterwideNetworkPolicy”, “cilium/v2::CiliumEndpoint”, “cilium/v2::CiliumNetworkPolicy”, “cilium/v2::CiliumNode”, “core/v1::Namespace”, “core/v1::Node”, “core/v1::Pods”, “core/v1::Service”, “discovery/v1beta1::EndpointSlice”, “networking.k8s.io/v1::NetworkPolicy”]
KubeProxyReplacement: Strict [ens33 192.168.2.33 (Direct Routing)]
Cilium: Ok 1.10.6 (v1.10.6-17d3d15)
NodeMonitor: Listening for events on 128 CPUs with 64x4096 of shared memory
Cilium health daemon: Ok
IPAM: IPv4: 4/254 allocated from 10.244.2.0/24,
BandwidthManager: Disabled
Host Routing: BPF
Masquerading: BPF [ens33] 10.0.0.0/16 [IPv4: Enabled, IPv6: Disabled]
Controller Status: 29/29 healthy
Proxy Status: OK, ip 10.244.2.85, 0 redirects active on ports 10000-20000
Hubble: Ok Current/Max Flows: 4095/4095 (100.00%), Flows/s: 2.66 Metrics: Disabled
Encryption: Disabled
Cluster health: 3/3 reachable (2022-01-16T09:00:29Z)
root@dev3:/home/cilium#
```

若有收获,就点个赞吧
0 人点赞
