# 通常情况下:我们需要首先理解一下DPDK和XDP。DPDK:DPDK(英语:Data Plane Development Kit),是一组快速处理数据包的开发平台及接口。[1][2] ,运行于Intel X86与arm平台上(最新版本也开始支持PowerPC[3])。该平台采用BSD许可证发布。XDP:eXpress Data Path, high-performance data path merged into the Linux kernel。# DPDK 详细描述:DPDK由intel支持,DPDK的加速方案原理是完全绕开内核实现的协议栈,把数据包直接从网卡拉到用户态,依靠Intel自身处理器的一些专门优化,来高速处理数据包。Intel DPDK全称Intel Data Plane Development Kit,是intel提供的数据平面开发工具集,为Intel architecture(IA)处理器架构下用户空间高效的数据包处理提供库函数和驱动的支持,它不同于Linux系统以通用性设计为目的,而是专注于网络应用中数据包的高性能处理。DPDK应用程序是运行在用户空间上利用自身提供的数据平面库来收发数据包,绕过了Linux内核协议栈对数据包处理过程。Linux内核将DPDK应用程序看作是一个普通的用户态进程,包括它的编译、连接和加载方式和普通程序没有什么两样。DPDK程序启动后只能有一个主线程,然后创建一些子线程并绑定到指定CPU核心上运行。# XDP详细描述:XDP的意思是eXpress Data Path,它能够在网络包进入用户态直接对网络包进行过滤或者处理。XDP依赖eBPF技术# 相对于DPDK,XDP具有以下优点无需第三方代码库和许可同时支持轮询式和中断式网络无需分配大页无需专用的CPU无需定义新的安全网络模型XDP的使用场景包括DDoS防御防火墙基于XDP_TX的负载均衡网络统计复杂网络采样高速交易平台但是这里我们就疑问,看起来一个DPDK在处理数据包,XDP只是在"挡"数据包。但是我们为何需要做DPDK和XDP的比较,有时候甚至觉得我们应该和XDP-TC等过程来和DPDK做比较。但是我们今天给大家阐述一下,为何我们需要DPDK和XDP做比较。
- 1.DPDK COMPARE WITH XDP
XDP: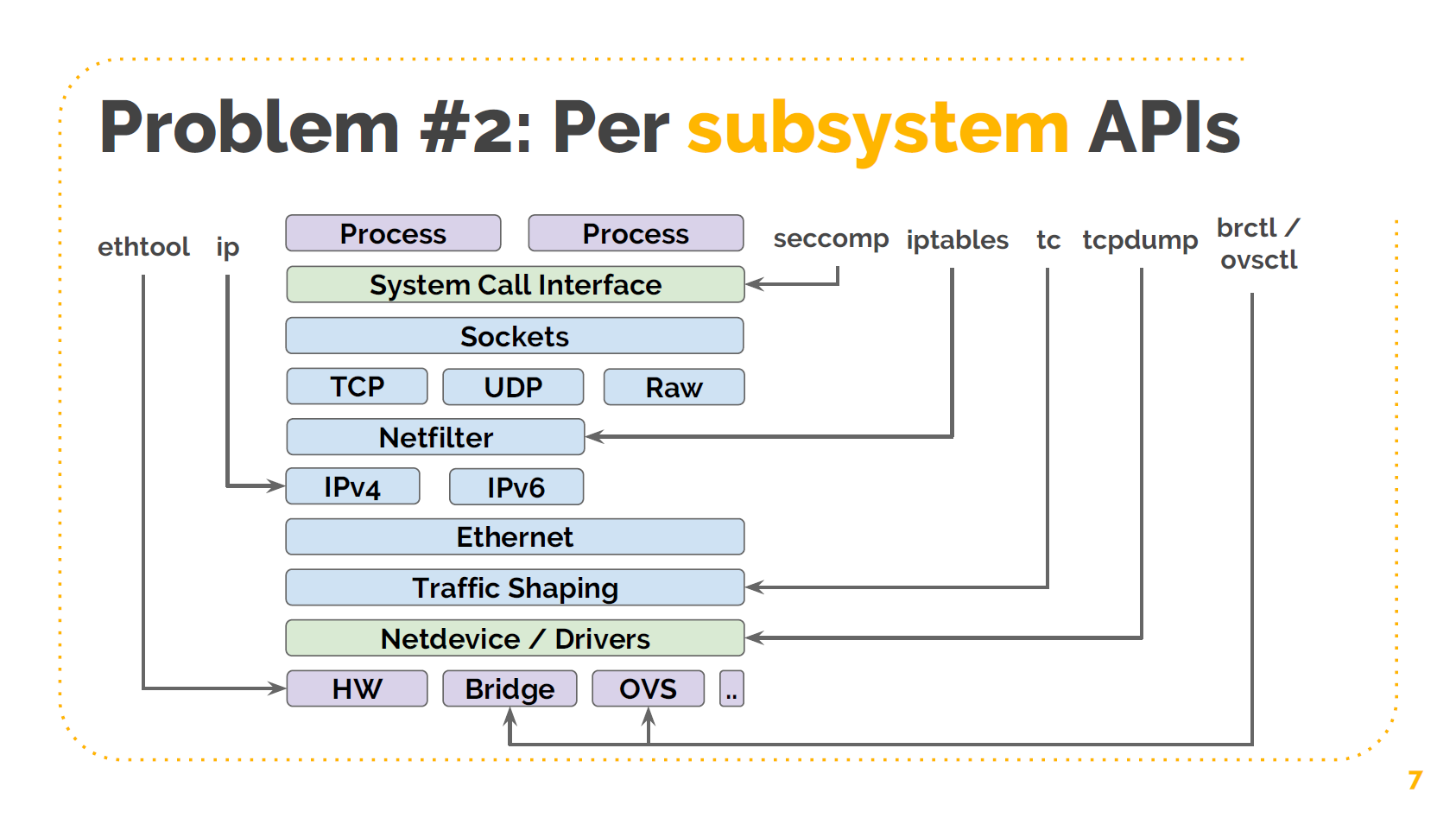
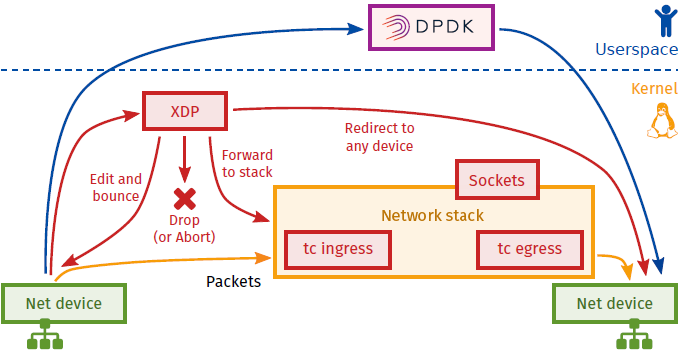
从上边的图上我们可以看到XDP实际上作用在非常靠前的地方,即在Netdevice/Drivers上。这里也仅仅是网卡过了DMA以后到达Driver这段过程中被处理到。
但是这个时候,我们会想到使用XDP做一些,比如官网中描述的防火墙呀,负载均衡呀等等。但是我们需要知道在传统的网络环境中,我们想要做看到这些需要通过iptables等来辅助实现,也就是说需要有一个控制面来告诉这个"健壮的玩意"如何把活干的更加的细致。这也就可以按照某些需求去对数据包进行处理。
这里插一句:我们有一个这样的理解误区,总会认为数据包进入用户空间的某一个APP以后,才能被处理,实际上这样的理解是不全面的。这点很重要,对于我们理解这样两个内核bypass技术尤为重要。只要我们发出去的流量是符合要求的即可,至于是不是直接由APP处理的这点不是非常重要。
所以,结合eBPF,我们知道,此时这个控制数据怎么按要求转发出去,eBPF就可以辅助实现,所以,我们就可以使用这种技术来做,比如防火墙等等特性。
但是我们知道eBPF所插进去的程式要求非常的高,所以在复杂的流量整形上,暂时还没有看到落地的案例,不过我们也相信未来的案例会越来越多。因为复杂的流量整形,我们通常需要一些特定的单元(程式)来帮助解决,但是这样数据包再XDP所代表的环境中就需要穿过内核然后到达用户空间被处理了。实际上这样就没有太显著的优势。当然此时我们也就相当于没有在讨论XDP了。因为这样的话,已经过了XDP所处理位置很远很远了。这样自然就没有什么Fastpath的优势了。所以从这个层面上来讲的话,我们需要觉得对于复杂的流量整形当前的XDP显得就不是那么合适了。
但是我们任然可以使用XDP做一些我们认为可以做的事情:
DDoS防御
防火墙
基于XDP_TX的负载均衡
网络统计
复杂网络采样
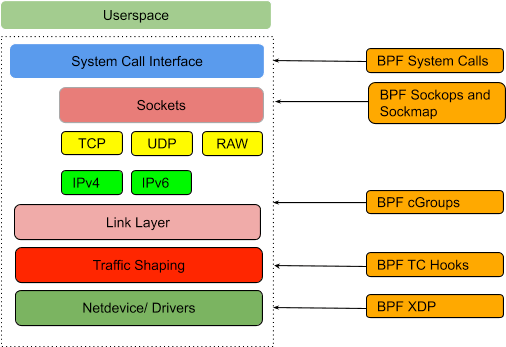
eXpress数据路径是ioVisor项目下的内核中数据包处理框架,该框架也由Linux基金会托管。它旨在在内核空间中提供高性能的数据包处理。 XDP通过挂钩实现了这一目标,进入内核以对传入的数据包运行优化的代码。这些程序在扩展的伯克利分组过滤器(eBPF)框架下执行。 eBPF是1992年创建的原始BPF内核解决方案的改进版本,该解决方案利用了有限的机器指令集,以在内核空间中运行用户创建的程序,基本上在轻量级虚拟机中运行。在将这些用户程序加载到内核之前,已经过验证,以确保它们没有恶意,并且不会无休止运行。 BPF的最初用途是通过过滤进行网络故障排除和分析,不久将扩展到安全用例。 eBPF诞生于2013年,是对原始BPF的改进,并引入了更复杂的虚拟机。通过低级虚拟机LLVM)将eBPF用户程序编译为eBPF指令,然后加载到内核中执行。今天,我们使用术语BPF来指代eBPF,将旧的BPF降级为经典的BPF。
因此,XDP方法通过运行自定义逻辑来处理内核中的数据包来实现性能(下图)。 XDP BPF和BPF已用于创建复杂的网络解决方案,包括Cilium等安全项目。 以内核内方法与内核旁路方法不同,XDP能够在处理数据包的同时利用内核网络堆栈。 它正在积极开发中,在除了删除,切换或传递到内核堆栈之外, 增加复杂动作的同时改善其性能。
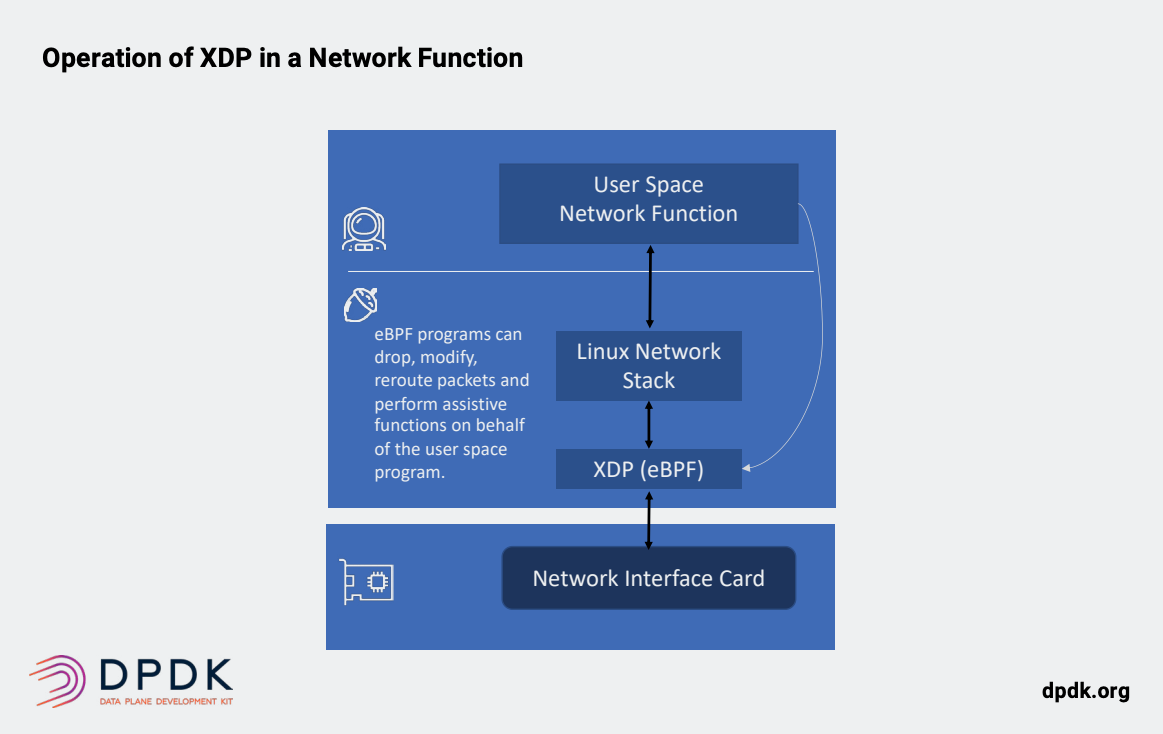
- [x] **3.AF_XDP:**
```json
AF_XDP
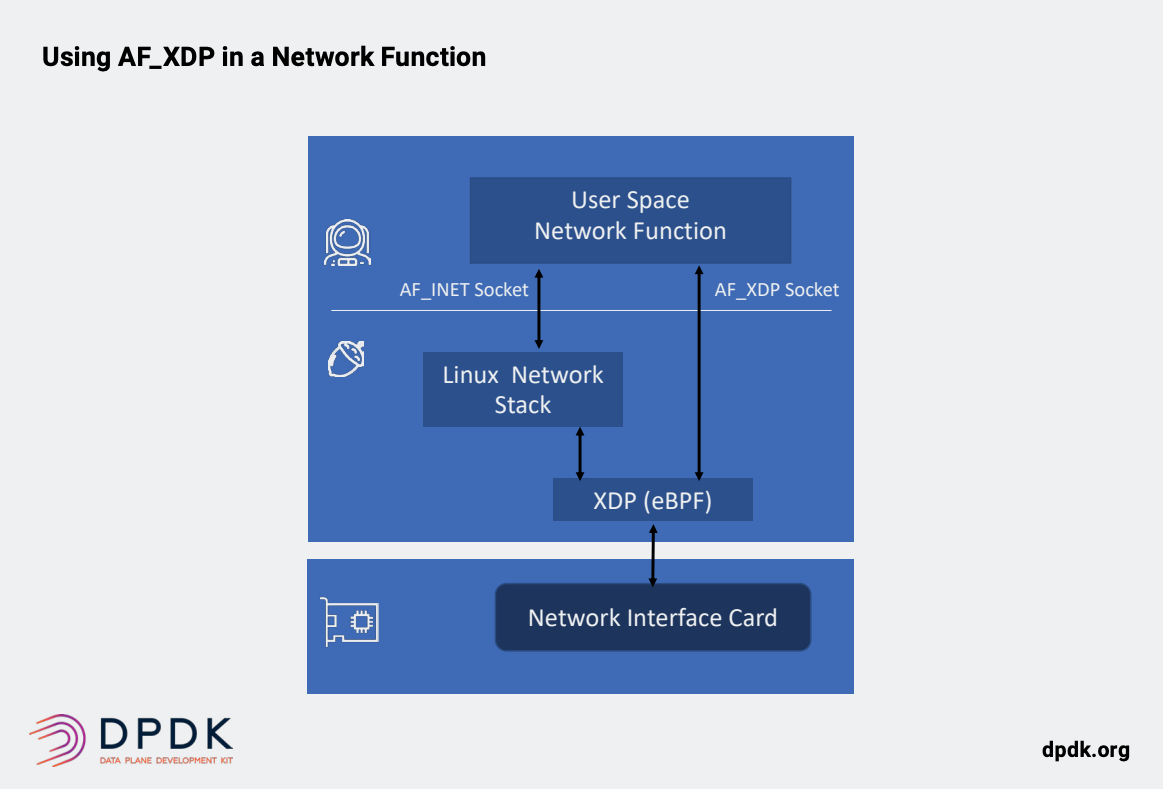
AF_XDP代表地址族XDP,这是Linux中新的套接字地址族类型。 AF_XDP与XDP有关,因为它使用eBPF机制以及VXP驱动程序层。 它会将符合特定条件的数据包直接引导到用户空间中。类似于DPDK的内核绕过。 当与XDP结合使用时,这种方法结合了最好的内核逻辑使用DPDK样式的内核绕过。 AF_XDP套接字允许内核XDP程序将帧重定向到用户空间中的缓冲区进行处理,或继续通过内核的现有网络堆栈,TCP / IP等分流一些流量(下图)。
目前AF_XDP还无法达到DPDK所能提供的高性能水平,该项目得到了英特尔,红帽和Mellanox等供应商的支持。 其中一个AF_XDP方法的潜在主要优点是减少了对特定于供应商的PMD的需求,而是允许构建与基础网卡无关的便携式网络功能应用程序。 实际上,DPDK该项目使用AF_XDP驱动程序框架来简化大量特定于供应商的PMD,从而提供了没有本地分叉的设备的模型。
- DPDK: ```json DPDK 和 Linux 容器: DPDK最初设计是针对具有虚拟机的环境,在裸机部署和虚拟机中均能很好地工作。 DPDK如今可以用于容器,对容器的支持也在不断地改善。当前容器环境中存在一些限制,例如需要为容器分配大量静态内存,数据包缓冲区,这使其不适用于临时的小规模微服务组件。 最新的DPDK版本解决了此问题,实现了增强的动态内存分配的功能。
对于DPDK在容器启用特权的上下文的安全性一些开发人员表达了担忧, 这可能会增加底层操作系统的受攻击可能性,并且DPDK可能仅仅只能在使用受信任的工作负载的平台中方可运行。 不过,DPDK 开发人员正在解决这些问题,我们期望DPDK的容器支持随着容器在现代云原生架构中的兴起,并随着时间的推移而不断地改善。
单根I / O虚拟化 单根I / O虚拟化(SR-IOV)是PCI标准的扩展,涉及创建虚拟功能(VF),该功能可以被视为独立的虚拟PCI设备。 可以将每个VF分配给VM或容器,并且每个VF具有传入数据包的专用队列。 同样,数据包到达后如何处理是一个单独的决定。 SR-IOV是通常在实际部署中与DPDK结合使用,目标是绕过主机和来宾OS的内核。它可用于提供从VNF(VM)中的用户空间到虚拟接口上的传入数据包队列的直接访问在NIC上,减少了等待时间,并减少了复制过程(图6)。 容器可以使用相同的技术。 主要的SR-IOV的问题在于它需要支持该功能的NIC,并且每个VF都占用NIC上的物理资源,因此虽然理论上VF限制很高,但实际上可以限制多少个VF存在实际的内存限制。
FD.io/VPP
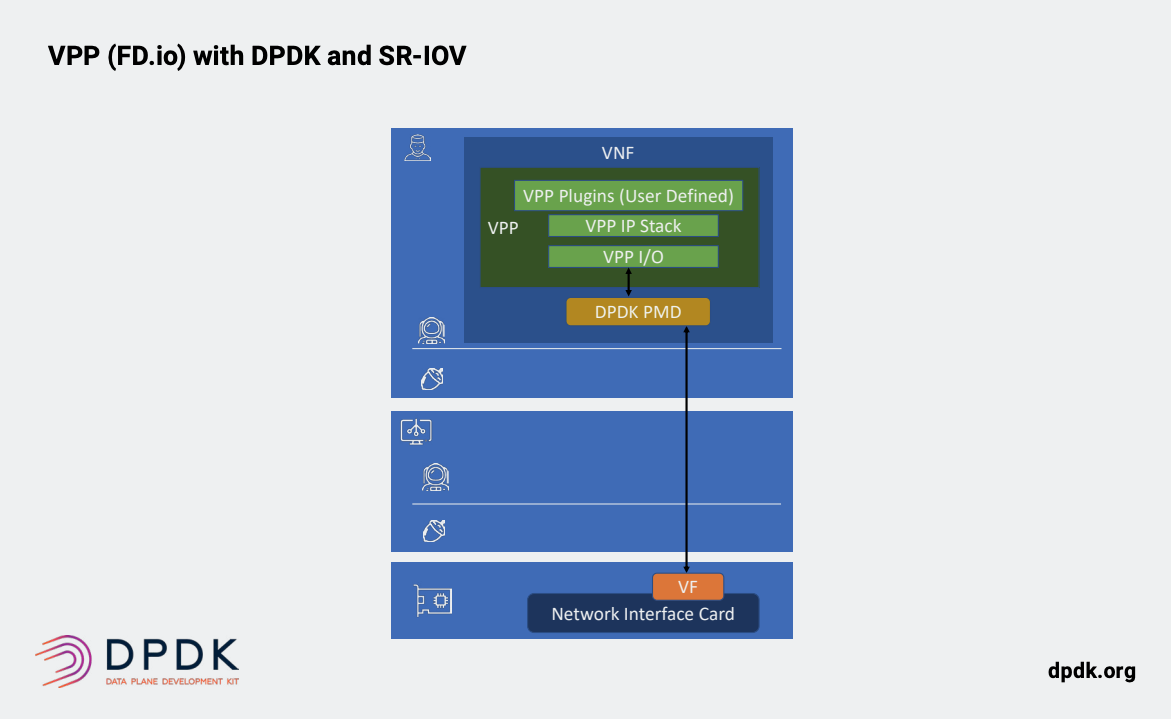
矢量数据包处理器(VPP)是Linux Foundation下的Fast Data(FD.io)项目的一部分。 VPP最初是由思科作为一个开源项目贡献。 VPP的目标是提供一个快速的2-4层用户空间网络堆栈,在x86,Arm和Power等常见架构上运行。如今,大多数VPP实施都利用DPDK作为插件,加速通过DPDK PMD将数据包进入用户空间。VPP专注于上层网络协议(下图)。 VPP通过在以下位置执行功能来获得其大部分性能分批或矢量分组,而不是单个分组。 VPP为第2层和第2层提供了虚拟交换机和虚拟路由器第三层数据包处理。它还集成了优化的TCP / IP堆栈,该堆栈使用矢量化数据包处理来提高性能。性能。与使用DPDK相比,这使在VPP之上构建高层(L4-7)网络功能更加容易。VPP专注于招募虚拟网络网关和安全性等上层网络功能的开发人员。它还正在努力确保使用容器的云原生平台可以有效地使用VPP。
- [x] **DPDK WITH VPP:**
```json
# DPDK的应用:
同样DPDK的流程是是直接把数据包从物理网卡(一般是SRIOV的VF)送到userspace中,但是我们通常原始编写的程式都是运行在内核空间中。所以这样就涉及一个问题,数据送到DPDK-VPP中以后,这样似乎没有办法去做流量的整形。因为我们原始编写的程式是在内核空间中:
这里有两种方式:
1.把数据包从VPP中转发到Kernel中,通过TAP或是TUN设备,如下图,把数据送到kernel。
2.只通过TAP和TUN设备转发少量的流量信息,借助Kernel中的程式来处理,而在VPP中处理方式,通常是使用Plugin来处理。
由于第一种,这样做意义并不大。
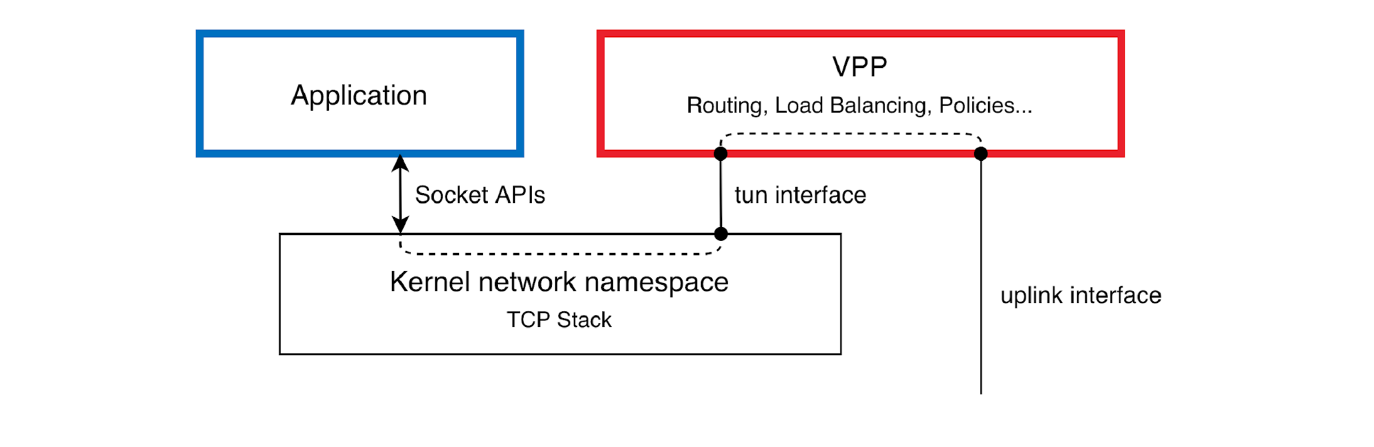
我们重点看第二种:
我们需要解决几个问题:
1.VPP(DPDK)接管的网卡通常使用dpdk tools才能查看到,因为此时网卡已经被DPDK给接管了,所以在kernel中暂时看不到此网卡,但是我们通常又想去ping一下我们的peer。这样该如何处理呢?
2.VPP如何去对流量进行整形?
3.VPP-DPDK的难度较大。商业程度更好。
我们来逐一解释这几个问题:
1.地址问题(涉及到使用习惯问题):
正常情况下,网卡被DPDK接管以后,只能在DPDK tools中查看到,然后VPP中我们可以看到IP地址,我们可以使用VPP的ping,同时我们习惯性的使用的内核的ping,所以我们给做出一个mapping,也就是在VPP中看到的网卡mapping到内核中,这样我么在内核中也能看到一个对应的网卡。但是光有这一个网卡,还不行,我们需要在VPP中添加此逻辑,使得ping能够从VPP中通过图上的TAP或是TUN设备送到内核空间中,这样就完成了一个ICMP的Loop。实际上由上边的图,我们也不难发现,VPP是一个用户空间的协议栈,其作用和我们内核空间的协议栈相似,所以有了这个,我们就比较容易理解了。
所以我们可以设置:
# show from vpp:
# vppctl
_______ _ _ _____ ___
__/ __/ _ \ (_)__ | | / / _ \/ _ \
_/ _// // / / / _ \ | |/ / ___/ ___/
/_/ /____(_)_/\___/ |___/_/ /_/
vpp# show int address
fpeth0 (up):
L3 2008:172:16:127::440/64
fpeth1 (up):
L3 fcff:172:16:227::440/64
fpeth2 (up):
L3 fcff:172:16:327::280/64
local0 (dn):
vpp#
# show from the kernel:
9: fpeth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UNKNOWN qlen 1000
link/ether ba:0c:2e:fa:e9:39 brd ff:ff:ff:ff:ff:ff
inet6 2008:172:16:127::440/64 scope global nodad
valid_lft forever preferred_lft forever
inet6 fe80::b80c:2eff:fefa:e939/64 scope link
valid_lft forever preferred_lft forever
10: fpeth2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1400 qdisc pfifo_fast state UNKNOWN qlen 1000
link/ether ee:26:9b:ce:cd:08 brd ff:ff:ff:ff:ff:ff
inet6 fcff:172:16:327::280/64 scope global nodad
valid_lft forever preferred_lft forever
inet6 fe80::ec26:9bff:fece:cd08/64 scope link
valid_lft forever preferred_lft forever
11: fpeth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UNKNOWN qlen 1000
link/ether 1a:50:84:66:7b:ba brd ff:ff:ff:ff:ff:ff
inet6 fcff:172:16:227::440/64 scope global nodad
valid_lft forever preferred_lft forever
inet6 fe80::1850:84ff:fe66:7bba/64 scope link
valid_lft forever preferred_lft forever
# 这样我们就能在Kernel中ping对端的peer。但是需要加载TAP设备:
# cat /etc/vpp/startup.conf
tap-inject {
enable
}
# ping6 2008:172:16:127::9100
PING 2008:172:16:127::9100(2008:172:16:127::9100) 56 data bytes
64 bytes from 2008:172:16:127::9100: icmp_seq=1 ttl=64 time=1.95 ms
^C
--- 2008:172:16:127::9100 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 1.955/1.955/1.955/0.000 ms
# 注意这里是做过适配的,我们在VPP的版块中也描述过这里,具体参考:https://www.yuque.com/wei.luo/sriov-dpdk-vpp/mi4rbg
2.VPP如何去对流量进行整形?
这里还是会涉及一个问题,我们的刚才也描述过VPP除了是一个stack,还提供了需要Plugin来完成丰富的流量整形,所以这里我们就可以避免把数据包从VPP中cp到Kernel中,造成性能下降等问题。
所以我们可以放少量的包到内核中完成一个类似控制面的交流,这样,拿到了如何去整形的依据以后,我们就知道该怎么去处理了。虽然这个处理是VPP中对应的某些plugin来处理。
Like:
plugins {
plugin default { disable }
plugin dpdk_plugin.so { enable }
plugin router.so { enable }
plugin mclb_plugin.so { enable }
plugin rtp_plugin.so { enable }
}
#DPDK的优势与提高
随着SmartNIC的出现,曾经有一些业内人士预测 DPDK 会逐渐消失。 然而事实是,DPDK依然在不断地发展,并且工作也在加速。 展望未来,我们看到DPDK具有以下优势,以及需要提高的地方:
成熟性和稳定性: API的稳定性是当今DPDK的独特属性之一。 不像其他加速方案,DPDK相对成熟,项目维护人员了解保持需求的必要性,可靠的API,以防止代码损坏或持续的补丁程序和重新编译。
持续的性能改进: DPDK将继续寻找方法和智能网卡SmartNIC和其他硬件加速的整合与集成。 同样,我们可以期待DPDK 继续在软件性能上的改进。
降低复杂性:DPDK并不是最容易部署和使用的,而且还必须包含多个组件的正确配置和部署,例如带有VNF并支持DPDK的OVS-DPDK。 此外,还有无数必须维护的供应商特定的PMD。 供应商并不想维护多个驱动程序,无论AF_XDP统一PMD是否成功,DPDK 都需要更标准化的方式与硬件集成。
更好的云和容器支持:今天DPDK 虽然支持容器,但还并不理想。 预期在用于容器部署的DPDK内存管理中 DPDK 会进行改进,来更好地与容器和微服务架构对齐。 同样,安全模型也需要加强,以避免使用DPDK的容器需要特权升级。
效率更高: 在Arm架构上,支持事件触发模式以提取数据包(相对于常量在x86上轮询)。 这样的方法以及时钟CPU缩放将有助于DPDK改善其非绿色声誉。
多供应商:期望在x86以外的各种指令体系中继续提供支持(英特尔和AMD),Arm和PowerPC。 同样,英特尔等供应商提供的加密和其他加速功能,也在Mellanox和Marvell以及其它新兴硬件供应商中得到进一步支持和发展。
最佳实践的合理化和规范化: 虽然2020年将出现不同的用例和体系结构, 但无论是使用在SmartNIC本身上使用DPDK或由API驱动模型中DPDK调用SmartNIC加速的技术,DPDK与SmartNIC(FPGA,ASIC,NPU)相结合的最佳实践方式的发展都将会继续下去。
无论如何,DPDK会继续成为基础设施加速中的主导框架,而DPDK项目也在寻找更多的贡献者和支持者。 和所有开源项目一样,只有通过各种社区人员的参与才能成功。无论您是软件开发人员还是硬件开发人员,质量检查人员,开发测试工程师,文档专家或市场营销专家,DPDK该项目正在寻找新的贡献者和成员。 如果需要了解更多信息,请访问Linux Foundation DPDK网站查看详情。
- DPDK vs XDP:
通过以上的描述,我们可以知道: 想要实现数据流的高速,我们都是在内核外做努力,但是需要内核的程式作为依据。

若有收获,就点个赞吧
0 人点赞
