# 阅读Cilium的Blog发现最近出 了一篇新的帖子,因为Cilium是一个新的CNI对我们来说,而且其中有许多新的概念是我们平时没能接触到(当然是我们平时很少看内核网络相关的代码所致,这点需要补充了。)要努力呀。How eBPF Streamlines the Service Mesh - 所以尝试翻译下,或是拜读一下:https://thenewstack.io/how-ebpf-streamlines-the-service-mesh/
- 1.Service Mesh With SideCar ```properties 1.首先来看一下我们平时谈的ServiceMesh,最直接的就是密密麻麻的Mesh混杂在一起,我们可能会想到,这样真的好么?我们会不会把问题复杂化了呢?我们脱离了OpenStack带来的臃肿,难道迎来了Kubernetes的复杂么?实际上,我们经常可能会有这样的疑问,甚至觉得Mesh给我们带来了什么?仅仅是联系么,此为一层。第二我们在mesh中加入一个SideCar,通常为envoy。这样每一个pod又会增加1:1个envoy。这样在Pod数量增加的时候,envoy也在增加,资源明显消耗过高。
目前针对于这个SideCar已经有的方案由三种: 1.对于每一个Pod都有一个infra容器,所以有方案想把这个SideCar做到这个infra中来实现。比如:https://github.com/flomesh-io/pipy
2.使用webhooks动态注入SideCar,目前Istio使用便是该方案。https://istio.io/
3.Cilium中的的endpoint使用单一的envoy来实现。https://thenewstack.io/how-ebpf-streamlines-the-service-mesh/
以上的三种方案我们目前都需要关注,因为社区很多时候会提出很多新颖的概念,初看起来我们觉得这个玩意还真好。但是实际上有时候也仅仅是停留在github上的一个repo,而鲜有落地的案例[当然这里因素有很多,大家应该都能理解]。当然首先我们需要肯定这个,这点毋庸置疑。我们也希望看到更多的方案,这也是开源的精髓所在。但是我们通常在商言商,如果技术不能被转化为生产力,那么也就鲜有市场为其买单。比如我们现在大火的宠儿BPF,实际上1992就被提出来了,现在已经过了将近30年,市场才愿意为其买单。这种案例非常之多,我们就不再赘述了。所以以上多种方案我们需要都关注一下。
1.方案1.我们后边的在于讨论。具体参考帖子:https://mp.weixin.qq.com/s/iHqmMVV0X5rBmRbS2BE8qw
2.方案2.我们也会在后期的帖子中讨论,具体涉及到Istio相关的逻辑,由于知识面比较广,不是今天的主题。
3.方案3.我们今天来重点看此方案。
- [x] **2.Cilium With SideCar**
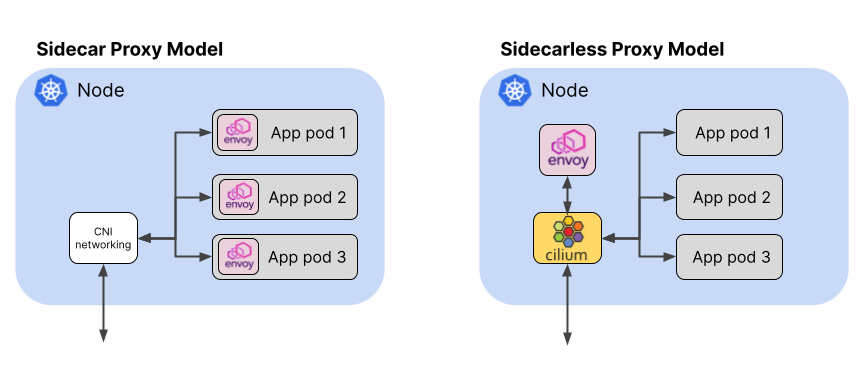
```properties
我们先整体描述它的逻辑:
从图上我们可以明显的看出来,envoy代理 由多个减少为1个。这样可大大的减少"重复"的SideCar,对我们的整体负载减少的非常明显。
// 来自该帖子的描述,我们这里借用一下。
The memory used by each proxy increases in relation to the number of services that it needs to be able to communicate with. Pranay Singhal wrote about his experiences configuring Istio to reduce consumption from around 1GB per proxy (!) to a much more reasonable 60-70MB each. But even in our small, imaginary environment with 100 proxies on three nodes, this optimized configuration still needs around 2GB per node.、
从上边的描述,我们可以看到效果实际上非常的明显。所以此种模式被定义为sidecarless。
The eBPF-based Cilium project (which recently joined the Cloud Computing Foundation at Incubation level) brings this “sidecarless” model to the world of service mesh. As well as the conventional sidecar model, Cilium supports running a service mesh data plane using a single Envoy proxy instance per node. Using our example from earlier, this reduces the number of proxy instances from 100 to just three.
In contrast, in the eBPF-enabled, sidecarless proxy model, the pods do not need any additional YAML in order to be instrumented. Instead, a CRD is used to configure the service mesh on a cluster-wide basis. Even pre-existing pods can become part of the service mesh without needing a restart!
我们看一下这里的描述:
在sidecarless 模式下,pod不需要额外的YAML,取而代之的是cluster-wide形式的CRD.甚至是已经存在的Pod我们也可以直接加入到这个envoy的backend中,而不用重新重启而被webhooks注入进来,这点优于我们目前的sidecar full mesh形式。
这单实际上得益于我们eBPF。因为:eBPF是一种内核技术,而在一个Node上,我们只有一个kernel,所以任何事件都能被内核的eBPF给发现,因为无论是以bare形式运行的进程还是以container形式运行的模式,都需要使用这个Node上的内核。
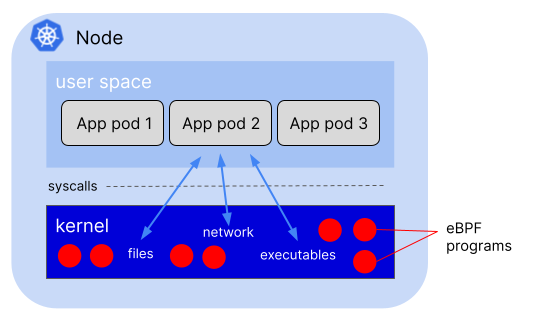
One kernel per host
- 3.CIlium eBPF 提升网络效率[sidecarless mode]
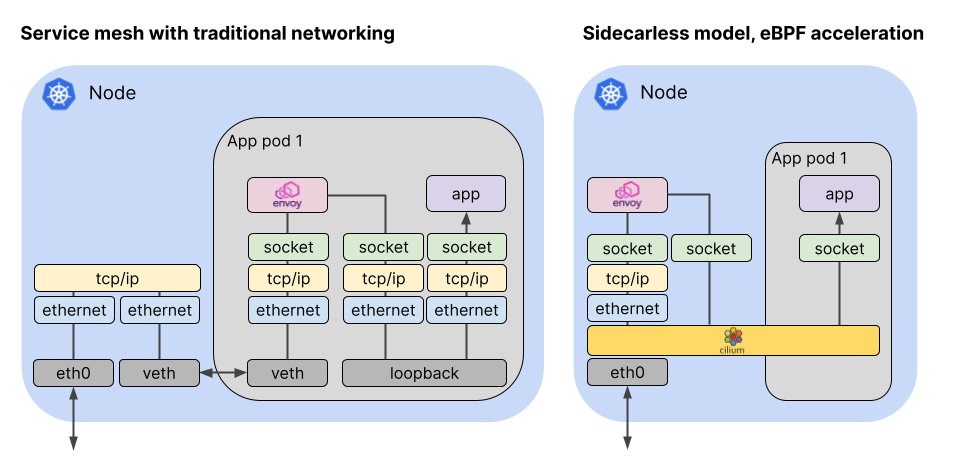
Network packets travel through a much shorter path in the eBPF-accelerated, sidecarless proxy model for service mesh
在sidecar 模式下:sidecar 容器和main container之间通信需要经过tcp/ip协议栈来实现数据通信,说白了就是使用lookback口进行通信,这是datapath 1.
而一个简单的数据通信,需要经过两层tcp/ip协议栈,这是我们目前的方式。而envoy代理的流量出去的时候,我们知道是采用veth pair的形式,此为datapath2.
经过container所在的ns以后,通过veth pair进入root ns中,继续走root ns中的协议栈。此为datapath3.
而在sidecarless模式下:首先是datapath1,这里可以实现基于bpf的跳转而不经过tcp/ip协议栈。
对于datapath2此时也再次被bpf跳转给bypass掉了。
所以之需要一次的tcp/ip协议栈的逻辑就可以实现。当然这里的tcp/ip的协议栈是在内核空间的形式,如果结合vpp的话,我们是否可以实现基于用户空间的tcp/ip协议栈呢?这个或许可以探究一下。
之所以我们能这样做:
An eBPF-based Kubernetes CNI implementation such as Cilium can use eBPF programs, judiciously hooked into specific points in the kernel, to redirect the packet along a much more direct route. This is possible because Cilium is aware of all the Kubernetes endpoints and service identities. When a packet arrives on the host, Cilium can dispatch it straight to the proxy or pod endpoint to which it is destined.
- 4.Service Mesh Encryption ```properties 对于我们目前看到的service之间的流量我们通常可能需要由加密的需求,所以在istio中我们使用mTLS。TLS不仅仅唯一的手段。我们还可以使用IPSec 或是 Wireguard。 But TLS, managed at the application layer, is not the only way to achieve authenticated and encrypted traffic between components. Another option is to encrypt traffic at the network layer, using IPSec or WireGuard. Because it operates at the network layer, this encryption is entirely transparent not only to the application but also to the proxy — and it can be enabled with or without a service mesh. If your only reason for using a service mesh is to provide encryption, you may want to consider network-level encryption. Not only is it simpler, but it can also be used to authenticate and encrypt any traffic on the node — it is not limited to only those workloads that are sidecar-enabled.
目前我们接受到的环境虽然没有使用service mesh ,但是我们也需要不同的components之间也是需要采用加密的需求,我们目前是基于IPSec的方式实现。原因是实现方式和组网模式不一样。 在我们的环境中,我们通常是基于vpp 的 plugin 来实现:具体参考vpp pulgin:https://ligato-docs.readthedocs.io/en/latest/user-guide/articles/IPSec-plugin/
借助于VPP和DPDK的高性能方案辅助实现。
```

若有收获,就点个赞吧
0 人点赞
