线程安全的集合框架总览
Collection

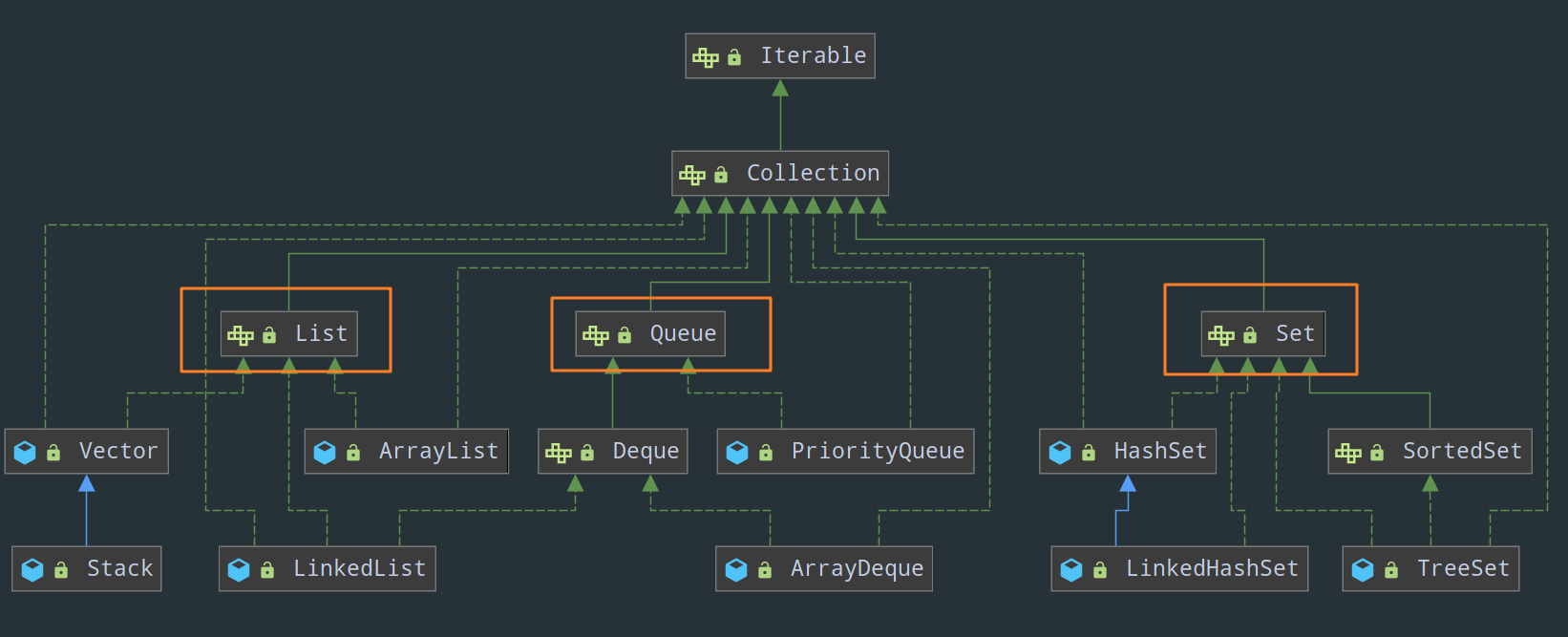
Collection 有三个子接口,分别是 List、Set 和 Queue,它们分别代表了有序集合、无序集合和队列:
- List 的特点是元素有序、可重复。注意,这里所谓有序的意思,并不是指集合中按照元素值的大小进行有序排序,而是说,List 会按照元素添加的顺序来进行存储,保证插入的顺序和存储的顺序一致。List 接口的常用实现类有:
- ArrayList:底层数据结构是数组,线程不安全
- LinkedList:底层数据结构是链表,线程不安全
- Set 接口在方法签名上与 Collection 接口其实是完全一样的,只不过在方法的说明上有更严格的定义,最重要的特点是他拒绝添加重复元素,不能通过整数索引来访问,并且元素无序。同样的,所谓无序也就是指 Set 并不会按照元素添加的顺序来进行存储,插入的顺序和存储的顺序是不一致的。其常用实现类有:
- HashSet:底层基于 HashMap 实现,采用 HashMap 来保存元素
- LinkedHashSet:LinkedHashSet 是 HashSet 的子类,并且其底层是通过 LinkedHashMap 来实现的。
- Queue 这个接口其实用的不多,可以把队列看作一种遵循 FIFO 原则的特殊线性表(事实上,LinkedList 也确实实现了 DeQueue 接口),Queue 接口是单向队列,而 DeQue 接口继承自 Queue,它是双向队列。
Map 接口
双列集合 java.util.Map:元素是成对存在的。每个元素由键(key)与值(value)两部分组成,通过键可以找对所对应的值。显然这个双列集合解决了数组无法存储映射关系的痛点。另外,需要注意的是,Map 不能包含重复的键,值可以重复;并且每个键只能对应一个值。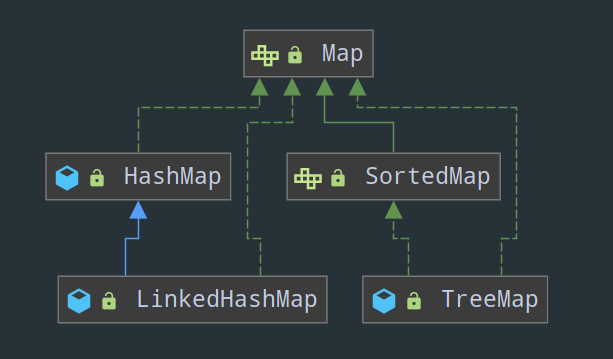
- HashMap:可以说 HashMap 不背到滚瓜烂熟不敢去面试,这里简单说下它的底层结构吧。JDK 1.8 之前 HashMap 底层由数组加链表实现,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的(“拉链法” 解决冲突)。JDK1.8 以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)时,将链表转化为红黑树,以减少搜索时间(注意:将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)
- LinkedHashMap:HashMap 的子类,可以保证元素的存取顺序一致(存进去时候的顺序是多少,取出来的顺序就是多少,不会因为 key 的大小而改变)。LinkedHashMap 继承自 HashMap,所以它的底层仍然是基于拉链式散列结构,即由数组和链表或红黑树组成。另外,LinkedHashMap 在上面结构的基础上,增加了一条双向链表,使得上面的结构可以保持键值对的插入顺序。同时通过对链表进行相应的操作,实现了访问顺序相关逻辑。也可以用LinkedHashMap 做LRU操作。
线程安全的集合总览
Collection 接口
- List:
- Vector(这个没啥好说的,它就是把 ArrayList 中所有的方法统统加上 synchronized )
- CopyOnWriteArrayList
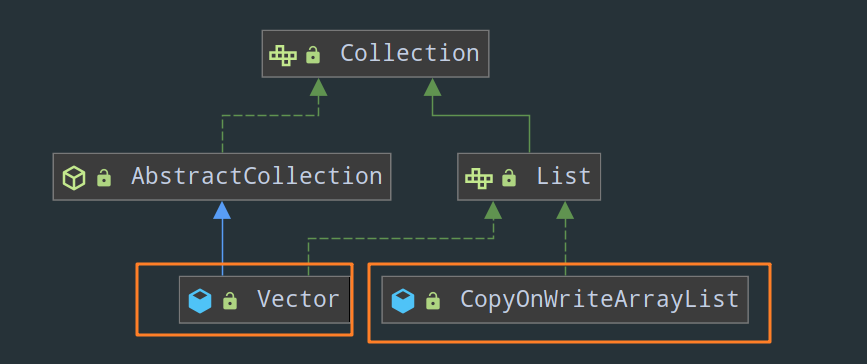
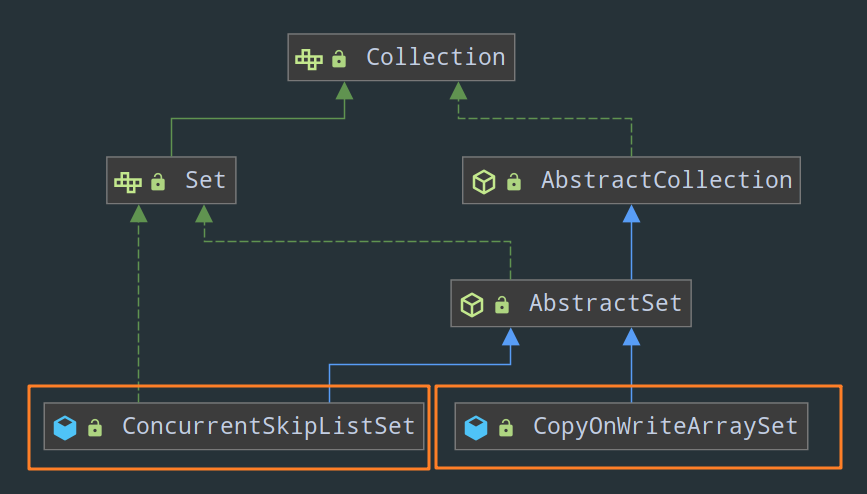
- Set
- CopyOnWriteArraySet
- ConcurrentSkipListSet
3)Queue:
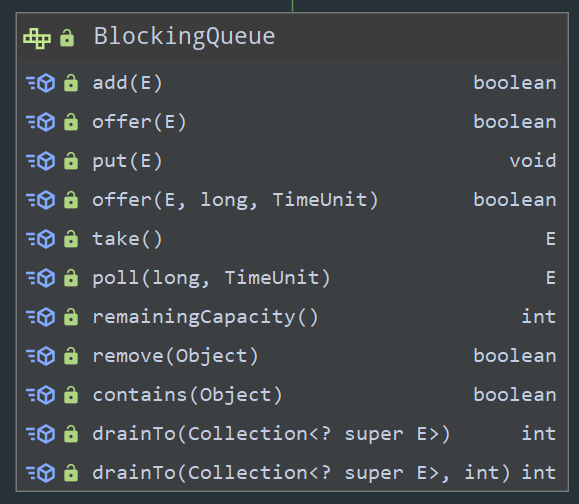
BlockingQueue 接口
- LinkedBlockingQueue
- DelayQueue
- PriorityBlockingQueue
- ConcurrentLinkedQueue
TransferQueue 接口
- LinkedTransferQueue
BlockingDeque 接口
- LinkedBlockingDeque
- ConcurrentLinkedDeque

Map 接口
- HashTable, 把HashMap 中所有的方法都加上synchronized。
- ConcurrentHashMap, ConcurrentSkipListMap
HashMap
HashTable
ConcurrentHashMap
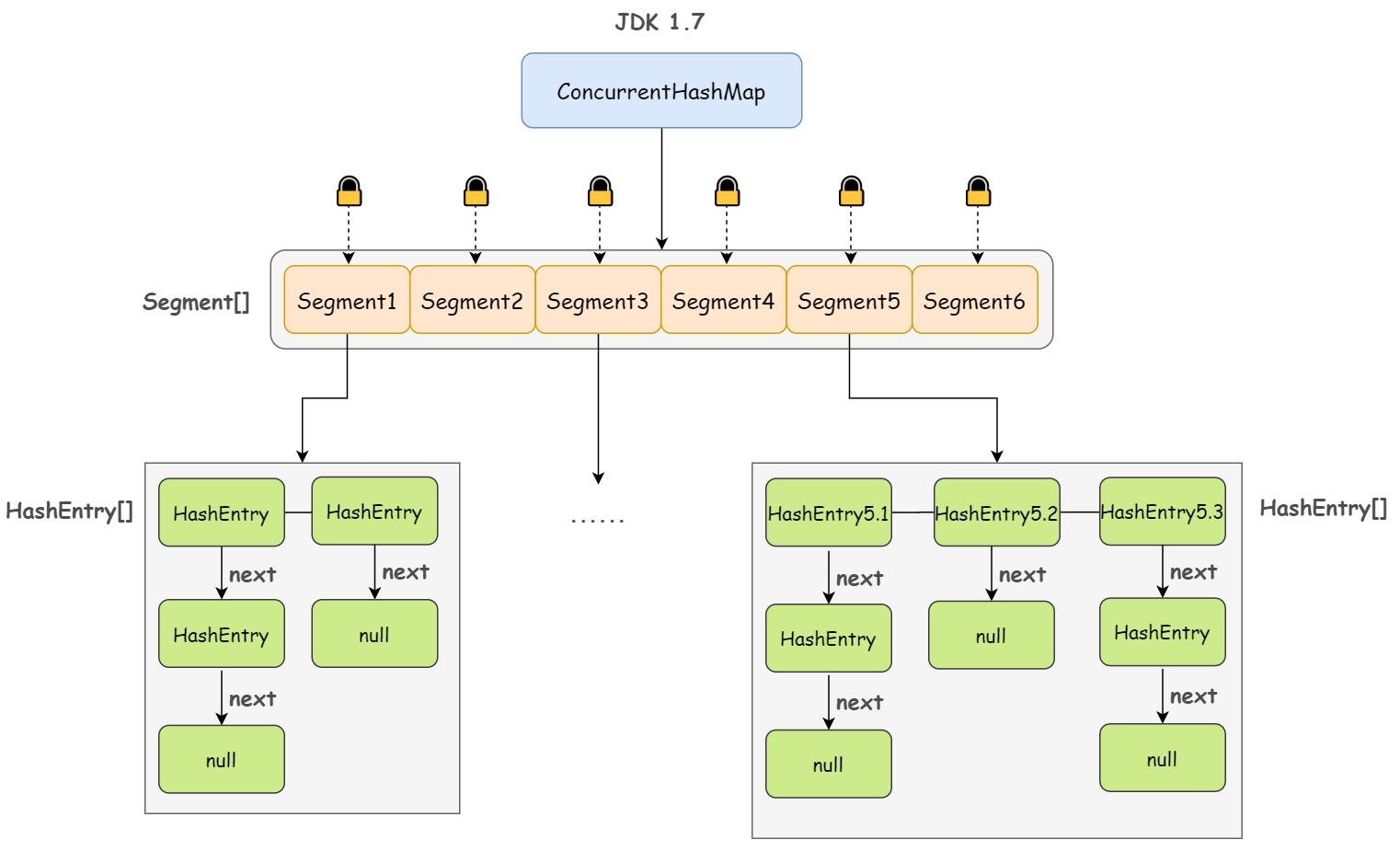
JDK 1.7
- ConcurrentHashMap 是由 Segment 数组结构和 HashEntry 数组结构组成。
Segment 继承自 ReentrantLock,是一种可重入锁;其中,HashEntry 是用于真正存储数据的地方。
static final class Segment<K,V> extends ReentrantLock implements Serializable {// 真正存放数据的地方transient volatile HashEntry<K,V>[] table;// 键值对数量transient int count;// 阈值transient int threshold;// 负载因子final float loadFactor;Segment(float lf, int threshold, HashEntry<K,V>[] tab) {this.loadFactor = lf;this.threshold = threshold;this.table = tab;}}
static final class HashEntry<K,V> { final int hash; final K key; volatile V value; volatile HashEntry<K,V> next; }value 用volatile 修饰,保证数据的可见性。
一个 ConcurrentHashMap 包含一个 Segment 数组,一个 Segment 里包含一个 HashEntry 数组,当对某个 HashEntry 数组中的元素进行修改时,必须首先获得该元素所属 HashEntry 数组对应的 Segment 锁。
put
既然 ConcurrentHashMap 使用分段锁 Segment 来保护不同段的数据,那么在插入和获取元素的时候,必须先通过 Hash 算法定位到 Segment:
然后在对应的 Segment 中进行真正的 put:
1)尝试获取锁,如果获取失败则利用 scanAndLockForPut() 进行自旋
2)遍历该 HashEntry 数组:
- 如果当前遍历到的 HashEntry 不为空则判断传入的 key 和当前遍历到的 key 是否相等,相等则覆盖旧的 value
- 为空则新建一个 HashEntry 并加入到 Segment 中(先判断是否需要对 Segment 数组进行扩容)
Get
get 就更简单了,效率也非常高,因为整个过程都不需要加锁:
1)将 Key 通过 Hash 定位到具体的 Segment
2)再通过一次 Hash 定位到具体的元素上
JDK1.8
阻塞队列
- ArrayBlockingQueue:一个由数组结构组成的有界阻塞队列
- LinkedBlockingQueue:一个由链表结构组成的有界阻塞队列
- PriorityBlockingQueue:一个支持优先级排序的无界阻塞队列
- DelayQueue:一个使用 PriorityBlockingQueue 实现的无界阻塞队列
- SynchronousQueue:一个不存储任何元素的阻塞队列
- LinkedTransferQueue:一个由链表结构组成的无界阻塞队列
- LinkedBlockingDeque:一个由链表结构组成的双向阻塞队列

ArrayBlockingQueue
Get
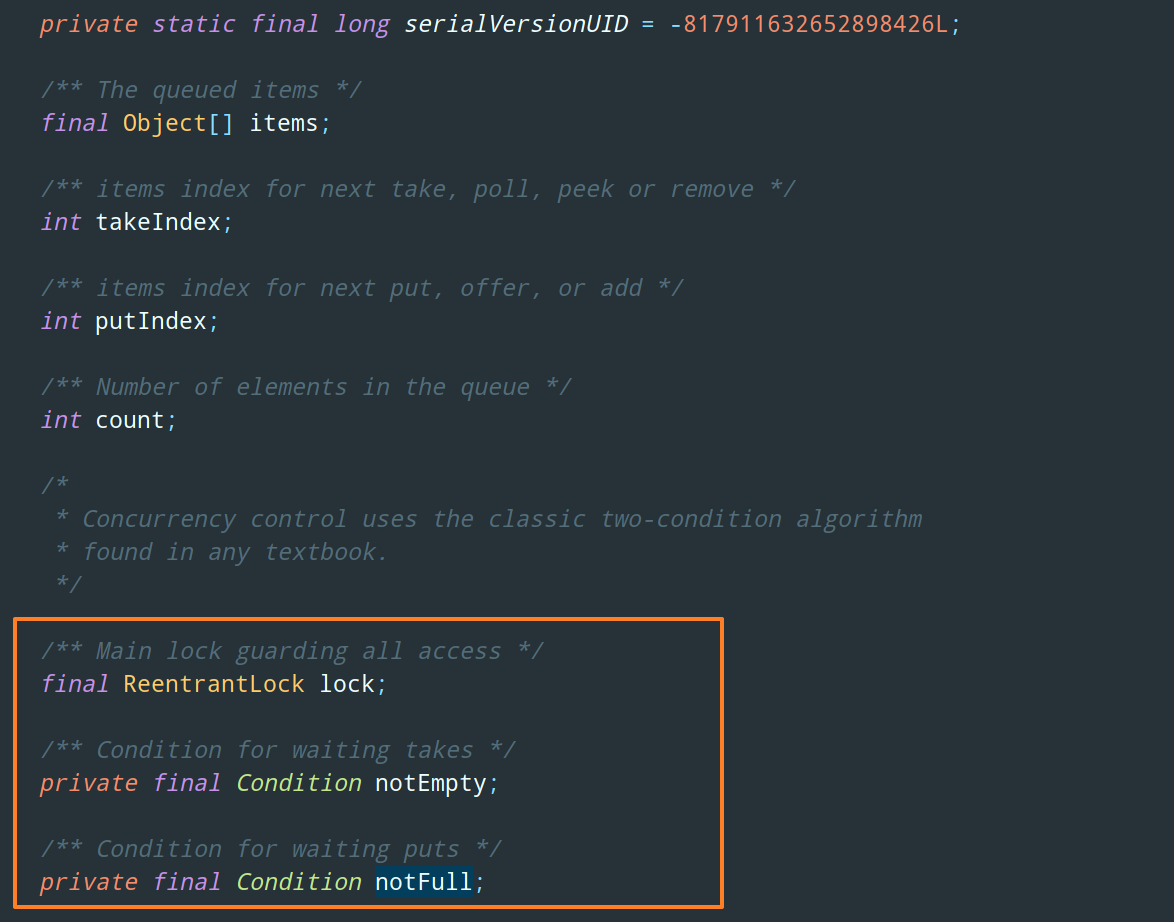
public void put(E e) throws InterruptedException {
checkNotNull(e);
final ReentrantLock lock = this.lock;
// 获取可中断锁
lock.lockInterruptibly();
try {
// 如果当前元素个数等于队列的最大长度,则调用 notFull.await() 进行等待
while (count == items.length)
notFull.await();
// 向队列中插入元素
enqueue(e);
} finally {
// 入队成功,释放锁
lock.unlock();
}
}
Put
public void put(E e) throws InterruptedException {
checkNotNull(e);
final ReentrantLock lock = this.lock;
// 获取可中断锁
lock.lockInterruptibly();
try {
// 如果当前元素个数等于队列的最大长度,则调用 notFull.await() 进行等待
while (count == items.length)
notFull.await();
// 向队列中插入元素
enqueue(e);
} finally {
// 入队成功,释放锁
lock.unlock();
}
}
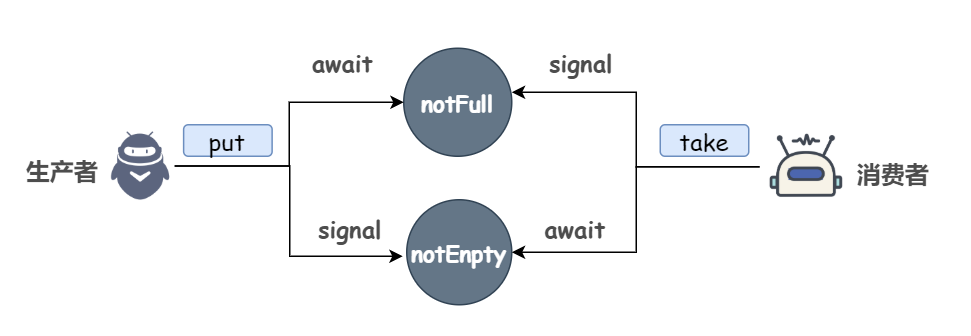
Copy On Write 写时复制
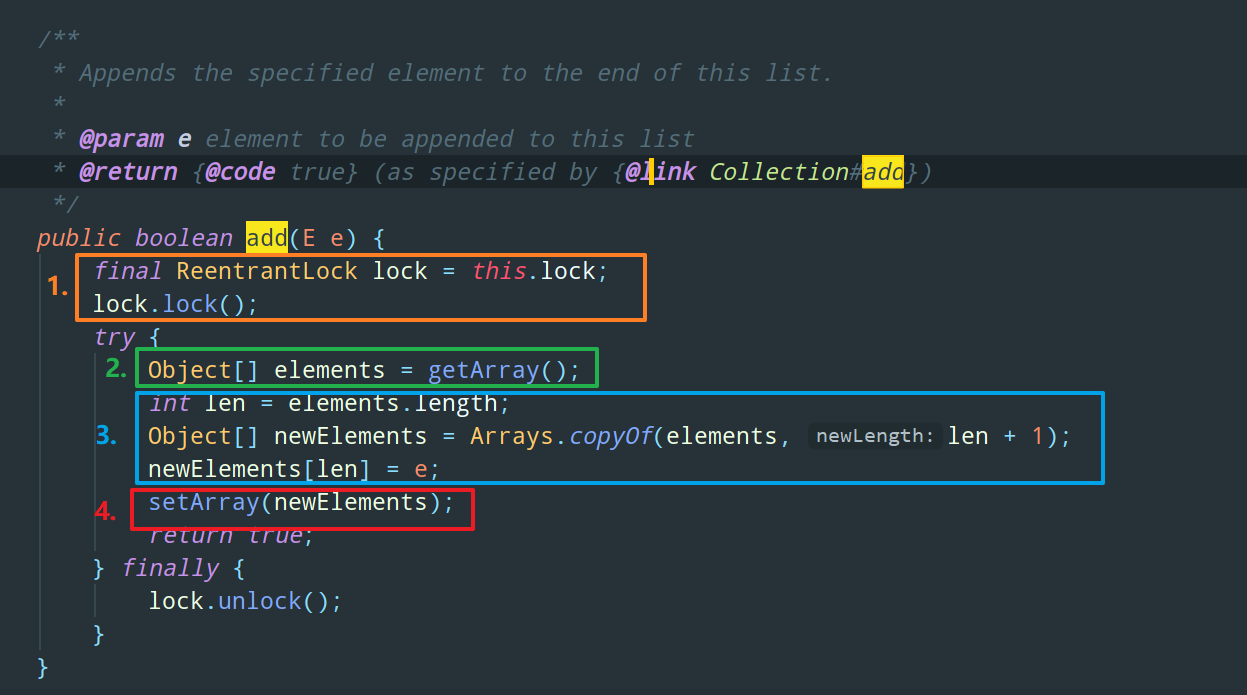
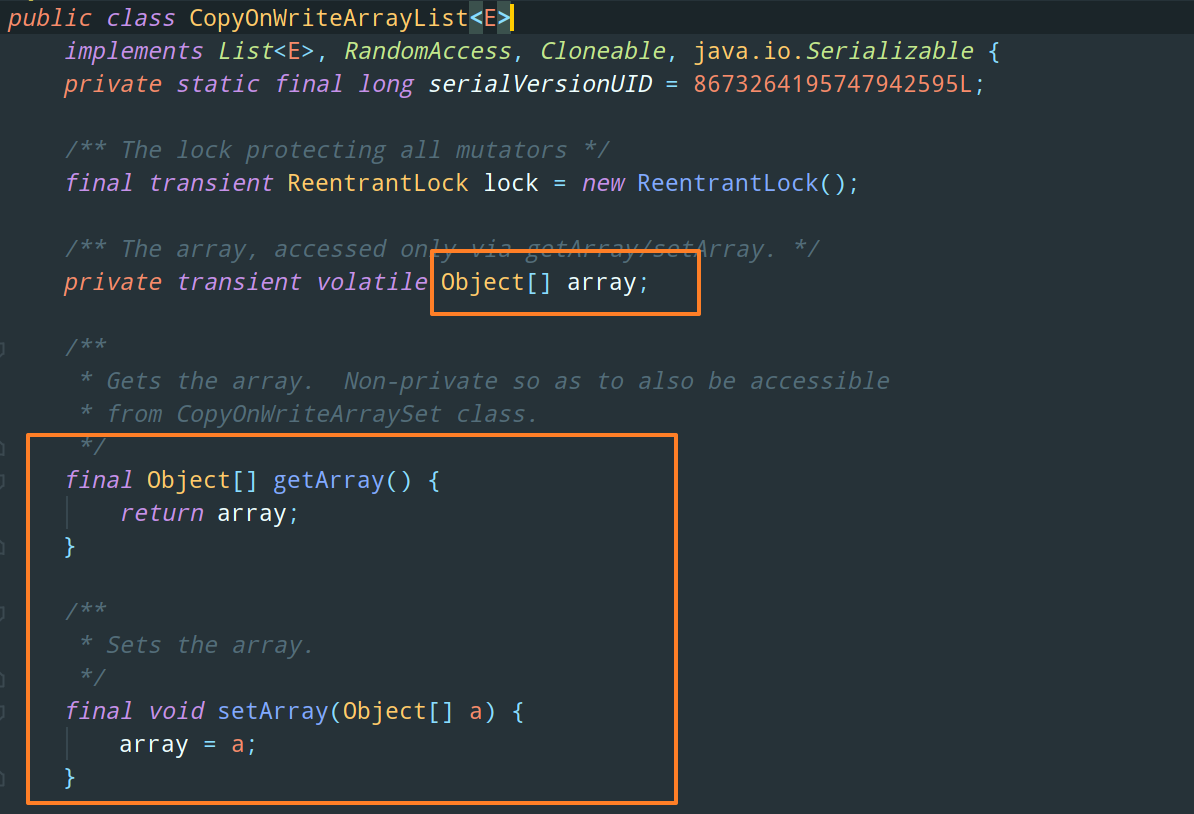
COW 的缺点
看到这里其实 COW 的缺点已经非常明显了,那就是内存占用问题,每修改一次数组,就意味着需要开辟内存空间生成一个新数组,对于写操作比较频繁的场景,频繁的元素添加会造成数组的不断扩容和复制,十分消耗性能和内存,并且如果原数组的数据比较多的话,还可能会导致 Young GC 或者 Full GC。
另外,如果业务场景对数据实时性要求比较高的话,也是不建议使用 COW 的。

若有收获,就点个赞吧
0 人点赞
