CountDownLatch
倒计时器, 线程同步工具
如果线程 A 执行到了 线程 B.join() 语句,其含义就是,当前线程 A 等待线程 B 结束运行之后才从 线程 B.join() 这条语句返回然后继续执行。
Thread.join()
Thread threadA = new Thread(new Runnable() {@Overridepublic void run() {System.out.println("first thing finish");}});Thread threadB = new Thread(new Runnable() {@Overridepublic void run() {System.out.println("second thing finish");}});threadA.start();threadB.start();threadA.join();threadB.join();System.out.println("FINISH");
可以看到,这里实际上有三个线程,主线程 + Thread A + ThreadB,主线程执行到 threadA.join(),需要等到 threadA 执行完才能继续往下执行,接着,走到 threadB.join(),同样的,主线程需要等到 threadB 执行完才能继续往下执行。
Thread 类 除了提供 join() 方法之外,还提供了 join(long millis) 和 join(long millis,int nanos) 两个具备超时特性的方法。也就是说,如果线程在给定的超时时间里没有终止,那么将会从该超时方法中返回。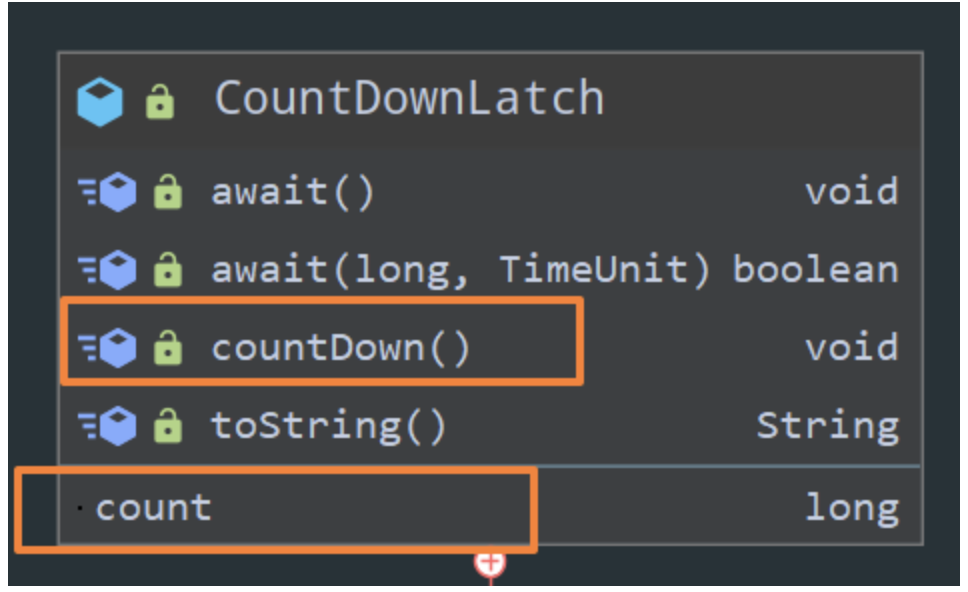
CountDownLatch 用await 阻塞主线程,每调用一次就countDown 一次。等到count 为0主线程才能执行。
static CountDownLatch countDownLatch = new CountDownLatch(2);
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("first thing finish");
countDownLatch.countDown(); // count --
System.out.println("second thing finish");
countDownLatch.countDown(); // count --
}
}).start();
countDownLatch.await(); // 主线程被阻塞住,直到 count = 0
System.out.println("FINISH");
CyclicBarrier
回环屏障
让一组线程到达一个屏障(也可以叫同步点)时被阻塞,直到最后一个线程到达屏障时,屏障才会开门,所有被屏障拦截的线程才会继续运行。
CyclicBarrier 默认的构造方法是 CyclicBarrier(int parties),其参数 parties 就表示被屏障拦截的线程数量,每个线程执行完各自的逻辑后可以调用 await 方法告诉 CyclicBarrier 我已经到达了屏障,然后当前线程就会被阻塞。直到抵达屏障的数量达到 parties,屏障打开,被阻塞的线程才可以继续往下执行。注意,主线程也包括在内
static CyclicBarrier cyclicBarrier = new CyclicBarrier(3);
Thread threadA = new Thread(new Runnable() {
@Override
public void run() {
System.out.println("first thing finish");
cyclicBarrier.await(); // threadA 线程已达到屏障
}
});
Thread threadB = new Thread(new Runnable() {
@Override
public void run() {
System.out.println("second thing finish");
cyclicBarrier.await(); // threadB 线程已达到屏障
}
});
threadA.start();
threadB.start();
cyclicBarrier.await(); // 主线程已达到屏障
System.out.println("FINISH");
另外,CyclicBarrier 还提供一个更高级的构造函数 CyclicBarrier(int parties,Runnable barrier-Action),就是说,当抵达屏障的线程数量满足 parties 后,在所有被阻塞的线程继续执行之前(即屏障打开之前),率先 barrier-Action 方法。
Semaphore
书中把 Semaphore 翻译成信号量,我感觉不是很好理解,翻译为 “许可证” 更好。
// 假设有20个许可证
Semaphore s = new Semaphore(20);
// 获取许可证
s.acquire();
// 释放许可证
s.release()
Semaphore 应用场景:
假设我们现在需要同时读取几万个文件的数据并存储到数据库中,单线程跑显然效率非常低下,于是呢,我们启动了 30 个线程来同时去读取文件。
读取完文件后还要存储到数据库中,但是,数据库的连接数只有 10 个,也就是说,虽然我们有 30 个读取文件的数据,但是同时只能由 10 个线程来保存数据。或者说,有 30 个人排队恰饭,但是餐馆里只有 10 张椅子,这时候,我们就可以利用 Semaphore 来发放许可证了: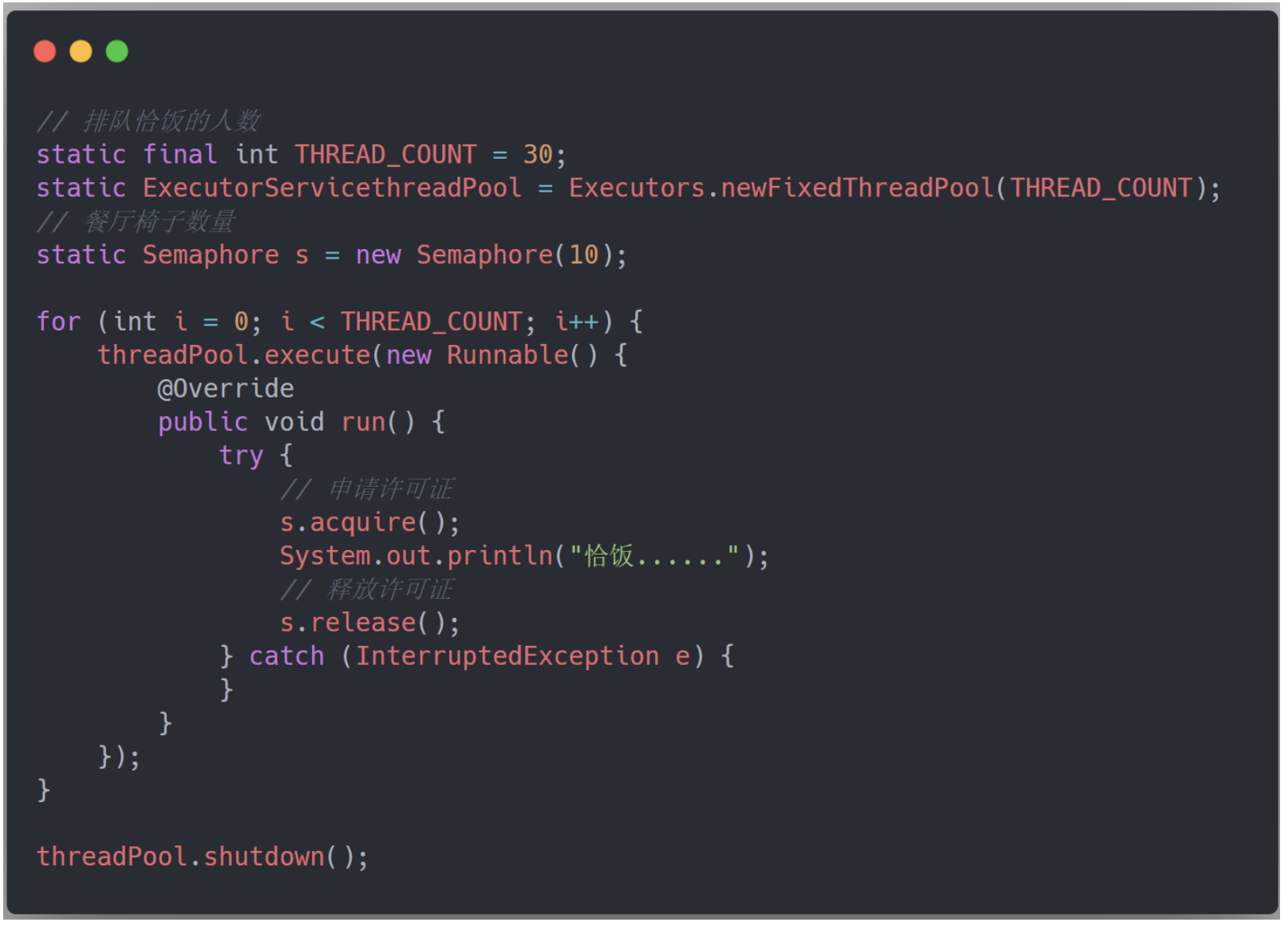
Semaphore 最大的用处就是做流量控制
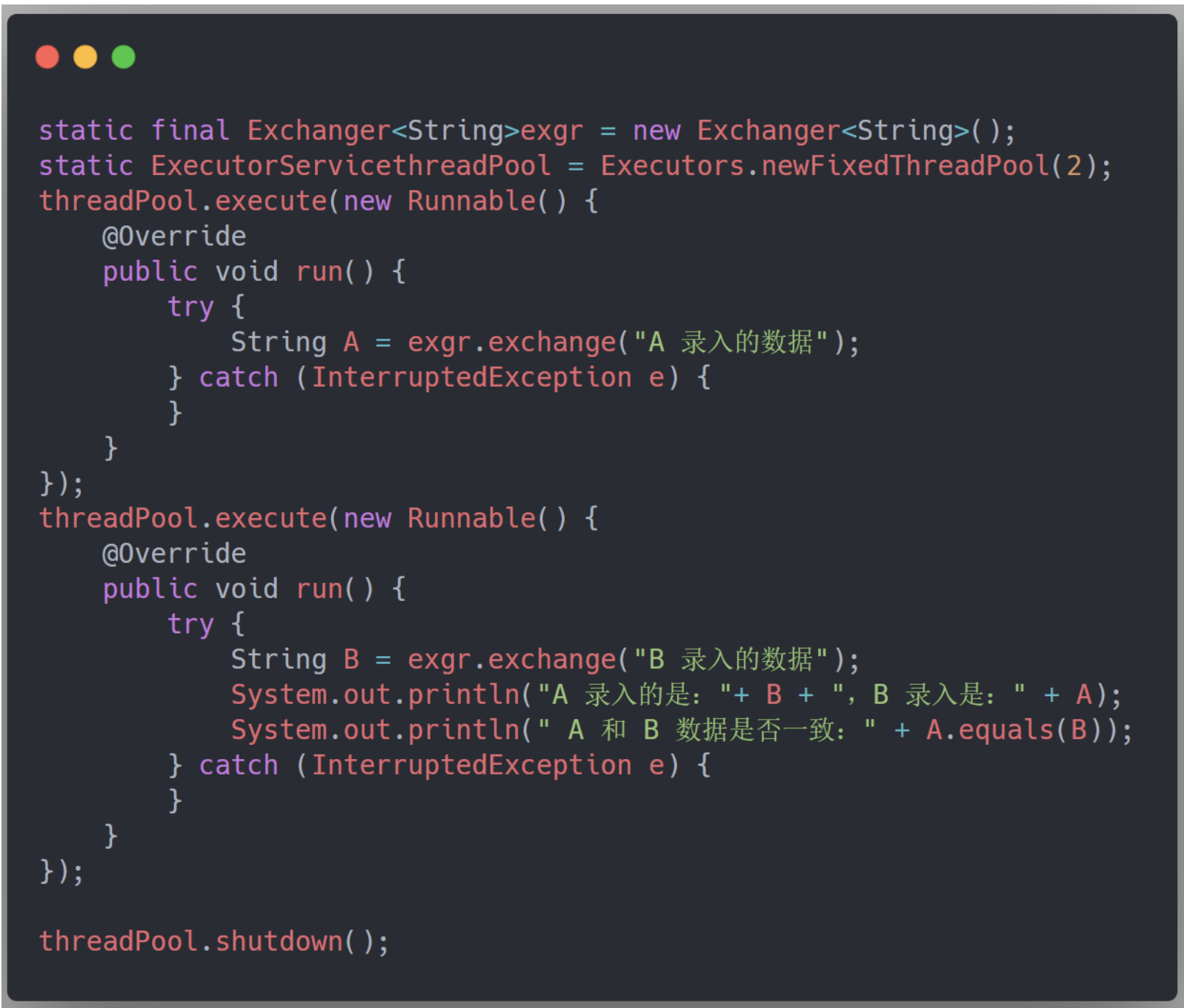
Exchanger
ThreadLocal
线程隔离术: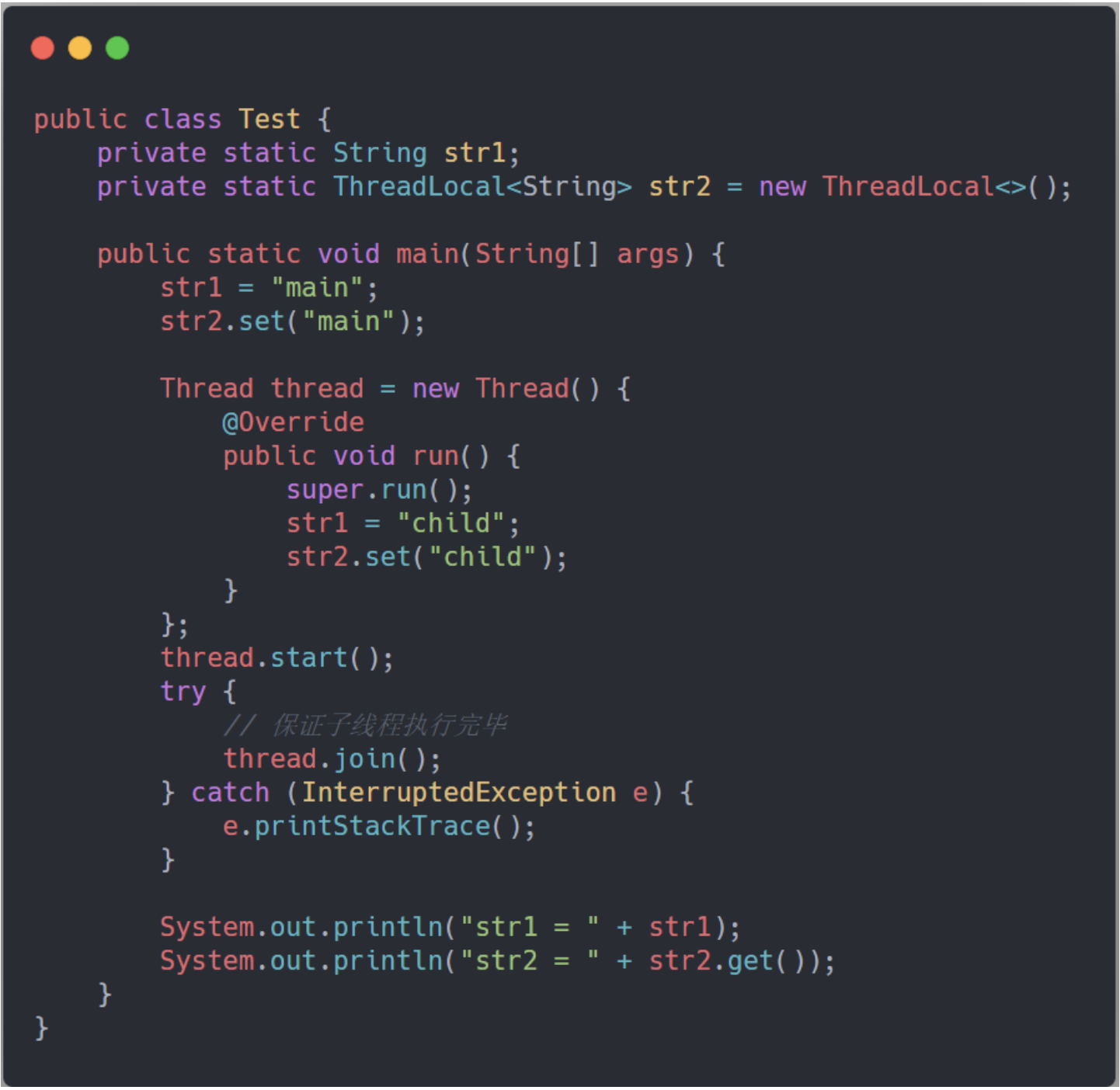
ThreadLocal 为什么能做到线程隔离
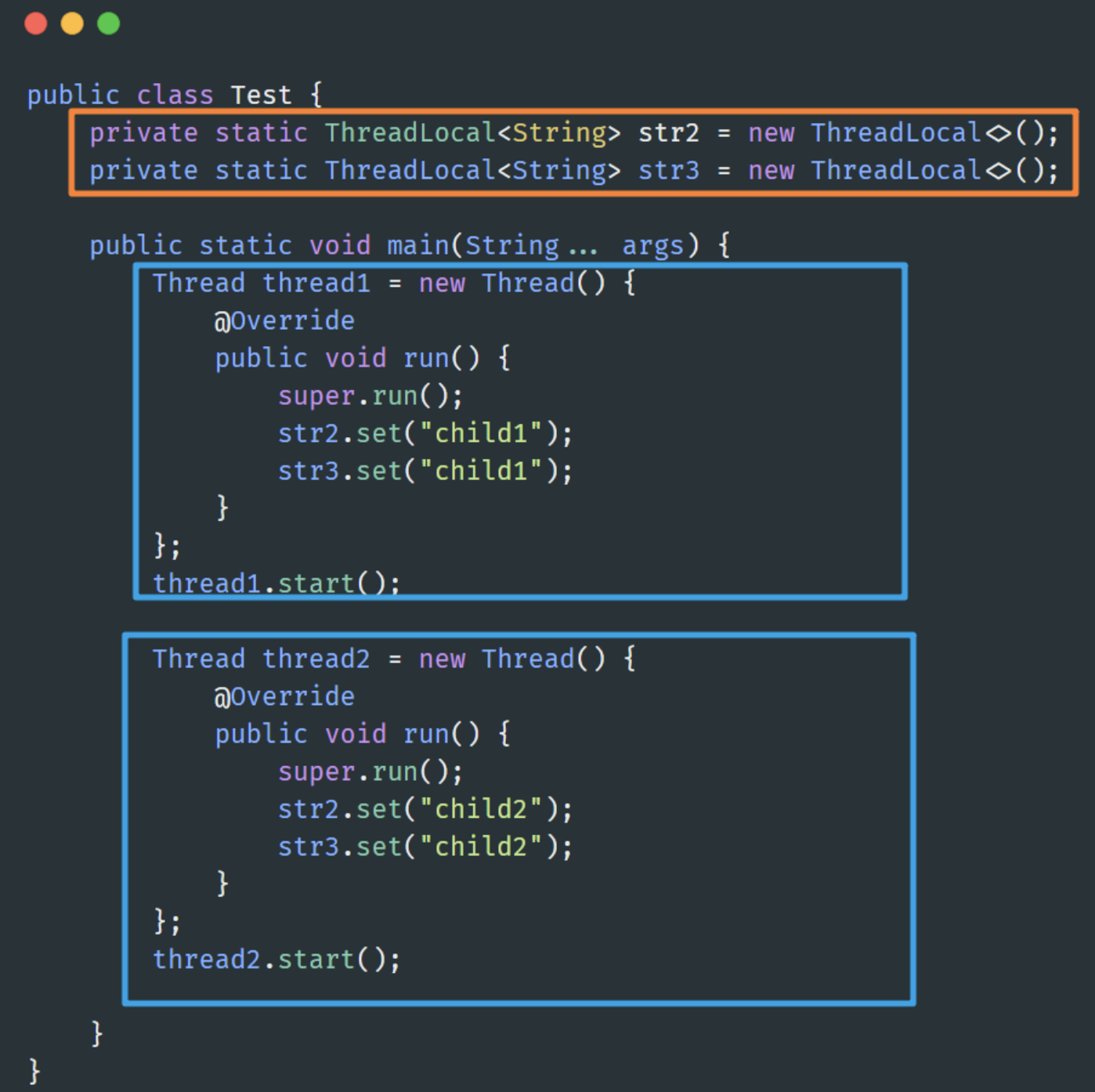
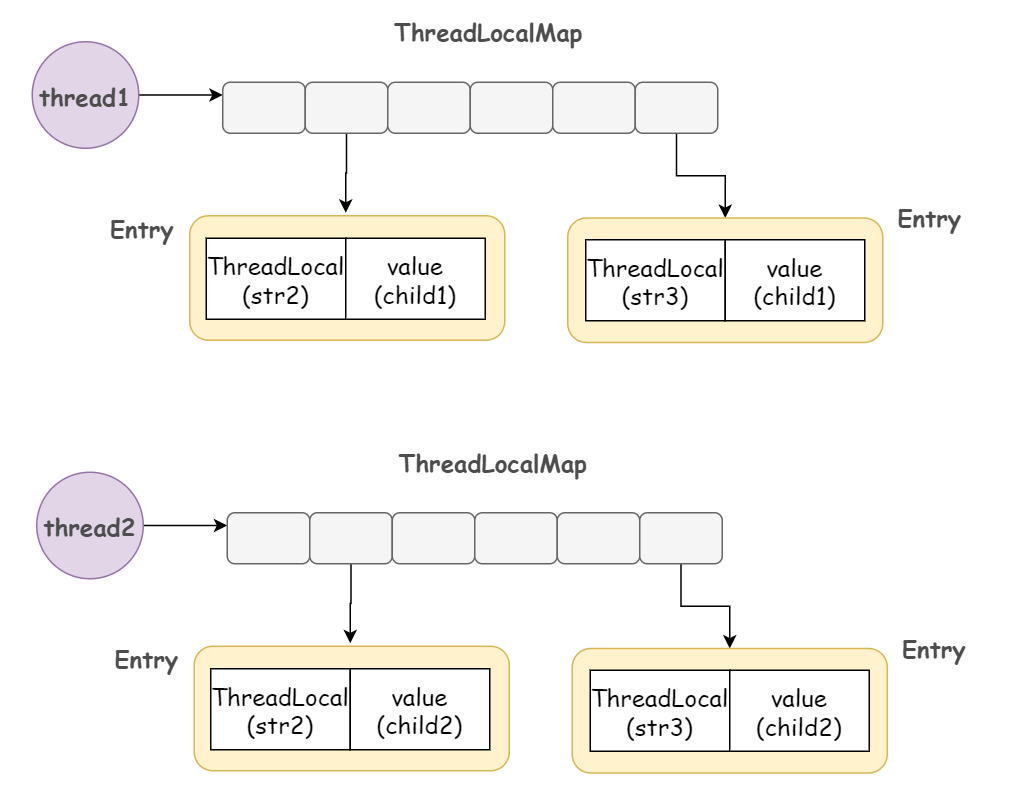
每个Thread 都维护了一个ThreadMap,Map的key就是ThreadLocal, value 是ThreadLocal set的值,所以ThreadLocal 可以做到线程隔离
ThreadLocal 经典之内存泄漏
要说 ThreadLocal 中最经典的知识点,当属内存泄漏了。为什么呢,我们来看一下 Entry 节点的具体实现就知道了: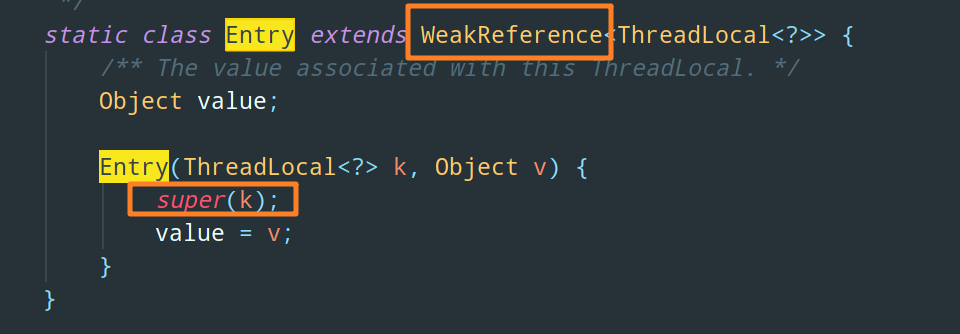
在 Entry 节点中,key 被保存到了 WeakReference(弱引用)对象中。
- 强引用:Java 中最常见的就是强引用,把一个对象赋给一个引用变量,这个引用变量就是一个强引用。当一个对象被强引用变量引用时,它是不可能被垃圾回收机制回收的,即使该对象以后永远都不会被用到。因此强引用是造成 Java 内存泄漏的主要原因之一
- 弱引用:只要垃圾回收机制一运行,不管 JVM 的内存空间是否足够,总会回收该对象占用的内存
为什么 key 要作为弱引用很好理解:
首先,ThreadLocalMap 是存在于 Thread 内部的,将 ThreadLocal 作为 key 扔到线程本身的的 Map 里,对吧。
在以往我们使用完对象以后等着 GC 来进行清理就行了。但如果 key(ThreadLocal) 是强引用,那就是说,这个 Thread 死亡之前,ThreadLocal 一直被该线程引用着,所以在这个线程销毁之前都是可达的,也即无法 GC,ThreadLocal 无法被回收。如果 ThreadLocal 太多的话,就会出现内存泄漏的问题。所以,key 需要被保存为弱引用。
虽然 key 被设计成弱应用了,可以从某种程度上避免内存泄漏,但是呢,value 仍然是强引用!
如果我们使用完 ThreadLocal 后,不对 key 为 null 的节点进行移除,还是会发生内存泄漏的
ThreadLocal 为我们提供了 remove 方法用来移除空节点,所以如果我们使用了 ThreadLocal 的 set 方法,最后一定要记得显示地调用 remove 方法: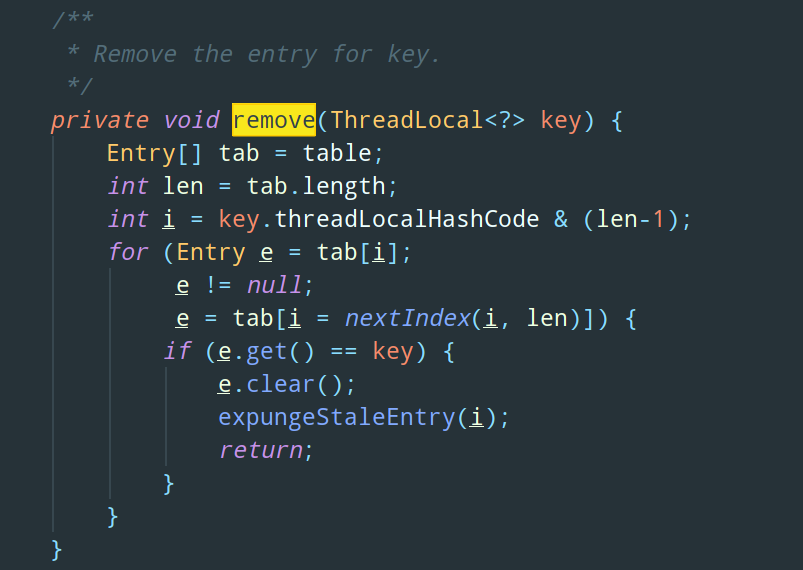
看到这里,不知道大伙儿有没有和我一样的疑问,那就是:value 为啥不和 key 一样设计成弱引用???
不设置为弱引用,是因为不清楚这个 value 除了 ThreadLocalMap 的引用还是否还存在其他引用。
如果 value 是弱引用且不存在其他引用的话,当 GC 的时候就会直接将这个 value 回收掉了,而此时我们的 ThreadLocal 还处于使用期间呢,就会报出 value 为 null 的错误。
所以仍然把 value 设置为强引用。
CompletableFuture

若有收获,就点个赞吧
0 人点赞
