CAS
乐观锁在 Java 中是采用 CAS 算法实现的,J.U.C 包中的原子类就是通过 CAS 算法来实现了乐观锁。使用这种 CAS 算法的代码也常被称为 无锁 编程(Lock-Free)。CAS 是一种算法,不要把 CAS 和乐观锁直接画等号。事实上,现代处理器基本都已经内置了实现 CAS 的指令,比如 x86 指令集上的 CAMPXCHG。
JMM 中不仅有主内存,每个线程还有各自的本地内存。每个线程会先更新自己的本地内存,然后再同步更新到主内存。
具体来说,CAS(Compare And Set):比较并替换,该算法中有重要的三个操作数:
- 需要读写的主内存位置(某个变量的值)
- 该变量原来应该有的值(检查值有没有发生变化)
- 线程想要把这个变量更新为哪个值。
只能保证一个共享变量的原子操作
当对一个共享变量执行操作时,我们确实可以使用循环 CAS 的方式来高效地保证原子操作,但是对多个共享变量操作时,循环 CAS 就无法保证操作的原子性了。
为什么呢?上文说过,x86 指令集上使用 CAMPCHG 来实现 CAS 操作,我们在一些源码里看到的 CAS 操作其实都是对这条底层指令的封装罢了,而这条指令的功能就是一次只原子地修改一个变量。
那如果想要同时原子地修改多个共享变量怎么办呢?
有两种方法:
1)最简单的一种:锁
2)第二种无锁方法,就是把多个共享变量合并成一个共享变量再来操作。比如,有两个共享变量 a = 1 和 b = 2,合并一下 ab = 12,然后用 CAS 来操作 ab。
同样地,针对这个问题,从 Java 1.5 开始,JDK 提供了 AtomicReference 类来保证引用对象之间的原子性,这样我们就可以把多个变量封装在一个对象里来进行 CAS 操作。
循环时间开销大
上面总结了 CAS 操作其实就是三步走嘛,在 “比较” 那一步,如果当前该变量的值与原来应该有的值不匹配,那就不会进行更新,开始自旋重试。自旋大家应该也都知道了,就是 CPU 空转,如果长时间自旋不成功,会给 CPU 带来相当大的执行开销。
至于如何解决循环时间开销大的问题,由于涉及的知识比较底层,所以各位做个了解即可,下文我也只是很浅地解释了一下。
其解决办法就是使 JVM 支持底层指令 pause,这个指令的功能就是当自旋失败时让 CPU 睡眠一小段时间再继续自旋,其有两个作用:
1)降低读操作的频率;
2)避免在退出循环的时候因 内存顺序冲突(Memory OrderViolation) 而引起 CPU 流水线被清空(CPU PipelineFlush)。
所谓内存顺序,就是 CPU 访问内存的顺序。对于 CAS 这种无锁方式来说,不同于 volatile 和 synchronized,它没有任何的 Happens-before 原则来约束重排序行为,所以在这种情况下可以说 CPU 是在乱序执行的。
当自旋锁快要释放的时候,持锁线程会有一个 store 命令,而外面自旋等待的线程会发出各自的 load 命令,如果发生重排序导致 load 出现在 store 之前,此时会进行流水线清空再重排序,显然这样会严重影响 CPU 的效率,而 pause 可以减少并行 load 的数量,从而减少重排序所耗费的时间。
UnSafe 与 原子类
UnSafe 类
Unsafe 类存在于 sun.misc 包中,单从名称看来就可以知道该类是非安全的,因为其内部方法操作可以像 C 的指针一样直接操作内存。所以事实上 Java 官方也不建议我们直接去使用 Unsafe 类。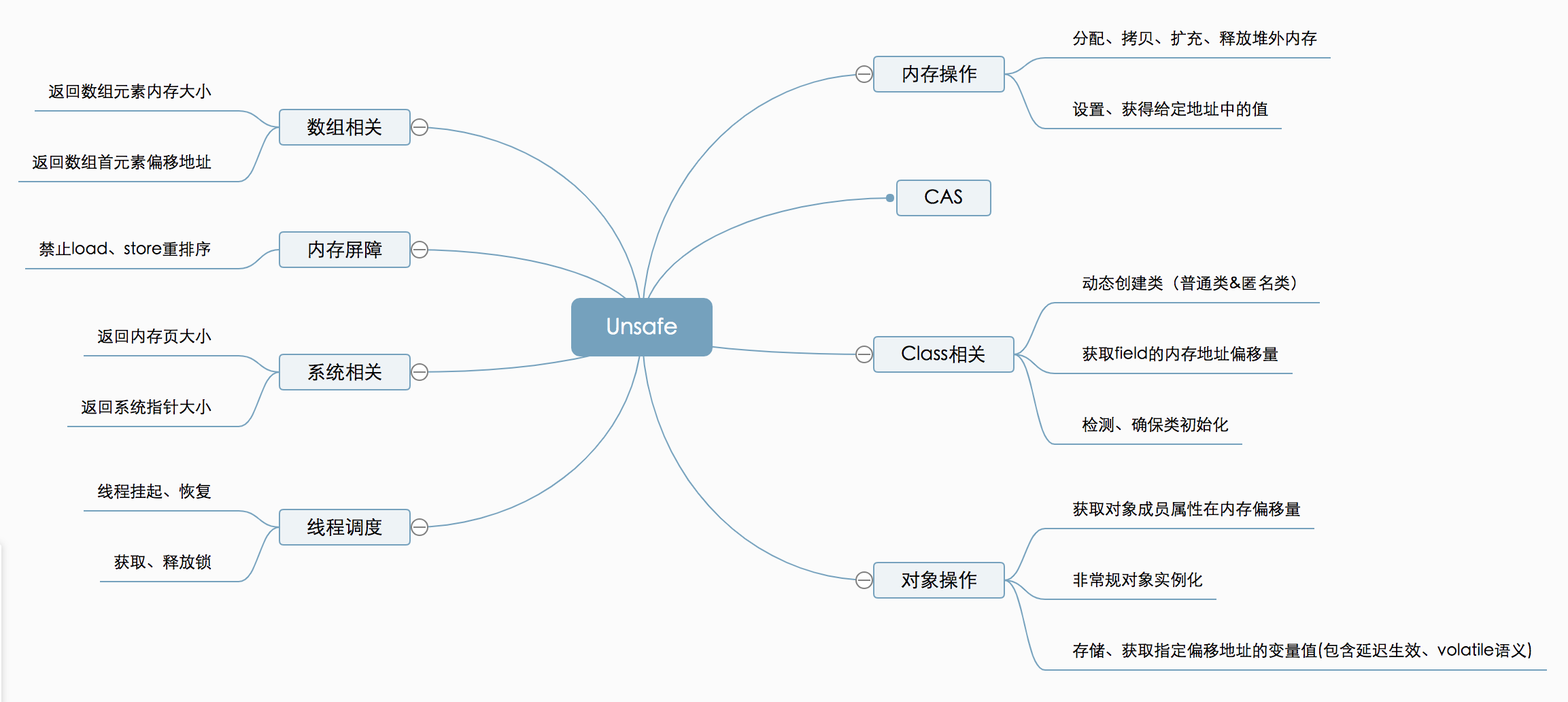
Unsafe 类中的所有方法都被 native 修饰,也就是说 Unsafe 类中的所有方法都是直接去调用底层操作系统资源去执行相应任务的。
Unsafe 类中与 CAS 相关的主要有以下 3 个方法:
public final native boolean compareAndSwapXxx(Object o, long offset, Object expected, Object update)
- 第一个参数 o 为给定对象,即包含要修改字段的对象
- 第二个参数 offset 为对象内存的偏移量,通过这个偏移量可以迅速定位字段并设置或获取该字段的值
- 第三个参数 expected 表示期望值
- 第四个参数 update 表示要设置的值
J.U.C 中很多类其实都会调用到 Unsafe 类的某个方法,比如 LockSupport 的 park 和 unpark 方法,其实际调用的就是 Unsafe 的 park、unpark 方法。所以,可以说 J.U.C 中的类大部分都是 Unsafe 的包装类。
原子类
原子类概览
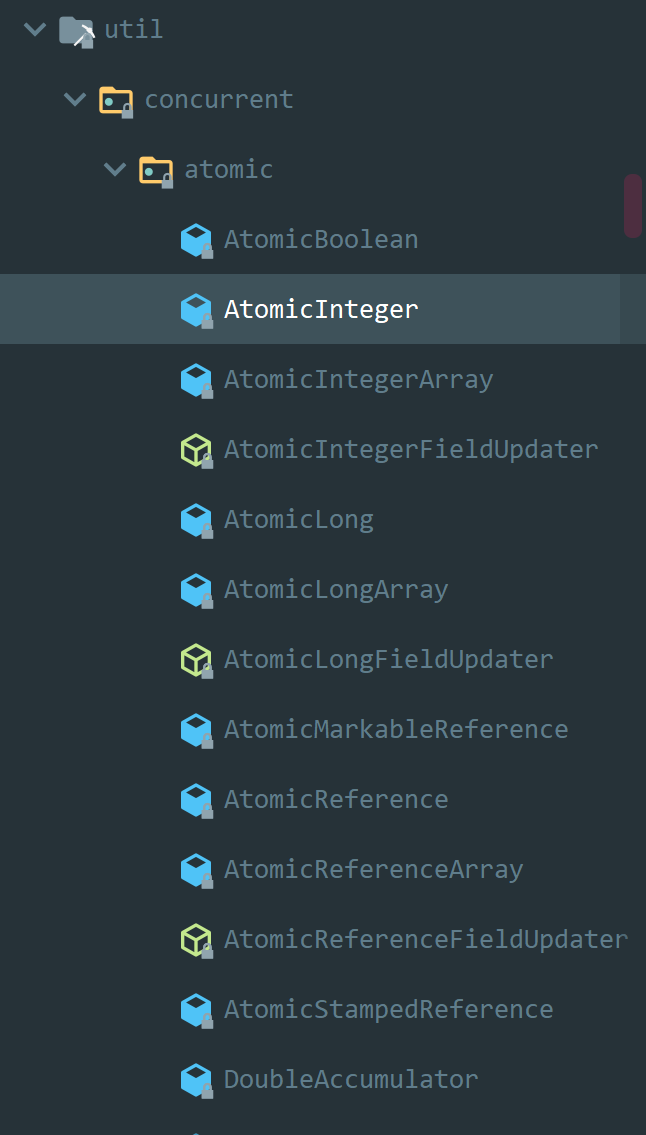
原子更新基本类型
- AtomicBoolean:原子更新布尔类型
- AtomicInteger:原子更新整型
-
原子更新数组
AtomicIntegerArray:原子更新整型数组里的元素
- AtomicLongArray:原子更新长整型数组里的元素
- AtomicReferenceArray:原子更新引用类型数组里的元素
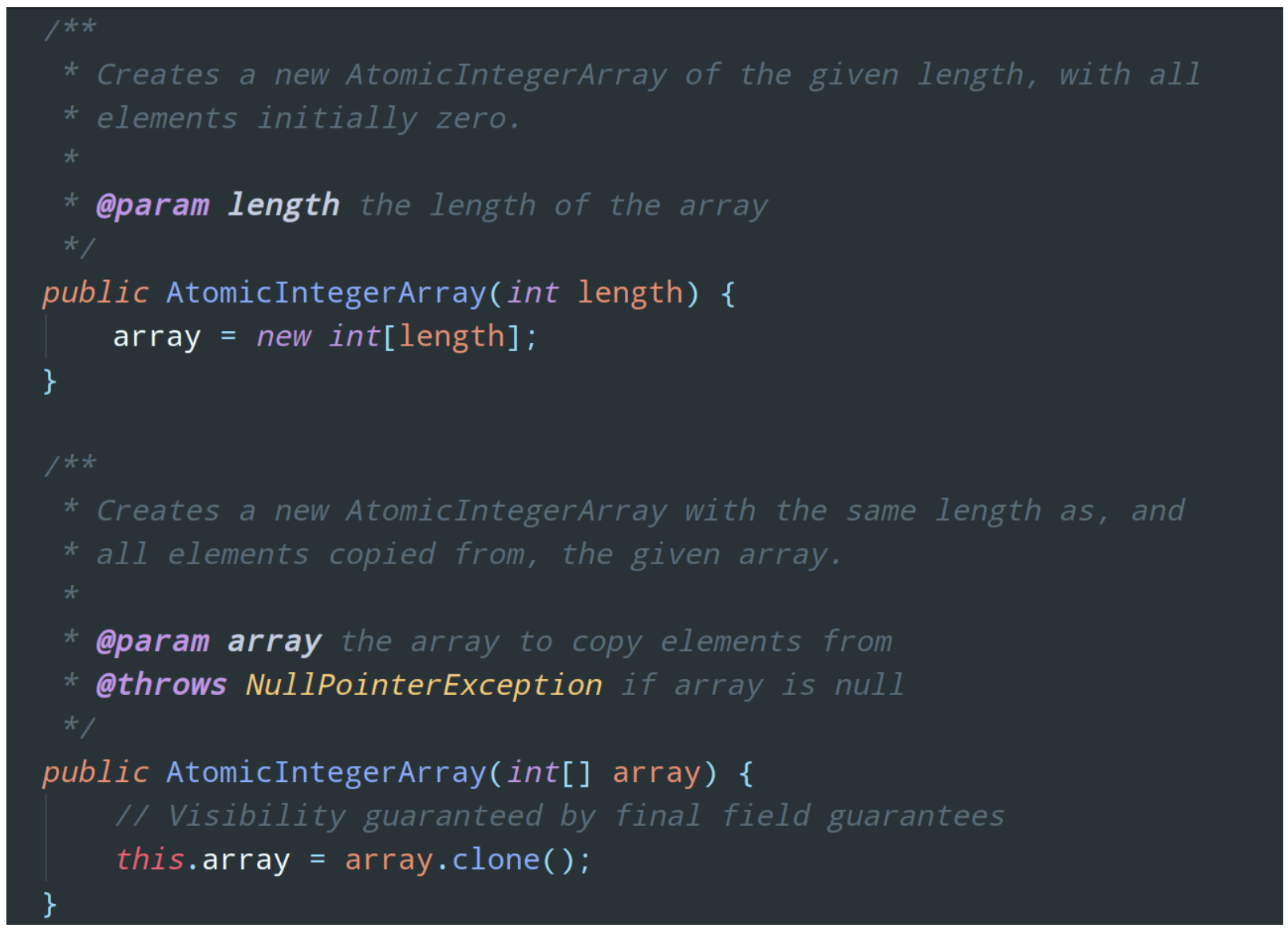
注意图片中的第二个构造函数!AtomicIntegerArray 会将当前数组 clone 一份,所以当 AtomicIntegerArray 对内部的数组元素进行修改时,是不会对传入的数组造成影响的。
来看下基本用法:
public class AtomicIntegerArrayTest {static int[] value = new int[] {1, 2, 3};static AtomicIntegerArray array = new AtomicIntegerArray(value);public static void main(String[] args) {array.getAndSet(0, 3)System.out.println(array.get(0)); // 输出 3System.out.println(value.get(0)); // 输出 1}}
原子更新引用
Atomic 包提供了以下 3 个类用来原子更新基本类型:
- AtomicReference:原子更新引用类型
- AtomicReferenceFieldUpdater:原子更新引用类型里的字段
- AtomicMarkableReference:原子更新带有标记位的引用类型

public class AtomicDemo {
private static AtomicReference<User> reference = new AtomicReference<>();
public static void main(String[] args) {
User user1 = new User("user1", 16);
reference.set(user1);
User user2 = new User("user2", 18);
reference.compareAndSet(user1, user2);
System.out.println(reference.get().getName()); // "user2"
}
static class User {
private String userName;
private int age;
public User(String userName, int age) {
this.userName = userName;
this.age = age;
}
}
}
首先构建一个 user 对象,然后把 user 对象设置进 AtomicReference 中,最后调用 compareAndSet 方法进行原子更新操作,当然其底层也是一样地调用了 Unsafe 类的 compareAndSet 方法。
原子更新属性
用来原子的地更新对象的某个字段
- AtomicIntegerFieldUpdater:原子更新整型字段
- AtomicLongFieldUpdater:原子更新长整型字段
- AtomicStampedReference:原子更新带有版本号的引用类型。这个类我们前文简单提到过,该类将整数值与引用关联起来,可用于原子的更新数据和数据的版本号,可以解决使用 CAS 进行原子更新时可能出现的 ABA 问题。

若有收获,就点个赞吧
0 人点赞
