注:索引是在存储引擎层实现的,而不是在服务器层实现的,所以不同存储引擎具有不同的索引类型和实现。
数据库的索引结构与种类
B树
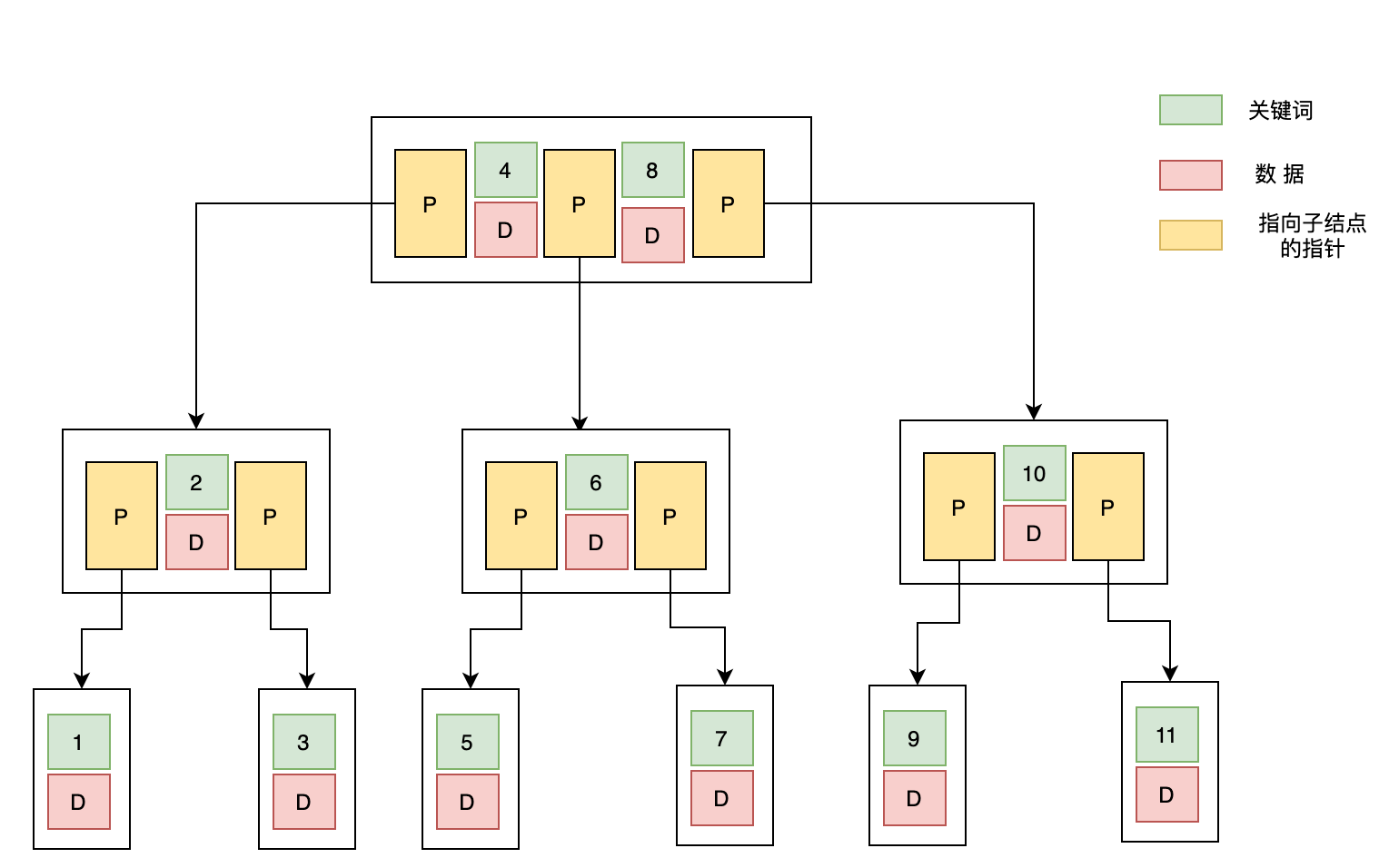
B 树索引,又称平衡树索引, 平衡搜索树的一种,是 MySQL 数据库中使用最频繁的索引类型,MySQL、Oracle 和 SQL Server 数据库默认的都是 B 树索引(实际是用 B+ 树实现的,因为在查看表索引时,MySQL 一律打印 BTREE,所以简称为 B 树索引)。
B 树索引以 树结构 组织,它有一个或者多个分支结点,分支结点又指向单级的叶结点。其中,分支结点用于遍历树,叶结点则保存真正的值和位置信息。
B+ 树是在 B 树基础上的一种优化,使其更适合实现外存储索引结构。
一棵 m 阶 B-Tree 的特性如下:
- 每个结点最多 m 个子结点;
- 除了根结点和叶子结点外,每个结点最少有 m/2(向上取整)个子结点;
- 所有的叶子结点都位于同一层;
- 每个结点都包含 k 个元素(关键字),这里 m/2≤k<m,这里 m/2 向下取整;
- 每个节点中的元素(关键字)从小到大排列;
- 每个元素子左结点的值,都小于或等于该元素,右结点的值都大于或等于该元素。
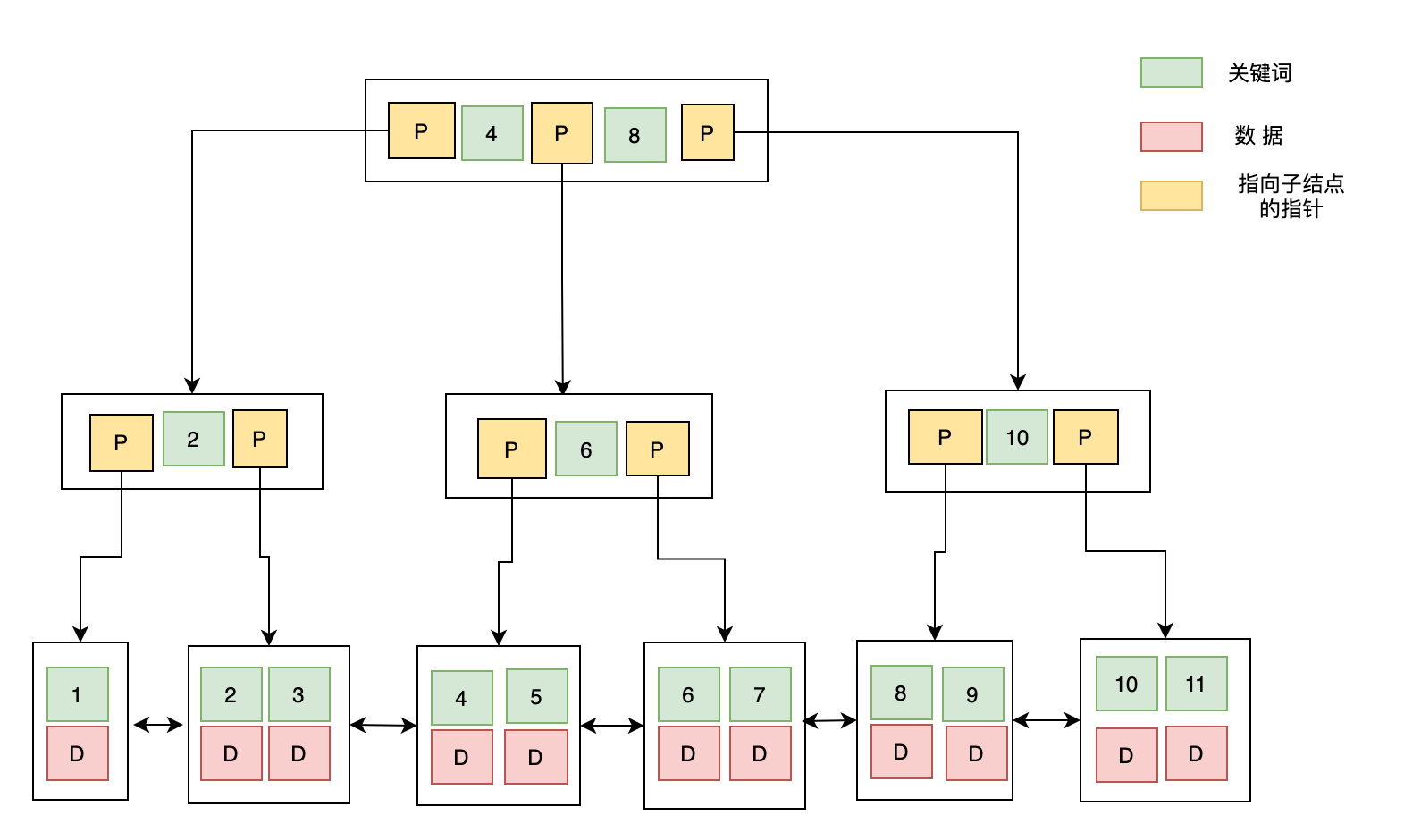
B+树
B+ Tree 与 B-Tree 的结构很像,但是也有自己的特性:
- 所有的非叶子结点只存储 关键字信息;
- 所有具体数据都存在叶子结点中;
- 所有的叶子结点中包含了全部元素的信息;
- 所有叶子节点之间都有一个链指针。
Hash 索引 (发生Hash碰撞时用链表形式存储)
哈希索引采用一定的 哈希算法(常见哈希算法有 直接定址法、平方取中法、折叠法、除数取余法、随机数法),将数据库字段数据转换成定长的 Hash 值,与这条数据的行指针一并存入 Hash 表的对应位置,如果发生 Hash 碰撞(两个不同关键字的 Hash 值相同),则在对应 Hash 键下以链表形式存储。
检索时不需要类似 B+ 树那样从根节点到叶子节点逐级查找,只需一次哈希算法即可立刻定位到相应的位置,速度非常快,平均检索时间为 O(1)。
自适应Hash索引
InnoDB 存储引擎有一个特殊的功能叫“自适应哈希索引”,当某个索引值被使用的非常频繁时,会在 B+Tree 索引之上再创建一个哈希索引,这样就让 B+Tree 索引具有哈希索引的一些优点,比如快速的哈希查找
位图索引
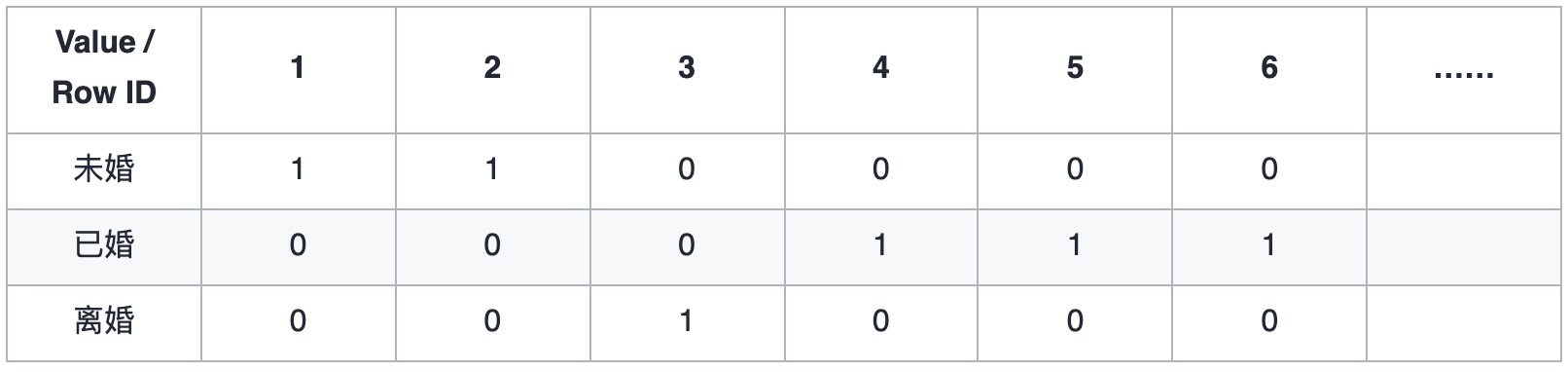
以上建立了三个位图,查询的时候就可以查询位图哪一个位值是1, 找到对应的row id。
oracle 可以建立位图索引
CREATE BITMAP INDEX acc_marital_idx ON account (marital_cd);
除了上述提及的,位图索引适合只有几个固定值的列,还需注意 ,位图索引适合静态数据,而不适合索引频繁更新的列。
B树, B+ 树,Hash 索引对比
- 由于 B+ 树的内部结点只存放键,不存放值,因此,一次读取,可以在同一内存页中获取更多的键,有利于更快地缩小查找范围。MySql 是用页来读取数据的,而页的大小是固定的,B+树只有叶子节点存放数据,所以个页可以存放更多的非叶子节点,减少了I/O 读取次数,从而更快。
B+ 树的高度固定,查询位O(logN)。 所有的数据都在B+ 树的叶子节点从小到大排列,适合范围查询。
Hash 索引适合等值查询而不是范围查询。
- Hash 索引不支持使用索引进行排序,B+ 树是搜索树的一种,数据可以是有序的
- Hash 索引不支持模糊查询以及多列索引的最左前缀匹配,原理也是因为 Hash 函数的不可预测;
- Hash 索引任何时候都避免不了回表查询数据,而 B+ 树在符合某些条件(聚簇索引,覆盖索引等)的时候可以只通过索引完成查询;
- Hash 索引虽然在等值查询上较快,但是不稳定,性能不可预测,当某个键值存在大量重复的时候,发生 Hash 碰撞,此时效率可能极差;而 B+ 树的查询效率比较稳定,对于所有的查询都是从根结点到叶子结点,且树的高度较低。
MySql 的索引为什么使用B+树而不是红黑树
- 红黑树是平衡二叉搜索树的一种,只有两个节点,树的高度会很高。磁盘IO次数多。
- 红黑树不适合范围查询。而且红黑树的调整过程很复杂。
什么是前缀索引
有时需要索引很长的字符列,它会使索引变大并且变慢,一个策略就是索引开始的几个字符,而不是全部值,即被称为 前缀索引,以节约空间并得到好的性能。使用前缀索引的前提是 此前缀的标识度高,比如密码就适合建立前缀索引,因为密码几乎各不相同。
前缀索引需要的空间变小,但也会降低选择性。索引选择性(INDEX SELECTIVITY)是不重复的索引值(也叫基数)和表中所有行数(T)的比值,数值范围为 1/T ~1。高选择性的索引有好外,因为在查找匹配的时候可以过滤掉更多的行,唯一索引的选择率为 1,为最佳值。对于前缀索引而言,前缀越长往往会得到好的选择性,但是短的前缀会节约空间,所以实操的难度在于前缀截取长度的抉择,可以通过调试查看不同前缀长度的 平均匹配度,来选择截取长度。什么是最左前缀匹配原则
聚簇索引与非聚簇索引
聚簇索引
又称 聚集索引, 首先并不是一种索引类型,而是一种数据存储方式。具体的,聚簇索引指将 数据存储 和 索引 放到一起,找到索引也就找到了数据。
MySQL 里只有 INNODB 表支持聚簇索引,INNODB 表数据本身就是聚簇索引,非叶子节点按照主键顺序存放,叶子节点存放主键以及对应的行记录。所以对 INNODB 表进行全表顺序扫描会非常快。
特点
- 因为索引和数据存放在一起,所以具有更高的检索效率;
- 相比于非聚簇索引,聚簇索引可以减少磁盘的 IO 次数;
- 表的物理存储依据聚簇索引的结构,所以一个数据表只能有一个聚簇索引,但可以拥有多个非聚簇索引;
- 一般而言,会在频繁使用、排序的字段上创建聚簇索引
非聚簇索引
除了聚簇索引以外的其他索引,均称之为非聚簇索引。非聚簇索引也是 B 树结构,与聚簇索引的存储结构不同之处在于,非聚簇索引中不存储真正的数据行,只包含一个指向数据行的指针。
就简单的 SQL 查询来看,分为 SELECT 和 WHERE 两个部分,索引的创建也是以此为根据的,分为 复合索引 和 覆盖索引。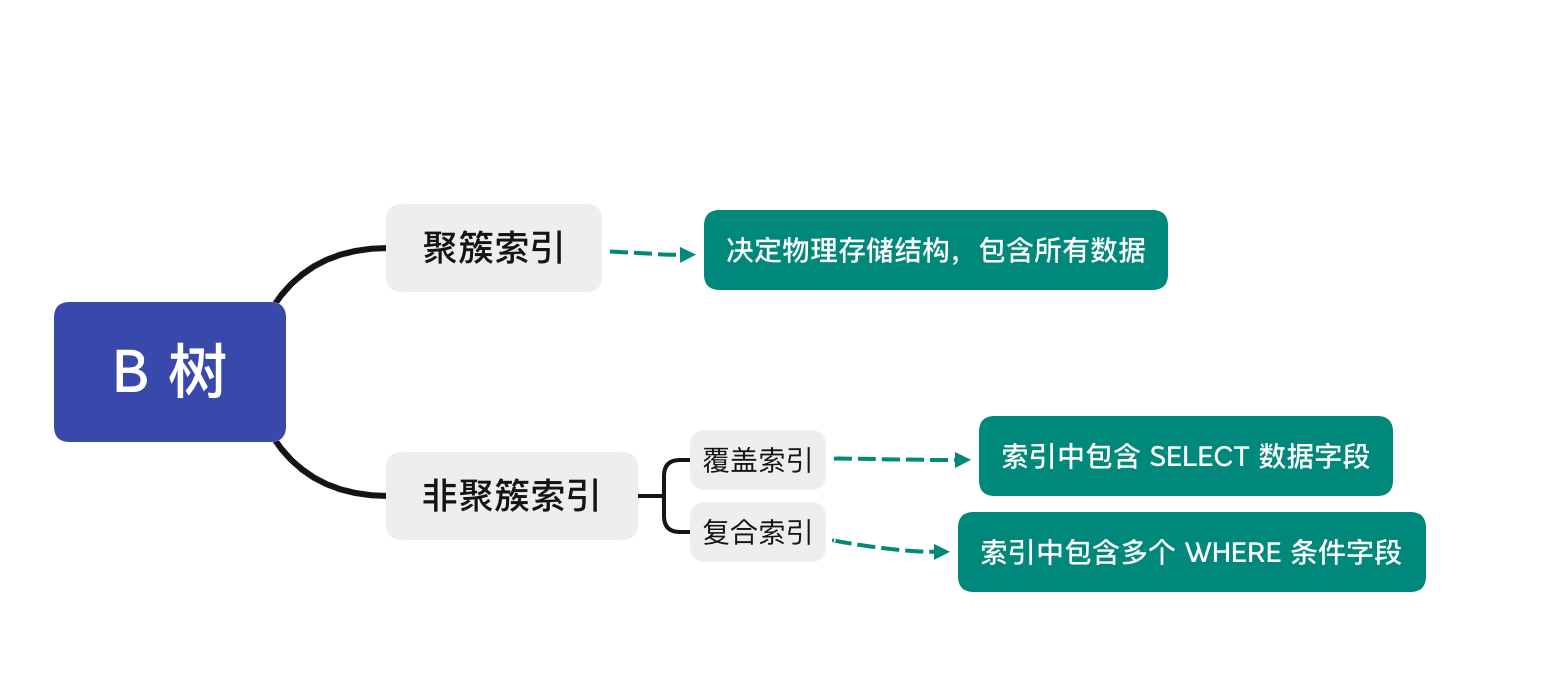
什么是回表查询
有用的链接;https://zhuanlan.zhihu.com/p/401198674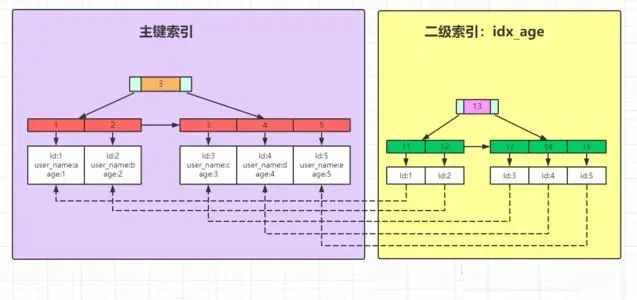
通俗的讲就是,如果索引的列在 select 所需获得的列中(因为在 mysql 中索引是根据索引列的值进行排序的,所以索引节点中存在该列中的部分值)或者根据一次索引查询就能获得记录就不需要回表,如果 select 所需获得列中有大量的非索引列,索引就需要到表中找到相应的列的信息,这就叫回表。
InnoDB聚集索引的叶子节点存储行记录,因此, InnoDB必须要有,且只有一个聚集索引:
(1)如果表定义了主键,则PK就是聚集索引;
(2)如果表没有定义主键,则第一个非空唯一索引(not NULL unique)列是聚集索引;
(3)否则,InnoDB会创建一个隐藏的row-id作为聚集索引;
索引覆盖
所谓覆盖索引就是指索引中包含了查询中的所有字段,这种情况下就不需要再进行回表查询了
建立索引的规则或者原则有哪些
- 表的主键、外键必须有索引;
- 数据量超过300的表应该有索引;
- 经常与其他表进行连接的表,在连接字段上应该建立索引;
- 经常出现在Where子句中的字段,特别是大表的字段,应该建立索引;
- 索引应该建在选择性高的字段上;
- 索引应该建在小字段上,对于大的文本字段甚至超长字段,不要建索引(或者取前缀)。
- 复合索引的建立需要进行仔细分析;尽量考虑用单字段索引代替:
- 频繁进行数据操作的表,不要建立太多的索引;
- 删除无用的索引,避免对执行计划造成负面影响;
- 在 查询中很少使用 或者参考的列不要创建索引。由于这些列很少使用到,增加索引反而会降低系统的维护速度和增大空间需求。
- 只有很少数据值的列 也不应该增加索引。由于这些列的取值很少,区分度太低,例如人事表中的性别,在查询时,需要在表中搜索的数据行的比例很大。增加索引,并不能明显加快检索速度。
- 定义为 text、image 和 bit 数据类型的列不应该增加索引。这是因为,这些列的数据量要么相当大,要么取值很少。
- 当 修改性能远远大于检索性能 时,不应该创建索引。这时因为,二者是相互矛盾的,当增加索引时,会提高检索性能,但是会降低修改性能。
- 定义有 外键 的数据列一定要创建索引。

若有收获,就点个赞吧
0 人点赞
