简介
Logstash是一个开源的、服务端的数据处理pipeline(管道),基于java编写,它可以接收多个源的数据、然后对它们进行转换、最终将它们发送到指定类型的目的地。Logstash是通过插件机制实现各种功能的,可以在https://github.com/logstash-plugins 下载各种功能的插件,也可以自行编写插件。
Logstash实现的功能主要分为接收数据、解析过滤并转换数据、输出数据三个部分,对应的插件依次是input插件、filter插件、output插件,其中,filter插件是可选的,其它两个是必须插件。也就是说在一个完整的Logstash配置文件中,必须有input插件和output插件。可以看出,filebeat是通过配置的方式处理数据,而logstash是通过插件的方式处理数据
下载
官网地址:https://www.elastic.co/cn/downloads/logstash,下载后解压至对应目录
tar -zxvf logstash-6.3.2.tar.gz -C /usr/logstash/
配置文件介绍
在config目录查看可配置的文件,
jvm.option:可以设置jvm参数,
log4j2.properties:设置输出日志级别,
logstash.yml:logstash全局配置文件
pipelines.yml:管道配置文件
startup.options:启动参数配置文件
启动
在配置Logstash之前,先来看一下logstash是如何实现输入和输出的。Logstash提供了一个shell脚本/usr/logstash/logstash-6.3.2/bin/logstash,可以方便快速的启动一个logstash进程,在Linux命令行下,运行如下命令启动Logstash进程:
文档截图: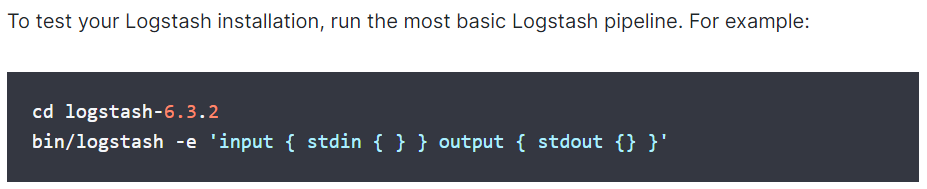
bin/logstash -e 'input{stdin{}} output{stdout{codec=>rubydebug}}'
各参数含义

- -e代表执行的意思。
- input即输入的意思,input里面即是输入的方式,这里选择了stdin,就是标准输入(从终端输入)。
- output即输出的意思,output里面是输出的方式,这里选择了stdout,就是标准输出(输出到终端)。
- 这里的codec是个插件,表明格式。这里放在stdout中,表示输出的格式,rubydebug是专门用来做测试的格式,一般用来在终端输出JSON格式。
命令执行后稍等一会会有以下输出: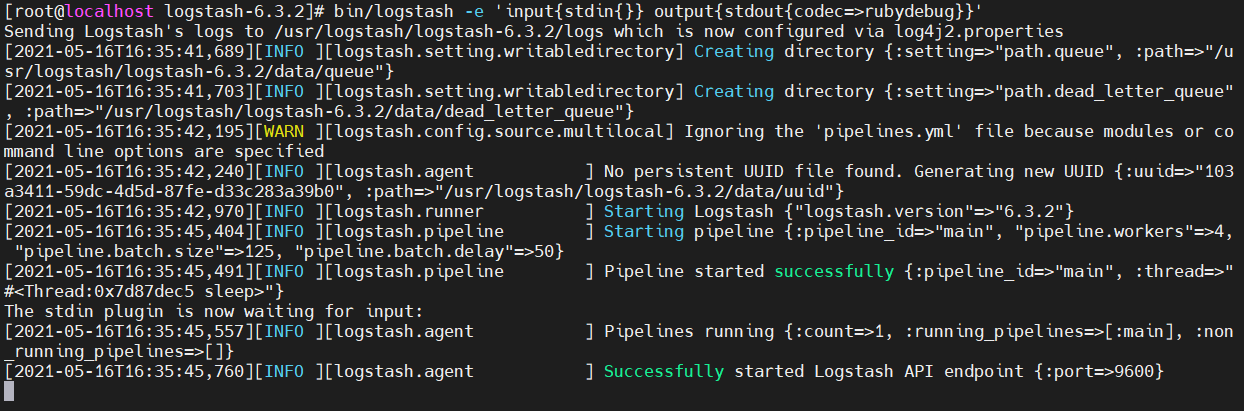
接下来我们在命令行输入,看看对应的日志信息输出
日志内容分析
这就是logstash的输出格式。Logstash在输出内容中会给事件添加一些额外信息。比如”@version”、”host”、”@timestamp” 都是新增的字段, 而最重要的是@timestamp ,用来标记事件的发生时间。由于这个字段涉及到Logstash内部流转,如果给一个字符串字段重命名为@timestamp的话,Logstash就会直接报错。另外,也不能删除这个字段。在logstash的输出中,常见的字段还有type,表示事件的唯一类型、tags,表示事件的某方面属性,我们可以随意给事件添加字段或者从事件里删除字段。
自定义启动配置文件
使用-e参数在命令行中指定配置是很常用的方式,但是如果logstash需要配置更多规则的话,就必须把配置固化到文件里,这就是logstash事件配置文件,如果把上面在命令行执行的logstash命令,写到一个配置文件logstash-myconf.conf中,内容如下:
input { stdin { }}output {stdout { codec => rubydebug }}
这就是最简单的Logstash事件配置文件。此时,可以使用logstash的-f参数来读取配置文件,然后启动logstash进程
//前台执行bin/logstash -f logstash-myconf.conf//后台执行nohup bin/logstash -f logstash-myconf.conf &//后台执行会当前目录会生成一个nohup.out文件,可通过此文件查看logstash进程的启动状态
执行结果 —— 前台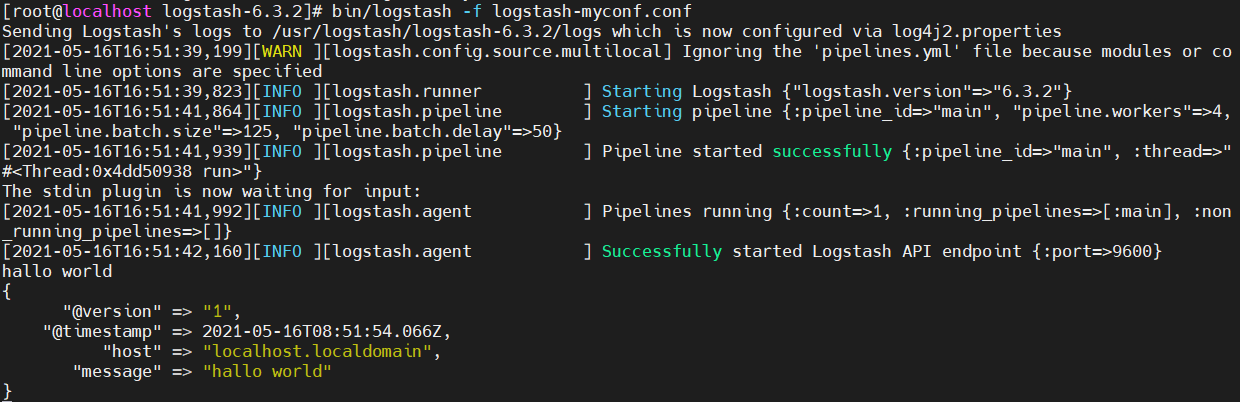
执行结果 —— 后台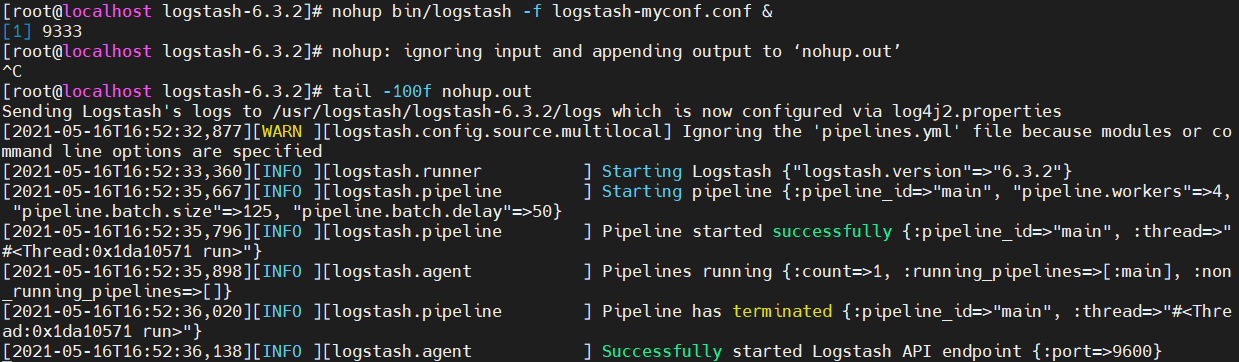
插件介绍
官方文档:https://www.elastic.co/guide/en/logstash/index.html
input
input插件主要用于接收数据,Logstash支持接收多种数据源,这里列举参见的几种:
file: 读取一个文件,这个读取功能有点类似于linux下面的tail命令,一行一行的实时读取。
input {file {path => "/var/log/messages"//多个文件path => ["/var/log/*.log","/var/log/message","/var/log/secure"]}}
syslog: 监听系统514端口的syslog messages,并使用RFC3164格式进行解析。
input {syslog {port => 514codec => RFC3164syslog_field => "syslog"grok_pattern => "<%{POSINT:priority}>%{SYSLOGTIMESTAMP:timestamp} CUSTOM GROK HERE"}}
redis: Logstash可以从redis服务器读取数据,此时redis类似于一个消息缓存组件。
input {redis {key => "logstash-demo"host => "192.168.126.91"password => "root"port => 6379db => "0"data_type => "list"type => "one"}}
kafka:Logstash也可以从kafka集群中读取数据,kafka加Logstash的架构一般用在数据量较大的业务场景,kafka可用作数据的缓冲和存储。
input {kafka {bootstrap_servers => "192.168.126.11:9092,192.168.126.12:9092,192.168.126.13:9092"topics => ["osmessages"]codec => "json"}}
filebeat:filebeat是一个文本日志收集器,性能稳定,并且占用系统资源很少,Logstash可以接收filebeat发送过来的数据。
input {beats {port => 5044}}
注意:这里需要将filebeat的默认输出改为输出到logstash,选择filebeat的安装目录下的filebeat.yml,进行设置
output.logstash:hosts: ["192.168.126.31:5044"]
filter
filter插件主要用于数据的过滤、解析和格式化,也就是将非结构化的数据解析成结构化的、可查询的标准化数据。常见的filter插件有如下几个:
grok:grok是Logstash最重要的插件,可解析并结构化任意数据,支持正则表达式,并提供了很多内置的规则和模板可供使用。此插件使用最多,但也最复杂。
- mutate: 此插件提供了丰富的基础类型数据处理能力。包括类型转换,字符串处理和字段处理等。
- date:此插件可以用来转换你的日志记录中的时间字符串。
GeoIP:此插件可以根据IP地址提供对应的地域信息,包括国别,省市,经纬度等,对于可视化地图和区域统计非常有用。
output
output插件用于数据的输出,一个Logstash事件可以穿过多个output,直到所有的output处理完毕,这个事件才算结束。输出插件常见的有如下几种:
elasticsearch: 发送数据到elasticsearch。
output {elasticsearch {hosts => ["192.168.126.101:9200","192.168.126.102:9200","192.168.126.103:9200"]index => "osmessageslog-%{+YYYY-MM-dd}"}}
file:发送数据到文件中。
output {file {path => "/usr/logs/oslogs"codec => line {format => "custom format: %{message}"}}}
redis:发送数据到redis中,从这里可以看出,redis插件既可以用在input插件中,也可以用在output插件中。
output {redis {data_type => "list"key => "logstash-demo"host => "192.168.126.91"port => 6379}}
kafka:发送数据到kafka中,与redis插件类似,此插件也可以用在Logstash的输入和输出插件中。
output {kafka {codec => "json"bootstrap_servers => "192.168.126.11:9092,192.168.126.12:9092,192.168.126.13:9092"topic_id => "osmessages"}}

若有收获,就点个赞吧
0 人点赞
