Logstash功能虽然强大,但是它依赖java、在数据量大的时候,Logstash进程会消耗过多的系统资源,这将严重影响业务系统的性能,而filebeat就是一个完美的替代者,filebeat是Beat成员之一,基于Go语言,没有任何依赖,配置文件简单,格式明了,同时,filebeat比logstash更加轻量级,所以占用系统资源极少,非常适合安装在生产机器上。
下载安装
官方下载地址:https://www.elastic.co/cn/downloads/beats/filebeat
选择自己对应的版本下载即可,解压下载后的包对应的目录为: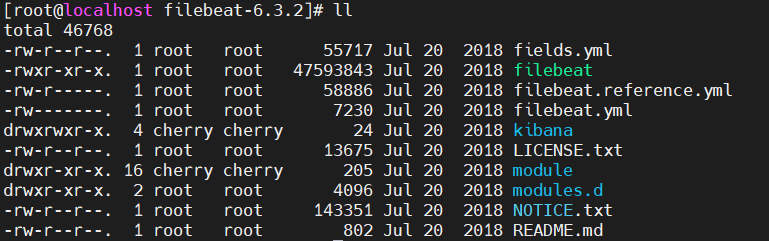
文件介绍
fields:
filebeat:二进制启动文件
filebeat.yml:filebeat配置文件
modules.d:配置模板文件,进去后有各种服务的日志收集模板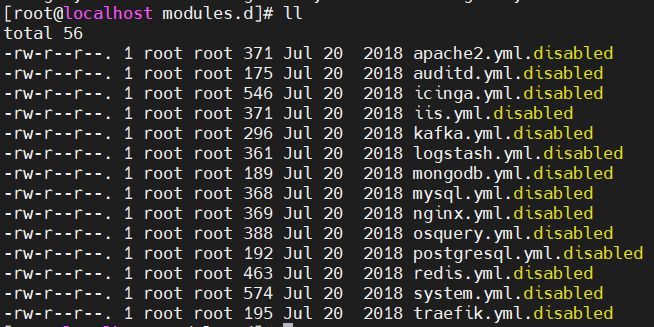
这些模板配置在官网有详细介绍:
1、使用命令来查看可使用的配置模板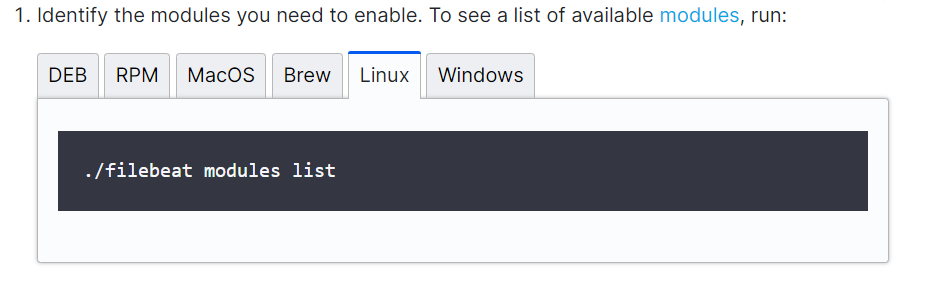
2、可以这样同时启动多个配置模板,这里启动了system,nginx,mysql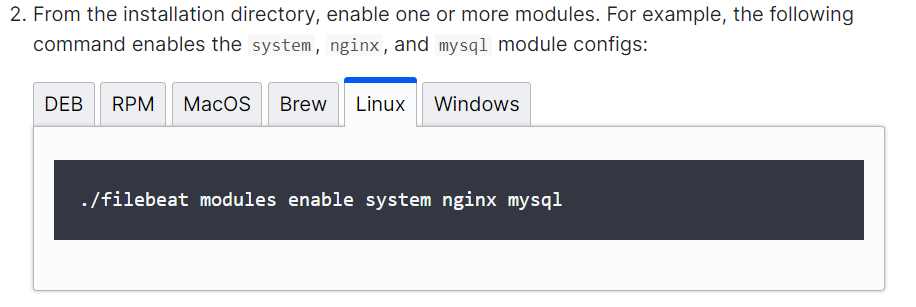
3、可以将对应的配置模板收集的日志输出到指定的目录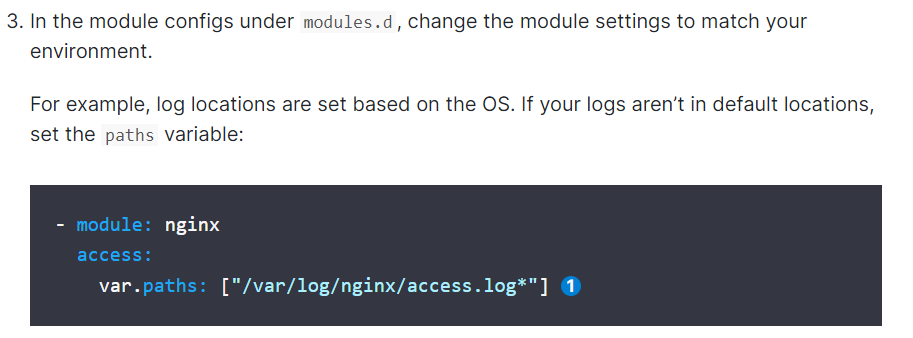
如需了解更多查看配置,请看modules文档,文档地址:
https://www.elastic.co/guide/en/beats/filebeat/current/configuration-filebeat-modules.html
配置
filebeat的配置文件为filebeat.yml,这里仅列出常用的配置项,内容如下:
filebeat.inputs:- type: logenabled: truepaths:- /var/log/messages- /var/log/securefields:log_topic: osmessagesname: "192.168.126.101"output.kafka:enabled: truehosts: ["192.168.126.11:9092", "192.168.126.12:9092", "192.168.126.13:9092"]version: "0.10"topic: '%{[fields][log_topic]}'partition.round_robin:reachable_only: trueworker: 2required_acks: 1compression: gzipmax_message_bytes: 10000000logging.level: debug
各配置项介绍
filebeat.inputs:用于定义数据原型。
type:指定数据的输入类型,这里是log,即日志,是默认值,还可以指定为stdin,即标准输入。?
enabled: true:启用手工配置filebeat,而不是采用模块方式配置filebeat。?
paths:用于指定要监控的日志文件,可以指定一个完整路径的文件,也可以是一个模糊匹配格式,例如:
- /data/nginx/logs/nginx_.log,该配置表示将获取/data/nginx/logs目录下的所有以.log结尾的文件,注意这里有个破折号“-”,要在paths配置项基础上进行缩进,不然启动filebeat会报错,另外破折号前面不能有tab缩进,建议通过空格方式缩进。
- /var/log/.log,该配置表示将获取/var/log目录的所有子目录中以”.log”结尾的文件,而不会去查找/var/log目录下以”.log”结尾的文件。
name: 设置filebeat收集的日志中对应主机的名字,如果配置为空,则使用该服务器的主机名。这里设置为IP,便于区分多台主机的日志信息。
output.kafka:filebeat支持多种输出,支持向kafka,logstash,elasticsearch输出数据,这里的设置是将数据输出到kafka。
nabled:表明这个模块是启动的。
host: 指定输出数据到kafka集群上,地址为kafka集群IP加端口号。
topic:指定要发送数据给kafka集群的哪个topic,若指定的topic不存在,则会自动创建此topic。注意topic的写法,在filebeat6.x之前版本是通过“%{[type]}”来自动获取document_type配置项的值。而在filebeat6.x之后版本是通过’%{[fields][log_topic]}’来获取日志分类的。
partition.round_robin:设置kafka选择partition的方式,robin指轮询的方式
worker:指worker数量
required_acks:指kafka生产和消费的机制,设置为1代表kafka的leader确定收到消息后才开始第二条的发送
compression:设置数据的压缩方式
max_message_bytes:指单条消息的最大长度
logging.level:定义filebeat的日志输出级别,有critical、error、warning、info、debug五种级别可选,在调试的时候可选择debug模式。
更多的配置项详情请查看官方文档:
https://www.elastic.co/guide/en/beats/filebeat/current/configuring-howto-filebeat.html
这里以输入和数据简单介绍:
输入
可配置的输入介质,这里看到可以收集到的日志包括了绝大部分的介质,例如网络日志,系统日志,各种缓存,协议日志,以及docker的容器日志,具体的配置可以点击对应的输入介质查看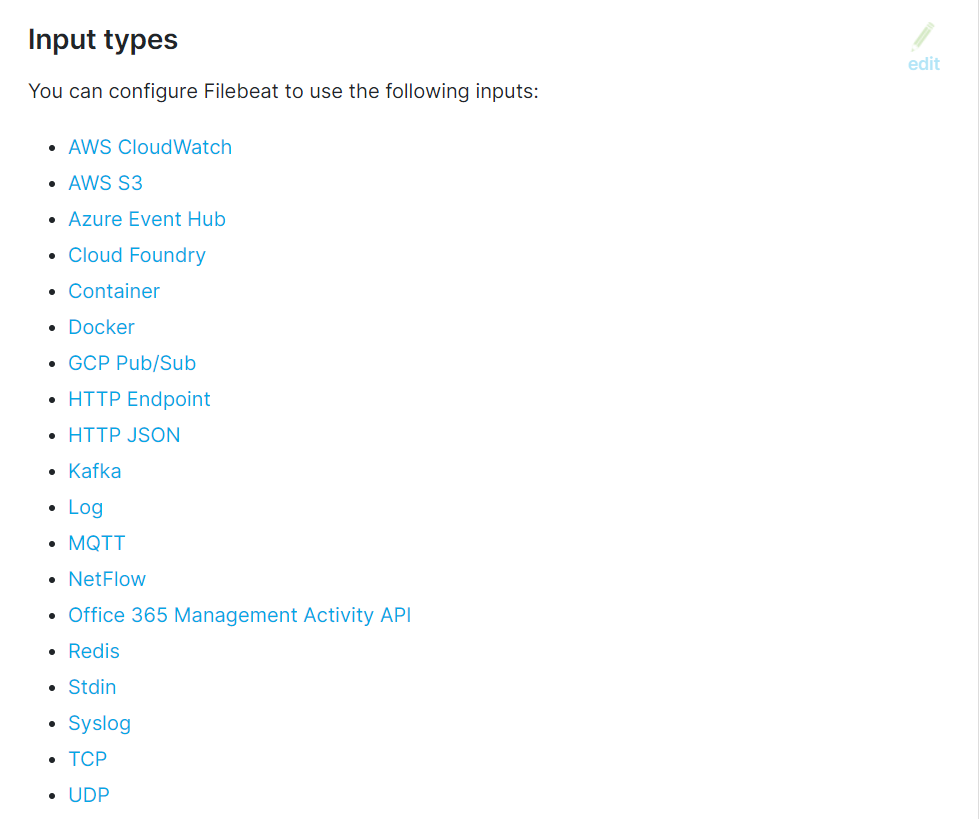
这里可以看到采集redis日志的配置(虽然这里说此功能还在测试阶段,可能后面会被移除或做部分修改,但不妨碍文档教学,哈哈哈),当然后面还有很多的可选配置,有兴趣的可以去看看哦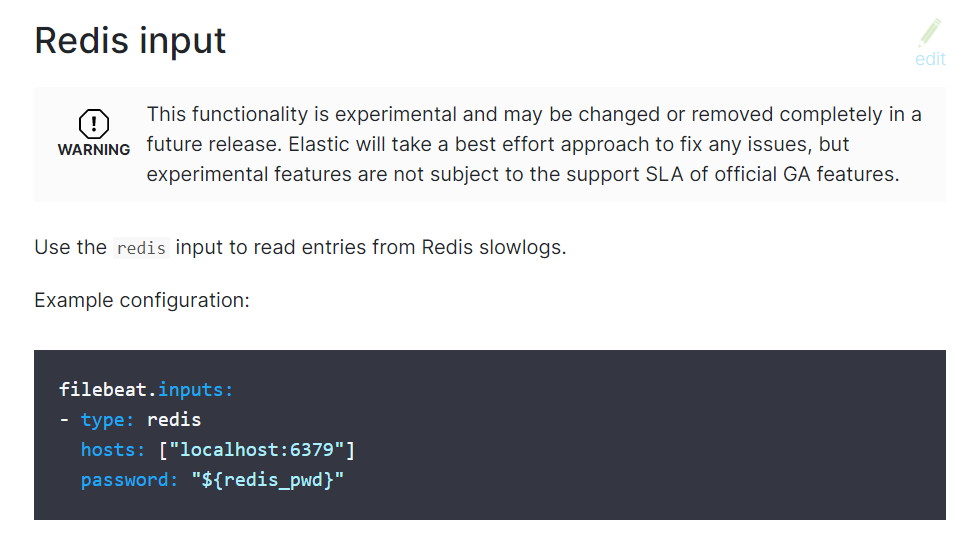
输出
可配置的输出介质,可以将日志直接输出到es中,也可以将日志通过kafka,redis等中间件来做桥梁,缓冲输出到对应的系统中,或者直接输出到控制台上
点击kafka可以看到输出日志到kafka最精简的配置,基本上和我们上面配置的差不多,哈哈哈
其他的有兴趣可以自己看看,官方文档写的是真滴不错

若有收获,就点个赞吧
0 人点赞
