安装
kafka作为apache的顶级开源项目,以其百万级TPS的吞吐量占领了大数据处理领域,外界号称性能怪兽,早期由LinkedIn公司基于独特的设计实现为一个分布式的提交日志系统( a distributed commit log),之后成为Apache项目的一部分。
相关文章:https://www.cnblogs.com/qcloud1001/p/8990527.html
接下看官网描述:Kafka是一个分布式的流处理平台

- 发布和订阅消息流(我们常说的MQ)
- 以容错的、持久的方式存储消息流(类似于缓存)
- 当消息流到来的时候,处理消息
下载地址:http://kafka.apache.org/downloads
src为源码包,选择二进制方式安装,选择对应的分支版本下载即可,在之前的kafka都需要和zookeeper保持对应的版本关系,以至于出现了使用了kafka就的加上zookeeper,用于作为kafka集群的管理,但是在最新的一次更新中,貌似kafka在慢慢的移除了zookeeper了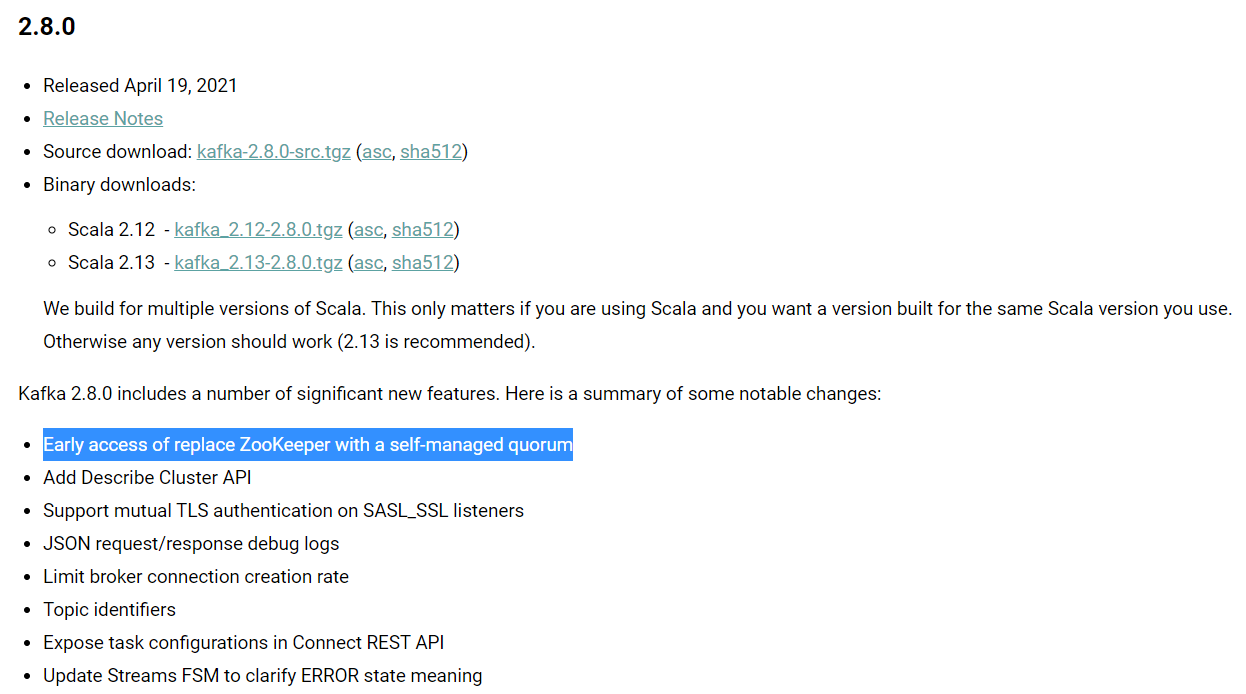
在以前的老版本中,基本上每次kafka的打更新都会携带zookeeper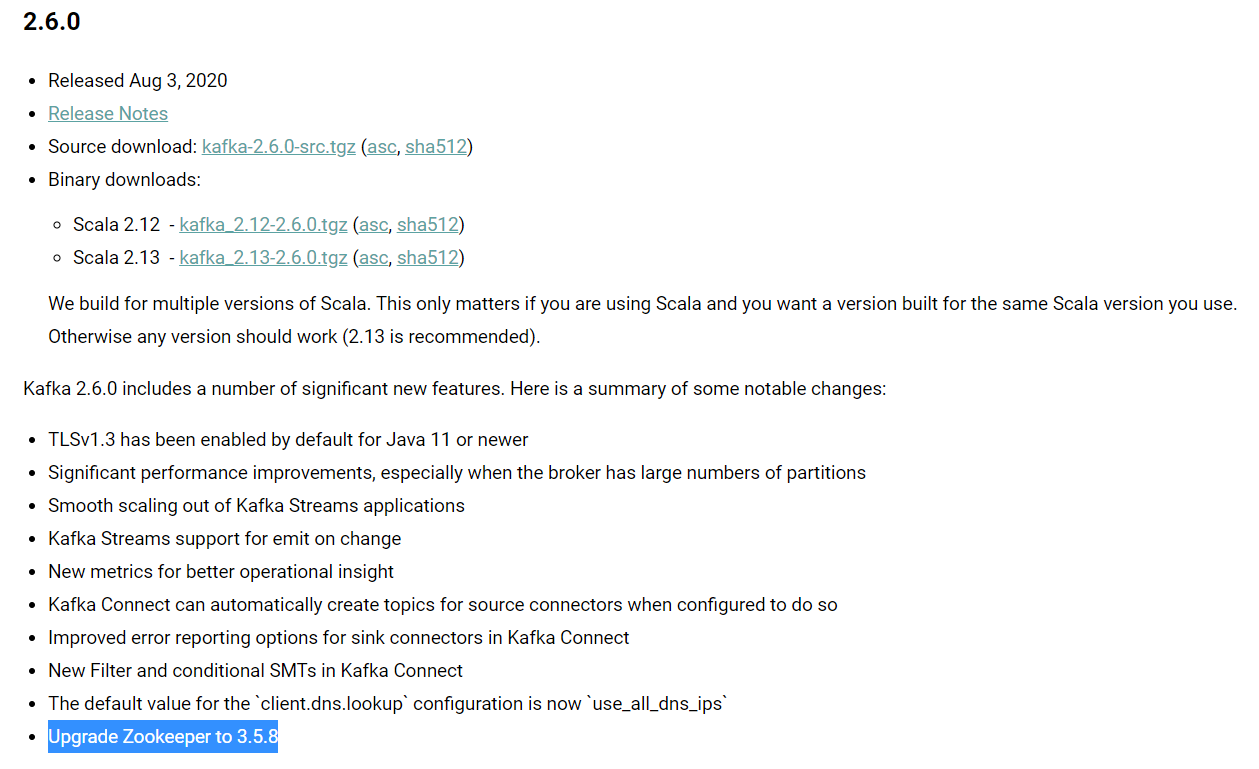
配置
这里将kafka安装到/usr/kafka/kafka-2.10目录下,因此,kafka的主配置文件为/usr/kafka/kafka-2.10/config/server.properties,接下来在文件中配置以下信息
broker.id=1listeners=PLAINTEXT://172.16.213.51:9092log.dirs=/usr/local/kafka/logsnum.partitions=6log.retention.hours=60log.segment.bytes=1073741824zookeeper.connect=172.16.213.51:2181,172.16.213.75:2181,172.16.213.109:2181auto.create.topics.enable=truedelete.topic.enable=true
每个配置项含义如下
broker.id:每一个broker在集群中的唯一表示,要求是正数。当该服务器的IP地址发生改变时,broker.id没有变化,则不会影响consumers的消息情况。
listeners:设置kafka的监听地址与端口,可以将监听地址设置为主机名或IP地址,这里将监听地址设置为IP地址。
log.dirs:这个参数用于配置kafka保存数据的位置,kafka中所有的消息都会存在这个目录下。可以通过逗号来指定多个路径, kafka会根据最少被使用的原则选择目录分配新的parition。需要注意的是,kafka在分配parition的时候选择的规则不是按照磁盘的空间大小来定的,而是根据分配的 parition的个数多小而定。
num.partitions:这个参数用于设置新创建的topic有多少个分区,可以根据消费者实际情况配置,配置过小会影响消费性能。这里配置6个(节点数 * 2)。
log.retention.hours:这个参数用于配置kafka中消息保存的时间,还支持log.retention.minutes和 log.retention.ms配置项。这三个参数都会控制删除过期数据的时间,推荐使用log.retention.ms。如果多个同时设置,那么会选择最小的那个。
log.segment.bytes:配置partition中每个segment数据文件的大小,默认是1GB,超过这个大小会自动创建一个新的segment file。
zookeeper.connect:这个参数用于指定zookeeper所在的地址,它存储了broker的元信息。 这个值可以通过逗号设置多个值,每个值的格式均为:hostname:port/path,每个部分的含义如下:
hostname:表示zookeeper服务器的主机名或者IP地址,这里设置为IP地址。
port: 表示是zookeeper服务器监听连接的端口号。
/path:表示kafka在zookeeper上的根目录。如果不设置,会使用根目录。
auto.create.topics.enable:这个参数用于设置是否自动创建topic,如果请求一个topic时发现还没有创建, kafka会在broker上自动创建一个topic,如果需要严格的控制topic的创建,那么可以设置auto.create.topics.enable为false,禁止自动创建topic。
delete.topic.enable:在0.8.2版本之后,Kafka提供了删除topic的功能,但是默认并不会直接将topic数据物理删除。如果要从物理上删除(即删除topic后,数据文件也会一同删除),就需要设置此配置项为true。
启动
注意:因为kafka注册到了zookeeper上,所以在启动kafka集群前,需要确保ZooKeeper集群已经正常启动
# 切换到kafka的安装目录执行以下命令
nohup bin/kafka-server-start.sh config/server.properties &
# 也可以使用jps查看进程
nohup表示这里将kafka放到后台运行,启动后,会在启动kafka的当前目录下生成一个nohup.out文件,可通过此文件查看kafka的启动和运行状态。通过jps指令,可以看到有个Kafka标识,这是kafka进程成功启动的标志。
使用
kafka提供了多个命令用于查看、创建、修改、删除topic信息,也可以通过命令测试如何生产消息、消费消息等,这些命令位于kafka安装目录的bin目录下,这里是/usr/kafka/kafka-2.10/bin。登录任意一台kafka集群节点,切换到此目录下,即可进行命令操作。下面列举kafka的一些常用命令的使用方法。

若有收获,就点个赞吧
0 人点赞
