![5122}9DA{Z2CK0TL%SUUC.png
分析器(analyzer)有三部分组成
char filter : 字符过滤器
tokenizer : 分词器
token filter :token过滤器
_char filter(字符过滤器)
字符过滤器以字符流的形式接收原始⽂本,并可以通过添加、删除或更改字符来转换该流。⼀个分析器可能有0个或多个字符过滤器。
tokenizer (分词器)
⼀个分词器接收⼀个字符流,并将其拆分成单个token (通常是单个单词),并输出⼀个token流。⽐如使⽤whitespace分词器当遇到空格的时候会将⽂本拆分成token。“eating an apple” >> [eating, and, apple]。⼀个分析器必须只能有⼀个分词器
token filter (token过滤器)
token过滤器接收token流,并且可能会添加、删除或更改tokens。⽐如⼀个lower case token filter可以将所有的token转成⼩写。⼀个分析器可能有0个或多个token过滤器,它们按顺序应⽤。
es自带的分词器:
standard分析器
- tokenizer
- Stanard tokenizer
- token filters
- Standard Token Filter
- Lower Case Token Filter
对英文的支持比较好,对中文的分词就比较差,要对中文进行分词,推荐使用ik分词器。
ik分词器
1.下载:网上一般推荐都是去https://github.com/medcl/elasticsearch-analysis-ik/releases 上下载与自己es版本对应的ik压缩包。我这边是直接git clone https://github.com/medcl/elasticsearch-analysis-ik/releases ,将源码更新到本地,可以根据自己的需要来编译出对应版本的ik压缩包。如下图所示
只需要改pom.xml文件中elasticsearch.version的版本,在package的时候会去自动下载对应版本的es包,生成ik压缩包
这样的好处就是当自己的es版本更新时方便切换ik版本,不需要再去github上下载对应版本ik包。
2.安装:在es服务的plugin目录,新建ik文件夹
将ik压缩包添加到该目录下,并解压,再重启es服务器,即可生效。
3.ik分词器与standard分词器中文分词对比,拿我本地es服务中存在的index(index:product,字段名:name,书名:”白鹿原”)来进行比较
1)ik_max_word(文本最细粒度匹配)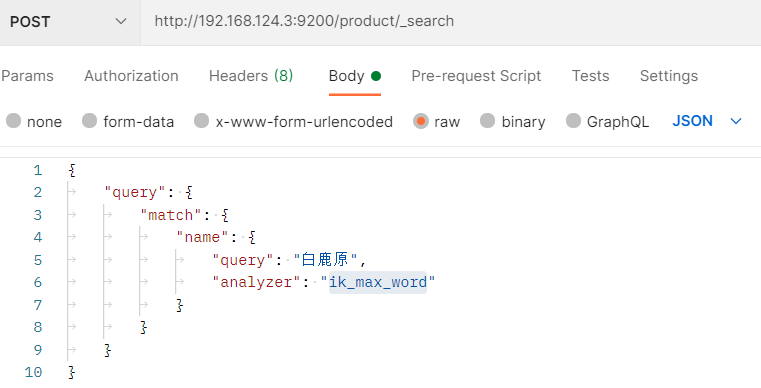
结果:
{
“took”: 2,
“timed_out”: false,
“_shards”: {
“total”: 1,
“successful”: 1,
“skipped”: 0,
“failed”: 0
},
“hits”: {
“total”: {
“value”: 11,
“relation”: “eq”
},
“max_score”: 21.436504,
“hits”: [
{
“_index”: “product”,
“_type”: “_doc”,
“_id”: “1010000100946369”,
“_score”: 21.436504,
“_source”: {
“_class”: “com.example.demo.domain.Product”,
“id”: 1010000100946369,
“name”: “白鹿原(陈忠实集长篇小说)(精)”,
“url”: “//item.xhsd.com/items/1010000100946369”,
“price”: 34.2,
“shop”: “陈忠实”,
“date”: “2021-06-08 15:24:44”
}
},
{
“_index”: “product”,
“_type”: “_doc”,
“_id”: “110000100409047”,
“_score”: 18.320427,
“_source”: {
“_class”: “com.example.demo.domain.Product”,
“id”: 110000100409047,
“name”: “白鹿原(新中国70年70部长篇小说典藏)”,
“url”: “//item.xhsd.com/items/110000100409047”,
“price”: 39.9,
“shop”: “陈忠实”,
“date”: “2021-06-08 15:30:27”
}
},
{
“_index”: “product”,
“_type”: “_doc”,
“_id”: “1010000101607417”,
“_score”: 16.519442,
“_source”: {
“_class”: “com.example.demo.domain.Product”,
“id”: 1010000101607417,
“name”: “白鹿原(陈忠实小说自选集现当代长篇小说经典)”,
“url”: “//item.xhsd.com/items/1010000101607417”,
“price”: 36.1,
“shop”: “陈忠实”,
“date”: “2021-06-08 15:24:25”
}
},
{
“_index”: “product”,
“_type”: “_doc”,
“_id”: “1010000102804389”,
“_score”: 8.095207,
“_source”: {
“_class”: “com.example.demo.domain.Product”,
“id”: 1010000102804389,
“name”: “游神/马原小说”,
“url”: “//item.xhsd.com/items/1010000102804389”,
“price”: 15.68,
“shop”: “马原著”,
“date”: “2021-06-08 15:31:59”
}
},
{
“_index”: “product”,
“_type”: “_doc”,
“_id”: “1010000101178261”,
“_score”: 7.6804366,
“_source”: {
“_class”: “com.example.demo.domain.Product”,
“id”: 1010000101178261,
“name”: “猎原/西部人文小说系列”,
“url”: “//item.xhsd.com/items/1010000101178261”,
“price”: 28.5,
“shop”: “雪漠”,
“date”: “2021-06-08 15:23:12”
}
},
{
“_index”: “product”,
“_type”: “_doc”,
“_id”: “1010000102506141”,
“_score”: 6.9665523,
“_source”: {
“_class”: “com.example.demo.domain.Product”,
“id”: 1010000102506141,
“name”: “猎原(插图版)(精)/西部小说系列”,
“url”: “//item.xhsd.com/items/1010000102506141”,
“price”: 74.1,
“shop”: “雪漠”,
“date”: “2021-06-08 15:26:23”
}
},
{
“_index”: “product”,
“_type”: “_doc”,
“_id”: “1010000102502345”,
“_score”: 6.9665523,
“_source”: {
“_class”: “com.example.demo.domain.Product”,
“id”: 1010000102502345,
“name”: “猎原(插图版上下)/西部小说系列”,
“url”: “//item.xhsd.com/items/1010000102502345”,
“price”: 55.1,
“shop”: “雪漠”,
“date”: “2021-06-08 15:25:04”
}
},
{
“_index”: “product”,
“_type”: “_doc”,
“_id”: “1010000101424048”,
“_score”: 6.6571655,
“_source”: {
“_class”: “com.example.demo.domain.Product”,
“id”: 1010000101424048,
“name”: “马原中篇小说选/新经典文库”,
“url”: “//item.xhsd.com/items/1010000101424048”,
“price”: 11.4,
“shop”: “马原”,
“date”: “2021-06-08 15:29:02”
}
},
{
“_index”: “product”,
“_type”: “_doc”,
“_id”: “1010000102453201”,
“_score”: 5.874501,
“_source”: {
“_class”: “com.example.demo.domain.Product”,
“id”: 1010000102453201,
“name”: “我的黄土高原(柏原乡土小说自选集)”,
“url”: “//item.xhsd.com/items/1010000102453201”,
“price”: 38.0,
“shop”: “柏原”,
“date”: “2021-06-08 15:29:08”
}
},
{
“_index”: “product”,
“_type”: “_doc”,
“_id”: “1010000101098560”,
“_score”: 5.0784254,
“_source”: {
“_class”: “com.example.demo.domain.Product”,
“id”: 1010000101098560,
“name”: “原乡人(钟理和代表作)/中国现代文学百家”,
“url”: “//item.xhsd.com/items/1010000101098560”,
“price”: 26.6,
“shop”: “中国现代文学馆”,
“date”: “2021-06-08 15:27:43”
}
}
]
}
}
2)ik_smart(文本最粗粒度拆分)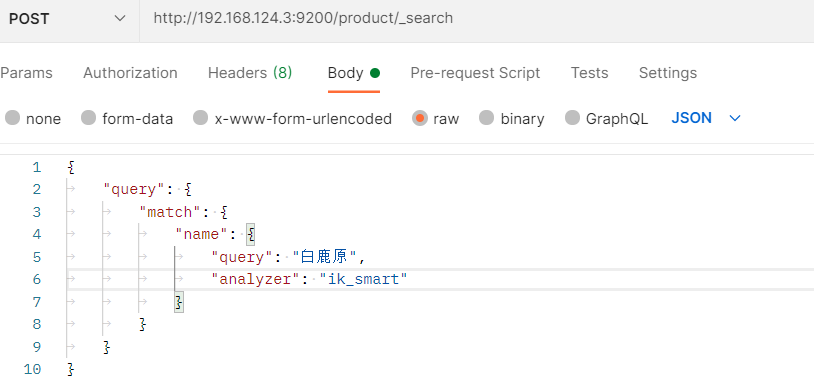
结果:
{
“took”: 12,
“timed_out”: false,
“_shards”: {
“total”: 1,
“successful”: 1,
“skipped”: 0,
“failed”: 0
},
“hits”: {
“total”: {
“value”: 3,
“relation”: “eq”
},
“max_score”: 7.531207,
“hits”: [
{
“_index”: “product”,
“_type”: “_doc”,
“_id”: “1010000100946369”,
“_score”: 7.531207,
“_source”: {
“_class”: “com.example.demo.domain.Product”,
“id”: 1010000100946369,
“name”: “白鹿原(陈忠实集长篇小说)(精)”,
“url”: “//item.xhsd.com/items/1010000100946369”,
“price”: 34.2,
“shop”: “陈忠实”,
“date”: “2021-06-08 15:24:44”
}
},
{
“_index”: “product”,
“_type”: “_doc”,
“_id”: “110000100409047”,
“_score”: 6.436447,
“_source”: {
“_class”: “com.example.demo.domain.Product”,
“id”: 110000100409047,
“name”: “白鹿原(新中国70年70部长篇小说典藏)”,
“url”: “//item.xhsd.com/items/110000100409047”,
“price”: 39.9,
“shop”: “陈忠实”,
“date”: “2021-06-08 15:30:27”
}
},
{
“_index”: “product”,
“_type”: “_doc”,
“_id”: “1010000101607417”,
“_score”: 5.803714,
“_source”: {
“_class”: “com.example.demo.domain.Product”,
“id”: 1010000101607417,
“name”: “白鹿原(陈忠实小说自选集现当代长篇小说经典)”,
“url”: “//item.xhsd.com/items/1010000101607417”,
“price”: 36.1,
“shop”: “陈忠实”,
“date”: “2021-06-08 15:24:25”
}
}
]
}
}
3)standard(es标准分词器)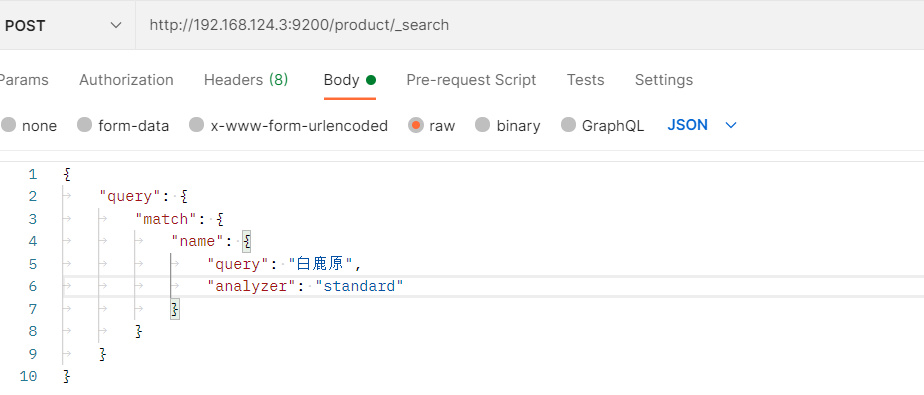
结果:
{
“took”: 1,
“timed_out”: false,
“_shards”: {
“total”: 1,
“successful”: 1,
“skipped”: 0,
“failed”: 0
},
“hits”: {
“total”: {
“value”: 30,
“relation”: “eq”
},
“max_score”: 8.726444,
“hits”: [
{
“_index”: “product”,
“_type”: “_doc”,
“_id”: “1010000103367080”,
“_score”: 8.726444,
“_source”: {
“_class”: “com.example.demo.domain.Product”,
“id”: 1010000103367080,
“name”: “鹿眼/张炜长篇小说年编”,
“url”: “//item.xhsd.com/items/1010000103367080”,
“price”: 36.1,
“shop”: “张炜”,
“date”: “2021-06-08 15:27:23”
}
},
{
“_index”: “product”,
“_type”: “_doc”,
“_id”: “1010000100723513”,
“_score”: 8.584315,
“_source”: {
“_class”: “com.example.demo.domain.Product”,
“id”: 1010000100723513,
“name”: “马原(冈底期的诱惑旧死总在途中拉萨河女神白卵石海滩)/中…”,
“url”: “//item.xhsd.com/items/1010000100723513”,
“price”: 28.5,
“shop”: “马原”,
“date”: “2021-06-08 15:27:43”
}
},
{
“_index”: “product”,
“_type”: “_doc”,
“_id”: “1010000102804389”,
“_score”: 8.095207,
“_source”: {
“_class”: “com.example.demo.domain.Product”,
“id”: 1010000102804389,
“name”: “游神/马原小说”,
“url”: “//item.xhsd.com/items/1010000102804389”,
“price”: 15.68,
“shop”: “马原著”,
“date”: “2021-06-08 15:31:59”
}
},
{
“_index”: “product”,
“_type”: “_doc”,
“_id”: “1010000101178261”,
“_score”: 7.6804366,
“_source”: {
“_class”: “com.example.demo.domain.Product”,
“id”: 1010000101178261,
“name”: “猎原/西部人文小说系列”,
“url”: “//item.xhsd.com/items/1010000101178261”,
“price”: 28.5,
“shop”: “雪漠”,
“date”: “2021-06-08 15:23:12”
}
},
{
“_index”: “product”,
“_type”: “_doc”,
“_id”: “1010000100499036”,
“_score”: 7.0615106,
“_source”: {
“_class”: “com.example.demo.domain.Product”,
“id”: 1010000100499036,
“name”: “花镜(白螺系列悬念小说)”,
“url”: “//item.xhsd.com/items/1010000100499036”,
“price”: 15.2,
“shop”: “沧月”,
“date”: “2021-06-08 15:22:59”
}
},
{
“_index”: “product”,
“_type”: “_doc”,
“_id”: “1010000100987245”,
“_score”: 7.0615106,
“_source”: {
“_class”: “com.example.demo.domain.Product”,
“id”: 1010000100987245,
“name”: “花镜(白螺系列悬念小说)”,
“url”: “//item.xhsd.com/items/1010000100987245”,
“price”: 19.0,
“shop”: “沧月”,
“date”: “2021-06-08 15:22:53”
}
},
{
“_index”: “product”,
“_type”: “_doc”,
“_id”: “110000100119773”,
“_score”: 7.0615106,
“_source”: {
“_class”: “com.example.demo.domain.Product”,
“id”: 110000100119773,
“name”: “白的海/花城小说馆”,
“url”: “//item.xhsd.com/items/110000100119773”,
“price”: 36.1,
“shop”: “小昌”,
“date”: “2021-06-08 15:22:33”
}
},
{
“_index”: “product”,
“_type”: “_doc”,
“_id”: “1010000102506141”,
“_score”: 6.9665523,
“_source”: {
“_class”: “com.example.demo.domain.Product”,
“id”: 1010000102506141,
“name”: “猎原(插图版)(精)/西部小说系列”,
“url”: “//item.xhsd.com/items/1010000102506141”,
“price”: 74.1,
“shop”: “雪漠”,
“date”: “2021-06-08 15:26:23”
}
},
{
“_index”: “product”,
“_type”: “_doc”,
“_id”: “1010000102502345”,
“_score”: 6.9665523,
“_source”: {
“_class”: “com.example.demo.domain.Product”,
“id”: 1010000102502345,
“name”: “猎原(插图版上下)/西部小说系列”,
“url”: “//item.xhsd.com/items/1010000102502345”,
“price”: 55.1,
“shop”: “雪漠”,
“date”: “2021-06-08 15:25:04”
}
},
{
“_index”: “product”,
“_type”: “_doc”,
“_id”: “1010000100603080”,
“_score”: 6.7173376,
“_source”: {
“_class”: “com.example.demo.domain.Product”,
“id”: 1010000100603080,
“name”: “白客/郑渊洁成人荒诞小说系列”,
“url”: “//item.xhsd.com/items/1010000100603080”,
“price”: 19.0,
“shop”: “郑渊洁”,
“date”: “2021-06-08 15:23:19”
}
}
]
}
}
如上三种情况对比可以发现:
standard是按照(“白”,”鹿”,”原”)拆解匹配的,检索精确度低,还有可能查不到想要的数据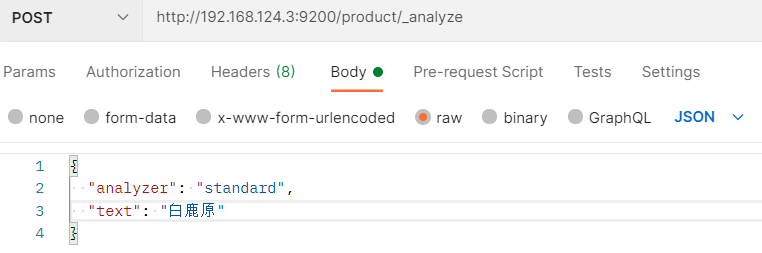
{
“tokens”: [
{
“token”: “白”,
“start_offset”: 0,
“end_offset”: 1,
“type”: “
“position”: 0
},
{
“token”: “鹿”,
“start_offset”: 1,
“end_offset”: 2,
“type”: “
“position”: 1
},
{
“token”: “原”,
“start_offset”: 2,
“end_offset”: 3,
“type”: “
“position”: 2
}
]
}
ik_max_word粒度划分最细(“白鹿原”,”白鹿”,”原”)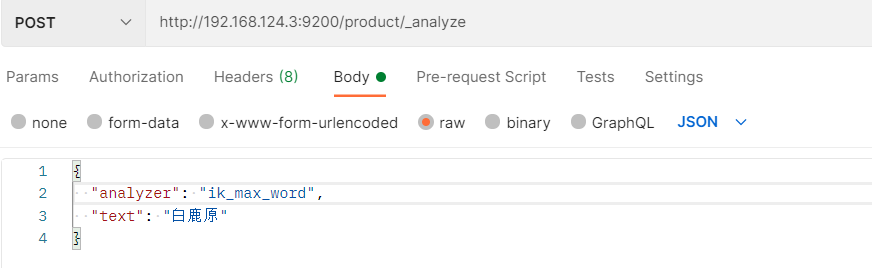
{
“tokens”: [
{
“token”: “白鹿原”,
“start_offset”: 0,
“end_offset”: 3,
“type”: “CN_WORD”,
“position”: 0
},
{
“token”: “白鹿”,
“start_offset”: 0,
“end_offset”: 2,
“type”: “CN_WORD”,
“position”: 1
},
{
“token”: “原”,
“start_offset”: 2,
“end_offset”: 3,
“type”: “CN_CHAR”,
“position”: 2
}
]
}
ik_smart按最粗粒度分(“白鹿原”)
{
“tokens”: [
{
“token”: “白鹿原”,
“start_offset”: 0,
“end_offset”: 3,
“type”: “CN_WORD”,
“position”: 0
}
]
}
自定义分析器
以下为es官网对于自定义分析器的介绍(https://www.elastic.co/guide/cn/elasticsearch/guide/current/custom-analyzers.html#custom-analyzers)
虽然Elasticsearch带有一些现成的分析器,然而在分析器上Elasticsearch真正的强大之处在于,你可以通过在一个适合你的特定数据的设置之中组合字符过滤器、分词器、词汇单元过滤器来创建自定义的分析器。
在 分析与分析器 我们说过,一个 分析器 就是在一个包里面组合了三种函数的一个包装器, 三种函数按照顺序被执行:
字符过滤器
字符过滤器 用来 整理 一个尚未被分词的字符串。例如,如果我们的文本是HTML格式的,它会包含像
或者
一个分析器可能有0个或者多个字符过滤器。
分词器
一个分析器 必须 有一个唯一的分词器。 分词器把字符串分解成单个词条或者词汇单元。 标准 分析器里使用的 标准分词器 把一个字符串根据单词边界分解成单个词条,并且移除掉大部分的标点符号,然而还有其他不同行为的分词器存在。
例如, 关键词分词器 完整地输出 接收到的同样的字符串,并不做任何分词。 空格分词器 只根据空格分割文本 。 正则分词器 根据匹配正则表达式来分割文本 。
词单元过滤器
经过分词,作为结果的 词单元流 会按照指定的顺序通过指定的词单元过滤器 。
词单元过滤器可以修改、添加或者移除词单元。我们已经提到过 lowercase和 stop词过滤器 ,但是在 Elasticsearch 里面还有很多可供选择的词单元过滤器。 词干过滤器 把单词 遏制 为 词干。 ascii_folding过滤器移除变音符,把一个像 “très” 这样的词转换为 “tres” 。 ngram 和 edge_ngram词单元过滤器 可以产生 适合用于部分匹配或者自动补全的词单元。
创建一个自定义分析器
和我们之前配置 es_std 分析器一样,我们可以在 analysis 下的相应位置设置字符过滤器、分词器和词单元过滤器:
PUT /my_index{"settings": {"analysis": {"char_filter": { ... custom character filters ... },"tokenizer": { ... custom tokenizers ... },"filter": { ... custom token filters ... },"analyzer": { ... custom analyzers ... }}}}
作为示范,让我们一起来创建一个自定义分析器吧,这个分析器可以做到下面的这些事:
- 使用 html清除 字符过滤器移除HTML部分。
使用一个自定义的 映射 字符过滤器把 & 替换为 “ and “ :
"char_filter": {"&_to_and": {"type": "mapping","mappings": [ "&=> and "]}}
使用 标准 分词器分词。
- 小写词条,使用 小写 词过滤器处理。
- 使用自定义 停止 词过滤器移除自定义的停止词列表中包含的词:
我们的分析器定义用我们之前已经设置好的自定义过滤器组合了已经定义好的分词器和过滤器:"filter": {"my_stopwords": {"type": "stop","stopwords": [ "the", "a" ]}}
汇总起来,完整的 创建索引 请求 看起来应该像这样:"analyzer": {"my_analyzer": {"type": "custom","char_filter": [ "html_strip", "&_to_and" ],"tokenizer": "standard","filter": [ "lowercase", "my_stopwords" ]}}
索引被创建以后,使用 analyze API 来 测试这个新的分析器:PUT /my_index{"settings": {"analysis": {"char_filter": {"&_to_and": {"type": "mapping","mappings": [ "&=> and "]}},"filter": {"my_stopwords": {"type": "stop","stopwords": [ "the", "a" ]}},"analyzer": {"my_analyzer": {"type": "custom","char_filter": [ "html_strip", "&_to_and" ],"tokenizer": "standard","filter": [ "lowercase", "my_stopwords" ]}}}}}
下面的缩略结果展示出我们的分析器正在正确地运行:GET /my_index/_analyze?analyzer=my_analyzerThe quick & brown fox
这个分析器现在是没有多大用处的,除非我们告诉 Elasticsearch在哪里用上它。我们可以像下面这样把这个分析器应用在一个 string 字段上:{"tokens" : [{ "token" : "quick", "position" : 2 },{ "token" : "and", "position" : 3 },{ "token" : "brown", "position" : 4 },{ "token" : "fox", "position" : 5 }]}
PUT /my_index/_mapping/my_type{"properties": {"title": {"type": "string","analyzer": "my_analyzer"}}}

若有收获,就点个赞吧
0 人点赞

{kind=link}