索引
何为索引?大家可以想象刚刚学习汉字的时候,每当我们需要查询一个不知道其意思的时候,但是直到他的配音的时候,例如:”新” : xin,我们可以在字典先找到X,再找到in,再通过声调,找到对应的汉字释义,其实我们可以看到字典查的方法和我们程序检索的方法是差不多的,将一堆数据收集,从中找出其相同的部分,将此部分抽象出来,之后再用一个地址将抽象出来的部分和他们对应的数据关联起来,如下图
分类前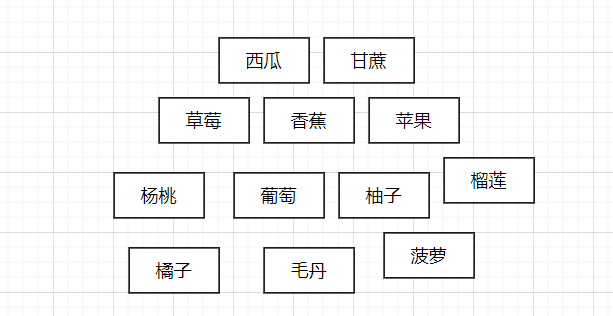 分类后
分类后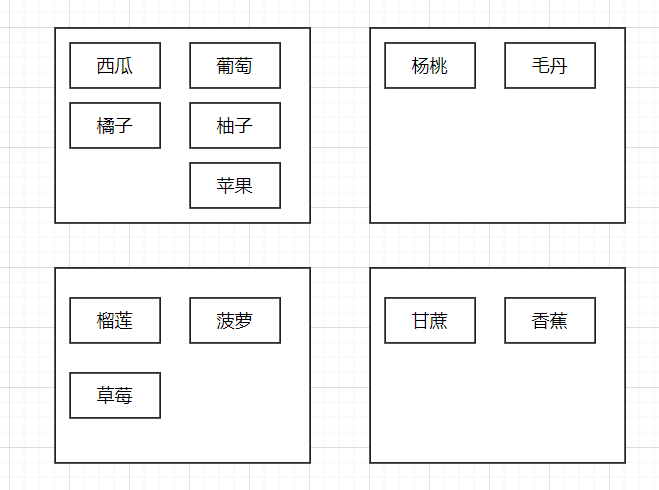
如果按形状分类后,数据量还比较大的话可以再按其大小分,季节,名字首字母等
关系型数据库中的索引
这里以mysql为例,mysql中的索引,一般被叫做主键,这里以id为主键索引提供唯一id的标识,通过id可以找到对应的数据,也可以通过id进行范围查询 例如:
| id | name | sex | age | address |
|---|---|---|---|---|
| 24 | zs | 男 | 18 | 湖北 |
| 67 | ls | 女 | 19 | 浙江 |
| 5 | wq | 男 | 18 | 宁夏 |
| 50 | zl | 女 | 17 | 吉林 |
| 14 | liq | 男 | 20 | 新疆 |
MyISAM
在MyISAM存储引擎中,使用B+Tree作为索引结构,叶节点的data域存放的是数据记录的地址,数据存储如下图
可以看出MyISAM的索引文件仅仅保存数据记录的地址。在MyISAM中,主索引和辅助索引(Secondary key)在结构上没有任何区别,只是主索引要求key是唯一的,而辅助索引的key可以重复。data域保存数据记录的地址。因此,MyISAM中索引检索的算法为首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其data域的值,然后以data域的值为地址,读取相应数据记录。MyISAM的索引方式也叫做“非聚集”的,之所以这么称呼是为了与InnoDB的聚集索引区分。
InnoDB
而innoDB使用的也是b+tree但是二者在实现的方式上有很大的不同,第一个重大区别是InnoDB的数据文件本身就是索引文件。
从上文知道,MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。而在InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引,下图是InnoDB主索引(同时也是数据文件)的示意图,可以看到叶节点包含了完整的数据记录。这种索引叫做聚集索引。因为InnoDB的数据文件本身要按主键聚集,所以InnoDB要求表必须有主键(MyISAM可以没有),如果没有显式指定,则MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则MySQL自动为InnoDB表生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整形。
第二个与MyISAM索引的不同是InnoDB的辅助索引data域存储相应记录主键的值而不是地址。换句话说,InnoDB的所有辅助索引都引用主键作为data域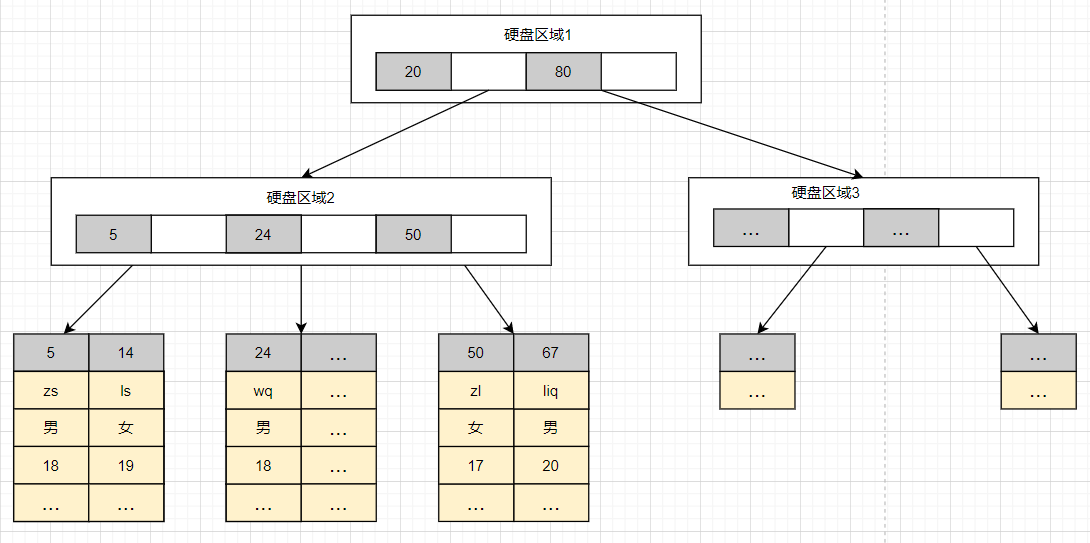
非关系型数据库索引
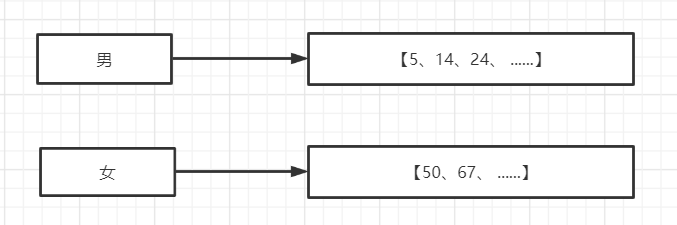
Elasticsearch 是通过 Lucene 的倒排索引技术实现比关系型数据库更快的过滤。那什么是倒排索引技术呢?按照我们上面得mysql表数据,就可以组成以下数据,而这些数据就组成了数据字典
| Term | Posting List |
|---|---|
| 男 | [5、14,24] |
| 女 | [50,67] |
| Term | Posting List |
|---|---|
| 17 | 50 |
| 18 | 5,24 |
| 19 | 67 |
| 20 | 14 |
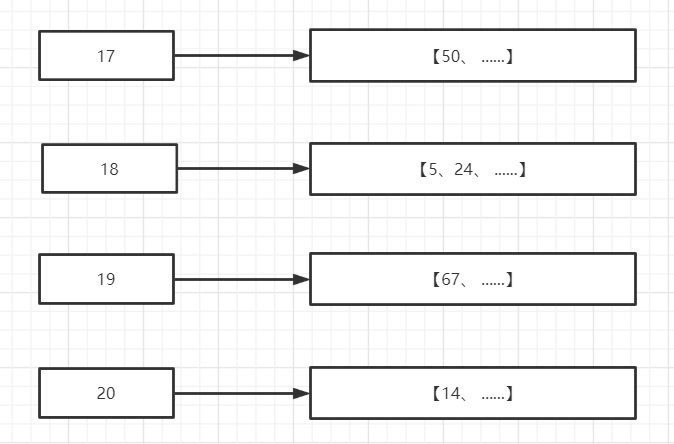
接下来我们解释下,上面出现的一些陌生词汇、Elasticsearch分别为每个field都建立了一个倒排索引,男, 20这些叫term,而[5、24]就是Posting List。Posting list就是一个int的数组,存储了所有符合某个term的文档id。并且他是一个有序的数组
此时,如果我们找对应得性别或者对应得年龄就会变得很容易,不必再按照id来排序,然后像mysql一样一层一层得找了,看到这里是不是觉得倒排索引很nice了,但是有趣得远远不止于此
想象一下如果我们是通过名字去找呢?年龄和性别可以选取某一范围,比如性别只有两个,年龄只有0-300之间,但是名字不一样,可以有很多个,如果将这些名字用来组成数据字典,那么数据字典将会无比的庞大,由此我们就使用了FST(Finite State Transducer)压缩技术,有兴趣的可以阅读关于此技术的文章、可以将上面的名字转换为以下结构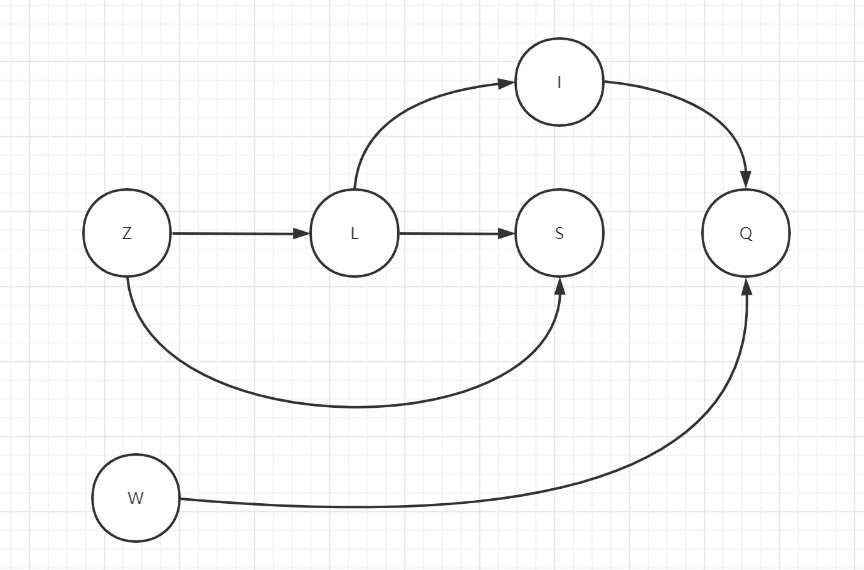
再将数据和值匹配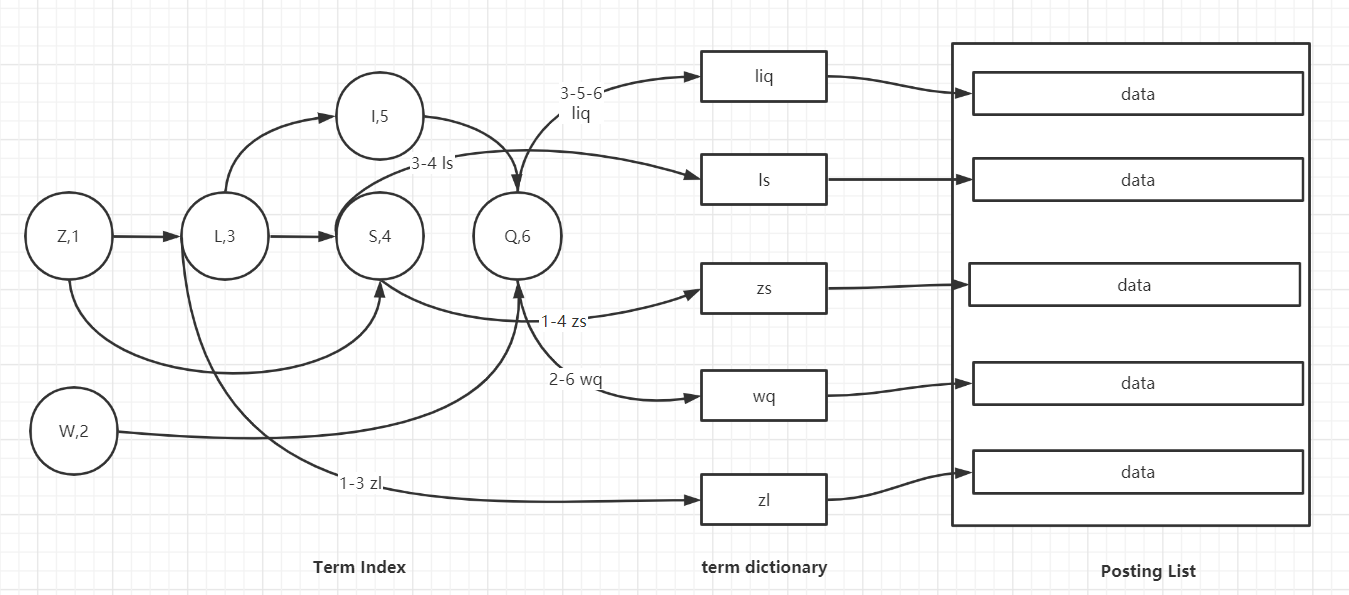
Term Dictionary
Elasticsearch为了能快速找到某个term,将所有的term排个序,二分法查找term,logN的查找效率,就像通过字典查找一样,这就是Term Dictionary。现在再看起来,似乎和传统数据库通过B-Tree的方式类似啊,为什么说比B-Tree的查询快呢?
Term Index
B-Tree通过减少磁盘寻道次数来提高查询性能,Elasticsearch也是采用同样的思路,直接通过内存查找term,不读磁盘,但是如果term太多,term dictionary也会很大,放内存不现实,于是有了Term Index,就像字典里的索引页一样,A开头的有哪些term,分别在哪页
此时我们再想想,如果按照性别分的话,随着数据量越来越大,Posting List必然会逐步增大,所以,为了减少Posting List的size,我们对Posting List也采用压缩
Frame of Reference
以上面的数据为例,在未压缩前,每个数据都需要按照最大占用空间来计算,67 > 2^6 因此需要5 7 需要35bit 将35 8 向上取整得到5bytes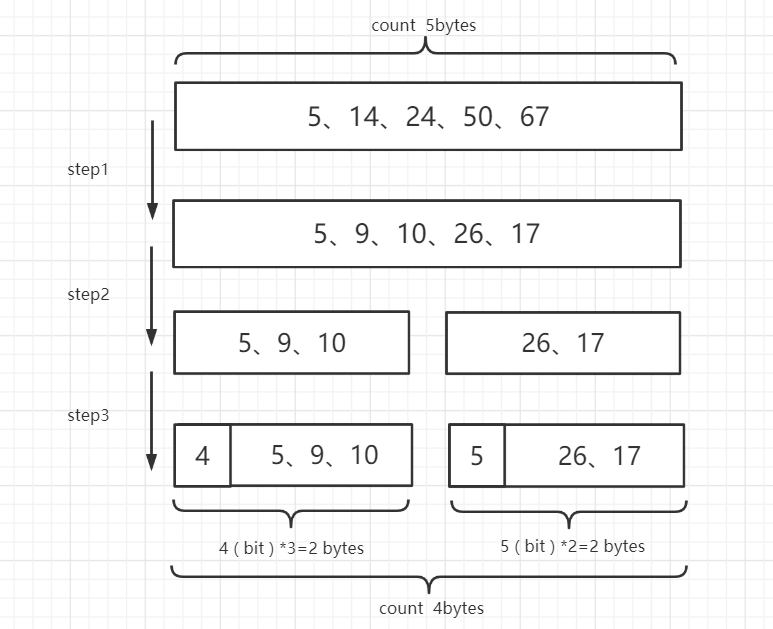
step1:将排序的整数列表转换成delta列表
step2:切分成blocks。具体是怎么做的呢?Lucene是规定每个block是256个delta,这里为了简化一下,搞成2个delta。
step3:看下每个block最大的delta是多少。上图的第一个block,最大的delta是10,最接近的2次幂是16(4bits),于是规定这个block里都用4bits来编码,第二个block,最大的delta是26,最接近的2次幂是32(5bits),于是规定这个block里都用5bit来编码
filter cache
在filter cache中,Lucene需要编码一个int列表。这是一个简单的cache。但是这个的filter跟倒排索引是不一样的,因为我们只需要缓存那些比较频繁的过滤条件,此时压缩率就显得没那么重要了,但是我们在重复查询的时候希望越快越好,所以在这里使用一个好的数据结构是比较重要的,和倒排索引不一样的是cached filters 是保存在内存的,因此和倒排索引的压缩算法最好不一致,下面列举几个常见的方法
Integer array最简单的方法:直接保存成array。这样遍历很简单,然而压缩很糟糕。这个编码技术每个entry需要4个bytes,此时你的filter匹配结果所需要的内存是要乘以4的,例如匹配成功的数据有100M,那么此时占用的内存为100 * 4 M,Integer array的缺点是存储空间随着文档个数线性增长
bitmap(位图) 当数字列表很稠密的时候,bitmaps就很好使了。还是刚才这个例子,100M的文档,用bitmap那就是100M/8=12.5MB。
而bitmap是什么样的呢?举个例子[1,3,4,6,8,9] 在bitmap中为 [1,0,1,1,0,1,0,1,1],非常直观,用0/1表示某个值是否存在,比如9这个值就对应第9位,对应的bit值是1,这样用一个字节就可以代表8个文档id,旧版本(5.0之前)的Lucene就是用这样的方式来压缩的,但这样的压缩方式仍然不够高效,如果数据是以下存储方式[10,50,100]那么对应的位图则为[0,…..1,…..1,…………,1],很显然对于数据不密集的,仍需要这么多的空间用来存储,数据越稀疏,空间浪费越严重。于是有人想出了Roaring bitmaps这样更高效的数据结构。
roaring bitmaps 融合上面两种选项的优势。它于2016年由S. Chambi、D. Lemire、O. Kaser等人在论文《Better bitmap performance with Roaring bitmaps》与《Consistently faster and smaller compressed bitmaps with Roaring》中提出
首先根据数字的高16位把拉链切分成不同的块(block)。这就意味着,第一个block我们会编码0-65535的值,第二个block是65536-131071,以此类推。然后在每个block我们分别编码低16位:如果列表数量小于4096,我们会使用选项一(Integer array),否则使用bitmap。需要注意的是,使用Integer array的时候每个值实际上我们一般需要4个byte。但是在这里我们只需要使用2个byte因为block ID已经说明了高16位是啥
而列表数量为什么要小于4096呢?因为每个block的大小是65536(2^16),如果是bitmap的话,需要65536/8 byte=8192 byte(不论实际的文档数有多少都需要这么多)而如果是用Integer array的话,则真正包含的文档数越多的话,需要的内存越大,是一个线性增长的过程。
那么看看下面的图,我们就可以得出这个阈值就是 8192byte / 2byte = 4096(个)文档。也就是说,当文档数少于4096的时候,用Integer array划算,否则用bitmap划算。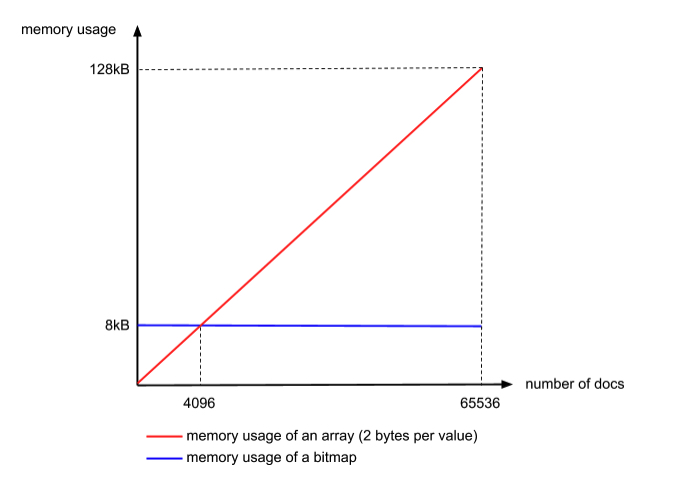

若有收获,就点个赞吧
0 人点赞
