filebeat启动
配置内容
修改安装目录的filebeat.yml文件
filebeat.yml
启动filebeat
nohup ./filebeat -e -c filebeat.yml &

日志分析
可以提供查看nohop.out文件的输出,一般没有报错即可,下面是一些日志截图
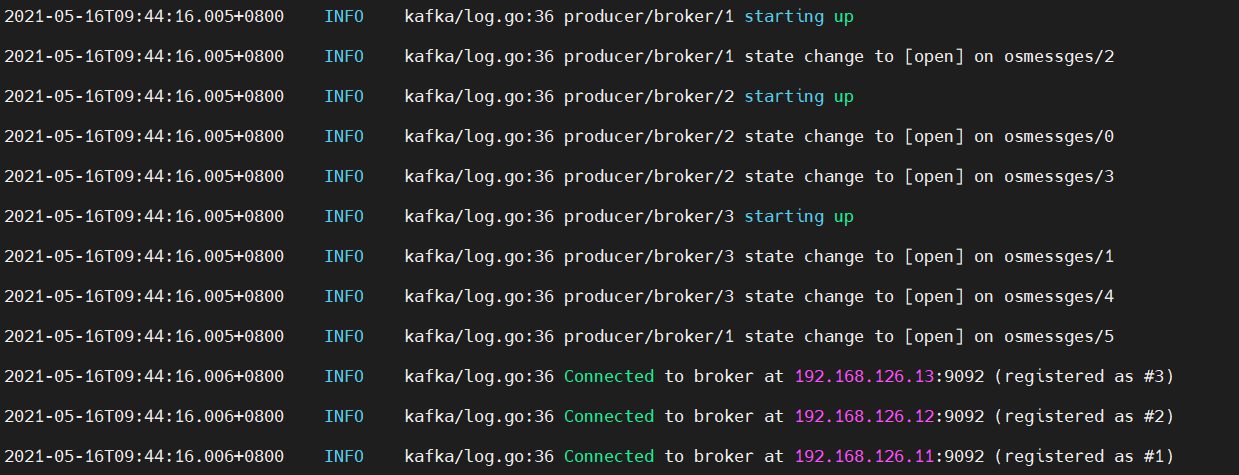
连接kafka集群
注册了新的broker,kafka初始化工作完成
日志采集的输入文件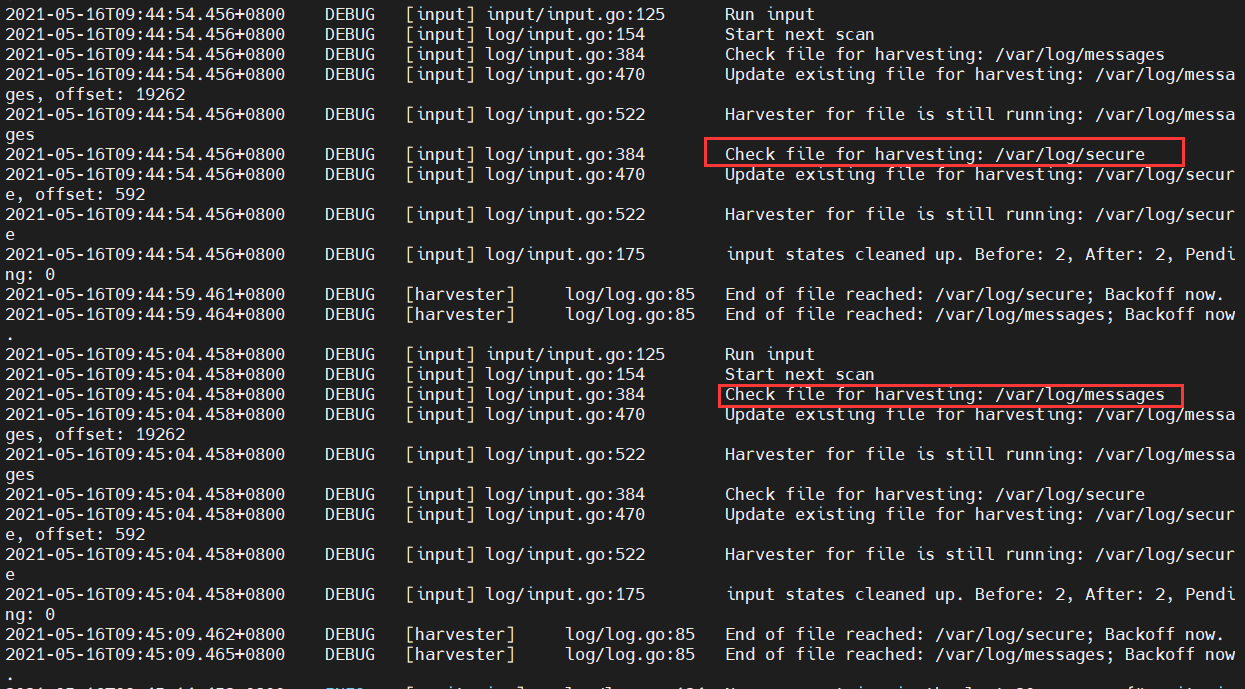
这里看到我们使用的是两个系统的日志文件,messages:系统进程日志 secure:系统登录信息日志
这里我们产生一个登录日志,同时打开启动日志nohop.out和kafka消费端
启动kafka消费端
bin/kafka-console-consumer.sh --zookeeper 192.168.126.11:2181,192.168.126.12:2181,192.168.126.13:2181 --topic osmessages
nohop.out输出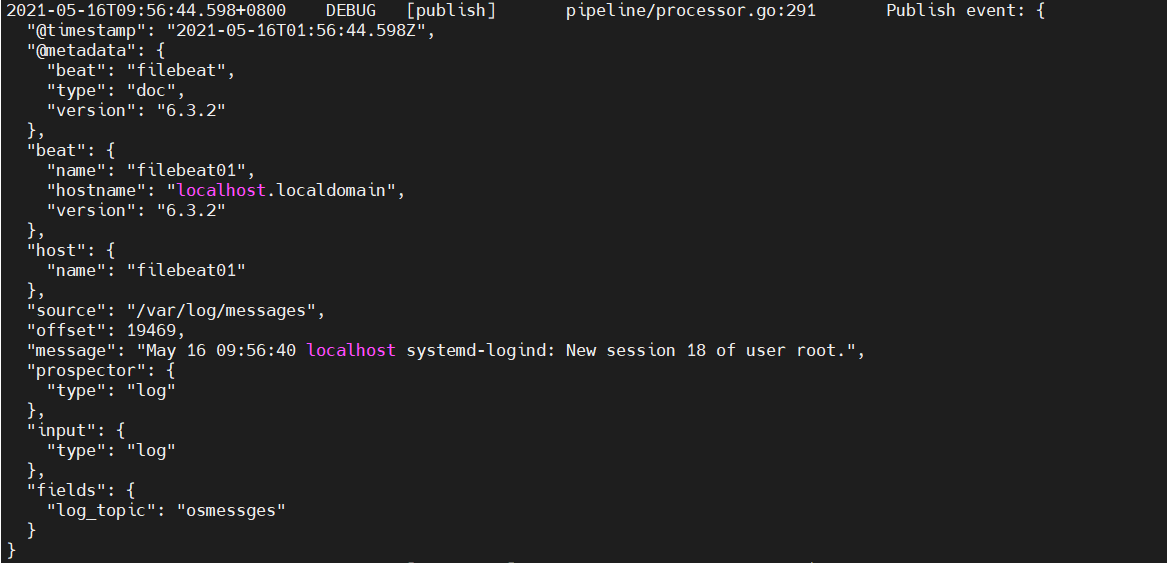
Publish event: 一次输出事件
@timestamp:收集到日志的时间戳
@metadata:元数据类型
beat:beat名称,beat的产品有Filebeat、packetbeat、Winlogbeat
type:类型
version:版本
beat:在filebeat.yml配置beat信息
name:在filebeat.yml配置的name
hostname:所在的机器名字
version:版本
host:在哪个机器收集到的日志
name:日志收集到的机器的hostname
source:收集的日志所在的全路径
offset:偏移量,在以后读取日志时可以直接使用此数字读取
message:日志文件输出的信息
prospector:指定收集日志的类型
type:类型
input:输入日志的类型
type:输入类型
fields:在filebeat.yml配置的自定义字段
log_topic:日志主题,将要发送给kafka的主题
kafka消费端输出:
kafka没有做日志格式化输出,我们截取一段用json转一下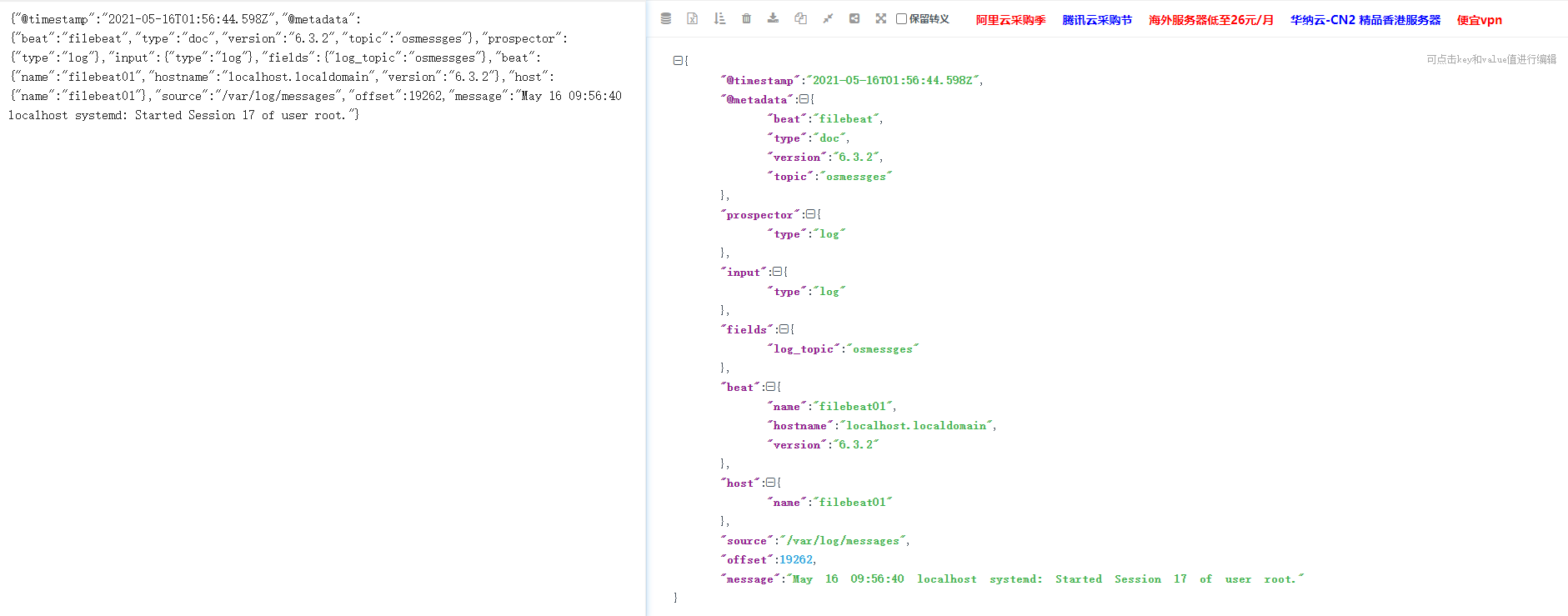
日志过滤
可以看到kafka也收集到了,但是其中有太多我们不需要的信息了,比如host,beat,input等等,这些不需要的日志信息可以过滤掉,在filebeat.yml中有一个这样的配置,注意这里的配置还要看自己下载的版本,不同的版本可能配置的不一样
processors:- drop_fields:fields: ["field1", "field2", ...]processors:- drop_fields:fields: ["beat", "host"]
文档地址:https://www.elastic.co/guide/en/beats/filebeat/6.3/index.html

将这个配置更改后重启filebeat
ps -ef | grep filebeatkill -9 filebeat进程idnohup ./filebeat -e -c filebeat.yml &tail -200f nohup.out
此时再看,以及没有了host和beat信息了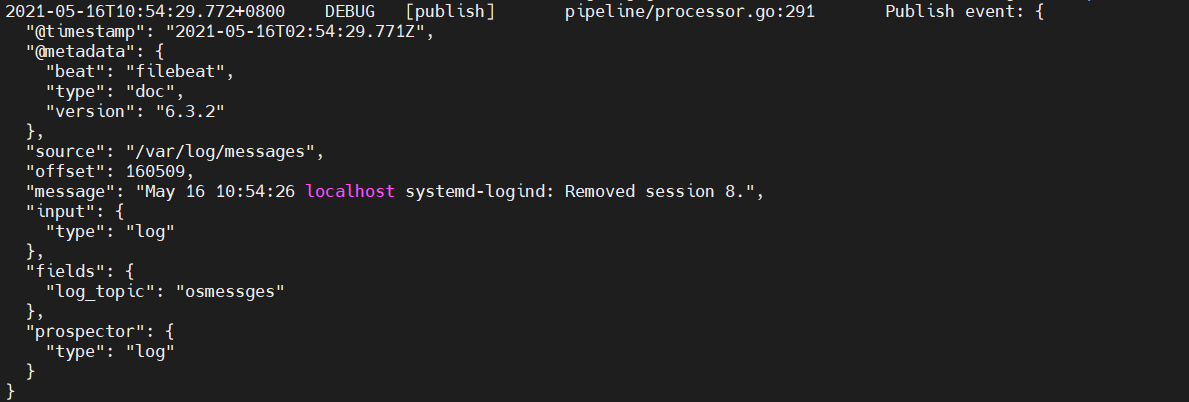
这边的过滤很简单的过滤,主要用于采集,而真正的的过滤在logstash

若有收获,就点个赞吧
0 人点赞
