elasticsearch介绍
Elasticsearch 是一个基于java开源的实时分布式搜索引擎,它可以用于全文搜索,结构化搜索以及分析,它的主要特点如下:
实时搜索,实时分析
分布式,零配置、实时文件存储,并将每一个字段都编入索引
文档导向,所有的对象全部是文档
高可用性,易扩展,支持集群(Cluster),自动发现,索引自动分片和复制(Shards和Replicas)
restful风格接口,接口友好,支持JSON
多数据源,自动搜索负载
基本概念
索引
索引(index)是Elasticsearch对逻辑数据的逻辑存储,所以它可以分为更小的部分。可以把索引看成关系型数据库的表,索引的结构是为快速有效的全文索引准备的,特别是它不存储原始值。Elasticsearch可以把索引存放在一台机器或者分散在多台服务器上,每个索引有一或多个分片(shard),每个分片可以有多个副本(replica)。
文档
存储在Elasticsearch中的主要实体叫文档(document)。用关系型数据库来类比的话,一个文档相当于数据库表中的一行记录。例如:上海市徐汇区区建材城西路徐汇大厦办公楼一层 电话:021-611-8080,Elasticsearch和MongoDB中的文档类似,都可以有不同的结构,但Elasticsearch的文档中,相同字段必须有相同类型。文档由多个字段组成,每个字段可能多次出现在一个文档里,这样的字段叫多值字段(multivalued)。每个字段的类型,可以是文本、数值、日期等。字段类型也可以是复杂类型,一个字段包含其他子文档或者数组。
映射
所有文档写进索引之前都会先进行分析,如何将输入的文本分割为词条、哪些词条又会被过滤,这种行为叫做映射(mapping)。一般由用户自己定义规则。
文档类型
在Elasticsearch中,一个索引对象可以存储很多不同用途的对象。例如,一个博客应用程序可以保存文章和评
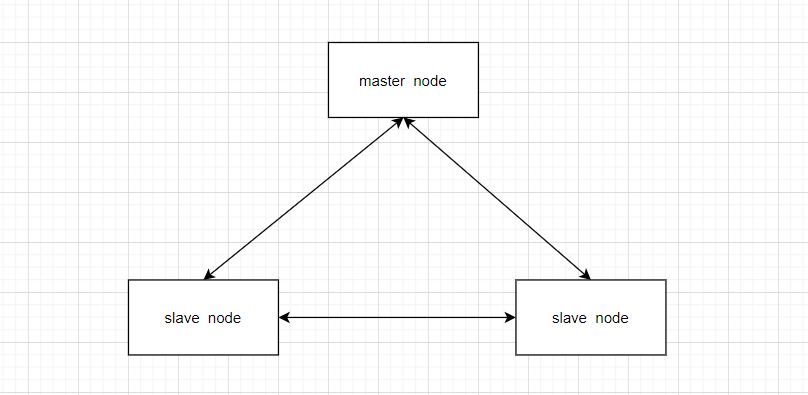
典型的es集群架构如下图所示
安装配置es
es架构中各角色介绍
在ElasticSearch的架构中,有三类角色,分别是Client Node、Data Node和Master Node,搜索查询的请求一般是经过Client Node来向Data Node获取数据,而索引查询首先请求Master Node节点,然后Master Node将请求分配到多个Data Node节点完成一次索引查询,如下图所示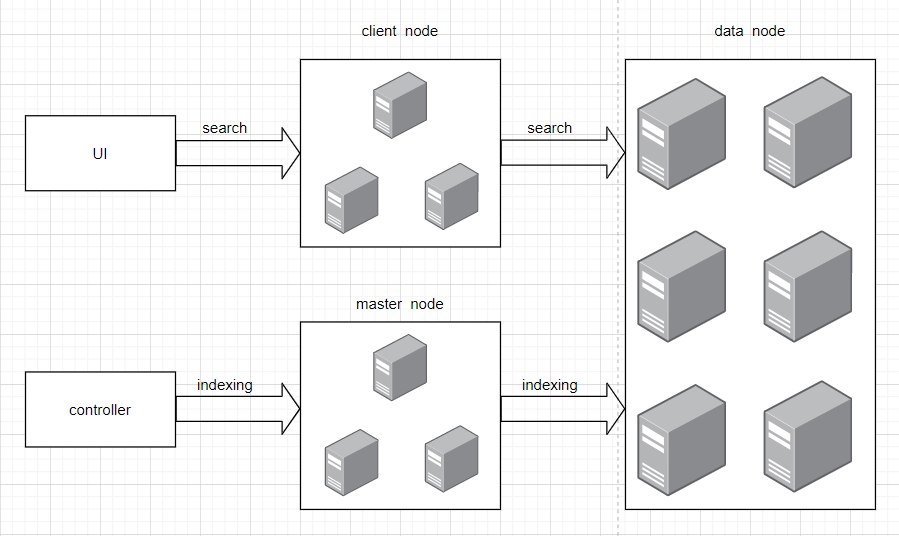
master node:
可以理解为主节点,主要用于元数据(metadata)的处理,比如索引的新增、删除、分片分配等,以及管理集群各个节点的状态。elasticsearch集群中可以定义多个主节点,但是,在同一时刻,只有一个主节点起作用,其它定义的主节点,是作为主节点的候选节点存在。当一个主节点故障后,集群会从候选主节点中选举出新的主节点。
data node:
数据节点,这些节点上保存了数据分片。它负责数据相关操作,比如分片的CRUD、搜索和整合等操作。数据节点上面执行的操作都比较消耗 CPU、内存和I/O资源,因此数据节点服务器要选择较好的硬件配置,才能获取高效的存储和分析性能。
client node:
客户端节点,属于可选节点,是作为任务分发用的,它里面也会存元数据,但是它不会对元数据做任何修改。client node存在的好处是可以分担data node的一部分压力,因为elasticsearch的查询是两层汇聚的结果,第一层是在data node上做查询结果汇聚,然后把结果发给client node,client node接收到data node发来的结果后再做第二次的汇聚,然后把最终的查询结果返回给用户。这样,client node就替data node分担了部分压力
es安装及配置
安装
将之前下载好的包上传至服务器对应目录,解压下载的包,并给予他新的用户访问权限,这里举例我们将文件上传至usr/es目录下
//解压文件tar -zxvf elasticsearch.tar.gz//添加用户useradd cherry//授权用户chown -R cherry:cherry /usr/es/elasticsearch
配置
操作系统配置(可忽略)
操作系统以及JVM调优主要是针对安装elasticsearch的机器。对于操作系统,需要调整几个内核参数,将下面内容添加到/etc/sysctl.conf文件中
fs.file-max=655360
vm.max_map_count = 262144
fs.file-max主要是配置系统最大打开文件描述符数,建议修改为655360或者更高
vm.max_map_count影响Java线程数量,用于限制一个进程可以拥有的VMA(虚拟内存区域)的大小,系统默认是65530,建议修改成262144或者更高
另外,还需要调整进程最大打开文件描述符(nofile)、最大用户进程数(nproc)和最大锁定内存地址空间(memlock),添加如下内容到/etc/security/limits.conf文件中
* soft nproc 20480
* hard nproc 20480
* soft nofile 65536
* hard nofile 65536
* soft memlock unlimited
* hard memlock unlimited
最后,还需要修改/etc/security/limits.d/20-nproc.conf文件(centos7.x系统)
soft nproc 4096
//改为
soft nproc 20480

JVM配置(不可忽略)
VM调优主要是针对elasticsearch的JVM内存资源进行优化,elasticsearch的内存资源配置文件为jvm.options,此文件位于/usr/local/elasticsearch/config目录下,打开此文件,修改如下内容
//默认JVM内存为2g,可根据服务器内存大小,修改为合适的值。一般设置为服务器物理内存的一半最佳
-Xms2g
-Xmx2g
elasticsearch配置
elasticsearch的配置文件均在elasticsearch根目录下的config文件夹,这里是/usr/local/elasticsearch/config目录,主要有jvm.options、elasticsearch.yml和log4j2.properties三个主要配置文件。这里重点介绍elasticsearch.yml一些重要的配置项及其含义。这里配置的elasticsearch.yml文件内容如下,在其他机器的配置也大致一样,只需要修改节点名,和其他机器的ip
cluster.name: es
node.name: server1
node.master: true
node.data: true
path.data: /data1/elasticsearch,/data2/elasticsearch
path.logs: /usr/es/elasticsearch/logs
bootstrap.memory_lock: true
network.host: 0.0.0.0
http.port: 9200
discovery.zen.minimum_master_nodes: 1
discovery.zen.ping.unicast.hosts: ["192.168.126.82:9300","192.168.126.83:9300"]
各配置项含义
(1)cluster.name: es
配置elasticsearch集群名称,默认是elasticsearch。这里修改为es,elasticsearch会自动发现在同一网段下的集群名为es的主机。
(2)node.name: server1
节点名,任意指定一个即可,这里是server1,我们这个集群环境中有三个节点,分别是server1、server2和server3,记得根据主机的不同,要修改相应的节点名称。
(3)node.master: true
指定该节点是否有资格被选举成为master,默认是true,elasticsearch集群中默认第一台启动的机器为master角色,如果这台服务器宕机就会重新选举新的master。
(4)node.data: true
指定该节点是否存储索引数据,默认为true,表示数据存储节点,如果节点配置node.master:false并且node.data: false,则该节点就是client node。这个client node类似于一个“路由器”,负责将集群层面的请求转发到主节点,将数据相关的请求转发到数据节点。
(5)path.data:/data1/elasticsearch,/data2/elasticsearch
设置索引数据的存储路径,默认是elasticsearch根目录下的data文件夹,这里自定义了两个路径,可以设置多个存储路径,用逗号隔开。
(6)path.logs: /usr/es/elasticsearch/logs
设置日志文件的存储路径,默认是elasticsearch根目录下的logs文件夹
(7)bootstrap.memory_lock: true 此
配置项一般设置为true用来锁住物理内存。 linux下可以通过“ulimit -l” 命令查看最大锁定内存地址空间(memlock)是不是unlimited
(8)network.host: 0.0.0.0
此配置项用来设置elasticsearch提供服务的IP地址,默认值为0.0.0.0,此参数是在elasticsearch新版本中增加的,此值设置为服务器的内网IP地址即可。
(9)http.port: 9200
设置elasticsearch对外提供服务的http端口,默认为9200。其实,还有一个端口配置选项transport.tcp.port,此配置项用来设置节点间交互通信的TCP端口,默认是9300。
(10)discovery.zen.minimum_master_nodes: 1
配置当前集群中最少的master节点数,默认为1,也就是说,elasticsearch集群中master节点数不能低于此值,如果低于此值,elasticsearch集群将停止运行。在三个以上节点的集群环境中,建议配置大一点的值,推荐2至4个为好。(官方建议:Prevent the “split brain” by configuring the majority of nodes (total number of master-eligible nodes / 2 + 1):)
(11)discovery.zen.ping.unicast.hosts: [“192.168.126.82:9300”,”192.168.126.83:9300”]
设置集群中master节点的初始列表,可以通过这些节点来自动发现新加入集群的节点。这里需要注意,master节点初始列表中对应的端口是9300。即为集群交互通信端口。
启动ES
启动命令
cd bin
./elasticsearch
//加了-d 说明是后台启动
./elasticsearch -d
启动elasticsearch服务需要在一个普通用户下完成,如果通过root用户启动elasticsearch的话,可能会收到如下错误: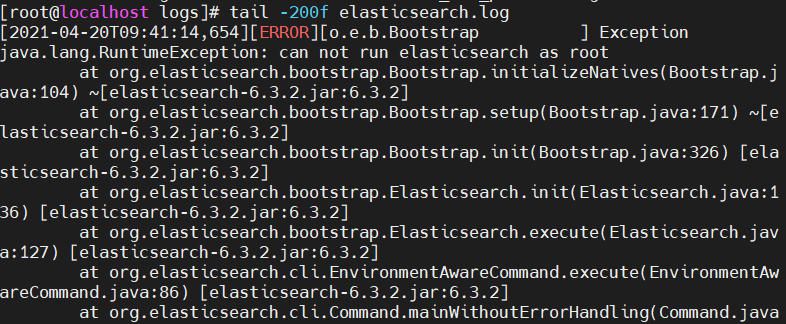
错误很明显can not run elasticsearch as root,为啥不能使用root呢,这是出于系统安全考虑,elasticsearch服务必须通过普通用户来启动,这里直接切换到elasticsearch用户下启动elasticsearch集群即可。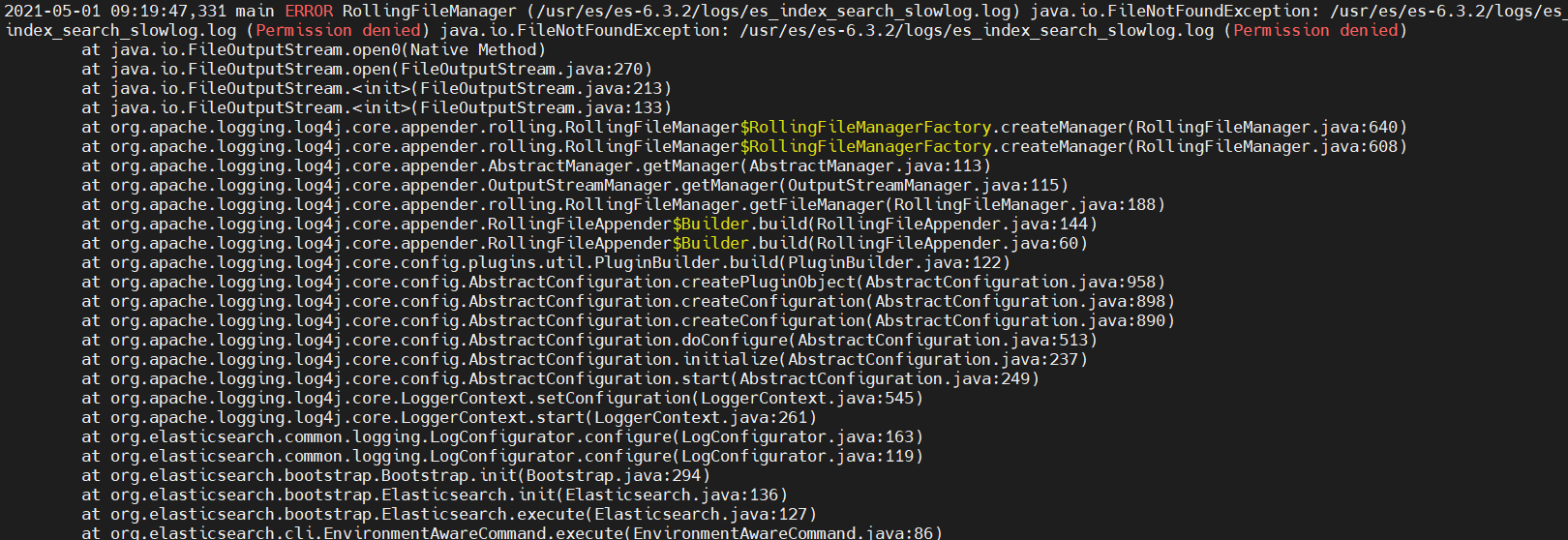
此问题说明没有给当前用户授权es下的目录,当前用户无权访问,查看下当前目录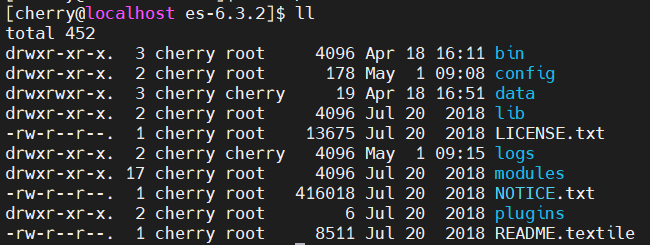
如果报以下错误
请修改/etc/sysctl.conf文件在文件中添加以下内容
vm.max_map_count=262144
//添加完后执行以下命令,使修改生效
/sbin/sysctl -p
直至日志输出started才算启动,也可以使用curl命令访问es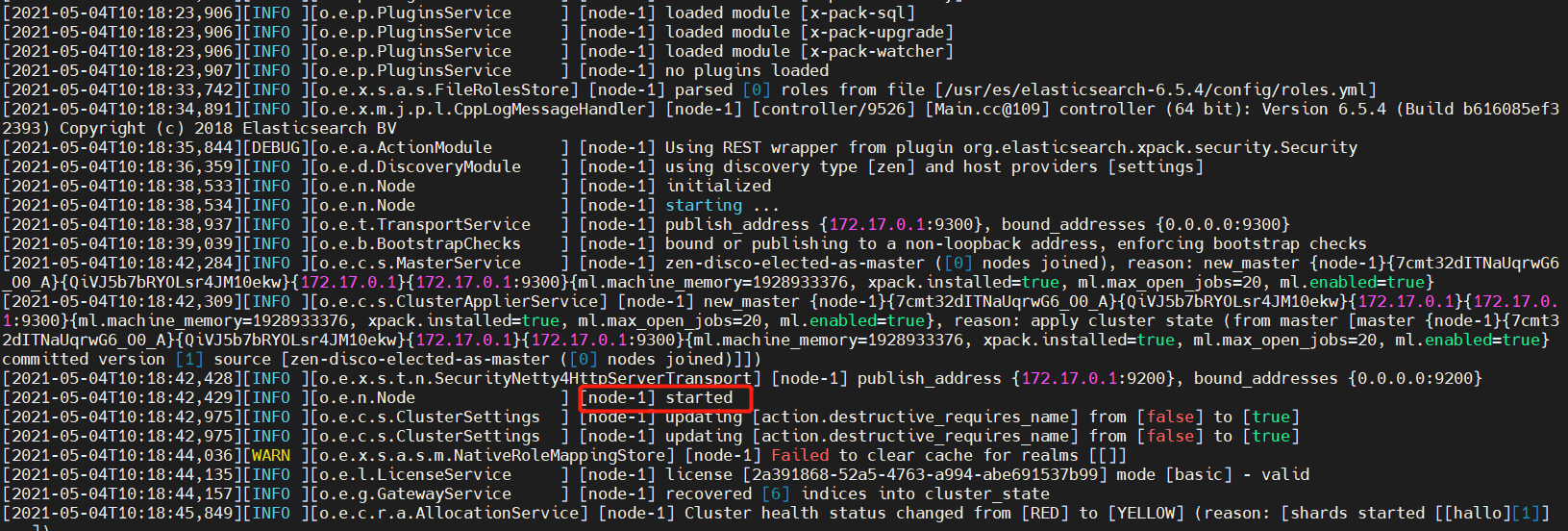
命令访问
curl http://192.168.126.81:9200
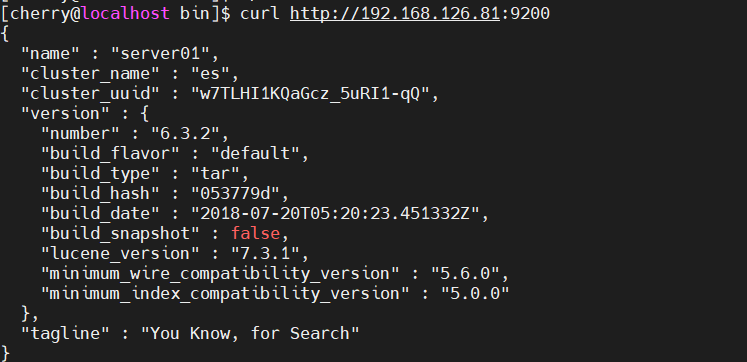
查看es节点信息
curl http://192.168.126.81:9200/_cat/nodes
带 * 为master节点

若有收获,就点个赞吧
0 人点赞
