日志简介
维基百科介绍
在计算机领域,日志文件(logfile)是一个记录了发生在运行中的操作系统或其他软件中的事件的文件,或者记录了在网络聊天软件的用户之间发送的消息。来源请求日志记录(Logging)是指保存日志的行为。最简单的做法是将日志写入单个存放日志的文件。
许多操作系统、软件框架和程序都包含日志系统。广泛使用的一项日志标准是syslog,它在互联网任务工程组(IETF)的RFC5424中定义。syslog标准使专门的标准化子系统得以生成、过滤、记录和分析日志消息。这可以减轻软件开发人员设计和编写自己的临时日志系统的难度。
简单来说其实就是各种系统运行所产生的数据,那么该如何的去收集、保存、分析这些数据呢?
日志框架的演进(以Java举例)
三足鼎立
apache Log4j
1996年早期,欧洲安全电子市场项目组决定编写它自己的程序跟踪API(Tracing API)。经过不断的完善,这个API终于成为一个十分受欢迎的Java日志软件包,即Log4j。它是由Ceki Gülcü首创的,现在则是Apache软件基金会的一个项目,期间Log4j近乎成了Java社区的日志标准。在当时也就是jdk1.4前,只有这一种选择。谁能想到Java1.4之前,JDK都没有内置的日志功能!据说Apache基金会还曾经建议Sun引入Log4j到java的标准库中,但被Sun无情的拒绝了
Jul
2002年Java1.4发布,Sun推出了自己的日志库JUL(Java Util Logging),其实现基本模仿了Log4j的实现。在JUL出来以前,Log4j就已经成为一项成熟的技术,使得Log4j在选择上占据了一定的优势
Commons Logging
在jul发布后,开发者们有了两种选择,正是因为有了两种选择,所以导致了日志使用的混乱,从而各种不兼容,于是Apache在jul发布后推出了Jakarta Commons Logging,后更名为Commons Logging,JCL只是定义了一套日志接口(其内部也提供一个Simple Log的简单实现),支持运行时动态加载日志组件的实现(在程序运行时会优先找系统是否集成Log4j,如果集成则使用Log4j做为日志实现,如果没找到则使用J.U.L做为日志实现),也就是说,在你应用代码里,只需调用Commons Logging的接口,底层实现可以是Log4j,也可以是Java Util Logging
Slf4j
前面介绍的log4j的开发者Ceki Gülcü由于工作的原因,离开了apache。然后创建了Slf4j (Simple Logging Facade for Java)日志门面接口,类似于Commons Logging和Logback(Slf4j的实现),并且可以实现无缝与多种实现框架进行对接。而他已经成为现在Java中最多的一种日志集成方式
logbask
在Slf4j之后,Ceki Gülcü又顺带开发了Logback,做为Slf4j的默认实现。当时在功能完整度和性能上,Logback超越了所有已有的日志实现框架
Log4j2
在2012年,在logback的压力下,Apache重写了Log4j,实现了Log4j2。在功能上面具有Logback的所有特性。且配置上由原来的properties增加到了xml、yml、json配置
二分天下
而此时Java日志界有了两大门派,一是Ceki Gülcü的logback + slf4j体系、二是Commons Logging + Log4j2体系,那么这两种究竟怎么样呢?
logback + slf4j体系 vs Commons Logging + Log4j2体系
性能方面:
Slf4j实现机制决定Slf4j限制较少,使用范围更广。由于Slf4j在编译期间,静态绑定本地的LOG库使得通用性要比Commons Logging要好。
根据log4j2的官方介绍,log4j2的性能要比logback性能更加优异,当然这可能免不了“王婆卖瓜,自卖自夸”的成分,但从数据上来看确实是log4j2的性能更加优异,这得益于它的异步处理机制,实现了AsyncAppender,引入了无锁解构的Disruptor队列,替代Logback的ArrayBlockingQueue
以下是官方性能对比图(官网对比连接http://logging.apache.org/log4j/2.x/manual/async.html)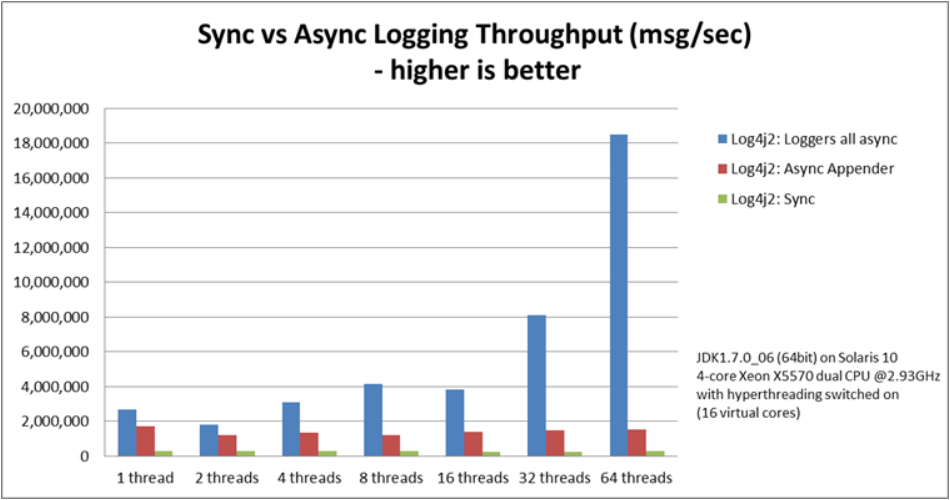

功能成熟度
在早期log4j成熟度不高,而当时的logback的功能可谓是十分全面,得到了多数开发者的追捧,但在log4j2出来后。提供了几乎全部场景的 Appender,文件、控制台、JDBC、NoSql、MQ、Syslog、Socket、SMTP等,而Logback提供 Appender 略少于 Log4j2,提供了文件、控制台、数据库、Syslog、Socket、SMTP等,动态化输出方面,Log4j2 提供了ScriptAppenderSelector,Logback 则提供了 Evaluator 与 SiftingAppender(两者均可以用于判断并选择对应的 Appender),Log4j2 API 支持使用java8 lambda,SLF4j 则在 2.0 版本提供流式(Fluent)API 同时支持 lambda,单论功能log4j2和logback可能相差不大,而配置上logback仅支持xml和groovy
生态:
logback由于早期的用户群体庞大,文档完善,并且现在仍然被大部分公司所使用,于2018年后不再更新,生态发展相对平衡
由于Log4j2 背后的Apache使得它有着不错的用户支持,并且官网文档也很完善,并且由于时间的累计,目前百度提供关于log4j2的内容越来越丰富了
附:仓库对比
logback : https://github.com/qos-ch/logback
log4j2: https://github.com/apache/logging-log4j2
日志系统
由于系统日渐复杂,每次线上出现问题都需要登录服务器拉取对应日志,而且日志极有可能被覆盖,导致开发者们无法及时的定位问题,这时普通单一的日志系统不再适当今的系统环境,尤其是在如今分布式微服务,容器云,大数据时代,单一的日志输出已经无法满足开发者们的需求了,于是,一套关于日志采集,传输,保存,过滤,分析的日志系统出现了
日志系统的发展
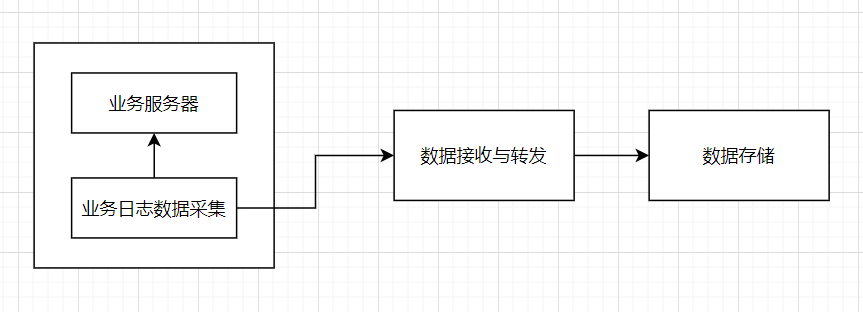
早期比较流行的架构一般为flume + hadoop + hive(离线日志架构),基本架构如下

整个离线分析的总体架构就是使用Flume从FTP服务器上采集日志文件,并存储在Hadoop HDFS文件系统上,再接着用Hadoop的mapreduce清洗日志文件,最后使用HIVE构建数据仓库做离线分析,最终展示给页面
知乎kids日志系统
kids是知乎的日志收集系统。采用Scribe的消息聚合模型和Redis的 pub/sub 模型。官方架构图如下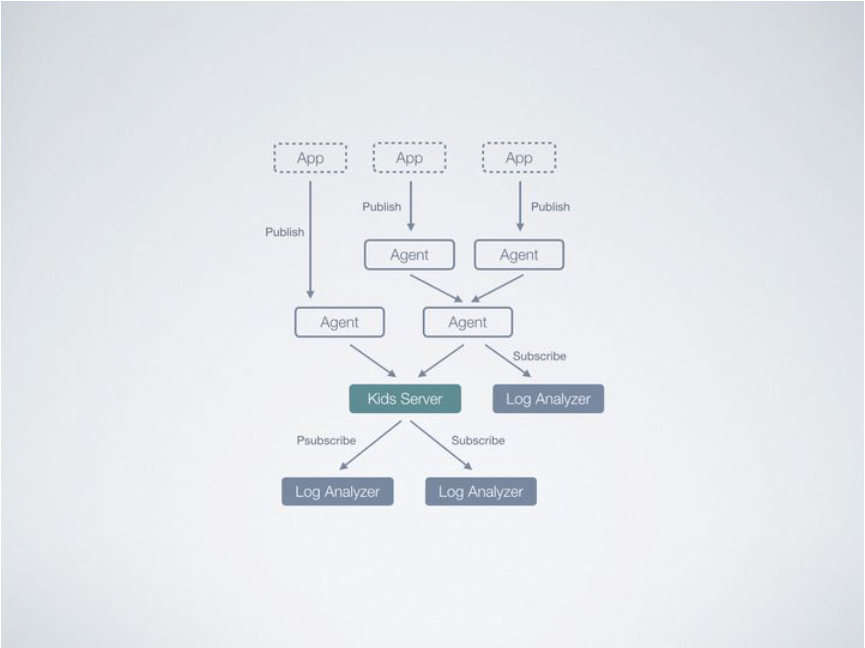

早期知乎用户注册方式采用邀请制注册,在后面开发注册后,出现了一批广告大军,传闻kids早期用来做广告文章筛选,此后在线上稳定跑了两年之后,知乎于2014年开源kids,仓库地址:https://github.com/zhihu/kids
ELK日志系统
ELK日志系统是由elasticsearch + logstash + kibana 构成,分别取每个单词的首字母作为名字。es主要用于日志信息的存储,logstash用于采集,清洗日志信息,kibana则用于日志信息的展示,以下是他们基本的架构图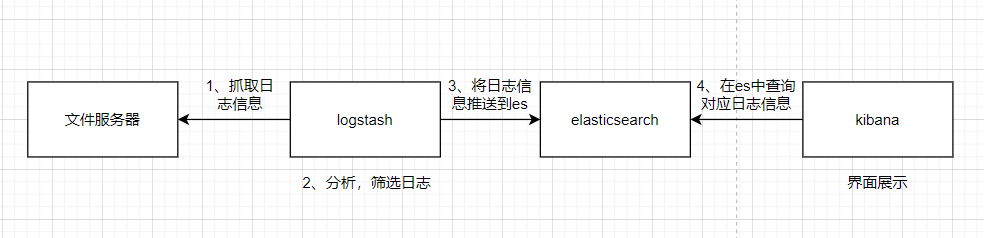

若有收获,就点个赞吧
0 人点赞
