介绍
以下来自官方介绍
https://zookeeper.apache.org/
ZooKeeper是一个集中维护配置信息、命名、提供分布式同步、提供组服务的服务。和eureka,nacos这些分布式服务注册管理类似,其实从zookeeper这个名字不难看出,他是hadoop(大象),hive(蜜蜂),pig(小猪),Hama(河马)这些动物的管理员,充当服务管理者的角色,那么这些为什么要管理呢?以及zookeeper是如何管理的呢?要弄清楚这些,还是得先明白几个分布式常见得问题
zookeeper分布式锁
zookeeper分布式锁指分布式环境中多个进程之间得资源竞争,而zookeeper正是协调这些进程,让他们有序的去访问某种共享资源,从而达到分布式环境当中多个进程之间的同步控制,那么什么是分布式系统呢?所谓分布式系统就是在不同地域分布的多个服务器,共同组成的一个应用系统来为用户提供服务,在分布式系统中最重要的是进程的调度
这里假设有三个业务服务器组成的一个应用系统,他们同时去竞争这个资源服务器,那么如何让他们有序的去访问呢?在java多线程中可以使用锁,但由于这些服务器每一个都是一个单独的进程,所以我们需要一个”进程锁“,就是我们常说的分布式锁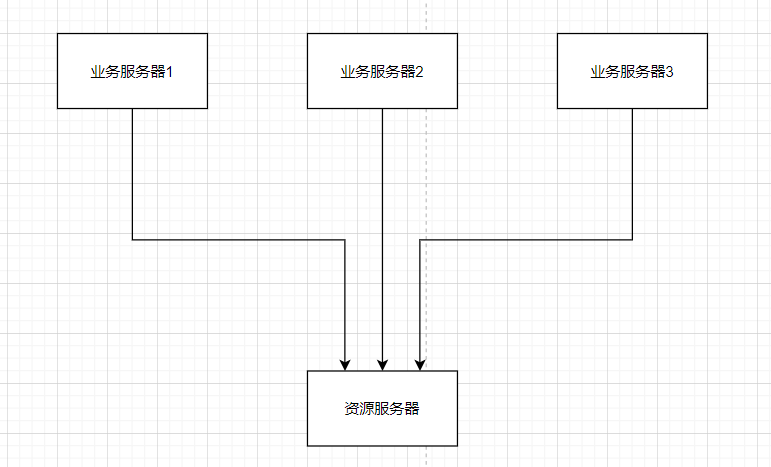
zookeeper的锁机制
基本概念
有序节点:假如当前有一个父节点为/lock,我们可以在这个父节点下面创建子节点;zookeeper提供了一个可选的有序特性,例如我们可以创建子节点“/lock/xxxx-”并且指明有序,那么zookeeper在生成子节点时会根据当前的子节点数量自动添加整数序号,也就是说如果是第一个创建的子节点,那么生成的子节点为/lock/xxxx-0000000000,下一个节点则为/lock/xxxx-0000000001,依次类推。
临时节点:客户端可以建立一个临时节点,在会话结束或者会话超时后,zookeeper会自动删除该节点。
事件监听:在读取数据时,我们可以同时对节点设置事件监听,当节点数据或结构变化时,zookeeper会通知客户端。当前zookeeper有如下四种事件:
- 节点创建
- 节点删除
- 节点数据修改
- 子节点变更。
以上图为例,”业务服务器1”在访问资源的时候,会先去获得这把锁,”进程1”获得锁以后会对该资源保持独占,此时其它进程就无法访问该资源,”业务服务器1”在用完该资源(执行相应的业务代码)以后会将该锁释放掉,同时通知客户端的其他节点,以便让其它进程来获得锁。这样就达成了有序竞争了,下面为分布式锁示意图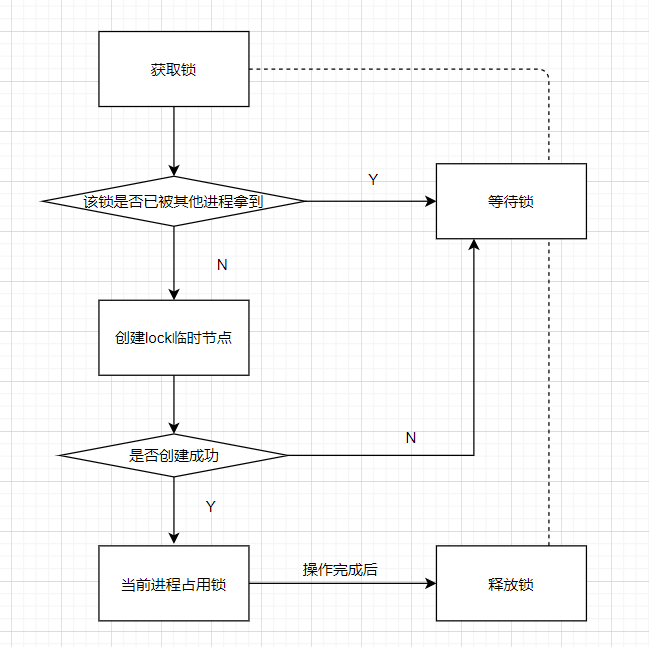
但是在这个情况下,如果客户端的数量比较多,假设有100个,那么此时100个客户端都会被唤醒,这种情况称为”羊群效应“,那么如何避免呢?此时就需要注意节点下的子节点顺序列表了,在唤醒客户端时,只需要唤醒节点顺序列表中最小的子节点,例如第一个业务服务器下的节点值为lock/xxx-000000,第二个为lock/xxx-000001,第三个为lock/xxx-000002,在第一个业务服务器释放锁以后,客户端获取/lock下的子节点列表,判断自己创建的子节点是否为当前子节点列表中序号最小的子节点,此时xxx-000001 < xxx-000002,业务服务器二获得锁。
zookeeper的选举机制
解决单点故障
所谓单点故障,就是在一个主从的分布式系统中,主节点负责任务调度分发,从节点负责任务的处理,而当主节点发生故障时,整个应用系统也就瘫痪了,那么这种故障就称为单点故障。
传统方式通过对集群进行Master角色的选举,来解决分布式系统中的单点故障问题,传统的方式是采用一个备用节点,这个备用节点定期向主节点发送ping包,主节点收到ping包以后向备用节点发送回复Ack信息,当备用节点收到回复的时候就会认为当前主节点运行正常,让它继续提供服务。而当主节点故障时,备用节点就无法收到回复信息了,此时,备用节点就认为主节点宕机,然后接替它成为新的主节点继续提供服务。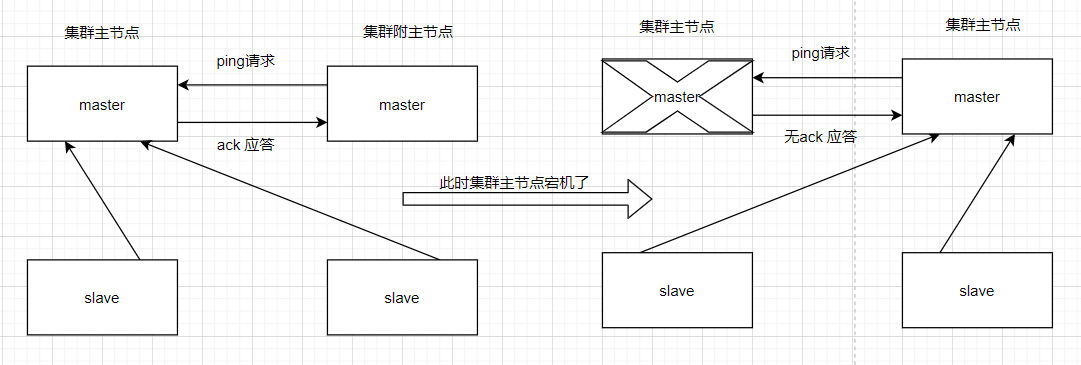
这种传统解决单点故障的方法,虽然在一定程度上解决了问题,但是有一个隐患,就是网络问题,可能会存在这样一种情况:主节点并没有出现故障,只是在回复ack响应的时候网络发生了故障,这样备用节点就无法收到回复,那么它就会认为主节点出现了故障,接着,备用节点将接管主节点的服务,并成为新的主节点,此时,分布式系统中就出现了两个主节点(双Master节点)的情况,双Master节点的出现,会导致分布式系统的服务发生混乱。这样的话,整个分布式系统将变得不可用,此时就需要使用zookeeper了
下面通过三种情形,介绍下Zookeeper是如何解决的
Master启动
在分布式系统中引入Zookeeper以后,就可以配置多个主节点,这里以配置两个主节点为例(生产环境建议配置服务数量为奇数个),假定它们是”主节点A”和”主节点B”,当两个主节点都启动后,它们都会向ZooKeeper中注册节点信息。我们假设”主节点A”锁注册的节点信息是”master0001”,”主节点B”注册的节点信息是”master0002”,注册完以后会进行选举,选举有多种算法,这里以编号最小作为选举算法,那么编号最小的节点将在选举中获胜并获得锁成为主节点,也就是”主节点A”将会获得锁成为主节点,然后”主节点B”将被阻塞成为一个备用节点。这样,通过这种方式Zookeeper就完成了对两个Master进程的调度。完成了主、备节点的分配和协作。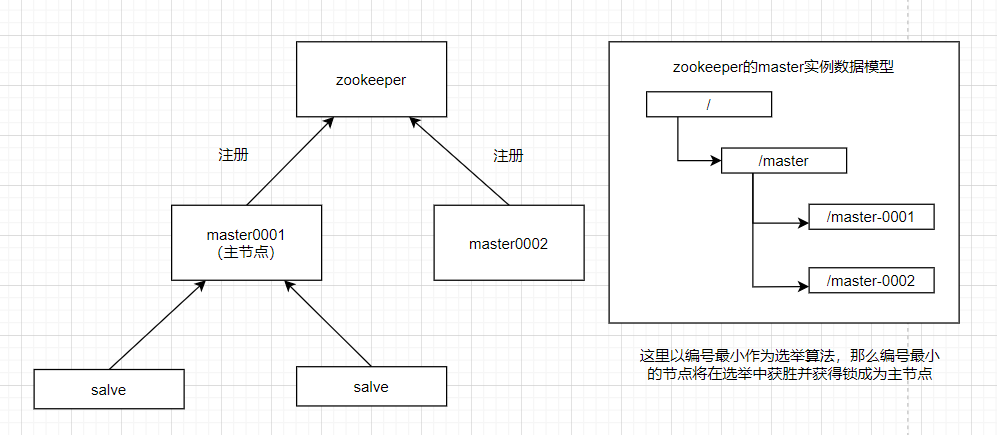
Master故障
如果”主节点A”发生了故障,这时候它在ZooKeeper所注册的节点信息会被自动删除,而ZooKeeper会自动感知节点的变化,发现”主节点A”故障后,会再次发出选举,这时候”主节点B”将在选举中获胜,替代”主节点A”成为新的主节点,这样就完成了主、被节点的重新选举。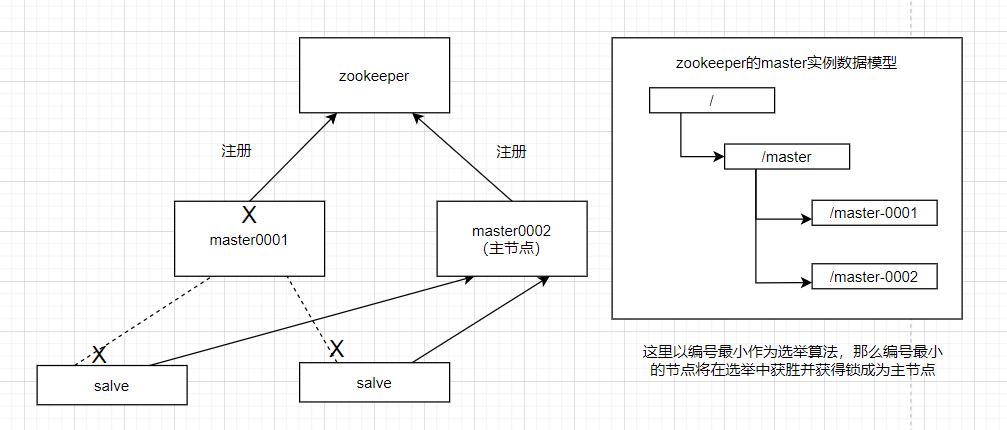
Master恢复
如果主节点恢复了,它会再次向ZooKeeper注册自身的节点信息,只不过这时候它注册的节点信息将会变成”master0003”,而不是原来的信息。ZooKeeper会感知节点的变化再次发动选举,这时候”主节点B”在选举中会再次获胜继续担任”主节点”,”主节点A”会担任备用节点。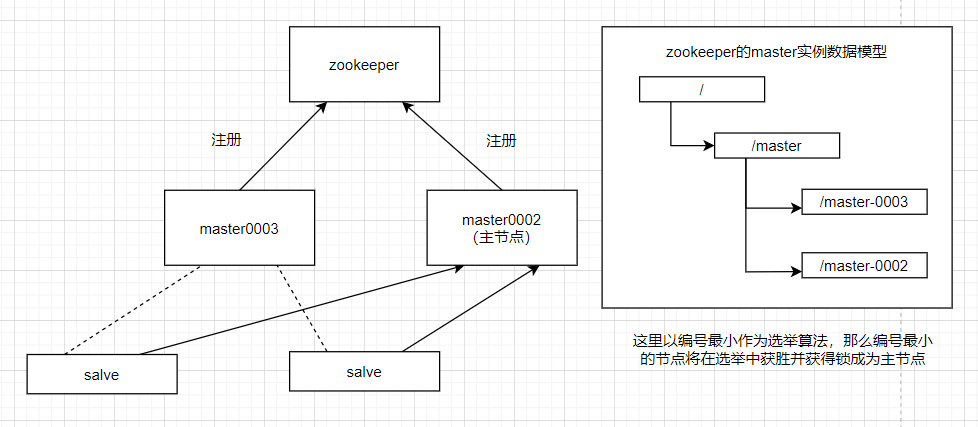
zookeeper集群架构
zookeeper一般是通过集群架构来提供服务的,下图是官方的zookeeper基本架构图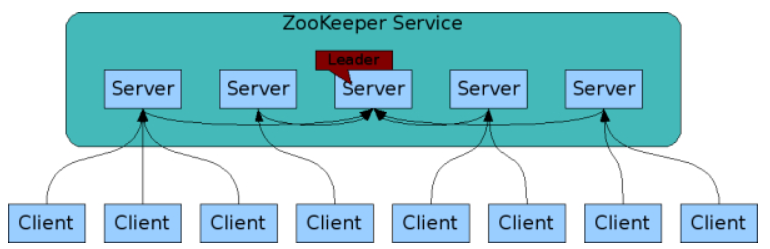
zookeeper集群主要角色有Server和client,其中,Server又分为Leader、Follower和Observer三个角色,每个角色的含义如下:
Leader:领导者角色,主要负责投票的发起和决议,以及更新系统状态。
Follower:跟随者角色,用于接收客户端的请求并返回结果给客户端,在选举过程中参与投票。
Observer:观察者角色,用户接收客户端的请求,并将写请求转发给leader,同时同步leader状态,但不参与投票。Observer目的是扩展系统,提高伸缩性。
Client:客户端角色,用于向Zookeeper发起请求。
zookeeper集群中每个Server在内存中存储了一份数据,在Zookeeper启动时,将从实例中选举一个Server作为leader,Leader负责处理数据更新等操作,当且仅当大多数Server在内存中成功修改数据,才认为数据修改成功。<br /> zookeeper写的流程为:客户端Client首先和一个Server或者Observe通信,发起写请求,然后Server将写请求转发给Leader, Leader再将写请求转发给其它Server,其它Server在接收到写请求后写入数据并响应Leader,Leader在接收到大多数写成功回应后,认为数据写成功,最后响应Client,完成一次写操作过程。
zookeeper部署时为什么时奇数个呢?
对于集群模式下的ZooKeeper部署,官方建议至少要三台服务器,关于服务器的数量,推荐是奇数个(3、5、7、9等等),而为什么使用奇数个,原因是leader选举,要求 可用节点数量 > 总节点数量/2,举个例子:
假设3个节点,那么剩余节点数必须大于3/2=1.5 , 即zookeeper想要正常提供服务(即leader选举成功),至少需要2个节点是正常的,可允许宕机服务器数为1,如果是4个节点,那么剩余节点数必须大于3/2=2,至少需要3个节点是正常的,可允许宕机服务器数也为1,此时如果为了节省资源,在同等的容错率的情况下,首选奇数个。
推荐阅读:https://www.pianshen.com/article/38431178266/

若有收获,就点个赞吧
0 人点赞
