 11讲答疑课堂:深⼊了解NIO的优化实现原理
11讲答疑课堂:深⼊了解NIO的优化实现原理
你好,我是刘超。专栏上线已经有20多天的时间了,⾸先要感谢各位同学的积极留⾔,交流的过程使我也收获良好。
 综合查看完近期的留⾔以后,我的第⼀篇答疑课堂就顺势诞⽣了。我将继续讲解I/O优化,对⼤家在08讲中提到的内容做重点补充,并延伸⼀些有关I/O的知识点,更多结合实际场景进⾏分享。话不多说,我们⻢上切⼊正题。
综合查看完近期的留⾔以后,我的第⼀篇答疑课堂就顺势诞⽣了。我将继续讲解I/O优化,对⼤家在08讲中提到的内容做重点补充,并延伸⼀些有关I/O的知识点,更多结合实际场景进⾏分享。话不多说,我们⻢上切⼊正题。
Tomcat中经常被提到的⼀个调优就是修改线程的I/O模型。Tomcat 8.5版本之前,默认情况下使⽤的是BIO线程模型,如果在
⾼负载、⾼并发的场景下,可以通过设置NIO线程模型,来提⾼系统的⽹络通信性能。
我们可以通过⼀个性能对⽐测试来看看在⾼负载或⾼并发的情况下,BIO和NIO通信性能(这⾥⽤⻚⾯请求模拟多I/O读写操作的请求):
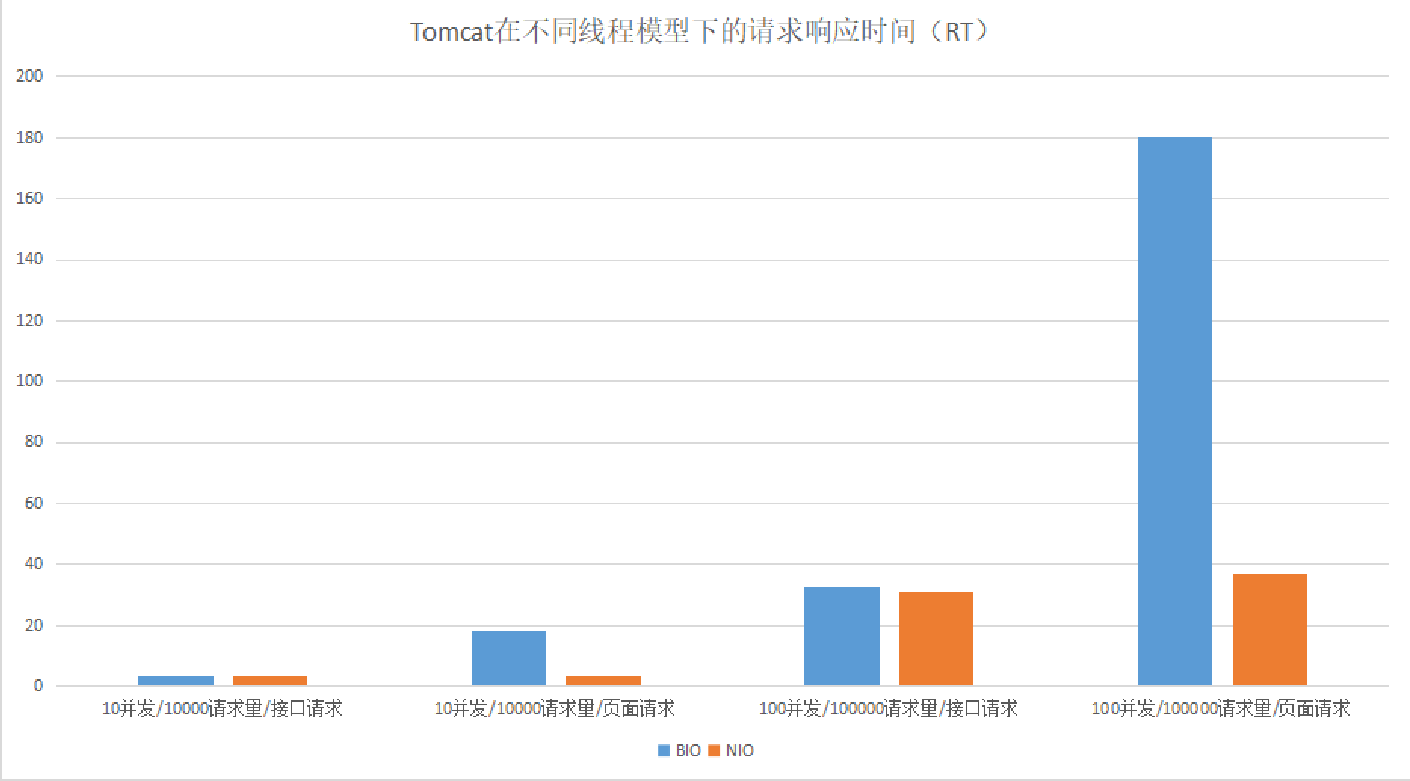
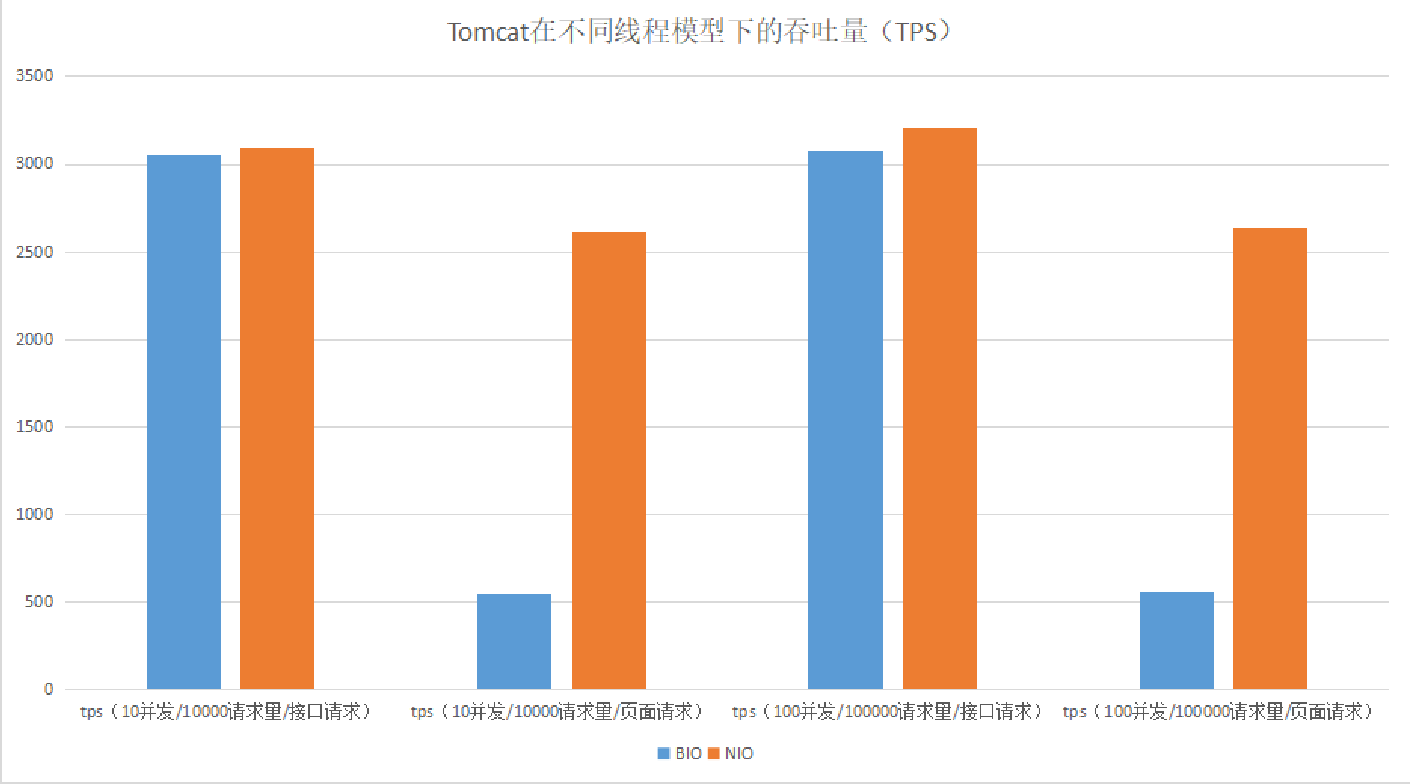
测试结果:Tomcat在I/O读写操作⽐较多的情况下,使⽤NIO线程模型有明显的优势。
Tomcat中看似⼀个简单的配置,其中却包含了⼤量的优化升级知识点。下⾯我们就从底层的⽹络I/O模型优化出发,再到内存拷⻉优化和线程模型优化,深⼊分析下Tomcat、Netty等通信框架是如何通过优化I/O来提⾼系统性能的。
⽹络I/O模型优化
⽹络通信中,最底层的就是内核中的⽹络I/O模型了。随着技术的发展,操作系统内核的⽹络模型衍⽣出了五种I/O模型,
《UNIX⽹络编程》⼀书将这五种I/O模型分为阻塞式I/O、⾮阻塞式I/O、I/O复⽤、信号驱动式I/O和异步I/O。每⼀种I/O模型的
出现,都是基于前⼀种I/O模型的优化升级。
最开始的阻塞式I/O,它在每⼀个连接创建时,都需要⼀个⽤户线程来处理,并且在I/O操作没有就绪或结束时,线程会被挂起,进⼊阻塞等待状态,阻塞式I/O就成为了导致性能瓶颈的根本原因。
那阻塞到底发⽣在套接字(socket)通信的哪些环节呢?
在《Unix⽹络编程》中,套接字通信可以分为流式套接字(TCP)和数据报套接字(UDP)。其中TCP连接是我们最常⽤
的,⼀起来了解下TCP服务端的⼯作流程(由于TCP的数据传输⽐较复杂,存在拆包和装包的可能,这⾥我只假设⼀次最简单的TCP数据传输):
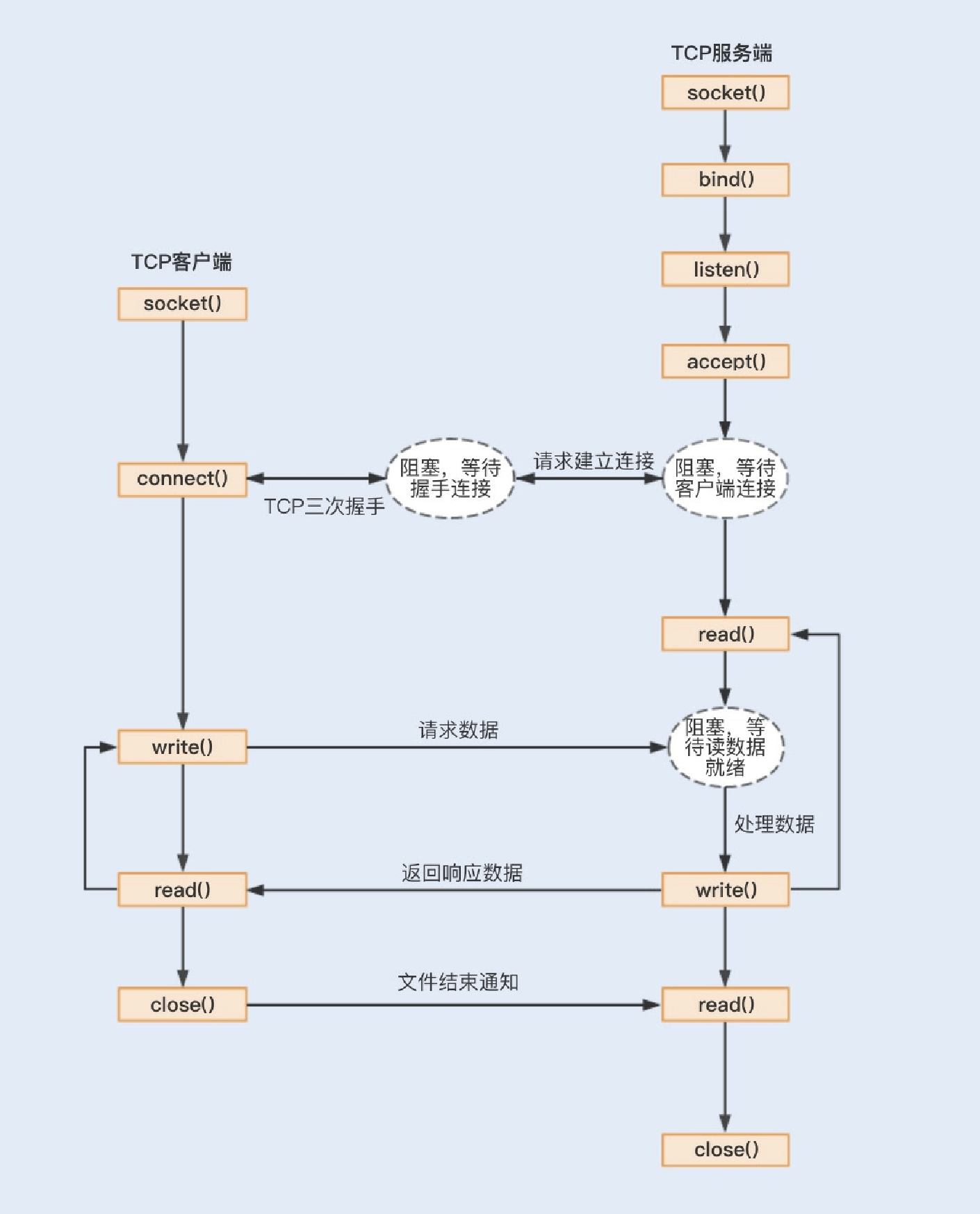
⾸先,应⽤程序通过系统调⽤socket创建⼀个套接字,它是系统分配给应⽤程序的⼀个⽂件描述符;
其次,应⽤程序会通过系统调⽤bind,绑定地址和端⼝号,给套接字命名⼀个名称; 然后,系统会调⽤listen创建⼀个队列⽤于存放客户端进来的连接;
最后,应⽤服务会通过系统调⽤accept来监听客户端的连接请求。
当有⼀个客户端连接到服务端之后,服务端就会调⽤fork创建⼀个⼦进程,通过系统调⽤read监听客户端发来的消息,再通过
write向客户端返回信息。
1.阻塞式I/O
在整个socket通信⼯作流程中,socket的默认状态是阻塞的。也就是说,当发出⼀个不能⽴即完成的套接字调⽤时,其进程将被阻塞,被系统挂起,进⼊睡眠状态,⼀直等待相应的操作响应。从上图中,我们可以发现,可能存在的阻塞主要包括以下三种。
connect阻塞:当客户端发起TCP连接请求,通过系统调⽤connect函数,TCP连接的建⽴需要完成三次握⼿过程,客户端需要等待服务端发送回来的ACK以及SYN信号,同样服务端也需要阻塞等待客户端确认连接的ACK信号,这就意味着TCP的每个connect都会阻塞等待,直到确认连接。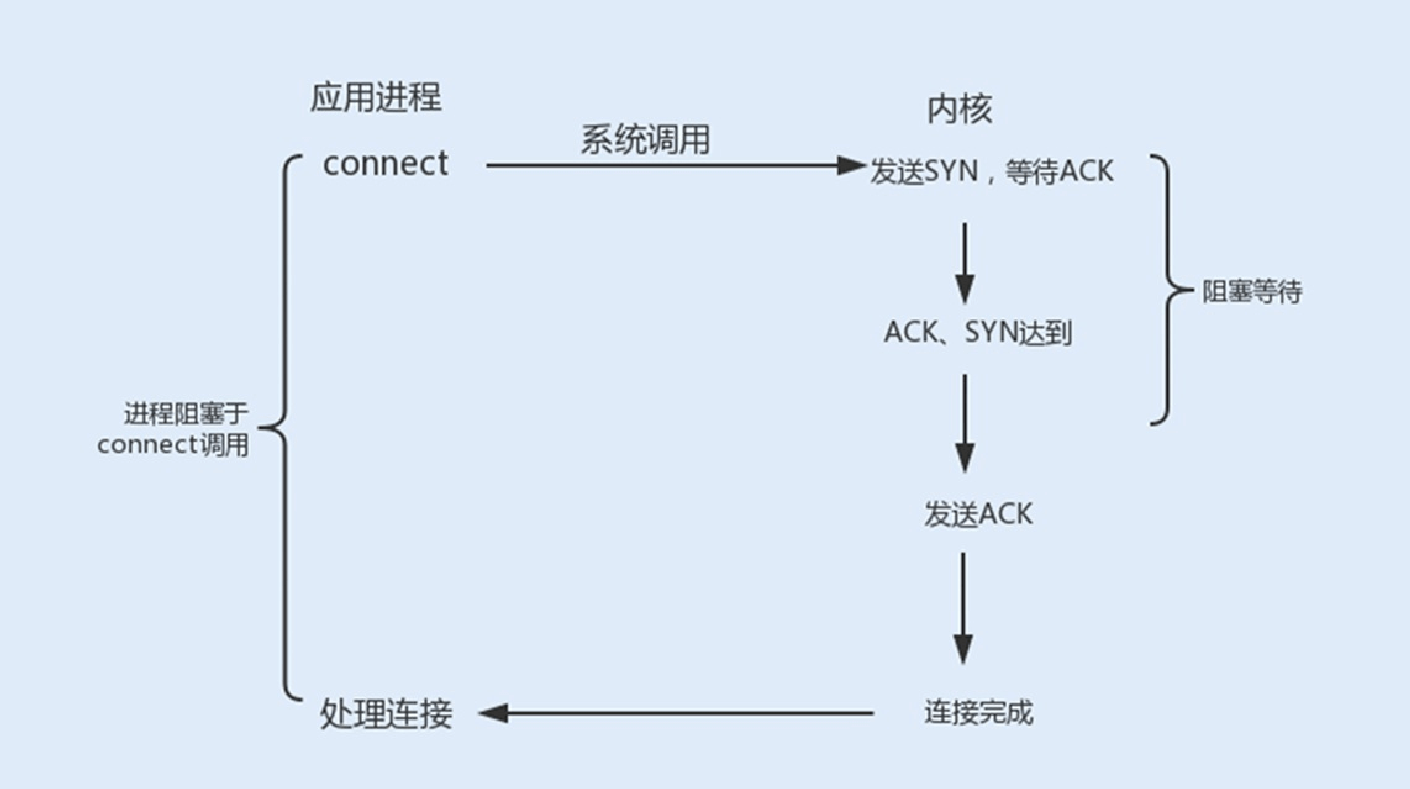
accept阻塞:⼀个阻塞的socket通信的服务端接收外来连接,会调⽤accept函数,如果没有新的连接到达,调⽤进程将被挂起,进⼊阻塞状态。
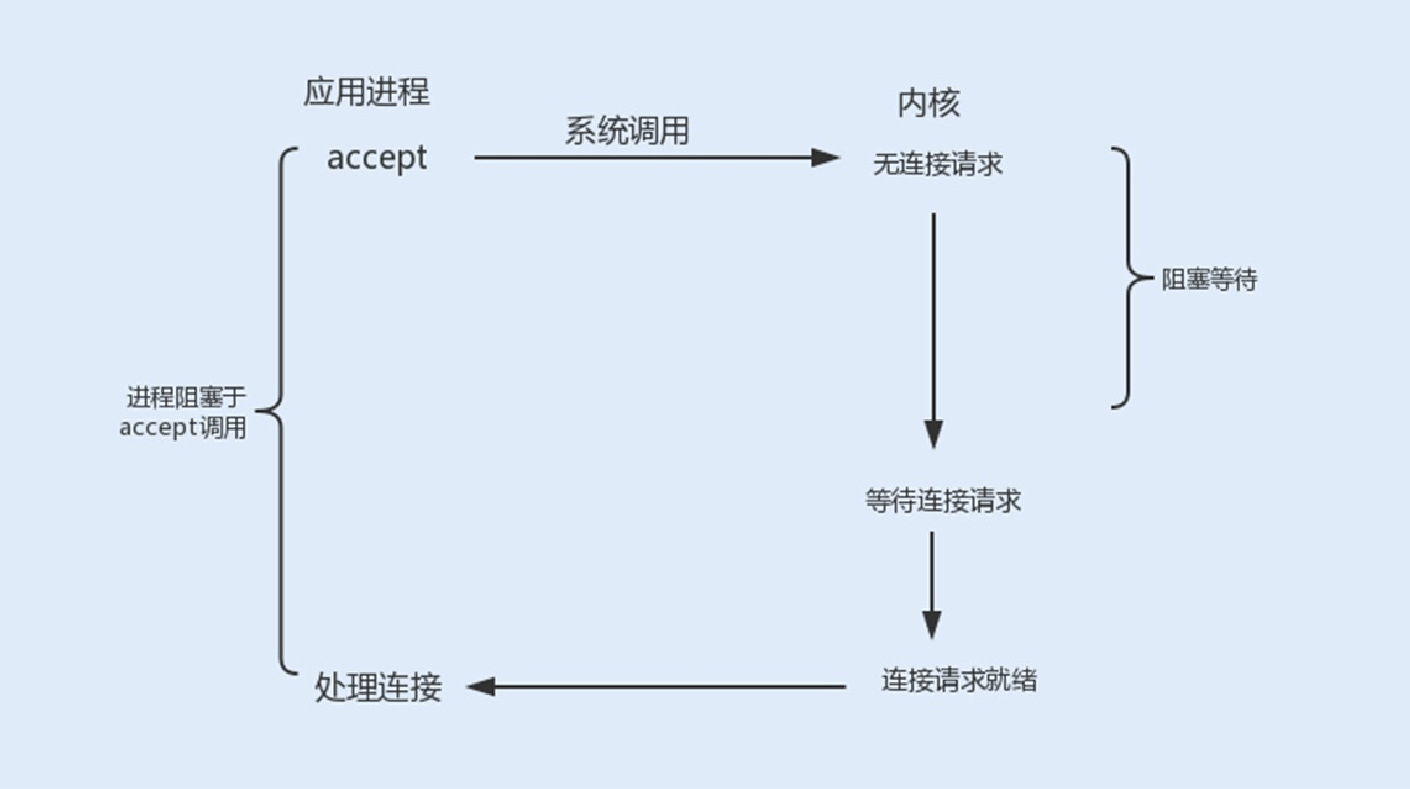
read、write阻塞:当⼀个socket连接创建成功之后,服务端⽤fork函数创建⼀个⼦进程, 调⽤read函数等待客户端的数据写
⼊,如果没有数据写⼊,调⽤⼦进程将被挂起,进⼊阻塞状态。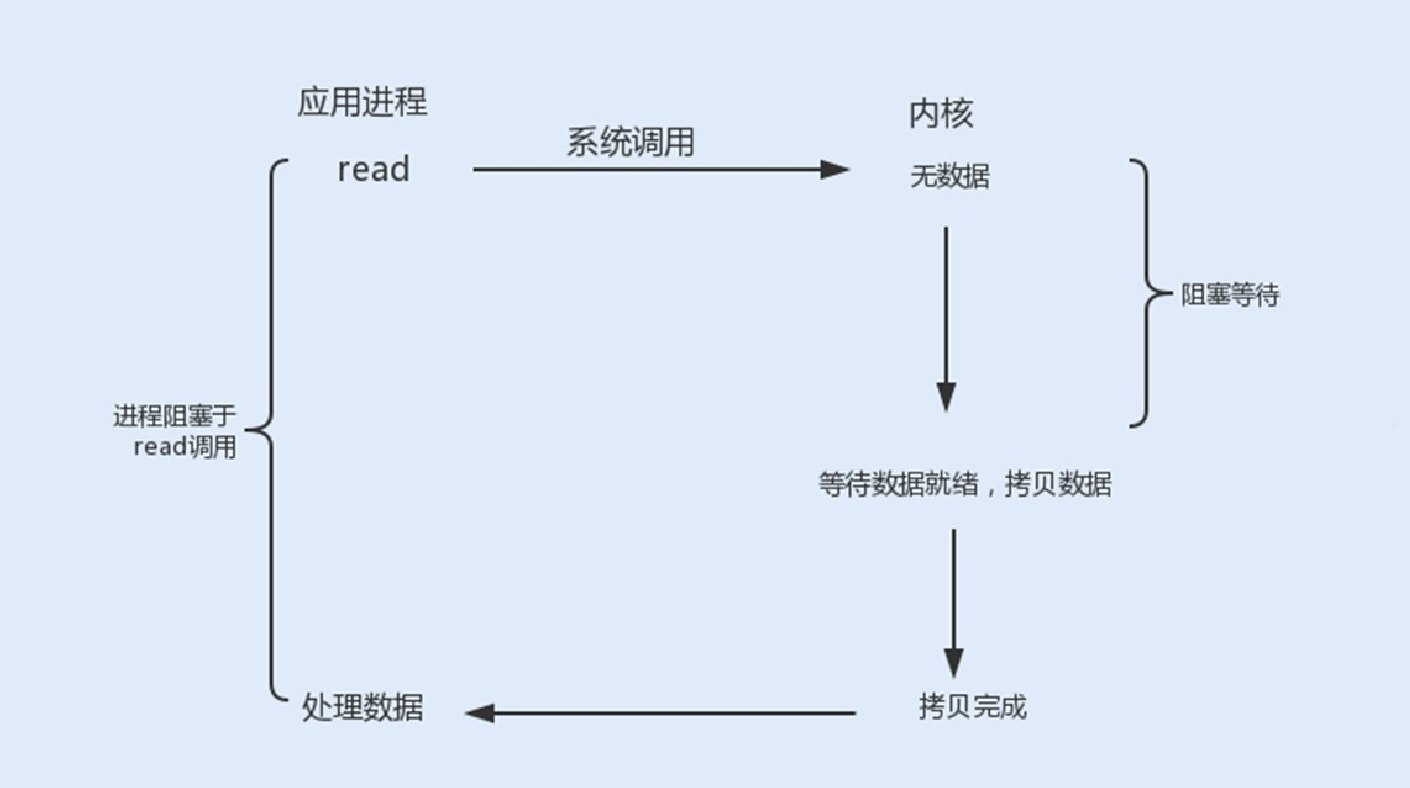
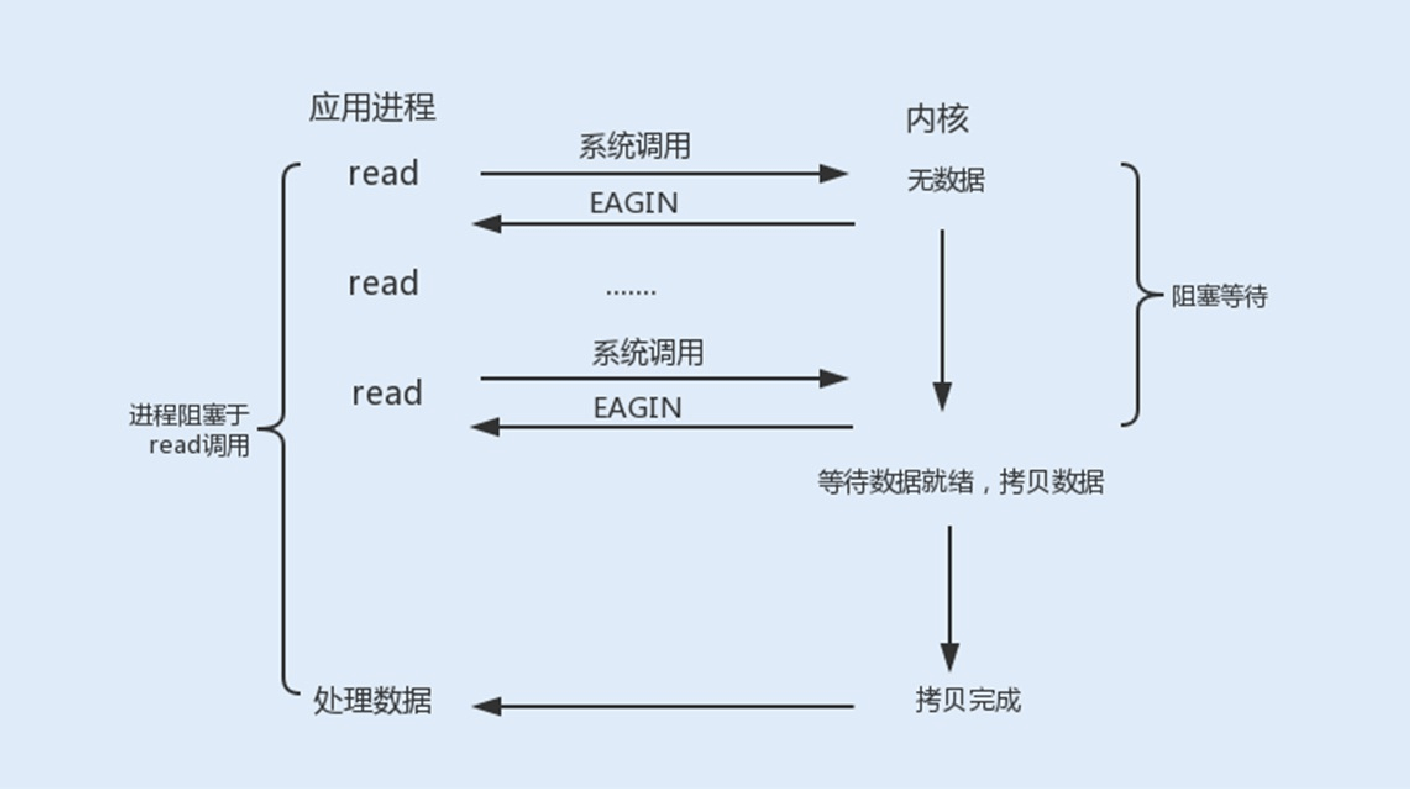
2.⾮阻塞式I/O
使⽤fcntl可以把以上三种操作都设置为⾮阻塞操作。如果没有数据返回,就会直接返回⼀个EWOULDBLOCK或EAGAIN错误,此时进程就不会⼀直被阻塞。
当我们把以上操作设置为了⾮阻塞状态,我们需要设置⼀个线程对该操作进⾏轮询检查,这也是最传统的⾮阻塞I/O模型。
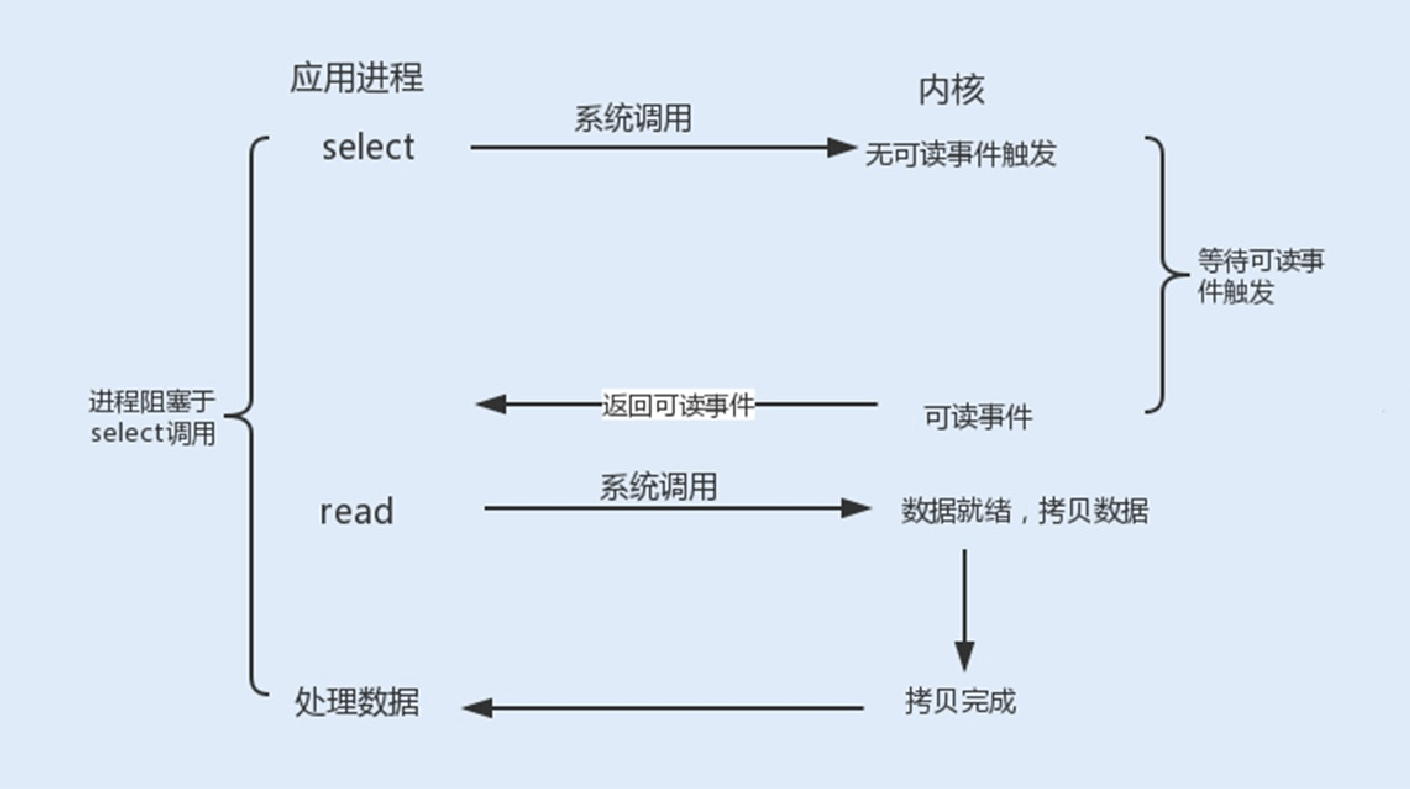
I/O复⽤
如果使⽤⽤户线程轮询查看⼀个I/O操作的状态,在⼤量请求的情况下,这对于CPU的使⽤率⽆疑是种灾难。 那么除了这种⽅式,还有其它⽅式可以实现⾮阻塞I/O套接字吗?
Linux提供了I/O复⽤函数select/poll/epoll,进程将⼀个或多个读操作通过系统调⽤函数,阻塞在函数操作上。这样,系统内核就可以帮我们侦测多个读操作是否处于就绪状态。
select()函数:它的⽤途是,在超时时间内,监听⽤户感兴趣的⽂件描述符上的可读可写和异常事件的发⽣。Linux 操作系统的内核将所有外部设备都看做⼀个⽂件来操作,对⼀个⽂件的读写操作会调⽤内核提供的系统命令,返回⼀个⽂件描述符
(fd)。
int select(int maxfdp1,fd_set readset,fd_set writeset,fd_set exceptset,const struct timeval timeout)
查看以上代码,select() 函数监视的⽂件描述符分3类,分别是writefds(写⽂件描述符)、readfds(读⽂件描述符)以及
exceptfds(异常事件⽂件描述符)。
调⽤后select() 函数会阻塞,直到有描述符就绪或者超时,函数返回。当select函数返回后,可以通过函数FD_ISSET遍历
fdset,来找到就绪的描述符。fd_set可以理解为⼀个集合,这个集合中存放的是⽂件描述符,可通过以下四个宏进⾏设置:
void FD_ZERO(fd_set fdset); //清空集合
void FD_SET(int fd, fd_set fdset); //将⼀个给定的⽂件描述符加⼊集合之中 void FD_CLR(int fd, fd_set fdset); //将⼀个给定的⽂件描述符从集合中删除
int FD_ISSET(int fd, fd_set fdset); // 检查集合中指定的⽂件描述符是否可以读写
poll()函数:在每次调⽤select()函数之前,系统需要把⼀个fd从⽤户态拷⻉到内核态,这样就给系统带来了⼀定的性能开销。
再有单个进程监视的fd数量默认是1024,我们可以通过修改宏定义甚⾄重新编译内核的⽅式打破这⼀限制。但由于fd_set是基于数组实现的,在新增和删除fd时,数量过⼤会导致效率降低。
poll() 的机制与 select() 类似,⼆者在本质上差别不⼤。poll() 管理多个描述符也是通过轮询,根据描述符的状态进⾏处理,但
poll() 没有最⼤⽂件描述符数量的限制。
poll() 和 select() 存在⼀个相同的缺点,那就是包含⼤量⽂件描述符的数组被整体复制到⽤户态和内核的地址空间之间,⽽⽆论这些⽂件描述符是否就绪,他们的开销都会随着⽂件描述符数量的增加⽽线性增⼤。
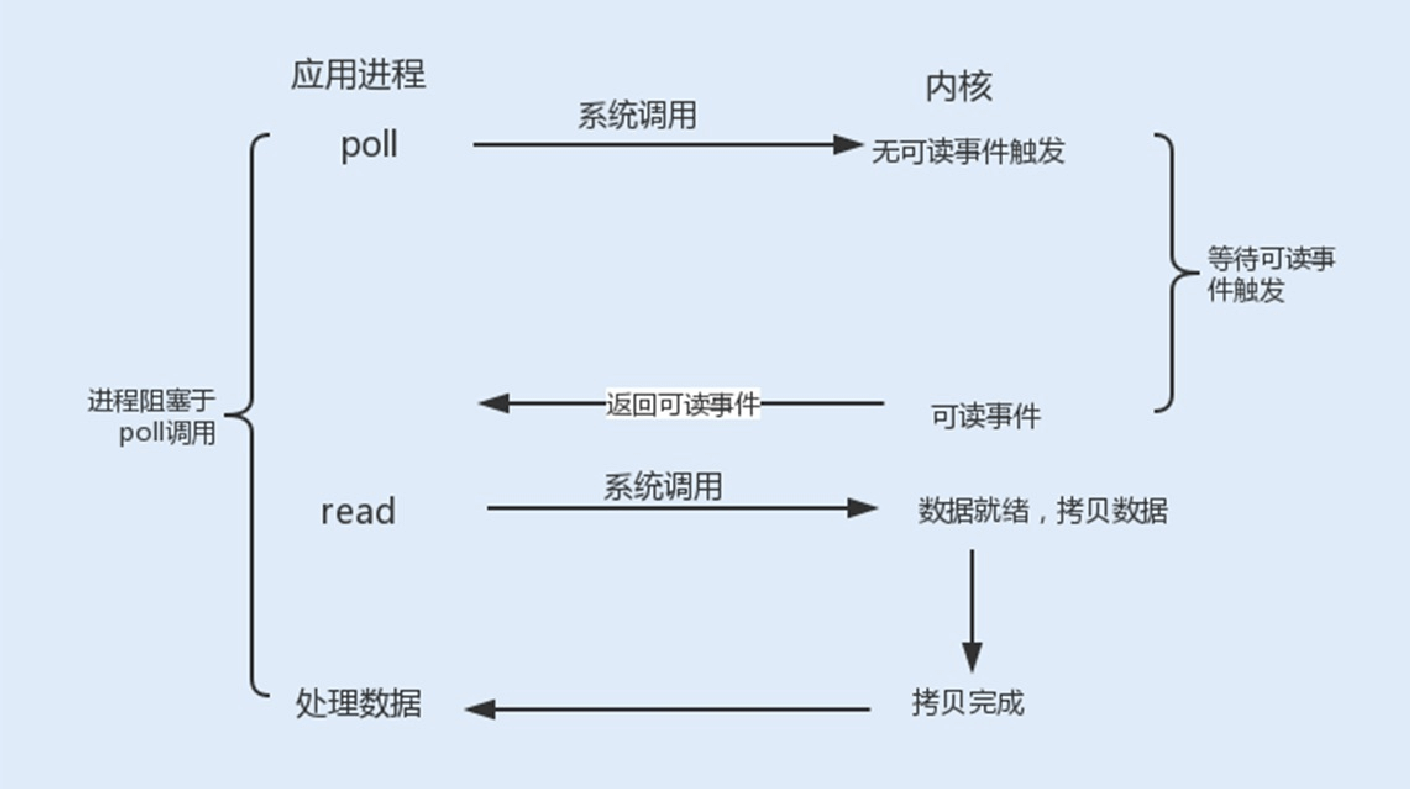
epoll()函数:select/poll是顺序扫描fd是否就绪,⽽且⽀持的fd数量不宜过⼤,因此它的使⽤受到了⼀些制约。
Linux在2.6内核版本中提供了⼀个epoll调⽤,epoll使⽤事件驱动的⽅式代替轮询扫描fd。epoll事先通过epoll_ctl()来注册⼀个
⽂件描述符,将⽂件描述符存放到内核的⼀个事件表中,这个事件表是基于红⿊树实现的,所以在⼤量I/O请求的场景下,插
⼊和删除的性能⽐select/poll的数组fd_set要好,因此epoll的性能更胜⼀筹,⽽且不会受到fd数量的限制。
int epoll_ctl(int epfd, int op, int fd, struct epoll_event event)
通过以上代码,我们可以看到:epoll_ctl()函数中的epfd是由 epoll_create()函数⽣成的⼀个epoll专⽤⽂件描述符。op代表操作事件类型,fd表示关联⽂件描述符,event表示指定监听的事件类型。
⼀旦某个⽂件描述符就绪时,内核会采⽤类似callback的回调机制,迅速激活这个⽂件描述符,当进程调⽤epoll_wait()时便得到通知,之后进程将完成相关I/O操作。
int epoll_wait(int epfd, struct epoll_event events,int maxevents,int timeout)
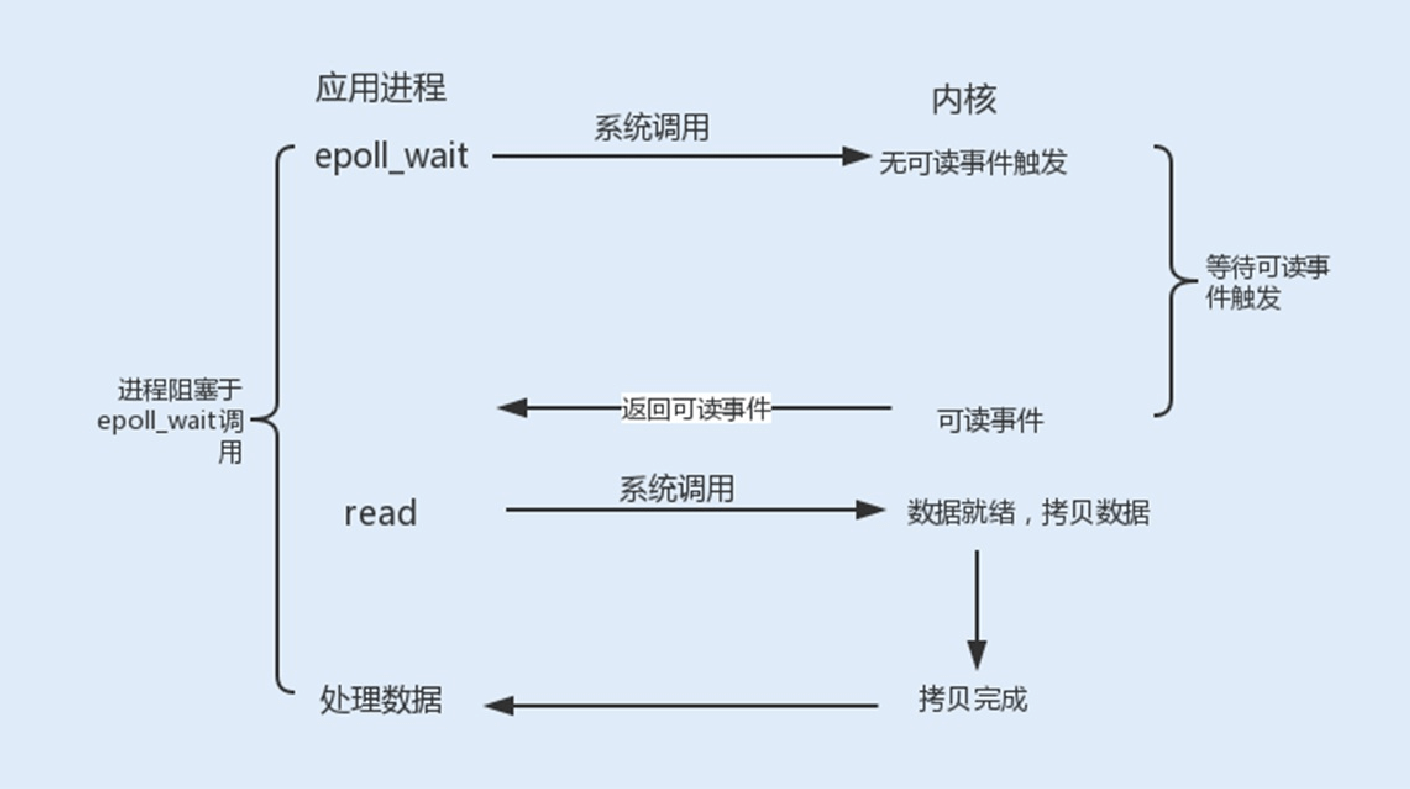
4.信号驱动式I/O
信号驱动式I/O类似观察者模式,内核就是⼀个观察者,信号回调则是通知。⽤户进程发起⼀个I/O请求操作,会通过系统调⽤
sigaction函数,给对应的套接字注册⼀个信号回调,此时不阻塞⽤户进程,进程会继续⼯作。当内核数据就绪时,内核就为该进程⽣成⼀个SIGIO信号,通过信号回调通知进程进⾏相关I/O操作。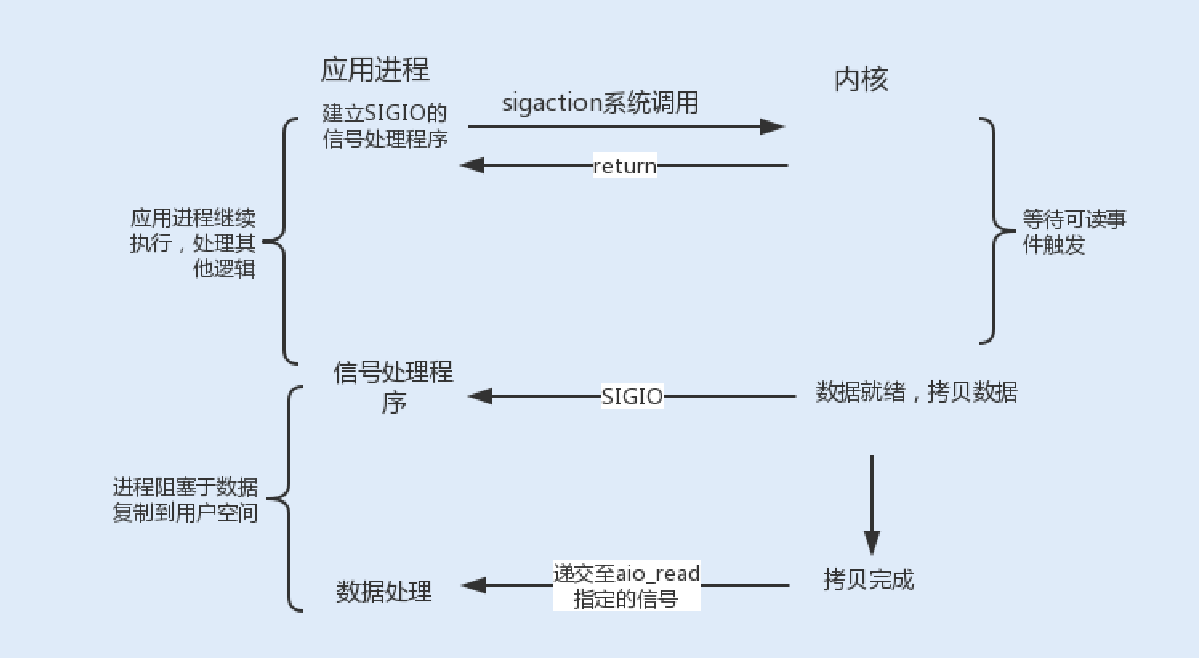
信号驱动式I/O相⽐于前三种I/O模式,实现了在等待数据就绪时,进程不被阻塞,主循环可以继续⼯作,所以性能更佳。
⽽由于TCP来说,信号驱动式I/O⼏乎没有被使⽤,这是因为SIGIO信号是⼀种Unix信号,信号没有附加信息,如果⼀个信号源有多种产⽣信号的原因,信号接收者就⽆法确定究竟发⽣了什么。⽽ TCP socket⽣产的信号事件有七种之多,这样应⽤程序 收到 SIGIO,根本⽆从区分处理。
但信号驱动式I/O现在被⽤在了UDP通信上,我们从10讲中的UDP通信流程图中可以发现,UDP只有⼀个数据请求事件,这也
就意味着在正常情况下UDP进程只要捕获SIGIO信号,就调⽤recvfrom读取到达的数据报。如果出现异常,就返回⼀个异常错误。⽐如,NTP服务器就应⽤了这种模型。
5.异步I/O
信号驱动式I/O虽然在等待数据就绪时,没有阻塞进程,但在被通知后进⾏的I/O操作还是阻塞的,进程会等待数据从内核空间复制到⽤户空间中。⽽异步I/O则是实现了真正的⾮阻塞I/O。
当⽤户进程发起⼀个I/O请求操作,系统会告知内核启动某个操作,并让内核在整个操作完成后通知进程。这个操作包括等待数据就绪和数据从内核复制到⽤户空间。由于程序的代码复杂度⾼,调试难度⼤,且⽀持异步I/O的操作系统⽐较少⻅(⽬前
Linux暂不⽀持,⽽Windows已经实现了异步I/O),所以在实际⽣产环境中很少⽤到异步I/O模型。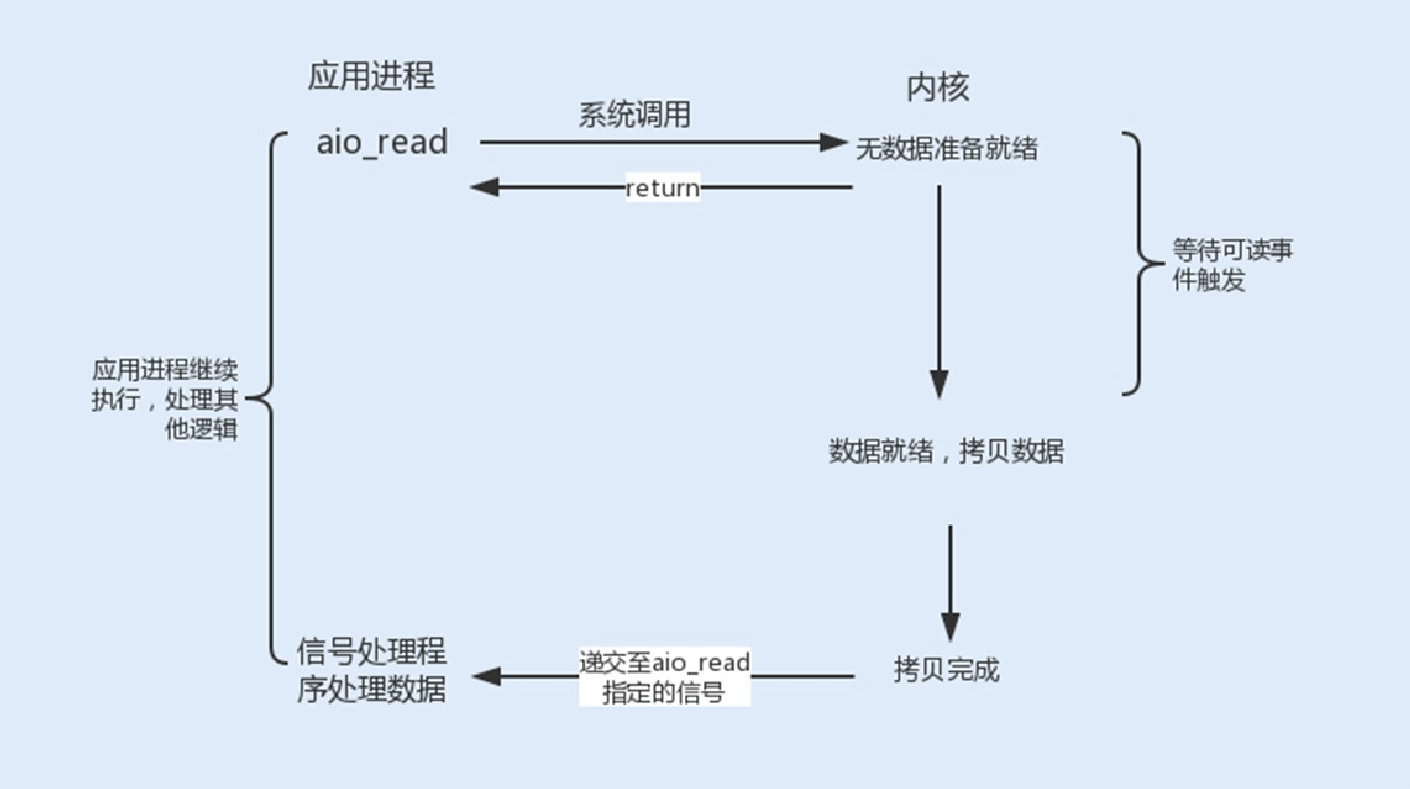
在08讲中,我讲到了NIO使⽤I/O复⽤器Selector实现⾮阻塞I/O,Selector就是使⽤了这五种类型中的I/O复⽤模型。Java中的
Selector其实就是select/poll/epoll的外包类。
我们在上⾯的TCP通信流程中讲到,Socket通信中的conect、accept、read以及write为阻塞操作,在Selector中分别对应
SelectionKey的四个监听事件OP_ACCEPT、OP_CONNECT、OP_READ以及OP_WRITE。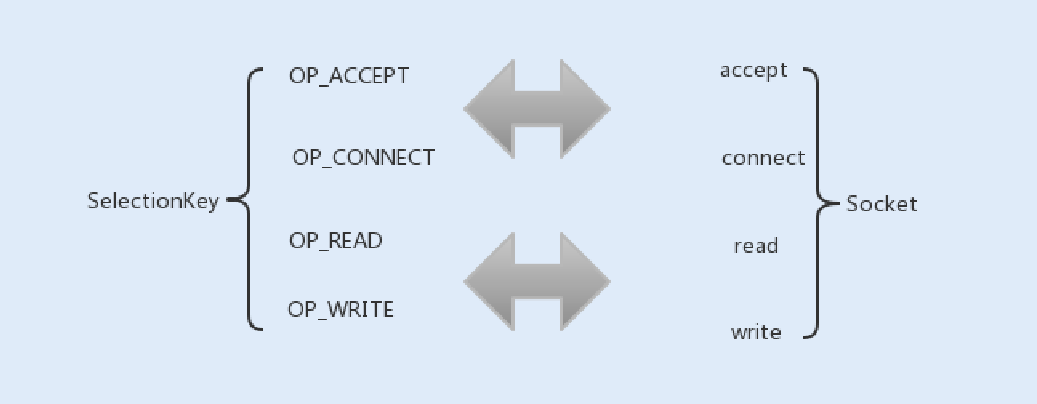
在NIO服务端通信编程中,⾸先会创建⼀个Channel,⽤于监听客户端连接;接着,创建多路复⽤器Selector,并将Channel注
册到Selector,程序会通过Selector来轮询注册在其上的Channel,当发现⼀个或多个Channel处于就绪状态时,返回就绪的监听事件,最后程序匹配到监听事件,进⾏相关的I/O操作。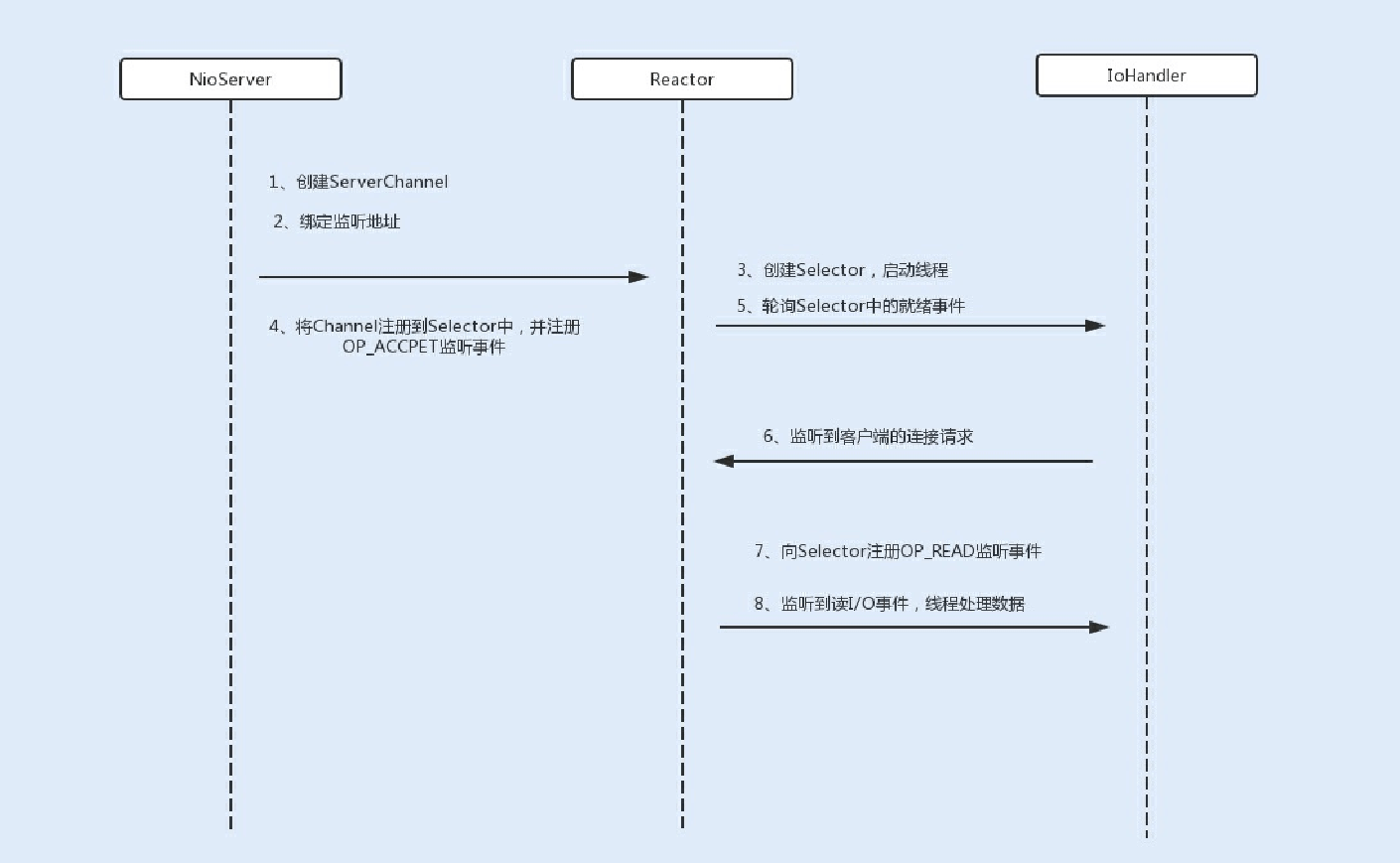
在创建Selector时,程序会根据操作系统版本选择使⽤哪种I/O复⽤函数。在JDK1.5版本中,如果程序运⾏在Linux操作系统, 且内核版本在2.6以上,NIO中会选择epoll来替代传统的select/poll,这也极⼤地提升了NIO通信的性能。
由于信号驱动式I/O对TCP通信的不⽀持,以及异步I/O在Linux操作系统内核中的应⽤还不⼤成熟,⼤部分框架都还是基于I/O 复⽤模型实现的⽹络通信。
零拷⻉
在I/O复⽤模型中,执⾏读写I/O操作依然是阻塞的,在执⾏读写I/O操作时,存在着多次内存拷⻉和上下⽂切换,给系统增加了性能开销。
零拷⻉是⼀种避免多次内存复制的技术,⽤来优化读写I/O操作。
在⽹络编程中,通常由read、write来完成⼀次I/O读写操作。每⼀次I/O读写操作都需要完成四次内存拷⻉,路径是I/O设备->内核空间->⽤户空间->内核空间->其它I/O设备。
Linux内核中的mmap函数可以代替read、write的I/O读写操作,实现⽤户空间和内核空间共享⼀个缓存数据。mmap将⽤户空 间的⼀块地址和内核空间的⼀块地址同时映射到相同的⼀块物理内存地址,不管是⽤户空间还是内核空间都是虚拟地址,最终要通过地址映射映射到物理内存地址。这种⽅式避免了内核空间与⽤户空间的数据交换。I/O复⽤中的epoll函数中就是使⽤了
mmap减少了内存拷⻉。
在Java的NIO编程中,则是使⽤到了Direct Buffer来实现内存的零拷⻉。Java直接在JVM内存空间之外开辟了⼀个物理内存空间,这样内核和⽤户进程都能共享⼀份缓存数据。这是在08讲中已经详细讲解过的内容,你可以再去回顾下。
线程模型优化
除了内核对⽹络I/O模型的优化,NIO在⽤户层也做了优化升级。NIO是基于事件驱动模型来实现的I/O操作。Reactor模型是同步I/O事件处理的⼀种常⻅模型,其核⼼思想是将I/O事件注册到多路复⽤器上,⼀旦有I/O事件触发,多路复⽤器就会将事件分发到事件处理器中,执⾏就绪的I/O事件操作。该模型有以下三个主要组件:
事件接收器Acceptor:主要负责接收请求连接;
事件分离器Reactor:接收请求后,会将建⽴的连接注册到分离器中,依赖于循环监听多路复⽤器Selector,⼀旦监听到事件,就会将事件dispatch到事件处理器;
事件处理器Handlers:事件处理器主要是完成相关的事件处理,⽐如读写I/O操作。
1.单线程Reactor线程模型
最开始NIO是基于单线程实现的,所有的I/O操作都是在⼀个NIO线程上完成。由于NIO是⾮阻塞I/O,理论上⼀个线程可以完成所有的I/O操作。
但NIO其实还不算真正地实现了⾮阻塞I/O操作,因为读写I/O操作时⽤户进程还是处于阻塞状态,这种⽅式在⾼负载、⾼并发的场景下会存在性能瓶颈,⼀个NIO线程如果同时处理上万连接的I/O操作,系统是⽆法⽀撑这种量级的请求的。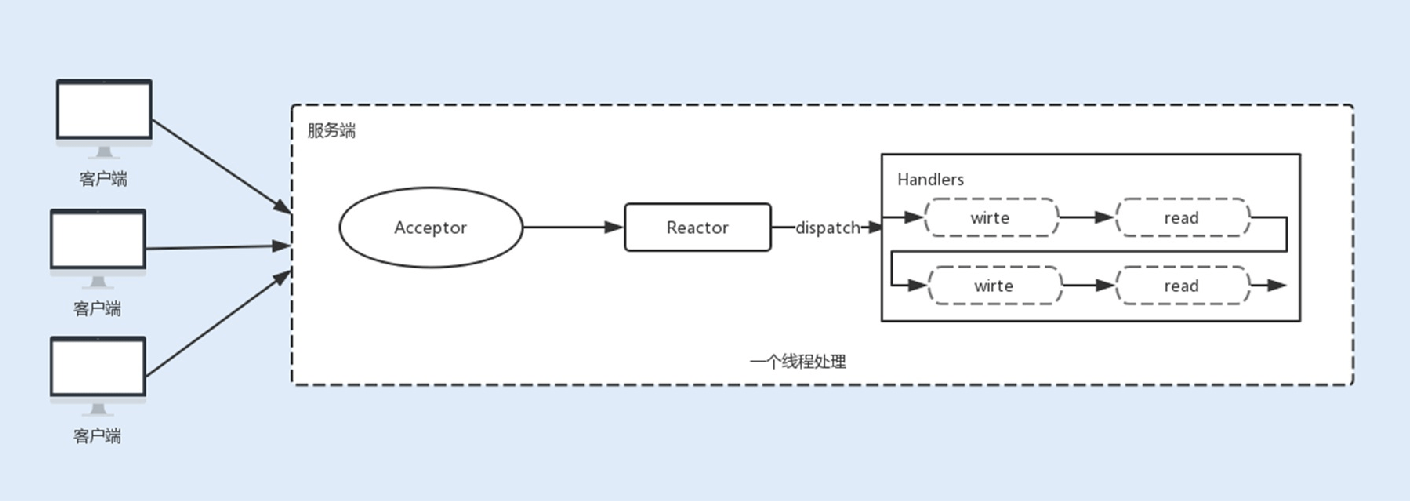
2.多线程Reactor线程模型
为了解决这种单线程的NIO在⾼负载、⾼并发场景下的性能瓶颈,后来使⽤了线程池。
在Tomcat和Netty中都使⽤了⼀个Acceptor线程来监听连接请求事件,当连接成功之后,会将建⽴的连接注册到多路复⽤器 中,⼀旦监听到事件,将交给Worker线程池来负责处理。⼤多数情况下,这种线程模型可以满⾜性能要求,但如果连接的客户端再上⼀个量级,⼀个Acceptor线程可能会存在性能瓶颈。
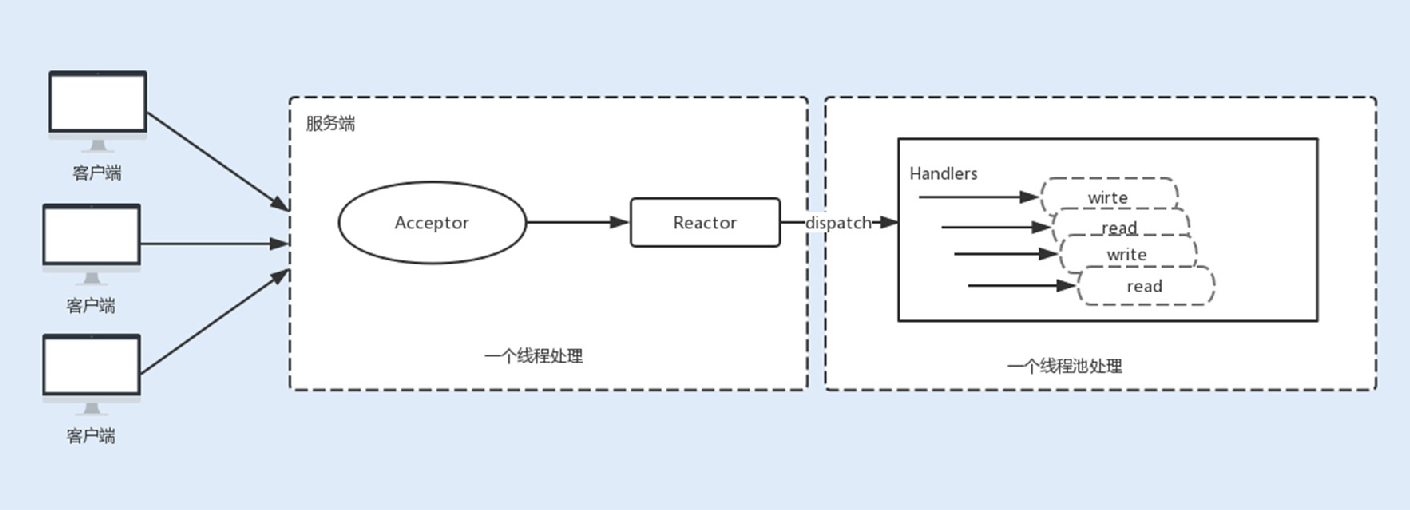
3.主从Reactor线程模型
现在主流通信框架中的NIO通信框架都是基于主从Reactor线程模型来实现的。在这个模型中,Acceptor不再是⼀个单独的NIO 线程,⽽是⼀个线程池。Acceptor接收到客户端的TCP连接请求,建⽴连接之后,后续的I/O操作将交给Worker I/O线程。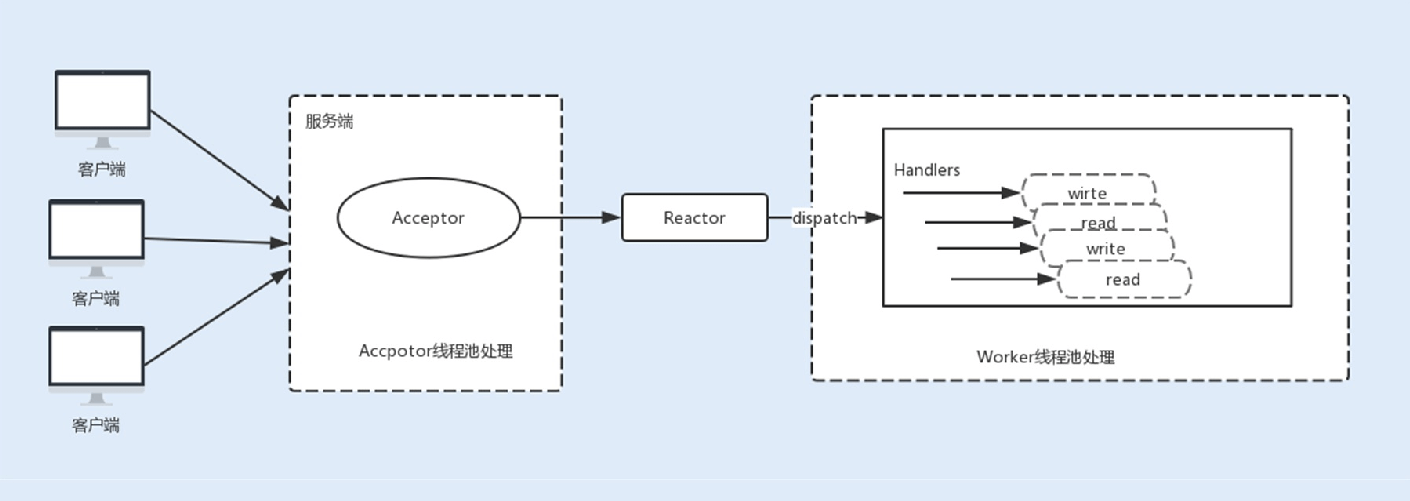
基于线程模型的Tomcat参数调优
Tomcat中,BIO、NIO是基于主从Reactor线程模型实现的。
在BIO中,Tomcat中的Acceptor只负责监听新的连接,⼀旦连接建⽴监听到I/O操作,将会交给Worker线程中,Worker线程专
⻔负责I/O读写操作。
在NIO中,Tomcat新增了⼀个Poller线程池,Acceptor监听到连接后,不是直接使⽤Worker中的线程处理请求,⽽是先将请求发送给了Poller缓冲队列。在Poller中,维护了⼀个Selector对象,当Poller从队列中取出连接后,注册到该Selector中;然后通过遍历Selector,找出其中就绪的I/O操作,并使⽤Worker中的线程处理相应的请求。
你可以通过以下⼏个参数来设置Acceptor线程池和Worker线程池的配置项。
acceptorThreadCount:该参数代表Acceptor的线程数量,在请求客户端的数据量⾮常巨⼤的情况下,可以适当地调⼤该线程数量来提⾼处理请求连接的能⼒,默认值为1。
maxThreads:专⻔处理I/O操作的Worker线程数量,默认是200,可以根据实际的环境来调整该参数,但不⼀定越⼤越好。
acceptCount:Tomcat的Acceptor线程是负责从accept队列中取出该connection,然后交给⼯作线程去执⾏相关操作,这⾥的
acceptCount指的是accept队列的⼤⼩。
当Http关闭keep alive,在并发量⽐较⼤时,可以适当地调⼤这个值。⽽在Http开启keep alive时,因为Worker线程数量有限,Worker线程就可能因⻓时间被占⽤,⽽连接在accept队列中等待超时。如果accept队列过⼤,就容易浪费连接。
maxConnections:表示有多少个socket连接到Tomcat上。在BIO模式中,⼀个线程只能处理⼀个连接,⼀般
maxConnections与maxThreads的值⼤⼩相同;在NIO模式中,⼀个线程同时处理多个连接,maxConnections应该设置得⽐
maxThreads要⼤的多,默认是10000。
今天的内容⽐较多,看到这⾥不知道你消化得如何?如果还有疑问,请在留⾔区中提出,我们共同探讨。最后欢迎你点击“请朋友读”,把今天的内容分享给身边的朋友,邀请他加⼊讨论。
精选留⾔ <br />QQ怪<br />⽼师这篇可以配合隔壁专栏tomcat的13,14章⼀起看,会更加有味道。<br />2019-06-13 08:30
 -W.LI-
-W.LI-
⽼师好对Reacktor的三种模式还是理解不太好。帮忙看看哪⾥有问题
单线程模型:⼀个selector同时监听accept,事件和read事件。检测到就在⼀个线程处理。
多线程模型:⼀个线程监听accept事件,创建channel注册到selector上,检听到Read等事件从线程池中获取线程处理。
主从模式:没看懂:-(,⼀个端⼝只能被⼀个serverSocketChannel监听,第⼆个好像会报错?这边的主从怎么理解啊
2019-06-14 08:57
作者回复
主从模式则是,Reactor主线程主要处理监听连接事件,⽽Reactor从线程主要监听I/O事件。这⾥是多线程处理accept事件,⽽不是创建多个ServerSocketChannel。
2019-06-16 10:07
 -W.LI-
-W.LI-
⽼师好!万分感觉,写的⾮常⾮常好谢谢。不过开⼼的同时,好多没看懂:-(先讲下我的理解吧。阻塞IO:调⽤read()线程阻塞了
⾮阻塞IO:调⽤read()⻢上拿到⼀个数据未就绪,或者就绪。
I/O多路复⽤:selector线程阻塞,channel⾮阻塞,⽤阻塞⼀个selector线程换了多个channel了⾮阻塞。select()函数基于数组,f
d个数限制1024,poll()函数也是基于数组但是fd数⽬⽆限制。都会负责所有的fd(未就绪的开销浪了),
epll()基于红⿊数实现,fd⽆⼤⼩限制,平衡⼆叉数插⼊删除效率⾼。
信号驱动模式IO:对IO多路复⽤进⼀步优化,selector也⾮阻塞了。但是sign信号⽆法区分多信号源。所以socket未使⽤这种, 只有在单⼀信号模型上才能应⽤。
异步IO模型:真正的⾮阻塞IO,其实前⾯的四种IO都不是真正的⾮阻塞IO,他们的⾮阻塞只是,从⽹络或者内存磁盘到内核空间的⾮阻塞,调⽤read()后还需要从内核拷⻉到⽤户空间。异步IO基于回调,这⼀步也⾮阻塞了,从内核拷⻉到⽤户空间后才通知⽤户进程。
能我是这么理解的前半断,有理解错的请⽼师指正谢谢。后半断没看完。
2019-06-13 13:28
作者回复
理解正确,赞⼀个
2019-06-14 10:26
 每天晒⽩⽛
每天晒⽩⽛
⽼师您在介绍Reactor线程模型的时候,关于多线程Reactor线程模型和主从Reactor线程模型,我有不同的理解。您画的多线程 模型,其中读写交给了线程池,我在看Doug Lea的 《Scalable in java》中画的图和代码示例,读写事件还是由Reactor线程处理,只把业务处理交给了线程池。主从模型也是同样的,Reactor主线程处理连接,Reactor从线程池处理读写事件,业务交给单独的线程池处理。
还望⽼师指点
2019-06-15 19:26
作者回复
你好,Reactor是⼀个模型,每个框架或者每个开发⼈员在处理I/O事件可能不⼀样,根据⾃⼰业务场景来处理。
Netty是基于Reactor主线程去监听连接, Reactor从线程池监听读写事件,同时如果监听到事件后直接在该从线程中操作读写I/
O,将业务交给单独的业务线程池,也可以不交给单独的线程池处理,直接在从线程池处理。不交给业务线程池的好处是,减少上下⽂切换,坏处是会造成线程阻塞。
所以根据⾃⼰的业务的特性,如果你的数据特别⼤,I/O读写操作放到handler线程池,,Reactor从线程数量有限,如果开⼤了
,由于开多个多路复⽤器也会带来性能消耗。所以这种处理也是⼀种提⾼系统吞吐量的优化。
2019-06-16 09:44
 ⾏者
⾏者
感谢⽼师分享,联想到Redis的单线程模式,Redis使⽤同⼀个线程来做selector,以及处理handler,这样的优点是减少上下⽂ 切换,不需要考虑并发问题;但是缺点也很明显,在IO数据量⼤的情况下,会导致QPS下降;这是由Redis选择IO模型决定的
。
2019-07-14 13:00
作者回复
对的,redis本身是操作内存,所以读取数据的效率会⾼很多。
2019-07-14 15:41
 余冲
余冲
⽼师能对reactor的⼏种模型,给⼀个简单版的代码例⼦看看吗。感觉通过代码应该能更好的理解理论。
2019-06-18 21:59
作者回复
好的,后⾯补上
2019-06-19 09:21
 kaixiao7
kaixiao7
⽼师,有两个疑惑还望您解答,谢谢
- ulimit -n 显示单个进程的⽂件句柄数为1024,但是启动⼀个socket服务(bio实现)后, cat /proc/
/limits 中显示的open files
为4096, 实际测试当socket连接数达到4000左右时就⽆法再连接了. 还请⽼师解答⼀下4096怎么来的, 为什么1024不⽣效呢?
- 您在⽂中提到epoll不受fd的限制. 但是我⽤NIO实现的服务端也是在连接到4000左右时⽆法再接收新的连接, 环境为Centos7( 虚拟机, 内核3.10, 除了系统之外, 没有跑其他程序), jdk1.8, ulimit -n 结果为1024, cat /proc/sys/fs/file-max 结果为382293. 按理说socket连接数最⼤可以达到38000左右, 代码如下:
public static void main(String[] args) throws IOException { ServerSocketChannel channel = ServerSocketChannel.open(); Selector selector = Selector.open();
channel.configureBlocking(false); channel.socket().bind(new InetSocketAddress(10301)); channel.register(selector, SelectionKey.OP_ACCEPT);
int size = 0;
while (true) {
if (selector.select() == 0) { continue;
}
Iterator
SelectionKey key = iterator.next(); iterator.remove();
if (key.isAcceptable()) { size++;
ServerSocketChannel server = (ServerSocketChannel) key.channel(); SocketChannel client = server.accept();
System.out.println(“当前客户端连接数: “ + size + “, “ + client.getRemoteAddress());
}
}
}
}
2019-07-11 13:59
 Geek_ebda96
Geek_ebda96
⽼师,请教⼀个问题,maxthreads这个参数在tomcat中是指只是单独处理I/o的读写线程数,还是读取完数据后,本身的业务层 处理也是在这个线程池⾥处理
2019-06-25 08:15 吾爱有三
吾爱有三
⽂章多次提到挂起会进⼊阻塞状态,然到挂起等价阻塞?不是吧
2019-06-18 19:49
作者回复
这⾥的挂起是⼀个动作,阻塞是⼀种状态。
2019-06-19 09:30
 趙衍
趙衍
I/O多路复⽤其实就相当于⽤了⼀个专⻔的线程来监听多个注册的事件,⽽之前的IO模型中,每⼀个事件都需要⼀个线程来监听
,不知道我这样理解的是否正确?⽼师我还有⼀个问题,就是当select监听到⼀个事件到来时,它是另起⼀个线程把数据从内核态拷⻉到⽤户态,还是⾃⼰就把这个事⼉给⼲了?
2019-06-17 09:38
作者回复
理解正确。select监听到事件之后就⽤当前线程把数据从内核态拷⻉到⽤户态。
2019-06-18 09:51
 z.l
z.l
⽼师,隔壁李号双⽼师的《深⼊拆解Tomcat & Jetty》中关于DirectByteBuffer的解释和您不⼀样,他的⽂章中DirectByteBuffer
的作⽤是:DirectByteBuffer 避免了 JVM 堆与本地内存直接的拷⻉,⽽并没有避免内存从内核空间到⽤户空间的拷⻉。⽽send
file 特性才是避免了内核与应⽤之间的内存拷⻉。请问哪种才是对的?
2019-06-16 22:25
作者回复
这⾥的本地内存应该指的是物理内存,避免堆内存和物理内存的拷⻉,其实就是避免内核空间和⽤户空间的拷⻉。
2019-06-17 10:01
 -W.LI-
-W.LI-
⽼师好!⼜看了⼀遍总结了下
epoll()⽅式的优点如下
1.⽆需⽤户空间到内核空间的fd拷⻉过程。
2.通过事件表,只返回就绪事件⽆需轮训遍历
3.基于红⿊树增删快。
4.事件发⽣后内核主动回调,⽤户进程wait状态(此时算阻塞还是⾮阻塞啊?)
内核也像观察者,(事件驱动的都像观察者) 还有别的优点么?
2019-06-15 07:00
作者回复
epoll是使⽤了wait⽅法阻塞等待事件,所以是阻塞的。
2019-06-16 10:01
 ⻄兹兹
⻄兹兹
刘⽼师,请问poller线程池 poller队列和⽂末提的acceptCount队列是不是⼀个队列?
2019-06-14 16:11
作者回复
不是的,这个acceptCount是Acceptor的线程数量,也就是Reactor主线程数量。
2019-06-16 10:02
 DemonLee
DemonLee
晕了,如果能结合点⽣活中的例⼦就更好了,我先去看看其他资料,再回来提问题。
2019-06-13 22:51
kim118000
acceptorThreadCount:该参数代表 Acceptor 的线程数量,在请求客户端的数据量⾮常巨⼤的情况下,可以适当地调⼤该线程数量来提⾼处理请求连接的能⼒,默认值为 1。
⽼师,我今天看了源码注释
doesn’t seem to work that well with mutiple acceptor threads
我之前的理解是Java还做不到多个接受连接来提⾼请求连接的处理能⼒,⽬前普遍的做法是通过fork多个⼦进程来达到同时监听同⼀个socket fd,但这样有惊群,所以利⽤mutex多个监听者只有⼀个能处理本次连接操作
⽬前还是⼀主多从⽅案,但这已经够⽤,可以通过多台机器提⾼并发。
2019-06-13 19:35 陆离
陆离
我所使⽤的Tomcat版本是9,默认的就是NIO,是不是版本不同默认模型也不同? directbuffer如果满了会阻塞还是会报错?这⼀块的⼤⼩设置是不是也可以优化?
directbuffer如果满了会阻塞还是会报错?这⼀块的⼤⼩设置是不是也可以优化?
因为Linux的aio这⼀块不成熟所以nio现在是主流?还是有其他原因?
2019-06-13 06:33
作者回复
是的,在Tomcat9版本改成了默认NIO。
在Linux系统上,AIO的底层实现仍使⽤EPOLL,没有很好实现AIO,因此在性能上没有明显的优势;
这个跟堆内存溢出是类似的道理,如果物理内存被分配完了就会出现溢出错误。NIO中的directbuffer是⽤来分配内存读取或写
⼊数据操作,如果数据⽐较⼤,⽽directbuffer分配⽐较下,则会分多次去读写,如果数据⽐较⼤的情况下可以适当调⼤提⾼效 率。
2019-06-14 10:23

若有收获,就点个赞吧
0 人点赞
