 05讲ArrayList还是LinkedList使⽤不当性能差千倍
05讲ArrayList还是LinkedList使⽤不当性能差千倍
你好,我是刘超。
 集合作为⼀种存储数据的容器,是我们⽇常开发中使⽤最频繁的对象类型之⼀。JDK为开发者提供了⼀系列的集合类型,这些集合类型使⽤不同的数据结构来实现。因此,不同的集合类型,使⽤场景也不同。
集合作为⼀种存储数据的容器,是我们⽇常开发中使⽤最频繁的对象类型之⼀。JDK为开发者提供了⼀系列的集合类型,这些集合类型使⽤不同的数据结构来实现。因此,不同的集合类型,使⽤场景也不同。
很多同学在⾯试的时候,经常会被问到集合的相关问题,⽐较常⻅的有ArrayList和LinkedList的区别。相信⼤部分同学都能回答上:“ArrayList是基于数组实现,LinkedList是基于链表实现。”
⽽在回答使⽤场景的时候,我发现⼤部分同学的答案是:“ArrayList和LinkedList在新增、删除元素时,LinkedList的效率要⾼于 ArrayList,⽽在遍历的时候,ArrayList的效率要⾼于LinkedList。”这个回答是否准确呢?今天这⼀讲就带你验证。
初识List接⼝
在学习List集合类之前,我们先来通过这张图,看下List集合类的接⼝和类的实现关系:
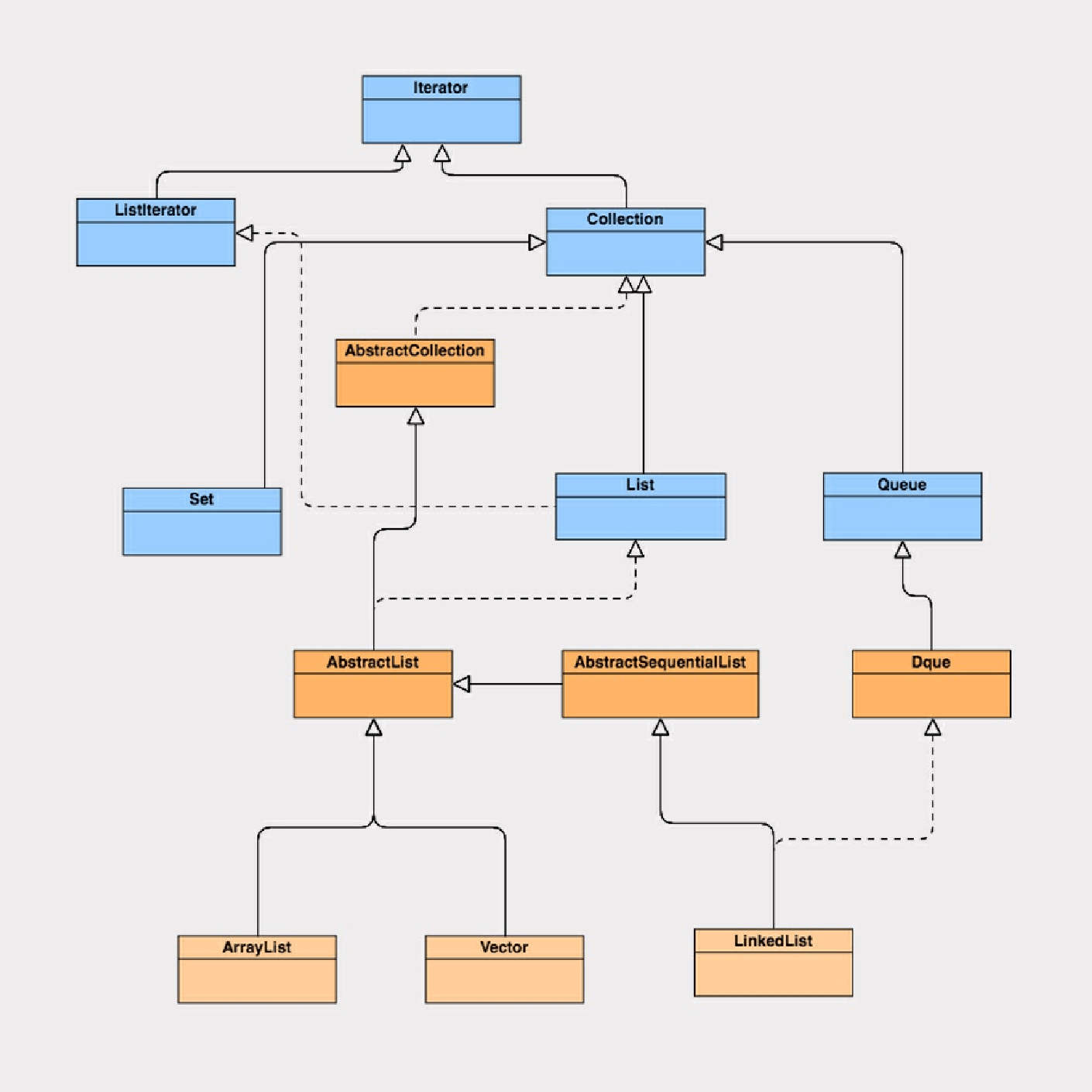
我们可以看到ArrayList、Vector、LinkedList集合类继承了AbstractList抽象类,⽽AbstractList实现了List接⼝,同时也继承了
AbstractCollection抽象类。ArrayList、Vector、LinkedList⼜根据⾃我定位,分别实现了各⾃的功能。
ArrayList和Vector使⽤了数组实现,这两者的实现原理差不多,LinkedList使⽤了双向链表实现。基础铺垫就到这⾥,接下来,我们就详细地分析下ArrayList和LinkedList的源码实现。
ArrayList是如何实现的?
ArrayList很常⽤,先来⼏道测试题,⾃检下你对ArrayList的了解程度。
问题1:我们在查看ArrayList的实现类源码时,你会发现对象数组elementData使⽤了transient修饰,我们知道transient关键字修饰该属性,则表示该属性不会被序列化,然⽽我们并没有看到⽂档中说明ArrayList不能被序列化,这是为什么?
问题2:我们在使⽤ArrayList进⾏新增、删除时,经常被提醒“使⽤ArrayList做新增删除操作会影响效率”。那是不是ArrayList在
⼤量新增元素的场景下效率就⼀定会变慢呢?
问题3:如果让你使⽤for循环以及迭代循环遍历⼀个ArrayList,你会使⽤哪种⽅式呢?原因是什么?
如果你对这⼏道测试都没有⼀个全⾯的了解,那就跟我⼀起从数据结构、实现原理以及源码⻆度重新认识下ArrayList吧。
ArrayList实现类
ArrayList实现了List接⼝,继承了AbstractList抽象类,底层是数组实现的,并且实现了⾃增扩容数组⼤⼩。
ArrayList还实现了Cloneable接⼝和Serializable接⼝,所以他可以实现克隆和序列化。
ArrayList还实现了RandomAccess接⼝。你可能对这个接⼝⽐较陌⽣,不知道具体的⽤处。通过代码我们可以发现,这个接⼝其实是⼀个空接⼝,什么也没有实现,那ArrayList为什么要去实现它呢?
其实RandomAccess接⼝是⼀个标志接⼝,他标志着“只要实现该接⼝的List类,都能实现快速随机访问”。
public class ArrayList
implements List
ArrayList属性
ArrayList属性主要由数组⻓度size、对象数组elementData、初始化容量default_capacity等组成, 其中初始化容量默认⼤⼩为
10。
//默认初始化容量
private static final int DEFAULT_CAPACITY = 10;
//对象数组
transient Object[] elementData;
//数组⻓度
private int size;
从ArrayList属性来看,它没有被任何的多线程关键字修饰,但elementData被关键字transient修饰了。这就是我在上⾯提到的第⼀道测试题:transient关键字修饰该字段则表示该属性不会被序列化,但ArrayList其实是实现了序列化接⼝,这到底是怎么回事呢?
这还得从“ArrayList是基于数组实现“开始说起,由于ArrayList的数组是基于动态扩增的,所以并不是所有被分配的内存空间都存储了数据。
如果采⽤外部序列化法实现数组的序列化,会序列化整个数组。ArrayList为了避免这些没有存储数据的内存空间被序列化,内部提供了两个私有⽅法writeObject以及readObject来⾃我完成序列化与反序列化,从⽽在序列化与反序列化数组时节省了空间和时间。
因此使⽤transient修饰数组,是防⽌对象数组被其他外部⽅法序列化。
ArrayList构造函数
ArrayList类实现了三个构造函数,第⼀个是创建ArrayList对象时,传⼊⼀个初始化值;第⼆个是默认创建⼀个空数组对象;第三个是传⼊⼀个集合类型进⾏初始化。
当ArrayList新增元素时,如果所存储的元素已经超过其已有⼤⼩,它会计算元素⼤⼩后再进⾏动态扩容,数组的扩容会导致整
个数组进⾏⼀次内存复制。因此,我们在初始化ArrayList时,可以通过第⼀个构造函数合理指定数组初始⼤⼩,这样有助于减少数组的扩容次数,从⽽提⾼系统性能。
public ArrayList(int initialCapacity) {
//初始化容量不为零时,将根据初始化值创建数组⼤⼩if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {//初始化容量为零时,使⽤默认的空数组this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException(“Illegal Capacity: “+
initialCapacity);
}
}
public ArrayList() {
//初始化默认为空数组
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
ArrayList新增元素
ArrayList新增元素的⽅法有两种,⼀种是直接将元素加到数组的末尾,另外⼀种是添加元素到任意位置。
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!! elementData[size++] = e;
return true;
}
public void add(int index, E element) { rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!! System.arraycopy(elementData, index, elementData, index + 1,
size - index); elementData[index] = element; size++;
}
两个⽅法的相同之处是在添加元素之前,都会先确认容量⼤⼩,如果容量够⼤,就不⽤进⾏扩容;如果容量不够⼤,就会按照原来数组的1.5倍⼤⼩进⾏扩容,在扩容之后需要将数组复制到新分配的内存地址。
private void ensureExplicitCapacity(int minCapacity) { modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0) grow(minCapacity);
}
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1); if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0) newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win: elementData = Arrays.copyOf(elementData, newCapacity);
}
当然,两个⽅法也有不同之处,添加元素到任意位置,会导致在该位置后的所有元素都需要重新排列,⽽将元素添加到数组的
末尾,在没有发⽣扩容的前提下,是不会有元素复制排序过程的。
这⾥你就可以找到第⼆道测试题的答案了。如果我们在初始化时就⽐较清楚存储数据的⼤⼩,就可以在ArrayList初始化时指定数组容量⼤⼩,并且在添加元素时,只在数组末尾添加元素,那么ArrayList在⼤量新增元素的场景下,性能并不会变差,反⽽
⽐其他List集合的性能要好。
ArrayList删除元素
ArrayList的删除⽅法和添加任意位置元素的⽅法是有些相同的。ArrayList在每⼀次有效的删除元素操作之后,都要进⾏数组的重组,并且删除的元素位置越靠前,数组重组的开销就越⼤。
public E remove(int index) { rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1; if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index, numMoved);
elementData[—size] = null; // clear to let GC do its work
return oldValue;
}
ArrayList遍历元素
由于ArrayList是基于数组实现的,所以在获取元素的时候是⾮常快捷的。
public E get(int index) { rangeCheck(index);
return elementData(index);
}
E elementData(int index) {
return (E) elementData[index];
}
LinkedList是如何实现的?
虽然LinkedList与ArrayList都是List类型的集合,但LinkedList的实现原理却和ArrayList⼤相径庭,使⽤场景也不太⼀样。
LinkedList是基于双向链表数据结构实现的,LinkedList定义了⼀个Node结构,Node结构中包含了3个部分:元素内容item、前指针prev以及后指针next,代码如下。
private static class Node
Node
Node(Node
this.next = next; this.prev = prev;
}
}
总结⼀下,LinkedList就是由Node结构对象连接⽽成的⼀个双向链表。在JDK1.7之前,LinkedList中只包含了⼀个Entry结构的
header属性,并在初始化的时候默认创建⼀个空的Entry,⽤来做header,前后指针指向⾃⼰,形成⼀个循环双向链表。
在JDK1.7之后,LinkedList做了很⼤的改动,对链表进⾏了优化。链表的Entry结构换成了Node,内部组成基本没有改变,但
LinkedList⾥⾯的header属性去掉了,新增了⼀个Node结构的first属性和⼀个Node结构的last属性。这样做有以下⼏点好处:
first/last属性能更清晰地表达链表的链头和链尾概念;
first/last⽅式可以在初始化LinkedList的时候节省new⼀个Entry;
first/last⽅式最重要的性能优化是链头和链尾的插⼊删除操作更加快捷了。
这⾥同ArrayList的讲解⼀样,我将从数据结构、实现原理以及源码分析等⼏个⻆度带你深⼊了解LinkedList。
LinkedList实现类
LinkedList类实现了List接⼝、Deque接⼝,同时继承了AbstractSequentialList抽象类,LinkedList既实现了List类型⼜有Queue
类型的特点;LinkedList也实现了Cloneable和Serializable接⼝,同ArrayList⼀样,可以实现克隆和序列化。
由于LinkedList存储数据的内存地址是不连续的,⽽是通过指针来定位不连续地址,因此,LinkedList不⽀持随机快速访问,LinkedList也就不能实现RandomAccess接⼝。
public class LinkedList
extends AbstractSequentialList
implements List
LinkedList属性
我们前⾯讲到了LinkedList的两个重要属性first/last属性,其实还有⼀个size属性。我们可以看到这三个属性都被transient修饰了,原因很简单,我们在序列化的时候不会只对头尾进⾏序列化,所以LinkedList也是⾃⾏实现readObject和writeObject进⾏序列化与反序列化。
transient int size = 0; transient Node
LinkedList新增元素
LinkedList添加元素的实现很简洁,但添加的⽅式却有很多种。默认的add (Ee)⽅法是将添加的元素加到队尾,⾸先是将last元素置换到临时变量中,⽣成⼀个新的Node节点对象,然后将last引⽤指向新节点对象,之前的last对象的前指针指向新节点对象。
public boolean add(E e) { linkLast(e); return true;
}
void linkLast(E e) {
final Node
final Node
if (l == null) first = newNode;
else
l.next = newNode; size++;
modCount++;
}
LinkedList也有添加元素到任意位置的⽅法,如果我们是将元素添加到任意两个元素的中间位置,添加元素操作只会改变前后元素的前后指针,指针将会指向添加的新元素,所以相⽐ArrayList的添加操作来说,LinkedList的性能优势明显。
public void add(int index, E element) { checkPositionIndex(index);
if (index == size) linkLast(element);
else
linkBefore(element, node(index));
}
void linkBefore(E e, Node
// assert succ != null;
final Node
final Node
if (pred == null) first = newNode;
else
pred.next = newNode; size++;
modCount++;
}
LinkedList删除元素
在LinkedList删除元素的操作中,我们⾸先要通过循环找到要删除的元素,如果要删除的位置处于List的前半段,就从前往后找;若其位置处于后半段,就从后往前找。
这样做的话,⽆论要删除较为靠前或较为靠后的元素都是⾮常⾼效的,但如果List拥有⼤量元素,移除的元素⼜在List的中间段,那效率相对来说会很低。
LinkedList遍历元素
LinkedList的获取元素操作实现跟LinkedList的删除元素操作基本类似,通过分前后半段来循环查找到对应的元素。但是通过这种⽅式来查询元素是⾮常低效的,特别是在for循环遍历的情况下,每⼀次循环都会去遍历半个List。
所以在LinkedList循环遍历时,我们可以使⽤iterator⽅式迭代循环,直接拿到我们的元素,⽽不需要通过循环查找List。
总结
前⾯我们已经从源码的实现⻆度深⼊了解了ArrayList和LinkedList的实现原理以及各⾃的特点。如果你能充分理解这些内容, 很多实际应⽤中的相关性能问题也就迎刃⽽解了。
就像如果现在还有⼈跟你说,“ArrayList和LinkedList在新增、删除元素时,LinkedList的效率要⾼于ArrayList,⽽在遍历的时候,ArrayList的效率要⾼于LinkedList”,你还会表示赞同吗?
现在我们不妨通过⼏组测试来验证⼀下。这⾥因为篇幅限制,所以我就直接给出测试结果了,对应的测试代码你可以访问Github查看和下载。
ArrayList和LinkedList新增元素操作测试
从集合头部位置新增元素
从集合中间位置新增元素从集合尾部位置新增元素
测试结果(花费时间):
ArrayList>LinkedList ArrayList
由于ArrayList是数组实现的,⽽数组是⼀块连续的内存空间,在添加元素到数组头部的时候,需要对头部以后的数据进⾏复制重排,所以效率很低;⽽LinkedList是基于链表实现,在添加元素的时候,⾸先会通过循环查找到添加元素的位置,如果要添 加的位置处于List的前半段,就从前往后找;若其位置处于后半段,就从后往前找。因此LinkedList添加元素到头部是⾮常⾼效的。
同上可知,ArrayList在添加元素到数组中间时,同样有部分数据需要复制重排,效率也不是很⾼;LinkedList将元素添加到中间位置,是添加元素最低效率的,因为靠近中间位置,在添加元素之前的循环查找是遍历元素最多的操作。
⽽在添加元素到尾部的操作中,我们发现,在没有扩容的情况下,ArrayList的效率要⾼于LinkedList。这是因为ArrayList在添 加元素到尾部的时候,不需要复制重排数据,效率⾮常⾼。⽽LinkedList虽然也不⽤循环查找元素,但LinkedList中多了new对象以及变换指针指向对象的过程,所以效率要低于ArrayList。
说明⼀下,这⾥我是基于ArrayList初始化容量⾜够,排除动态扩容数组容量的情况下进⾏的测试,如果有动态扩容的情况,ArrayList的效率也会降低。
ArrayList和LinkedList删除元素操作测试
从集合头部位置删除元素
从集合中间位置删除元素从集合尾部位置删除元素
测试结果(花费时间):
ArrayList>LinkedList ArrayList
ArrayList和LinkedList遍历元素操作测试
for(;;)循环
迭代器迭代循环
测试结果(花费时间):
ArrayList
这是因为LinkedList基于链表实现的,在使⽤for循环的时候,每⼀次for循环都会去遍历半个List,所以严重影响了遍历的效
率;ArrayList则是基于数组实现的,并且实现了RandomAccess接⼝标志,意味着ArrayList可以实现快速随机访问,所以for循环效率⾮常⾼。
LinkedList的迭代循环遍历和ArrayList的迭代循环遍历性能相当,也不会太差,所以在遍历LinkedList时,我们要切忌使⽤for
循环遍历。
思考题
我们通过⼀个使⽤for循环遍历删除操作ArrayList数组的例⼦,思考下ArrayList数组的删除操作应该注意的⼀些问题。
public static void main(String[] args)
{
ArrayList
list.add(“a”);
list.add(“b”);
list.add(“b”);
list.add(“c”);
list.add(“c”);
remove(list);//删除指定的“b”元素
for(int i=0; i
System.out.println(“element : “ + s)list.get(i)
}
}
从上⾯的代码来看,我定义了⼀个ArrayList数组,⾥⾯添加了⼀些元素,然后我通过remove删除指定的元素。请问以下两种写法,哪种是正确的?
写法1:
public static void remove(ArrayList
{
Iterator
while (it.hasNext()) { String str = it.next();
if (str.equals(“b”)) { it.remove();
}
}
}
写法2:
public static void remove(ArrayList
{
for (String s : list)
{
if (s.equals(“b”))
{
list.remove(s);
}
}
}
期待在留⾔区看到你的答案。也欢迎你点击“请朋友读”,把今天的内容分享给身边的朋友,邀请他⼀起学习。

精选留⾔ <br />陆离<br />对于arraylist和linkedlist的性能以前⼀直都是⼈云亦云,⼤家都说是这样那就这样吧,我也从来没有⾃⼰去验证过,没想过因操 作位置的不同差异还挺⼤。<br />当然这⾥⾯有⼀个前提,那就是arraylist的初始⼤⼩要⾜够⼤。<br />思考题是第⼀个是正确的,第⼆个虽然⽤的是foreach语法糖,遍历的时候⽤的也是迭代器遍历,但是在remove操作时使⽤的是原始数组list的remove,⽽不是迭代器的remove。<br />这样就会造成modCound != exceptedModeCount,进⽽抛出异常。<br />2019-05-30 05:15<br />作者回复<br />陆离同学⼀直保持⾮常稳定的发挥,答案⾮常准确!<br />2019-05-30 22:24
 刘天若Warner
刘天若Warner
⽼师,为什么第⼆种就会抛出ConcurrentModificationException异常呢,我觉得第⼀种迭代器会抛这个异常啊
2019-05-30 18:36
作者回复
for(:)循环[这⾥指的不是for(;;)]是⼀个语法糖,这⾥会被解释为迭代器,在使⽤迭代器遍历时,ArrayList内部创建了⼀个内部迭代器iterator,在使⽤next()⽅法来取下⼀个元素时,会使⽤ArrayList⾥保存的⼀个⽤来记录List修改次数的变量modCount,与it
erator保存了⼀个expectedModCount来表示期望的修改次数进⾏⽐较,如果不相等则会抛出异常;
⽽在在foreach循环中调⽤list中的remove()⽅法,会⾛到fastRemove()⽅法,该⽅法不是iterator中的⽅法,⽽是ArrayList中的
⽅法,在该⽅法只做了modCount++,⽽没有同步到expectedModCount。
当再次遍历时,会先调⽤内部类iteator中的hasNext(),再调⽤next(),在调⽤next()⽅法时,会对modCount和expectedModCount 进⾏⽐较,此时两者不⼀致,就抛出了ConcurrentModificationException异常。
所以关键是⽤ArrayList的remove还是iterator中的remove。
2019-05-30 22:17
 ⽪⽪
⽪⽪
第⼀种写法正确,第⼆种会报错,原因是上述两种写法都有⽤到list内部迭代器Iterator,⽽在迭代器内部有⼀个属性是excepted
modcount,每次调⽤next和remove⽅法时会检查该值和list内部的modcount是否⼀致,不⼀致会报异常。问题中的第⼆种写法
remove(e),会在每次调⽤时modcount++,虽然迭代器的remove⽅法也会调⽤list的这个remove(e)⽅法,但每次调⽤后 还有⼀个exceptedmodcount=modcount操作,所以后续调⽤next时判断就不会报异常了。
2019-05-30 13:03
作者回复
关键在⽤谁的remove⽅法。
2019-05-30 22:23
 建国
建国
⽼师,您好,linkList查找元素通过分前后半段,每次查找都要遍历半个list,怎么就知道元素是出于前半段还是后半段的呢?
2019-06-10 22:10
作者回复
这个是随机的,因为分配的内存地址不是连续的。
2019-06-13 09:44
 业余草
业余草
请问:List list = new ArrayList<>(); for(int i=0;i++;i<1000){
A a = new A(); list.add(a);
}
和
和 这个 List list = new ArrayList<>(); A a;
for(int i=0;i++;i<1000){ a = new A();
list.add(a);
}
效率上有差别吗?不说new ArrayList<>(); 初始化问题。单纯说创建对象这⼀块。谢谢!
2019-05-31 11:51
作者回复
没啥区别的,可以实际操作试试
2019-05-31 20:57
 计科⼀班
计科⼀班
写法⼀正确。
虽然都是调⽤了remove⽅法,但是两个remove⽅法是不同的。 写法⼆是有可能会报ConcurrentModificationException异常。
所以在ArrayList遍历删除元素时使⽤iterator⽅式或者普通的for循环。
2019-05-30 13:27
作者回复
对的,使⽤普通循环也需要注意。
2019-05-30 22:22
 mickle
mickle
第⼆种不⾏吧,会报并发修改异常的
2019-05-30 10:31 ⽼杨同志
⽼杨同志
写法⼀正确,写法⼆会快速失败
2019-05-30 07:40
 Loubobooo
Loubobooo
这⼀道我会。如果有看过阿⾥java规约就知道,在集合中进⾏remove操作时,不要在 foreach 循环⾥进⾏元素的 remove/add
操作。remove 元素请使⽤ Iterator⽅式,如果并发操作,需要对 Iterator 对象加锁。
2019-06-01 10:49
作者回复
2019-06-01 21:06
 晓杰
晓杰
写法2不正确,使⽤for循环遍历元素的过程中,如果删除元素,由于modCount != expectedModCount,会抛出
ConcurrentModificationException异常
2019-05-30 15:48
作者回复
对的!
2019-05-30 22:19
 每天晒⽩⽛
每天晒⽩⽛
需要⽤迭代器⽅式删除
for循环遍历删除会抛并发修改异常
2019-05-30 06:17
作者回复
是的,不要使⽤迭代器循环时⽤ArrayList的remove⽅法,具体分析可以看留⾔区。
2019-05-30 22:29
 涛哥
涛哥
arrayList,for循环访问快是因为内存连续,可以整个缓存⾏读取进cpu缓存中,遍历下个的时候⽆需去内存中获取。并不是实现什么随机获取接⼝
2019-07-17 14:41
作者回复
是的,是因为连续内存。在代码中,程序是不知道底层开辟的内存情况,所以需要⼀个类似序列化的接⼝标志,这个接⼝仅仅是⼀个标志,并不是实现。
2019-07-18 11:48
 刘浩
刘浩
⽼师,您好。LinkedList 中 Node 是私有的静态内部类,除了防⽌内存泄露吗?还有其他的设计考虑吗?
2019-07-16 23:12 我戒酒了
我戒酒了
ArrayListTest 的这个测试⽅法笔误写错了吧
public static void addFromMidTest(int DataNum) { ArrayList
long timeStart = System.currentTimeMillis(); while (i < DataNum) {
int temp = list.size();
list.add(temp/2+”aaavvv”); //正确写法list.add(temp/2, +”aaavvv”); i++;
}
long timeEnd = System.currentTimeMillis();
System.out.println(“ArrayList从集合中间位置新增元素花费的时间” + (timeEnd - timeStart));
}
2019-07-02 20:24
作者回复
对的,感谢细⼼的你提醒
2019-07-07 10:21
吃胖了再减肥再吃再健身之谜之不瘦
⽼师,我⽤的测试代码试了好多次,在“从集合尾部位置新增元素”这个场景下,我测试的结果是“ArrayList>LinkedList”,你代码
⾥⾯的1000000,⼀百万次遍历时,会有少量的情况出现“ArrayList
ArrayList从集合尾部位置新增元素花费的时间4690
LinkedList从集合尾部位置新增元素花费的时间2942
第⼆次:
ArrayList从集合尾部位置新增元素花费的时间4655
LinkedList从集合尾部位置新增元素花费的时间2798
第三次:
ArrayList从集合尾部位置新增元素花费的时间5126
LinkedList从集合尾部位置新增元素花费的时间2960
从这个场景看来,⼤数据量遍历的情况下,LinkedList新增数据⽐较快,不知道我这个验证的结果是否正确,期待⽼师指教, 谢谢!
2019-07-02 11:51
作者回复
⽼师没有在查询时同时新增测试,考虑的只是单个场景下的测试。ArrayList新增需要固定⼀个初始化⼤⼩,如果默认初始化⼤
⼩,则会在新增时出现扩容的情况,这样性能反⽽会降低。
2019-07-07 10:24
 ⽆忧
⽆忧
⽼师,你好。ArrayList删除元素时将对应位置元素设置为null。代码注释说GC会回收,请问回收是什么时候触发呢。 如果元素为空就会被回收的话,AreayList在扩容时未使⽤的数组部分会不会也是空的被回收呢?
public E remove(int index) { rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1; if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index, numMoved);
elementData[—size] = null; // clear to let GC do its work
return oldValue;
}
2019-06-20 21:08 ⽆忧
⽆忧
⽼师你好。ArrayLists删除元素时public E remove(int index) { rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1; if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index, numMoved);
elementData[—size] = null; // clear to let GC do its work
return oldValue;
}
2019-06-20 21:02 码德纽@宝
码德纽@宝
我个⼈感觉arraylist和linkedlist性能最⼤的区别在于arraylist需要重新组排和扩容的开销。
2019-06-19 16:54
gavin
⽼师好,怎么确定操作集合是从头部、中间、还是尾部操作的呢?
2019-06-11 08:45
作者回复
arraylist的add⽅法默认是从尾部操作,delete⽅法就是根据⾃⼰指定的位置来删除;linkedlist的add⽅法也是默认从尾部插⼊元素,delete⽅法也是根据指定的元素来删除。
2019-06-13 09:33
 源码粘贴不完。⼤概描述⼀下
源码粘贴不完。⼤概描述⼀下
⽅法1 最后是通过调⽤迭代器remove(int index),是直接删除对应下标的元素。
⽅法2 最终是 如果b存在,那么调⽤list的remove(Object o),list的remove是删除指定对象equlse为true的第⼀个元素。
⽅法2 其实是转换为迭代器遍历,迭代器遍历的过程中使⽤了list的删除,导致迭代器下标越界。顺便说下,⾃认为还有⽅法3
public static void remove3(ArrayList
}
}
这种⽅式删除元素 好像也是可以的。
2019-06-10 12:49

若有收获,就点个赞吧
0 人点赞
