 04讲慎重使⽤正则表达式
04讲慎重使⽤正则表达式
你好,我是刘超。
 上⼀讲,我在讲String对象优化时,提到了Split()⽅法,该⽅法使⽤的正则表达式可能引起回溯问题,今天我们就来深⼊了解下,这究竟是怎么回事?
上⼀讲,我在讲String对象优化时,提到了Split()⽅法,该⽅法使⽤的正则表达式可能引起回溯问题,今天我们就来深⼊了解下,这究竟是怎么回事?
开始之前,我们先来看⼀个案例,可以帮助你更好地理解内容。
在⼀次⼩型项⽬开发中,我遇到过这样⼀个问题。为了宣传新品,我们开发了⼀个⼩程序,按照之前评估的访问量,这次活动预计参与⽤户量30W+,TPS(每秒事务处理量)最⾼3000左右。
这个结果来⾃我对接⼝做的微基准性能测试。我习惯使⽤ab⼯具(通过yum -y install httpd-tools可以快速安装)在另⼀台机器上对http请求接⼝进⾏测试。
我可以通过设置-n请求数/-c并发⽤户数来模拟线上的峰值请求,再通过TPS、RT(每秒响应时间)以及每秒请求时间分布情况这三个指标来衡量接⼝的性能,如下图所示(图中隐藏部分为我的服务器地址):
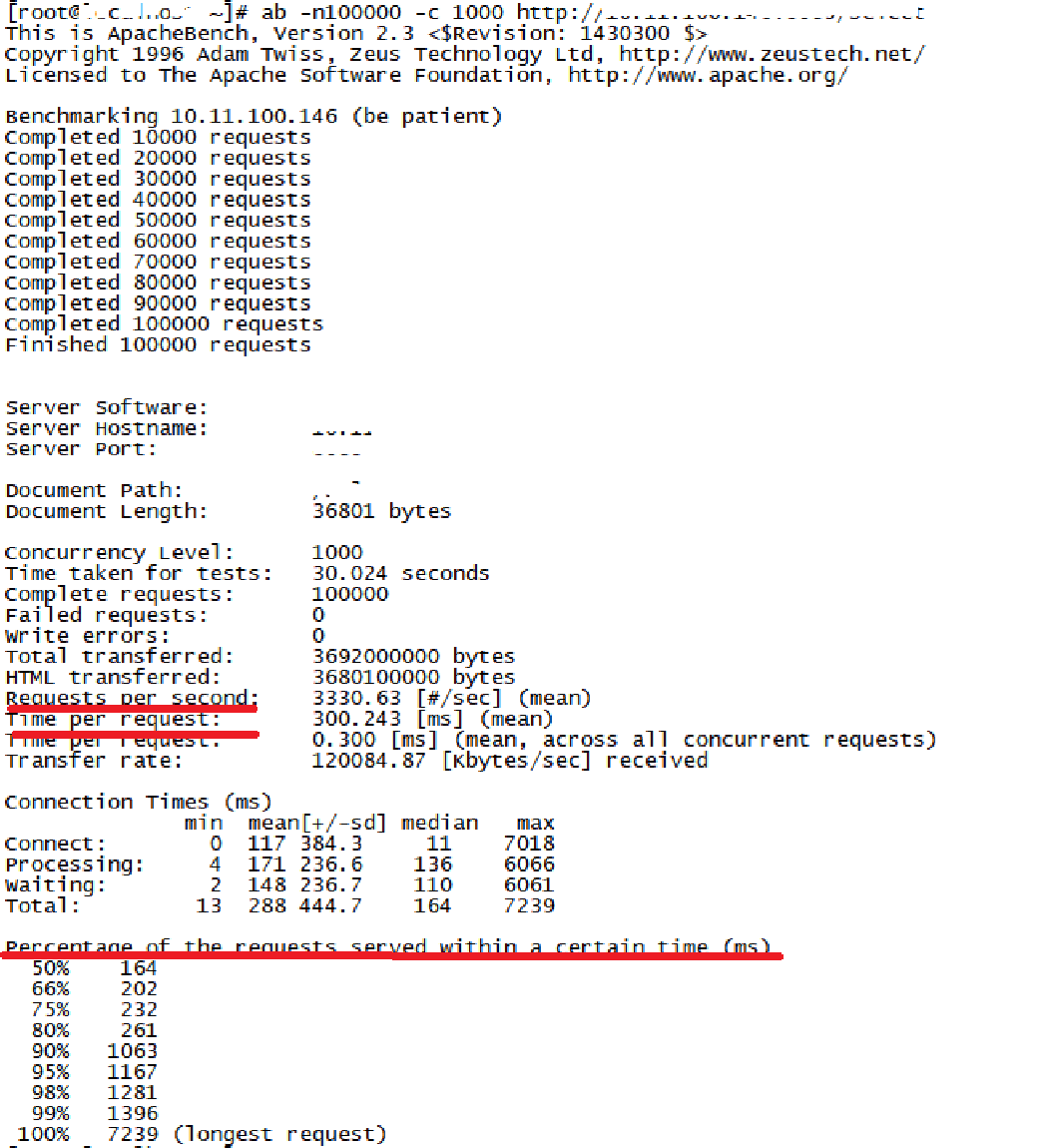
就在做性能测试的时候,我发现有⼀个提交接⼝的TPS⼀直上不去,按理说这个业务⾮常简单,存在性能瓶颈的可能性并不
⼤。
我迅速使⽤了排除法查找问题。⾸先将⽅法⾥⾯的业务代码全部注释,留⼀个空⽅法在这⾥,再看性能如何。这种⽅式能够很好地区分是框架性能问题,还是业务代码性能问题。
我快速定位到了是业务代码问题,就⻢上逐⼀查看代码查找原因。我将插⼊数据库操作代码加上之后,TPS稍微下降了,但还是没有找到原因。最后,就只剩下Split() ⽅法操作了,果然,我将Split()⽅法加⼊之后,TPS明显下降了。
可是⼀个Split()⽅法为什么会影响到TPS呢?下⾯我们就来了解下正则表达式的相关内容,学完了答案也就出来了。
什么是正则表达式?
很基础,这⾥带你简单回顾⼀下。
正则表达式是计算机科学的⼀个概念,很多语⾔都实现了它。正则表达式使⽤⼀些特定的元字符来检索、匹配以及替换符合规则的字符串。
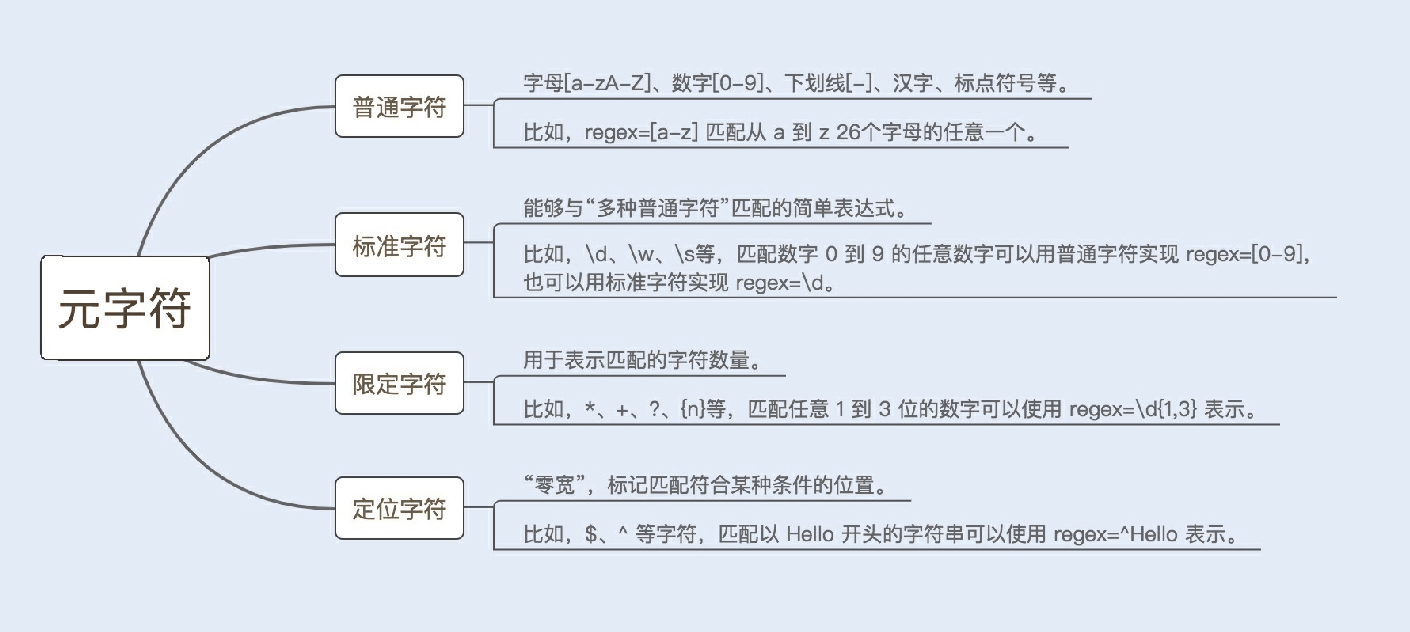
构造正则表达式语法的元字符,由普通字符、标准字符、限定字符(量词)、定位字符(边界字符)组成。详情可⻅下图:
正则表达式引擎
正则表达式是⼀个⽤正则符号写出的公式,程序对这个公式进⾏语法分析,建⽴⼀个语法分析树,再根据这个分析树结合正则表达式的引擎⽣成执⾏程序(这个执⾏程序我们把它称作状态机,也叫状态⾃动机),⽤于字符匹配。
⽽这⾥的正则表达式引擎就是⼀套核⼼算法,⽤于建⽴状态机。
⽬前实现正则表达式引擎的⽅式有两种:DFA⾃动机(Deterministic Final Automata 确定有限状态⾃动机)和NFA⾃动机
(Non deterministic Finite Automaton ⾮确定有限状态⾃动机)。
对⽐来看,构造DFA⾃动机的代价远⼤于NFA⾃动机,但DFA⾃动机的执⾏效率⾼于NFA⾃动机。
假设⼀个字符串的⻓度是n,如果⽤DFA⾃动机作为正则表达式引擎,则匹配的时间复杂度为O(n);如果⽤NFA⾃动机作为正则表达式引擎,由于NFA⾃动机在匹配过程中存在⼤量的分⽀和回溯,假设NFA的状态数为s,则该匹配算法的时间复杂度为
O(ns)。
NFA⾃动机的优势是⽀持更多功能。例如,捕获group、环视、占有优先量词等⾼级功能。这些功能都是基于⼦表达式独⽴进
⾏匹配,因此在编程语⾔⾥,使⽤的正则表达式库都是基于NFA实现的。
那么NFA⾃动机到底是怎么进⾏匹配的呢?我以下⾯的字符和表达式来举例说明。
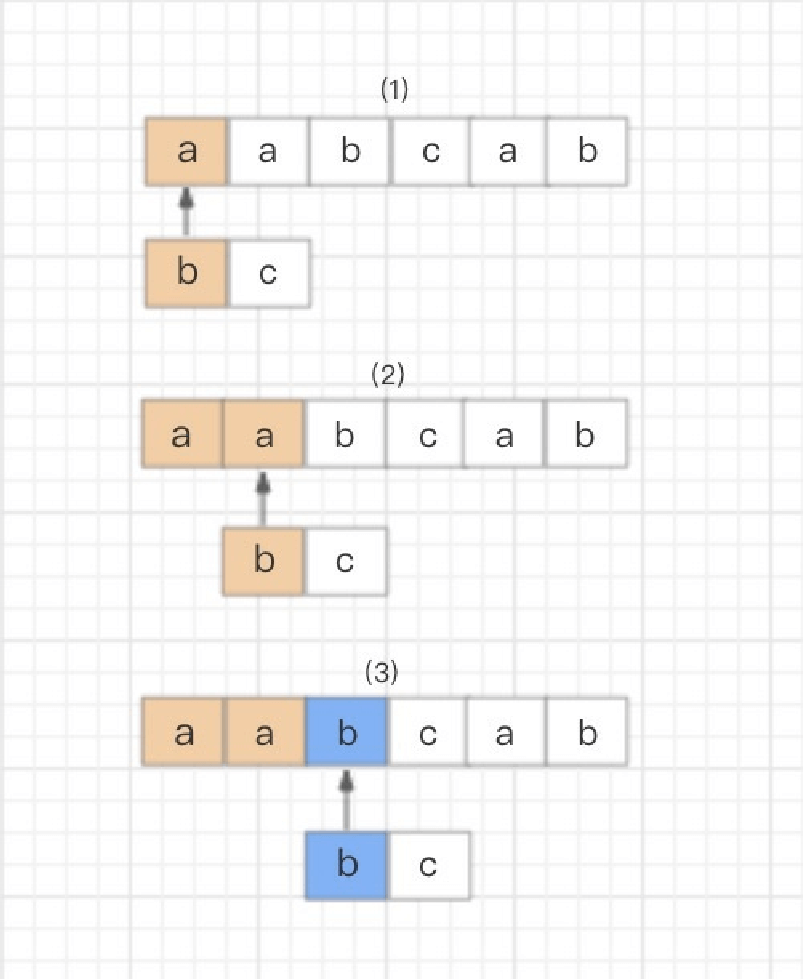
text=“aabcab” regex=“bc”
NFA⾃动机会读取正则表达式的每⼀个字符,拿去和⽬标字符串匹配,匹配成功就换正则表达式的下⼀个字符,反之就继续和
⽬标字符串的下⼀个字符进⾏匹配。分解⼀下过程。
⾸先,读取正则表达式的第⼀个匹配符和字符串的第⼀个字符进⾏⽐较,b对a,不匹配;继续换字符串的下⼀个字符,也是
a,不匹配;继续换下⼀个,是b,匹配。
然后,同理,读取正则表达式的第⼆个匹配符和字符串的第四个字符进⾏⽐较,c对c,匹配;继续读取正则表达式的下⼀个字
符,然⽽后⾯已经没有可匹配的字符了,结束。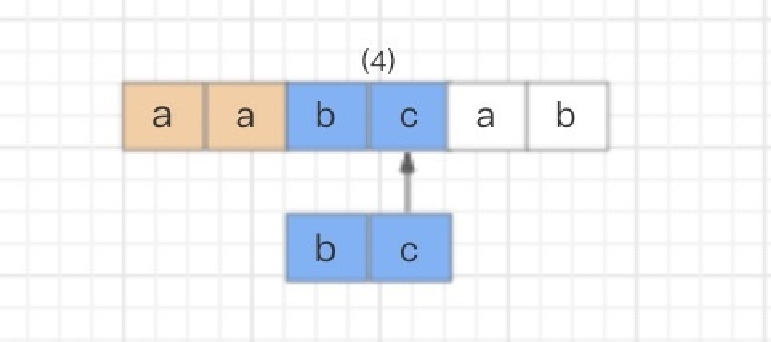
这就是NFA⾃动机的匹配过程,虽然在实际应⽤中,碰到的正则表达式都要⽐这复杂,但匹配⽅法是⼀样的。
NFA⾃动机的回溯
⽤NFA⾃动机实现的⽐较复杂的正则表达式,在匹配过程中经常会引起回溯问题。⼤量的回溯会⻓时间地占⽤CPU,从⽽带来系统性能开销。我来举例说明。
text=“abbc” regex=“ab{1,3}c”
这个例⼦,匹配⽬的⽐较简单。匹配以a开头,以c结尾,中间有1-3个b字符的字符串。NFA⾃动机对其解析的过程是这样的:
⾸先,读取正则表达式第⼀个匹配符a和字符串第⼀个字符a进⾏⽐较,a对a,匹配。
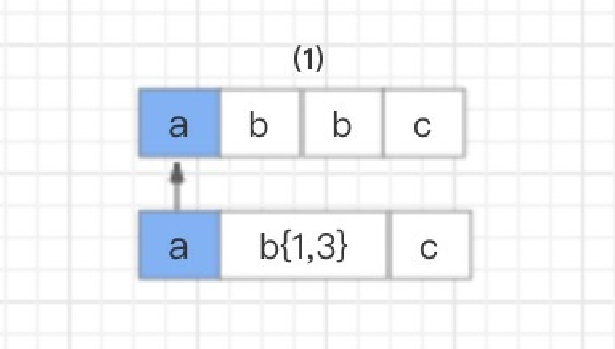
然后,读取正则表达式第⼆个匹配符b{1,3} 和字符串的第⼆个字符b进⾏⽐较,匹配。但因为 b{1,3} 表示1-3个b字符串,NFA
⾃动机⼜具有贪婪特性,所以此时不会继续读取正则表达式的下⼀个匹配符,⽽是依旧使⽤ b{1,3} 和字符串的第三个字符b进
⾏⽐较,结果还是匹配。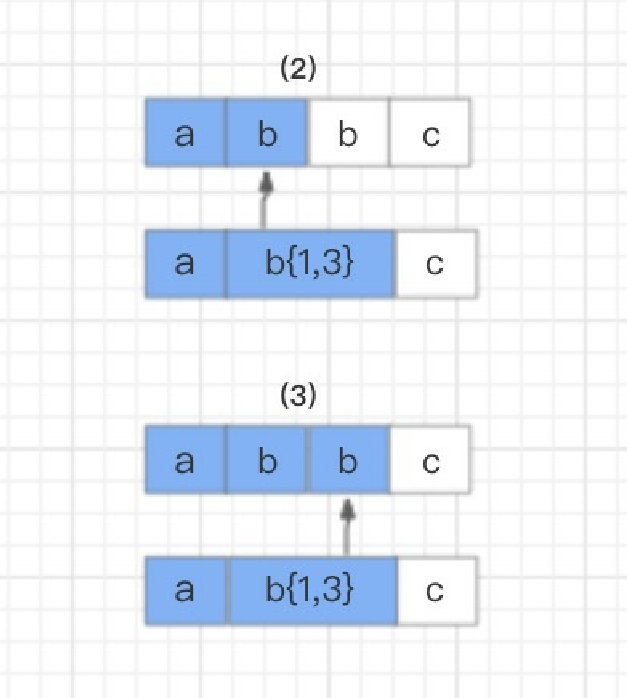
接着继续使⽤b{1,3} 和字符串的第四个字符c进⾏⽐较,发现不匹配了,此时就会发⽣回溯,已经读取的字符串第四个字符c将被吐出去,指针回到第三个字符b的位置。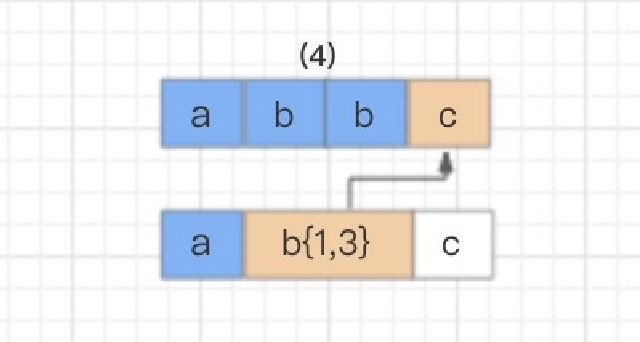
那么发⽣回溯以后,匹配过程怎么继续呢?程序会读取正则表达式的下⼀个匹配符c,和字符串中的第四个字符c进⾏⽐较,结果匹配,结束。
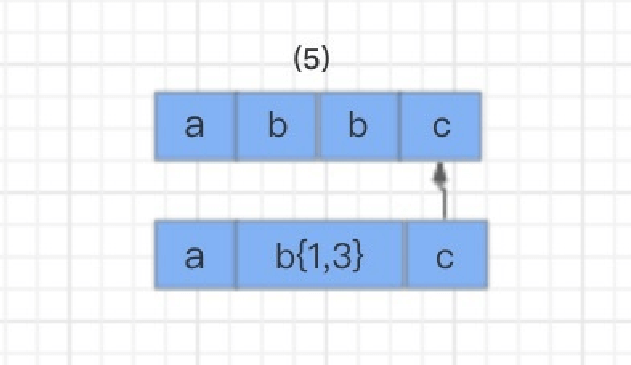
如何避免回溯问题?
既然回溯会给系统带来性能开销,那我们如何应对呢?如果你有仔细看上⾯那个案例的话,你会发现NFA⾃动机的贪婪特性就是导⽕索,这和正则表达式的匹配模式息息相关,⼀起来了解⼀下。
1.贪婪模式(Greedy)
顾名思义,就是在数量匹配中,如果单独使⽤+、 ? 、* 或{min,max} 等量词,正则表达式会匹配尽可能多的内容。例如,上边那个例⼦:
text=“abbc” regex=“ab{1,3}c”
就是在贪婪模式下,NFA⾃动机读取了最⼤的匹配范围,即匹配3个b字符。匹配发⽣了⼀次失败,就引起了⼀次回溯。如果匹配结果是“abbbc”,就会匹配成功。
2.懒惰模式(Reluctant)
在该模式下,正则表达式会尽可能少地重复匹配字符。如果匹配成功,它会继续匹配剩余的字符串。例如,在上⾯例⼦的字符后⾯加⼀个“?”,就可以开启懒惰模式。
text=“abc” regex=“ab{1,3}?c”
匹配结果是“abc”,该模式下NFA⾃动机⾸先选择最⼩的匹配范围,即匹配1个b字符,因此就避免了回溯问题。
3.独占模式(Possessive)
同贪婪模式⼀样,独占模式⼀样会最⼤限度地匹配更多内容;不同的是,在独占模式下,匹配失败就会结束匹配,不会发⽣回溯问题。
还是上边的例⼦,在字符后⾯加⼀个“+”,就可以开启独占模式。
text=“abbc” regex=“ab{1,3}+bc”
结果是不匹配,结束匹配,不会发⽣回溯问题。讲到这⾥,你应该⾮常清楚了,避免回溯的⽅法就是:使⽤懒惰模式和独占模式。
还有开头那道“⼀个split()⽅法为什么会影响到TPS”的存疑,你应该也清楚了吧?
我使⽤了split()⽅法提取域名,并检查请求参数是否符合规定。split()在匹配分组时遇到特殊字符产⽣了⼤量回溯,我当时是在正则表达式后加了⼀个需要匹配的字符和“+”,解决了这个问题。
\?(([A-Za-z0-9-~_=%]++\&{0,1})+)
正则表达式的优化
正则表达式带来的性能问题,给我敲了个警钟,在这⾥我也希望分享给你⼀些⼼得。任何⼀个细节问题,都有可能导致性能问题,⽽这背后折射出来的是我们对这项技术的了解不够透彻。所以我⿎励你学习性能调优,要掌握⽅法论,学会透过现象看本质。下⾯我就总结⼏种正则表达式的优化⽅法给你。
1.少⽤贪婪模式,多⽤独占模式
贪婪模式会引起回溯问题,我们可以使⽤独占模式来避免回溯。前⾯详解过了,这⾥我就不再解释了。
2.减少分⽀选择
分⽀选择类型“(X|Y|Z)”的正则表达式会降低性能,我们在开发的时候要尽量减少使⽤。如果⼀定要⽤,我们可以通过以下⼏种
⽅式来优化:
⾸先,我们需要考虑选择的顺序,将⽐较常⽤的选择项放在前⾯,使它们可以较快地被匹配;
其次,我们可以尝试提取共⽤模式,例如,将“(abcd|abef)”替换为“ab(cd|ef)”,后者匹配速度较快,因为NFA⾃动机会尝试匹配ab,如果没有找到,就不会再尝试任何选项;
最后,如果是简单的分⽀选择类型,我们可以⽤三次index代替“(X|Y|Z)”,如果测试的话,你就会发现三次index的效率要
⽐“(X|Y|Z)”⾼出⼀些。
3.减少捕获嵌套
在讲这个⽅法之前,我先简单介绍下什么是捕获组和⾮捕获组。
捕获组是指把正则表达式中,⼦表达式匹配的内容保存到以数字编号或显式命名的数组中,⽅便后⾯引⽤。⼀般⼀个()就是⼀个捕获组,捕获组可以进⾏嵌套。
⾮捕获组则是指参与匹配却不进⾏分组编号的捕获组,其表达式⼀般由(?:exp)组成。
在正则表达式中,每个捕获组都有⼀个编号,编号0代表整个匹配到的内容。我们可以看下⾯的例⼦:
public static void main( String[] args )
{
String text = “test“; String reg=”(
Pattern p = Pattern.compile(reg); Matcher m = p.matcher(text); while(m.find()) {
System.out.println(m.group(0));//整个匹配到的内容
System.out.println(m.group(1));//(<input.?>) System.out.println(m.group(2));//(.*?) System.out.println(m.group(3));//()
}
}
运⾏结果:
test
test
如果你并不需要获取某⼀个分组内的⽂本,那么就使⽤⾮捕获分组。例如,使⽤“(?:X)”代替“(X)”,我们再看下⾯的例⼦:
public static void main( String[] args )
{
String text = “test“; String reg=”(?:
Pattern p = Pattern.compile(reg); Matcher m = p.matcher(text); while(m.find()) {
System.out.println(m.group(0));//整个匹配到的内容
System.out.println(m.group(1));//(.?)
}
}
运⾏结果:
test test
综上可知:减少不需要获取的分组,可以提⾼正则表达式的性能。
总结
正则表达式虽然⼩,却有着强⼤的匹配功能。我们经常⽤到它,⽐如,注册⻚⾯⼿机号或邮箱的校验。
但很多时候,我们⼜会因为它⼩⽽忽略它的使⽤规则,测试⽤例中⼜没有覆盖到⼀些特殊⽤例,不乏上线就中招的情况发⽣。
综合我以往的经验来看,如果使⽤正则表达式能使你的代码简洁⽅便,那么在做好性能排查的前提下,可以去使⽤;如果不能,那么正则表达式能不⽤就不⽤,以此避免造成更多的性能问题。
思考题
除了Split()⽅法使⽤到正则表达式,其实Java还有⼀些⽅法也使⽤了正则表达式去实现⼀些功能,使我们很容易掉⼊陷阱。现在就请你想⼀想JDK⾥⾯,还有哪些⼯具⽅法⽤到了正则表达式?
期待在留⾔区看到你的⻅解。也欢迎你点击“请朋友读”,把今天的内容分享给身边的朋友,邀请他⼀起学习。
精选留⾔
 Geek_99fab9
Geek_99fab9
我没有你们优秀,我就明⽩以后少⽤点正则
2019-05-28 19:34
作者回复
不⼀样的优秀~恭喜你学到了精华!
2019-05-28 19:48
 陆离
陆离
⽼师{1,3}的意思不是最少匹配⼀次,最多匹配三次吗,独占模式那个例⼦为什么会不匹配呢?
2019-05-28 08:02
作者回复
你好,⽼师这⾥更正⼀下独占模式的例⼦,落了⼀个字符。ab{1,3}+bc
2019-05-28 10:01
 Liam
Liam ⽂中提供的split性能消耗⼤的例⼦:
⽂中提供的split性能消耗⼤的例⼦:
\?(([A-Za-z0-9-~_=%]+)\&{0,1})$”
⼀个+ 表示量词,⾄少1个,不是独占模式吧,这⾥能否详细解释下优化点在哪⾥
2019-05-29 09:02
作者回复
你好,⼀个+表示匹配⼀个或多个,表示尽量多的匹配。我们这个再加⼀个+,\?(([A-Za-z0-9-~_=%]++\&{0,1})+)。提供的这 个是没有优化的例⼦。
2019-05-29 22:50
 没有⼩名的曲⼉
没有⼩名的曲⼉
⽼师,那个(X|Y|Z)三次index是什么意思呢
2019-05-28 08:32
作者回复
指的是String中的indexof⽅法
2019-05-28 19:59
 K
K
\?(([A-Za-z0-9-~_=%]++\&{0,1})+)。⽼师好,麻烦您讲解⼀下实际您当时是怎么优化的吗?从哪个正则改成了哪个正则,为什么能有这种优化。谢谢⽼师。
2019-06-01 17:55
作者回复
如果是单个+的情况下,是最⼤匹配规则,遇到特殊字符串时,会出现回溯问题。这⾥增加了⼀个+,变成两个++,变成了独占模式,避免回溯。
2019-06-01 21:49
 ABC
ABC
看完明⽩了回溯是什么意思,我总结如下:
回溯就⽐如,⻝堂吃饭,你⼀下拿了3个馒头。吃完两个,发现第三个不是你想吃的⼝味的时候,⼜把第三个放回去,这就造成了资源浪费。
避免的办法就是,⼀开始就只拿两个,觉得需要了再去继续拿,也就是懒惰模式。
2019-05-30 00:47
作者回复
理解很到位,懒惰就是有拿到馒头就⾛,⾮常懒,还有馒头拿也不要了。
2019-05-30 22:31
 WL
WL
请问⼀下⽼师 “NFA 的状态数”这个概念感觉有点抽象我不太理解, 状态数是什么意思, 是NFA可以匹配的字符串的格式枚举吗?
2019-05-28 08:53
作者回复
你好 WL,就是不同的匹配格式,例如 ab{1,2}c,则状态数为2, 即 abc abbc。
2019-05-28 19:52
 ID171
ID171
还是上边的例⼦,在字符后⾯加⼀个“+”,就可以开启独占模式。
text=“abbc” regex=“ab{1,3}+bc”
结果是不匹配,结束匹配,不会发⽣回溯问题。
这⾥的每⼀步做了什么,在最⼤匹配之后⼜发⽣了什么
2019-06-11 10:53
作者回复
1、匹配regex中的a和text中的a,匹配成功,继续匹配下⼀个字符;
2、匹配regex中的b{1,3}+,这个时候是最⼤匹配规则,也就是说text中会尽量多的去匹配b,直到满⾜3个b字符匹配成功,才会结束b{1,3}的匹配,这⾥可以直接匹配到text中的abb;
3、由于还没有满⾜最⼤3个的匹配需求,会继续匹配text中的c,发现不匹配,这个时候regex会跳到后⾯这个字符b,拿这个字符继续匹配;
4、regex中的b发现与text中的c不匹配,则进⾏回溯,回溯到text中的前⼀个字符b,发现匹配成功;
5、继续regex的下⼀个字符c与text中的c字符匹配,匹配成功,匹配结束。
2019-06-13 09:24
 胖
胖
字符串替换⽅法
Replace 普通字符替换
Replaceall 正则替换
⼀直觉得这两个⽅法的取名很具有迷惑性
2019-05-28 00:26
 ddddd
ddddd
贪婪总有存在的价值吧;贪恋相⽐于独占两者匹配结果是不同的,但是贪婪相⽐于懒惰模式呢,总有优势在吧?
2019-07-12 16:49
作者回复
对的,根据业务需要来定,贪婪模式会最⼤匹配字符。
2019-07-17 11:20
 郁陌陵
郁陌陵
⽼师,我理解独占模式可以减少回溯,但是不能避免回溯: String regex = “^ab{1,3}+c$”; String str = “abbc”; 这个例⼦⾥,b{1,3}+ 在匹配到 abb后,⽆法匹配c,是需要回溯的
2019-07-05 15:03
作者回复
此时不会回溯了,返回不匹配结果。
2019-07-07 10:18
Geek_087820
⽼师,请问下text=“abbc” regex=“ab{1,3}?c”
这个懒惰模式下怎么匹配的,如果尽可能少的匹配,第⼀个b匹配成功了,是不是会读取c去匹配,当使⽤c去匹配b的时候不是会失败么
2019-06-28 17:20
作者回复
是的,这种会是匹配失败
2019-06-30 10:42
lax66
⽼师,在懒惰匹配时候,这种情况text=“abbbbbbc” regex=“ab{1,6}?c”,
因为在匹配‘b‘时候只⽐较了⼀次,然后就使⽤表达式的c进⾏匹配,发现不匹配,⼜使⽤表达式的‘b‘进⾏匹配,所以表达式这边也有回溯?
2019-06-27 08:34
作者回复
懒惰模式是不会再回去匹配了,regex的ab匹配完成text的ab之后,就会⽤regex的c去匹配text的b,不匹配则结束。
2019-06-27 09:57
 mumu
mumu
⽼师您好,我看您回答@ID171的内容后很疑惑,text=“abbc” ,regex=“ab{1,3}+bc”。这是独占模式,您⽂中说的不会回溯, 可是解释执⾏过程中⼜说有回溯,我想知道独占模式的不会发⽣回溯是什么?
2019-06-19 12:05 草帽路⻜
草帽路⻜ 构造 DFA ⾃动机的代价远⼤于 NFA ⾃动机,但 DFA⾃动机的效率⾼于 NFA ⾃动机。
构造 DFA ⾃动机的代价远⼤于 NFA ⾃动机,但 DFA⾃动机的效率⾼于 NFA ⾃动机。
⽼师您好,这句话应该是 构造NFA ⾃动机的代价⼤于 DFA ⾃动机吧?
2019-06-19 09:54
 peace
peace
⽼师你好,
String text = “abbc”;
String reg1 = “ab{1,3}+bc”;
回溯的例⼦⾥,不是b{1,3}匹配c的时候发⽣回溯 ⽽是b匹配的时候吧
优化的正则 可以举个匹配的例⼦么 哪种url会产⽣回溯。。
\?(([A-Za-z0-9-~_=%]++\&{0,1})+)
2019-06-12 18:05
作者回复
由于是最⼤匹配,所以匹配text中的c时,发现不匹配,这时会继续下⼀个匹配b和text中的c,发现不匹配,回溯到text中的b中
,匹配成功。是在匹配reg1中的b和text中的c时,不匹配时发⽣回溯。
参数中包含特殊字符串的链接都可能存在回溯。
2019-06-13 09:14
 yu
yu
⽼师,\?(([A-Za-z0-9-~_=%]++\&{0,1})+),这个++的独占模式没看明⽩,+是⼀次或多次,所以会尽量尝试多次,第⼆个+是独占模式不匹配返回失败,那结果不是⼀直都是失败???
2019-06-10 20:54
作者回复
如果没有特殊字符的情况下,这个是可以分割成功,如果有特殊字符,也会失败,这也证明了这个链接不合法。这样通过split既判断了链接的合法性,⼜提取了域名。
2019-06-10 21:39
 肖韬
肖韬
https://stackoverflow.com/questions/4489551/what-is-double-plus-in-regular-expressions
2019-06-09 15:00
 ROAD
ROAD
replaceall
2019-06-06 13:48
Geek_d93d56
我的测试代码
long l1 = System.currentTimeMillis(); for (int i = 0; i < 10000000; i++) { “abc”.matches(“ab{1,3}c”);
}
System.out.println(“1111: “ + (System.currentTimeMillis()-l1)); long l2 = System.currentTimeMillis();
for (int i = 0; i < 10000000; i++) { “abc”.matches(“ab{1,3}?c”);
}
System.out.println(“2222: “ + (System.currentTimeMillis()-l2));
输出结果:
1111: 6348
2222: 6329
消耗时间差不多,没有什么差别,请问是正常的吗
2019-06-04 19:02
作者回复
因为你的这个例⼦发⽣回溯⾮常少,⼏乎可以忽略了,可以写个回溯⽐较⻓的。
2019-06-05 08:57

若有收获,就点个赞吧
0 人点赞
